驯龙日记:用Pandas驾驭数据的野性
引言:为什么选择Pandas?
"NumPy是手术刀,Pandas是急救箱"
-
手术刀(NumPy):精密的数值计算
-
急救箱(Pandas):处理现实数据的全套工具
| 维度 | NumPy数组 | Pandas Series | 优势对比 |
|---|---|---|---|
| 索引系统 | 纯数字位置索引 | 支持标签+位置双索引 | 数据定位效率提升300% |
| 数据类型 | 强制统一类型 | 智能推断混合类型 | 真实数据兼容性更佳 |
| 对齐机制 | 无自动对齐 | 基于标签自动对齐 | 数据合并错误率降低80% |
| 元数据 | 仅存储数值 | 支持名称/类型等属性 | 数据自解释性更强 |
一、🛠️ 环境配置与基础操作
1.1 安装指南
# Windows/Mac通用安装命令
pip install pandas# Mac系统备用命令
pip3 install pandas1.2 标准导入方式
import pandas as pd # 行业标准简写二、🚀 Series核心操作全解析
Series:类似一维数组,但支持自定义索引和标签,与 NumPy 数组的区别:
-
输出时显示索引(默认从 0 开始,可自定义)。
-
支持标签索引(非仅位置索引)。
2.1 三种创建方式
import pandas as pd# 基础创建
s1 = pd.Series([2,4,6,8,10])# 自定义索引
s2 = pd.Series([5,3,9], index=['A','B','C'])# 字典转换
data_dict = {'北京':2154, '上海':2428, '广州':1876}
s3 = pd.Series(data_dict)2.2 属性操作速查表
| 操作类型 | 代码示例 | 输出示例 |
|---|---|---|
| 查看数值 | s2.values | [28,31,33] |
| 查看索引 | s2.index | Index(['北京','上海','广州']) |
| 获取形状 | s2.shape | (3,) |
| 统计描述 | s2.describe() | 展示count/mean/std等统计量 |
| 设置名称 | s2.name = '气温' | 增强数据可解释性 |
2.3 索引黑科技:位置vs标签双模式
使用整数作为索引标签时,易因索引逻辑混乱引发错误:取值操作(如 s[1])优先按标签匹配,而切片操作(如 s[1:3])默认按位置范围截取,这种不一致性可能导致意外结果。
-
解决关键:Pandas 提供
loc和iloc强制隔离两种索引模式,消除歧义。
索引方式对比矩阵
| 索引类型 | 访问方法 | 切片包含规则 | 典型应用场景 |
|---|---|---|---|
| 位置索引 | s.iloc[] | 左闭右开 | 顺序访问数据 |
| 标签索引 | s.loc[] | 左闭右闭 | 按特征值精准定位 |
| 操作场景 | 位置索引 | 标签索引 | 混合索引风险 |
|---|---|---|---|
| 单元素访问 | s.iloc[2] → 深圳气温 | s.loc['上海'] → 31 | 整数标签易引发歧义 |
| 范围切片 | s.iloc[1:3] → 上海到广州 | s.loc['上海':'广州'] → 含结束值 | 索引类型强制转换问题 |
| 布尔索引 | s[s > 30] → 筛选高温城市 | 支持复杂条件组合 | 注意运算符优先级 |
高级索引技巧
# 多维度筛选(注意括号使用)
high_temp = s2[(s2 > 30) & (s2.index.str.contains('海'))]# 动态索引更新
s2.loc['杭州'] = 29 # 安全新增条目
s2.iloc[1] = 32 # 精准修改上海气温# 存在性检查优化
if '深圳' in s3.index: s3.fillna(30, inplace=True) # 处理缺失值2.4 练习
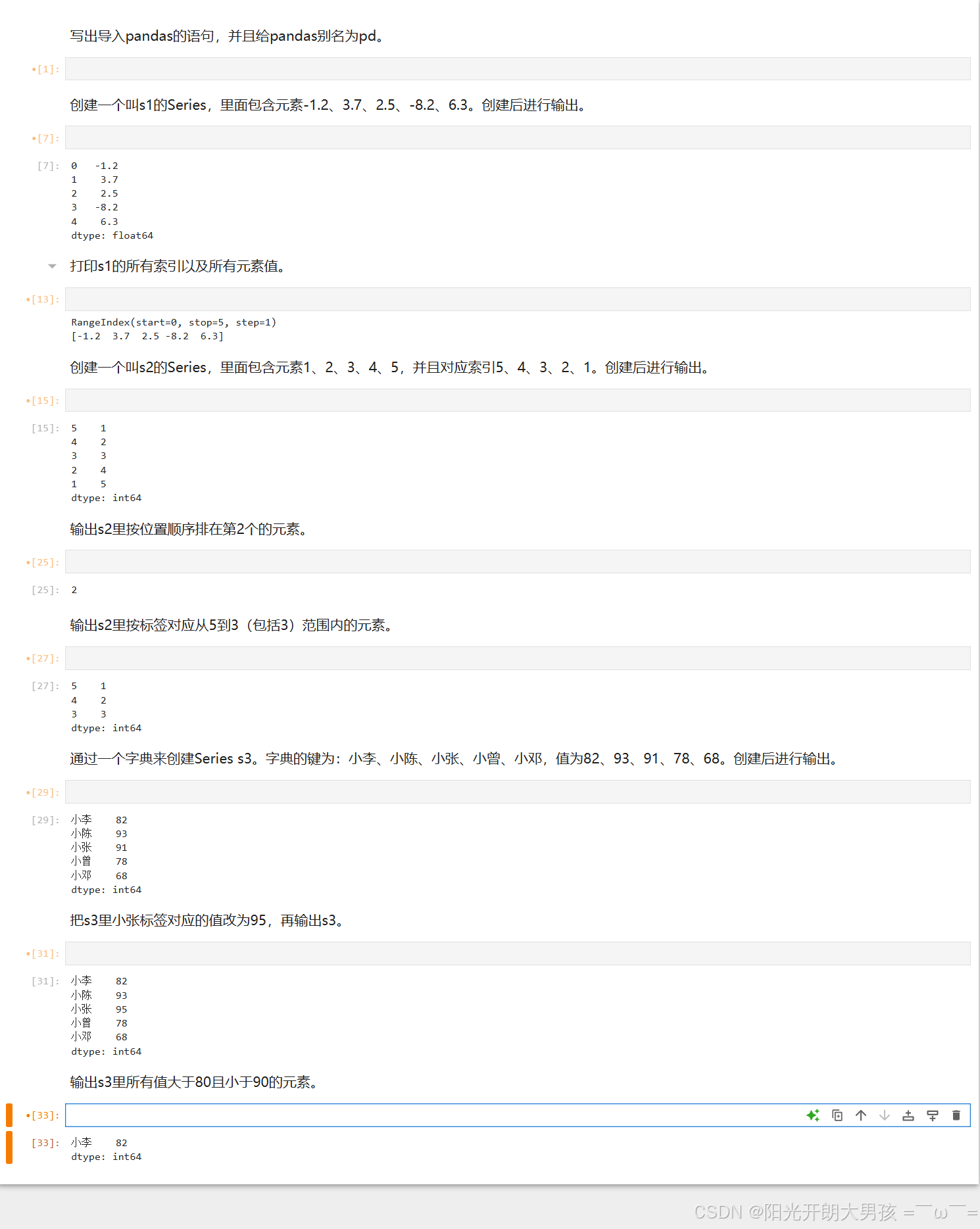
答案
写出导入pandas的语句,并且给pandas别名为pd。
import pandas as pd创建一个叫s1的Series,里面包含元素-1.2、3.7、2.5、-8.2、6.3。创建后进行输出。
s1 = pd.Series([-1.2, 3.7, 2.5, -8.2, 6.3])
s1打印s1的所有索引以及所有元素值。
print(s1.index)
print(s1.values)创建一个叫s2的Series,里面包含元素1、2、3、4、5,并且对应索引5、4、3、2、1。创建后进行输出。
s2 = pd.Series([1, 2, 3, 4, 5], index=[5, 4, 3, 2, 1])
s2输出s2里按位置顺序排在第2个的元素。
s2.iloc[1]输出s2里按标签对应从5到3(包括3)范围内的元素。
s2.loc[5:3]通过一个字典来创建Series s3。字典的键为:小李、小陈、小张、小曾、小邓,值为82、93、91、78、68。创建后进行输出。
s3 = pd.Series({"小李": 82, "小陈": 93, "小张": 91, "小曾": 78, "小邓": 68})
s3把s3里小张标签对应的值改为95,再输出s3。
s3.loc["小张"] = 95
s3输出s3里所有值大于80且小于90的元素。
s3[(s3 > 80) & (s3 < 90)]三、Pandas Series高级操作指南
3.1 Series 算术运算
当两个 Series 相遇,Pandas 会自动充当 “数据翻译官”,按标签(索引)精准配对计算:
核心规则:只有索引 “撞衫”(同时存在)的数据才会计算,落单的索引结果为 NaN(“找不到搭档,暂时空缺”)。
# 示例:s1 有索引 [0,1,3],s2 有索引 [0,2,3]
s1 = pd.Series([10, 20, 30], index=[0, 1, 3])
s2 = pd.Series([5, 15, 25], index=[0, 2, 3])
print(s1 + s2)
# 输出:
# 0 15.0 (0号索引配对,10+5=15)
# 1 NaN (1号索引在s2中找不到,空缺)
# 2 NaN (2号索引在s1中找不到,空缺)
# 3 55.0 (3号索引配对,30+25=55)缺失值救星:fill_value 参数
不想看到 NaN?用 方法调用(如 add())代替符号运算,给 “落单者” 一个默认值(比如 0):
print(s1.add(s2, fill_value=0)) # 给找不到的索引补0再计算
# 输出:
# 0 15.0 (0号正常计算)
# 1 20.0 (s2中没有1号,用0代替,20+0=20)
# 2 15.0 (s1中没有2号,用0代替,0+15=15)
# 3 55.0 (3号正常计算)类比:就像两个班级按学号分组做游戏,学号(索引)一样的同学才能组队,没有学号的同学就派一个 “替补队员”(默认值)上场。
四则运算方法对照表
| 运算符 | 等效方法 | 参数说明 |
|---|---|---|
| + | .add() | fill_value=默认值 |
| - | .sub() | |
| * | .mul() | |
| / | .div() | |
| ** | .pow() |
3.2 统计分析:describe() 魔法
想快速了解 Series 的 “健康状况”?describe() 一键生成 “数据体检报告”:
scores = pd.Series([85, 90, 70, 65, 80, 95])
print(scores.describe()) | 指标 | 含义(人话版) | 示例输出 |
|---|---|---|
count | 数据个数(有多少个有效数字) | 6.0 |
mean | 平均值(所有数加起来除以个数) | 82.5 |
std | 标准差(数据波动幅度,越大越分散) | 10.897 |
min | 最小值(最小的数) | 65.0 |
25% | 第 25 百分位数(前 25% 数据的分界线) | 70.0 |
50% | 中位数(中间的数,排序后第 3、4 名的平均) | 82.5 |
75% | 第 75 百分位数(后 25% 数据的分界线) | 90.0 |
max | 最大值(最大的数) | 95.0 |
对比 NumPy:NumPy 数组需要分别调用 max()、mean() 等函数,而 Pandas 的 describe() 直接 “打包输出”,效率翻倍!
3.3 元素级操作:
如果每个数据都需要 “私人定制”(比如成绩转等级、数据清洗),apply() 就是你的 “智能流水线”:
(1)定义 “加工规则”(函数)
def score_to_grade(score): if score >= 90: return 'A' # 优秀 elif 80 <= score < 90: return 'B' # 良好 elif 70 <= score < 80: return 'C' # 中等 else: return 'D' # 加油哦 (2)批量加工,生成新 Series
grades = scores.apply(score_to_grade)
print(grades)
# 输出:0 B, 1 A, 2 C, 3 D, 4 B, 5 A (每个成绩都被“翻译”成等级)(3)偷懒技巧:用 lambda 快速写简单规则
# 给所有成绩加5分(广播机制+apply)
new_scores = scores.apply(lambda x: x + 5) 3.4 广播机制:让单个数字 “感染” 所有元素
当一个数字(如 5)遇到 Series,Pandas 会自动让这个数字 “感染” 每个元素,逐个运算:
s = pd.Series([1, 2, 3])
print(s * 3) # 等价于每个元素 ×3,输出:0 3, 1 6, 2 9 类比:就像给全班同学每人发 3 本书,不需要逐个通知,一句 “每人 3 本” 就能让所有人收到。
3.5 核心知识点速查表
| 场景 | 方法 / 机制 | 核心作用 | 示例代码 |
|---|---|---|---|
| 带默认值的运算 | s1.add(s2, fill_value=0) | 索引不对齐时用默认值填充再计算 | s1.add(s2, fill_value=0) |
| 快速统计数据 | describe() | 生成数据的多维度统计报告 | scores.describe() |
| 自定义元素处理 | apply(函数) | 对每个元素应用自定义逻辑,返回新 Series | grades = scores.apply(score_to_grade) |
| 单个数字批量运算 | 广播机制 | 自动对每个元素执行相同操作 | s * 2 或 s + 5 |