【强化学习(实践篇)】#1 多臂赌博机网格世界
本系列是基于萨顿的《强化学习(第2版)》的实践内容,不详细介绍理论基础,可搭配【强化学习】系列食用。
博主参考书中的算法和案例,提炼了个人认为比较典型的问题及其求解方法尝试使用Python实现。由于该系列内容是博主在学习过程中自行布置并完成的作业,若讲解和代码有不足之处还请多多包涵指教,更新优先级也会放在其他系列之下。
本文前置知识对应【强化学习】系列的第1~3篇。
多臂赌博机
问题概述
一个 k k k臂赌博机,智能体在每个时刻拉下 k k k个拉杆的其中一个,拉下拉杆 i i i有 p i p_i pi的概率获得数值为 1 1 1的奖励,还有 1 − p i 1-p_i 1−pi的概率没有任何奖励。
程序导览
为 k k k臂赌博机定义一个MAB类,存储每个拉杆的获奖概率、最优拉杆和最优期望奖励,并为其定义step方法根据拉下的拉杆随机返回奖励。
求解方法为 ϵ \epsilon ϵ-贪心算法,同样定义一个EpsilonGreedy类,存储每个拉杆的拉下次数和动作价值,并为其定义增量式更新的update方法和采取动作的action方法。
求解过程的伪代码如下:

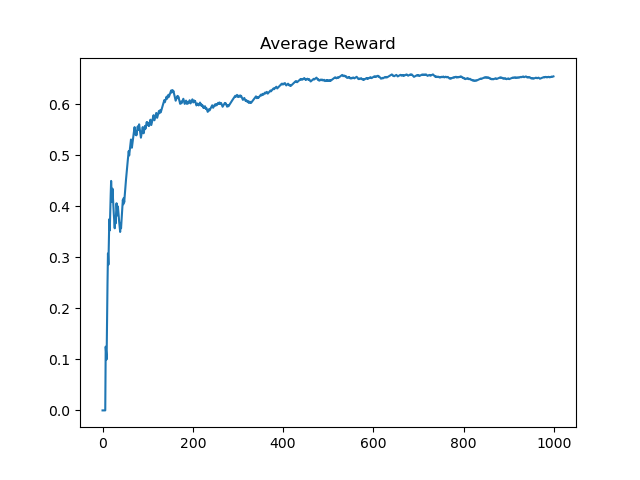
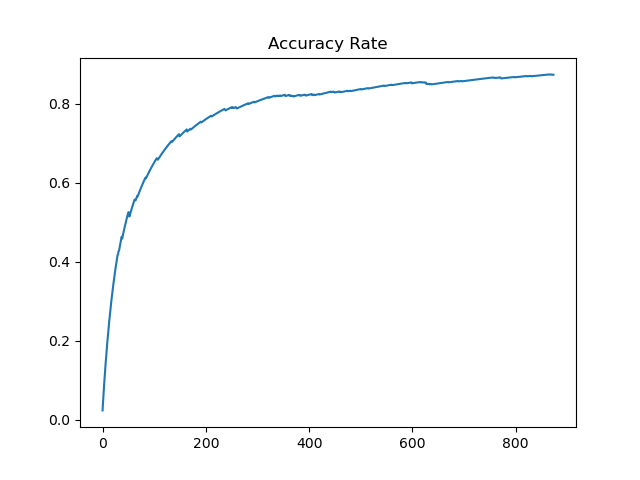
过程中记录算法的平均收益和拉下最优拉杆的概率。
代码实现
import numpy as np
import matplotlib.pyplot as plt #K臂赌博机模型
class MAB: def __init__(self, k): #拉杆数量 self.k = k #拉杆获奖概率 self.probs = np.random.uniform(size=k) #最优拉杆 self.best_action = np.argmax(self.probs) #最优期望奖励 self.best_prob = self.probs[self.best_action] #拉动拉杆 def step(self, action): if np.random.rand() < self.probs[action]: return 1 else: return 0 #Epsilon贪心算法
class EpsilonGreedy: def __init__(self, mab, epsilon): #赌博机模型 self.mab = mab #小概率值 self.epsilon = epsilon #初始化动作价值 self.q = np.zeros(self.mab.k) #拉杆拉下次数 self.n = np.zeros(self.mab.k) #更新动作价值 def update(self, action, reward): self.n[action] += 1 self.q[action] = self.q[action] + (reward - self.q[action]) / self.n[action] #选择动作 def action(self): if np.random.rand() < self.epsilon: return np.random.randint(0, self.mab.k) else: return np.argmax(self.q) #求解
def solve(bandit, solver, times): #记录平均奖励变化 total_reward, avg_reward = 0, [] total_acc, acc_rate = 0, [] for t in range(times): action = solver.action() reward = bandit.step(action) total_reward += reward avg_reward.append(total_reward / (t + 1)) solver.update(action, reward) if action == bandit.best_action: total_acc += 1 acc_rate.append(total_acc / (t + 1)) return avg_reward, acc_rate np.random.seed(1)
K = 10
Bandit = MAB(K)
print("Best Action:", Bandit.best_action)
print("Best Prob:", Bandit.best_prob) Epsilon = 0.1
Times = 1000
Solver = EpsilonGreedy(Bandit, Epsilon)
Avg_Reward, Acc_Rate = solve(Bandit, Solver, Times) plt.title("Average Reward")
plt.plot(Avg_Reward)
plt.show()
运行结果
最优拉杆和最优期望奖励:
Best Action: 1
Best Prob: 0.7203244934421581
网格世界
问题概述
在一个Width×Height的网格世界中,终点(终结状态)位于Goal State,障碍分布在Block State,状态集合是网格世界中除了Block State的格子。在到达终点前,智能体每移动一步都会得到Step Reward的惩罚(负数奖励),状态也相应地转移到下一个格子;撞到障碍物或边界则得到Block Reward的惩罚,位置不变;到达终点则得到Goal Reward的奖励。
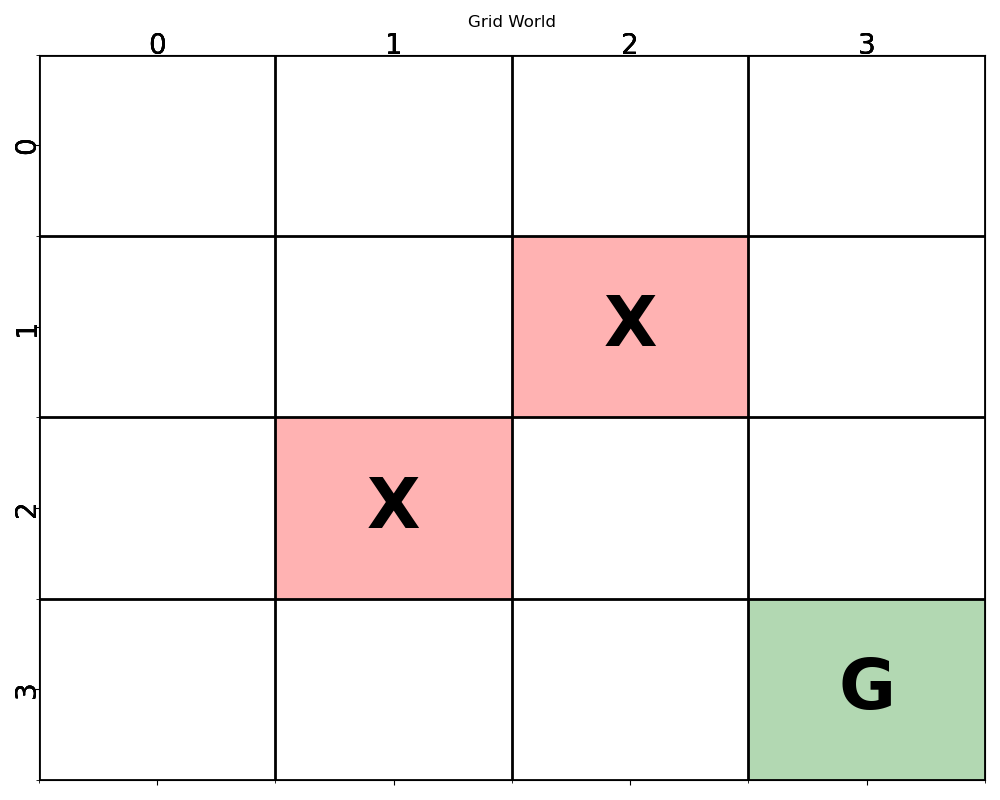
红底X格为障碍,绿底G格为终点。
该网格世界具有最简单的环境动态特性,只要当前状态和动作固定,后继状态和奖励也固定,通过给格子添加更丰富的属性可以得到更复杂的模型。
程序导览
网格世界按照问题概述进行建模。
求解方法为价值迭代,其伪代码如下:
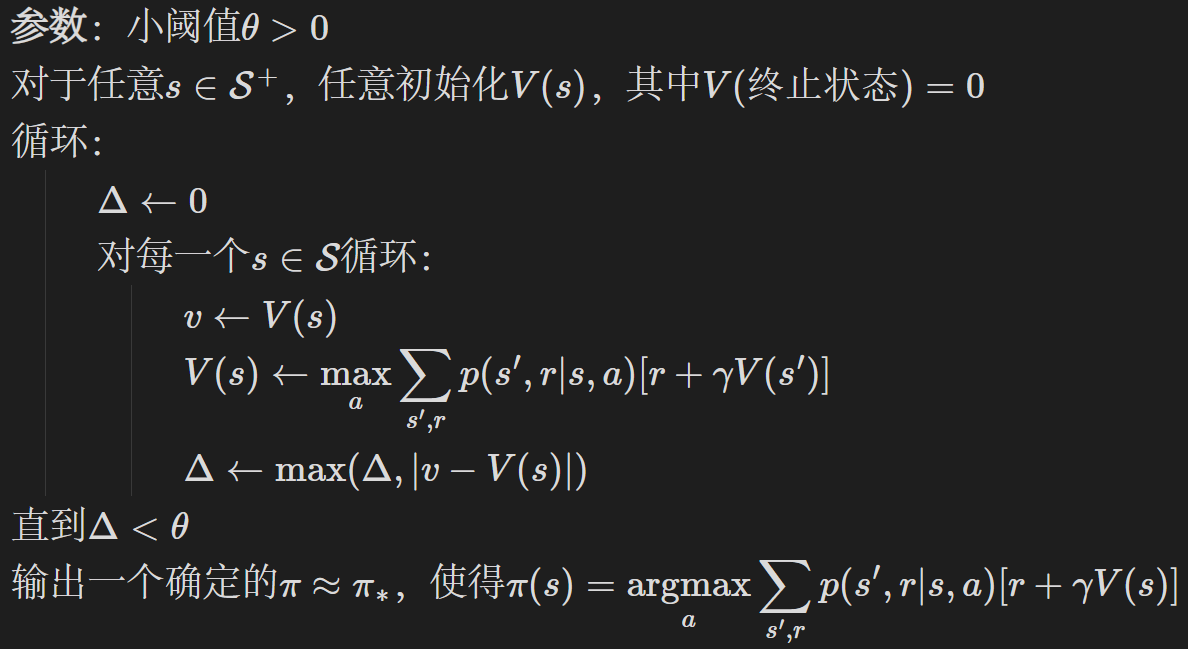
V ( s ) V(s) V(s)采用全 0 0 0初始化,状态遍历过程为:对网格世界中的每个坐标 ( i , j ) (i,j) (i,j),如果坐标属于障碍物或终点则跳过(障碍物不在状态集合,终点价值函数始终为 0 0 0),其余进行伪代码中的内层循环操作。动作带来的状态转移(坐标变化)通过Action_effects字典存储,对当前状态的每个动作,先计算后继状态的坐标,再根据后继状态位于终点、障碍物或界外、界内非终点三种情况分别设置奖励,并计算其动作价值。遍历所有动作后选取最优动作价值作为当前状态价值。
策略生成过程为:障碍物和终点的位置排除,对其余状态按同样的操作对动作进行遍历,并选取最优动作作为当前状态的策略。
代码实现
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.patches import Arrow, Rectangle #网格世界模型
Width = 4
Height = 4
State = [(i, j) for i in range(Width) for j in range(Height)]
Block_State = [(1, 2), (2, 1)]
Goal_State = [(3, 3)]
Action = ["up", "down", "left", "right"]
Action_effects = { "up": (-1, 0), "down": (1, 0), "left": (0, -1), "right": (0, 1)
} Goal_Reward = 0
Block_Reward = -1
Step_Reward = -1 #求解参数(小阈值,折扣系数)
Theta = 1e-7
Gamma = 0.9 #状态价值与策略
v = np.zeros([Width, Height])
pi = np.empty([Width, Height], dtype=object) #价值迭代
while True: delta = 0 for i in range(Width): for j in range(Height): if (i,j) in Goal_State + Block_State: continue v_temp = v[i, j] max_value = -np.inf for action in Action: next_i = i + Action_effects[action][0] next_j = j + Action_effects[action][1] next_state = (next_i, next_j) if next_state in Goal_State: reward = Goal_Reward elif next_state in Block_State or next_state not in State: reward = Block_Reward next_state = (i, j) else: reward = Step_Reward value = reward + Gamma * v[next_state] if value > max_value: max_value = value delta = max(delta, np.abs(max_value - v_temp)) v[i, j] = max_value if delta < Theta: break #策略生成
for i in range(Width): for j in range(Height): if (i, j) in Goal_State: pi[i, j] = "Goal" elif (i, j) in Block_State: pi[i, j] = "Block" else: best_action = None best_value = -np.inf for action in Action: next_i = i + Action_effects[action][0] next_j = j + Action_effects[action][1] next_state = (next_i, next_j) if next_state in Goal_State: reward = Goal_Reward elif next_state in Block_State or next_state not in State: reward = Block_Reward next_state = (i, j) else: reward = Step_Reward value = reward + Gamma * v[next_state] if value > best_value: best_value = value best_action = action pi[i, j] = best_action print(pi)
print(v) #可视化部分
fig, ax = plt.subplots(figsize=(10, 8))
ax.set_xlim(-0.5, Width - 0.5)
ax.set_ylim(-0.5, Height - 0.5)
ax.set_xticks(np.arange(-0.5, Width, 1), minor=True)
ax.set_yticks(np.arange(-0.5, Height, 1), minor=True)
ax.grid(which="minor", color="black", linestyle="-", linewidth=2)
ax.set_xticks(np.arange(Width))
ax.set_yticks(np.arange(Height))
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.invert_yaxis() arrow_length = 0.3
text_offset = 0.1 for i in range(Width): for j in range(Height): center_x, center_y = j, i if (i, j) in Block_State: ax.add_patch(Rectangle((center_x - 0.5, center_y - 0.5), 1, 1, color="red", alpha=0.3)) ax.text(center_x, center_y, "X", ha="center", va="center", fontsize=50, weight="bold") continue if (i, j) in Goal_State: ax.add_patch(Rectangle((center_x - 0.5, center_y - 0.5), 1, 1, color="green", alpha=0.3)) ax.text(center_x, center_y, "G", ha="center", va="center", fontsize=50, weight="bold") continue action = pi[i, j] if action == "up": dx, dy = 0, -arrow_length elif action == "down": dx, dy = 0, arrow_length elif action == "left": dx, dy = -arrow_length, 0 elif action == "right": dx, dy = arrow_length, 0 ax.arrow(center_x, center_y, dx, dy, head_width=0.1, head_length=0.15, fc="blue", ec="blue", lw=5) ax.text(center_x, center_y + text_offset, f"{v[i, j]:.1f}", ha="center", va="center", fontsize=40, color="lightgray", weight="bold", alpha=0.8) for i in range(Width): for j in range(Height): ax.text(j, -0.55, f"{j}", ha="center", va="center", fontsize=20) ax.text(-0.55, i, f"{i}", ha="center", va="center", fontsize=20, rotation=90) plt.title("Grid World", pad=20)
plt.tight_layout()
plt.show()
运行结果
[['down' 'right' 'right' 'down']['down' 'up' 'Block' 'down']['down' 'Block' 'down' 'down']['right' 'right' 'right' 'Goal']]
[[-4.0951 -3.439 -2.71 -1.9 ][-3.439 -4.0951 0. -1. ][-2.71 0. -1. 0. ][-1.9 -1. 0. 0. ]]
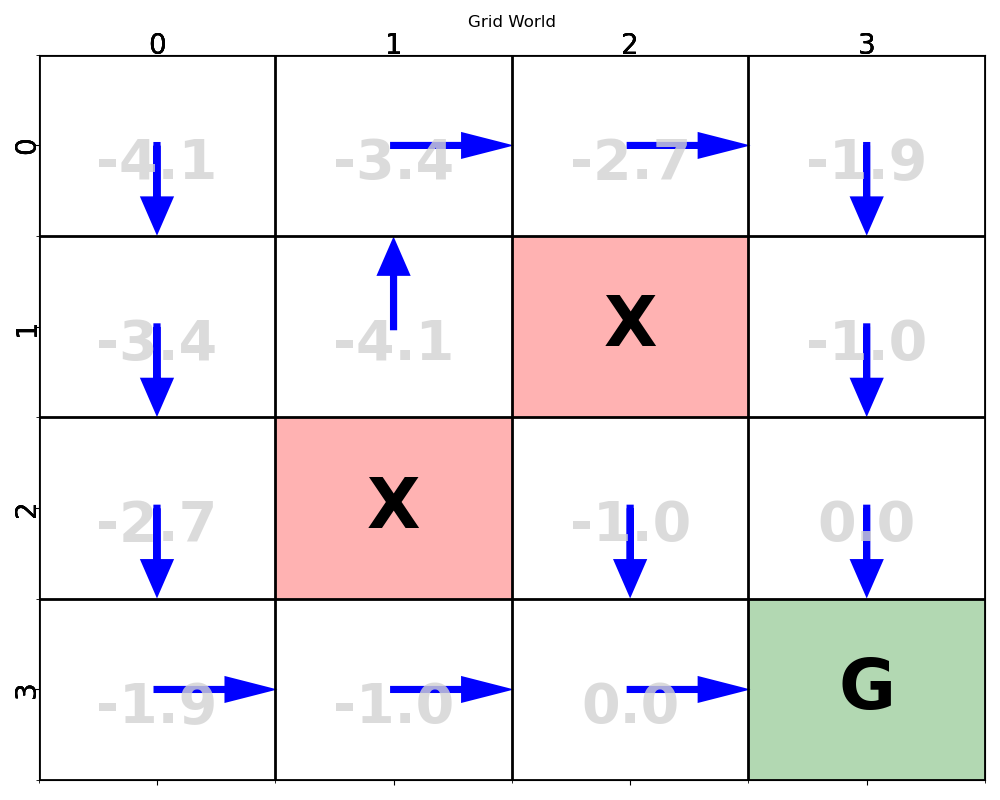
箭头为策略,灰色数字为策略的状态价值函数。