spark 课程总结
本次课程主要围绕Spark 大数据分析计算引擎展开,涵盖其概念、核心模块、运行模式、安装部署、编程及与其他组件集成等多方面知识。
一、Spark基础
1.定义
Spark 是基于内存的快速、通用、可扩展的大数据分析计算引擎,用 Scala 语言开发
2.核心模块
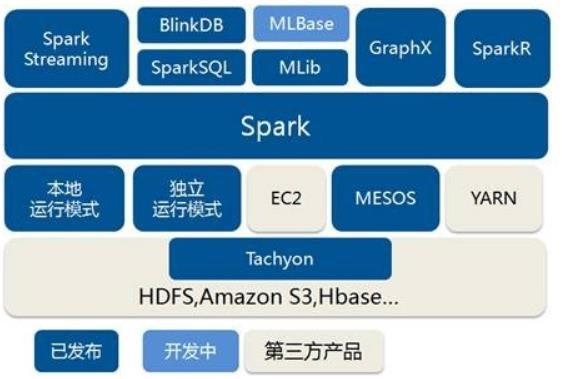
包含 Spark Core(提供基础核心功能)、Spark SQL(操作结构化数据)、Spark Streaming(处理实时数据)、MLlib(机器学习算法库)和 GraphX(面向图计算)

3.运行模式
有 Local(用于教学调试)、Standalone(独立集群模式)、Yarn(常用,与资源调度框架集成)、K8S & Mesos(国外使用较多)、Windows(方便学习)等模式,各模式在安装机器数、需启动进程、所属者和应用场景上有差异
二、Spark安装
可在多种环境下部署,如 Local 模式在单节点执行,Standalone 模式构建独立集群,Yarn 模式与 Hadoop Yarn 集成,Windows 模式便于本地学习。部署时需准备虚拟机、下载压缩包,按步骤进行解压、配置文件、启动集群等操作,并可配置历史服务查看任务运行情况 。
本次学习的是Spark 4种部署模式的其中2种,分别是Local、Standalone模式。
三、Spark运行架构与核心概念
1.运行架构
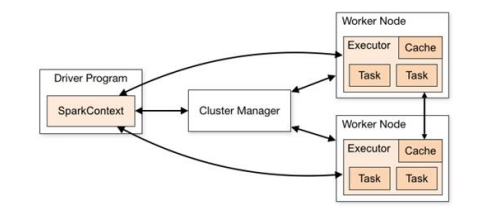
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
2.核心组件
spark框架的核心组件有两个:
Driver:
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Executor:
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。
3.核心概念
Executor 是工作节点的 JVM 进程,负责运行任务和缓存数据;并行度指集群并行执行任务的数量;有向无环图(DAG)是程序计算执行过程的抽象模型
四、Spark RDD
1.概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
2.核心属性
包括 分区列表、分区计算函数、RDD之间依赖关系、分区器、首选位置
3.执行原理
1)启用Yarn集群环境
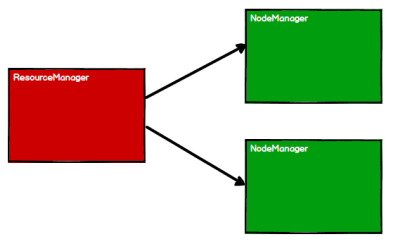
2)Spark 通过申请资源创建调度节点和计算节点
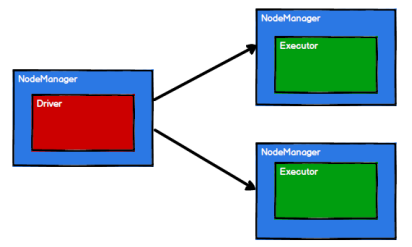
3)Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
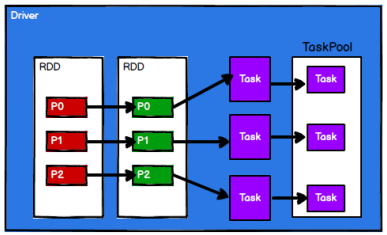
4)调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
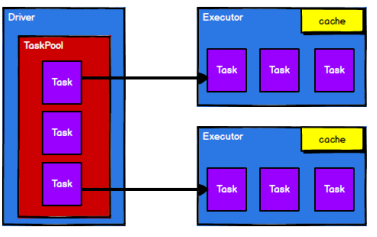
五、Spark SQL
1.概述和特点
用于结构化数据处理,前身是 Shark,具有易整合、统一数据访问、兼容 Hive、标准数据连接等特点,提供 DataFrame 和 DataSet 两个编程抽象
2.核心编程
可通过多种方式创建 DataFrame 和 DataSet,支持 SQL 语法、DSL 语法操作,RDD、DataFrame 和 DataSet 之间可相互转换,还能进行自定义函数和聚合函数操作,以及数据的加载与保存
六、Spark streaming

1.概述和特点
用于流式数据处理,支持多种数据输入源,使用 DStream 作为抽象表示,具有易用、容错、易整合的特点
2.架构
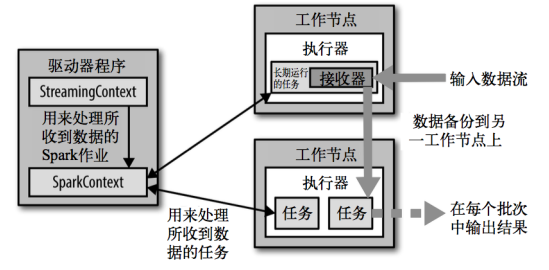
3.核心编程
可通过 RDD 队列、自定义数据源、Kafka 数据源创建 DStream,DStream 上的操作包括无状态转化操作和输出操作,还有特殊原语,如 updateStateByKey ()、transform () 等
七、Spark-Core
1.RDD基础操作
1)创建方式:RDD 可从集合(内存)、外部存储(文件)、其他 RDD 创建,还可由 Spark 框架自身使用new方式创建。如通过parallelize或makeRDD从集合创建,利用textFile从文件创建
2)并行度与分区:并行度指能并行计算的任务数量,可在构建 RDD 时指定。内存数据按并行度设定分区,文件数据依据 Hadoop 文件读取规则切片分区,且有相应的分区规则源码
2.RDD算子应用
1)转换算子:分为 Value 类型、双 Value 类型和 Key - Value 类型。Value 类型如map逐条映射转换数据,mapPartitions以分区为单位处理数据,二者在数据处理、功能和性能上有差异;双 Value 类型包括intersection求交集、union求并集等;Key - Value 类型有partitionBy分区、reduceByKey聚合等,不同算子功能和适用场景各异
2)行动算子:会触发真正的计算数据,如reduce聚集所有元素,collect以数组形式返回数据集所有元素,foreach分布式遍历元素并调用指定函数等
3.累加器和广播变量
1)累加器:用于将 Executor 端变量信息聚合到 Driver 端。可声明系统累加器,如longAccumulator,也可自定义累加器。自定义累加器需继承AccumulatorV2并实现相关方法,用于特定的聚合计算
2)广播变量:用于高效分发较大的只读对象到所有工作节点。通过sparkContext.broadcast创建广播变量,在多个并行操作中可使用,避免每个任务重复发送相同变量