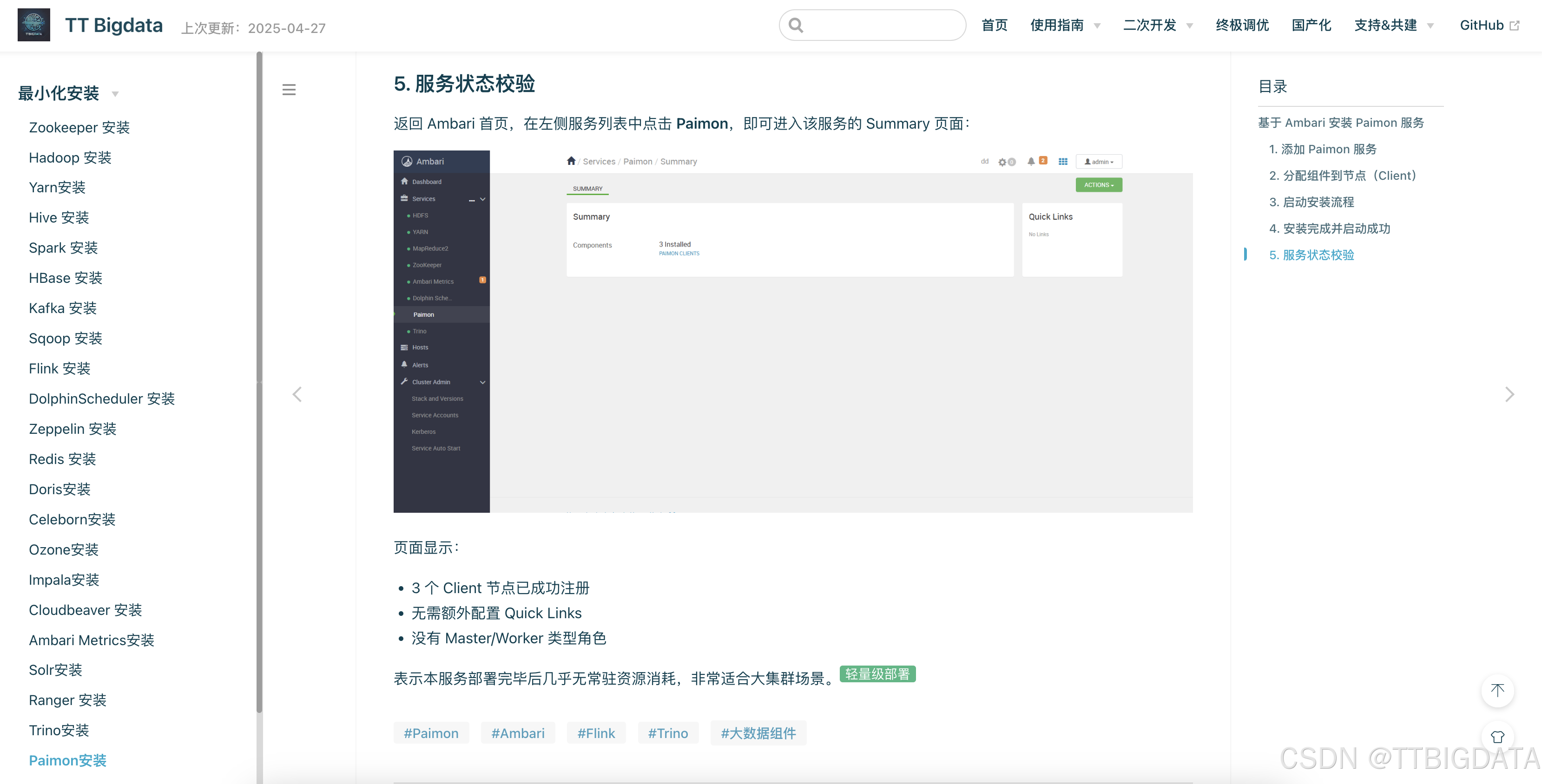
如何将 Apache Paimon 接入 Ambari?完整部署与验证指南
近期我已完成 Apache Paimon 在 Ambari 体系下的服务集成
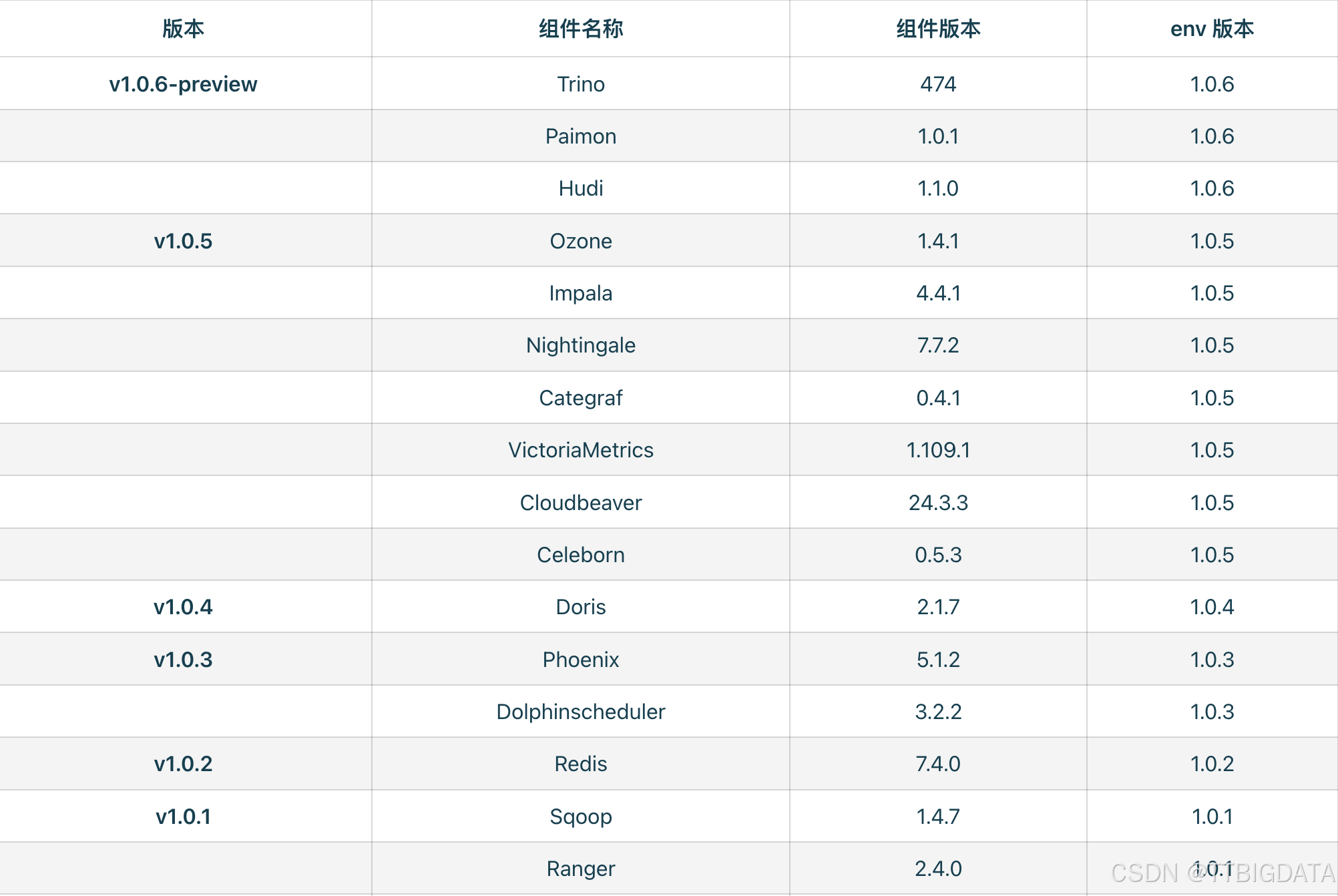
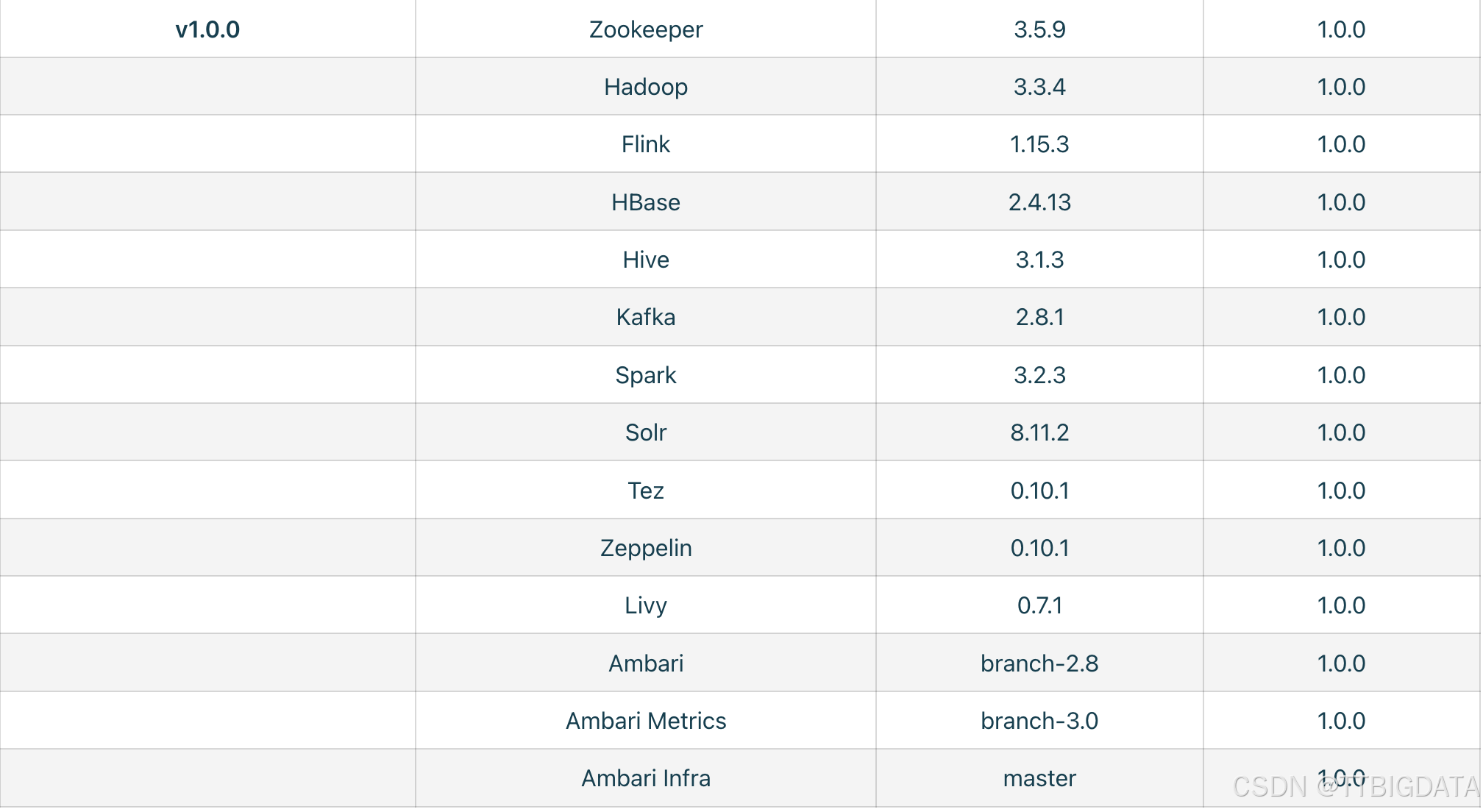
总的版本集成度可参考
🔍 为什么选择集成 Paimon?
Apache Paimon 是一款针对流式和批量数据处理场景优化的数据存储引擎,提供了 高效的数据写入、查询和一致性保障,特别适用于大数据处理平台中的数据湖和实时分析需求。
在实际项目中,常见的应用场景包括:
- 海量日志数据的处理和分析
- 数据实时流转与离线分析数据的统一访问
- 使用 Trino、Flink、Spark 等工具进行多维度数据分析和查询
而 Paimon 能够解决以下挑战:
- 高效的流批一体处理:支持实时流数据和批量数据的无缝集成,保证数据的一致性和低延迟。
- 支持多种存储格式:灵活支持 Parquet 和 ORC 等存储格式,优化存储效率。
- 可扩展性强:基于 Apache Flink 的架构设计,Paimon 能够在分布式环境中高效运行,扩展性强,适应不断增长的数据量。
- 支持统一的查询引擎:通过 Trino 等查询引擎,用户可以高效地对存储在 Paimon 中的数据进行多维度的查询分析。
集成 Paimon 后,可以帮助企业在大数据平台上构建 统一的数据湖架构,简化数据的流转与分析流程,提升数据处理的效率和一致性。
🔧 已完成哪些集成工作?
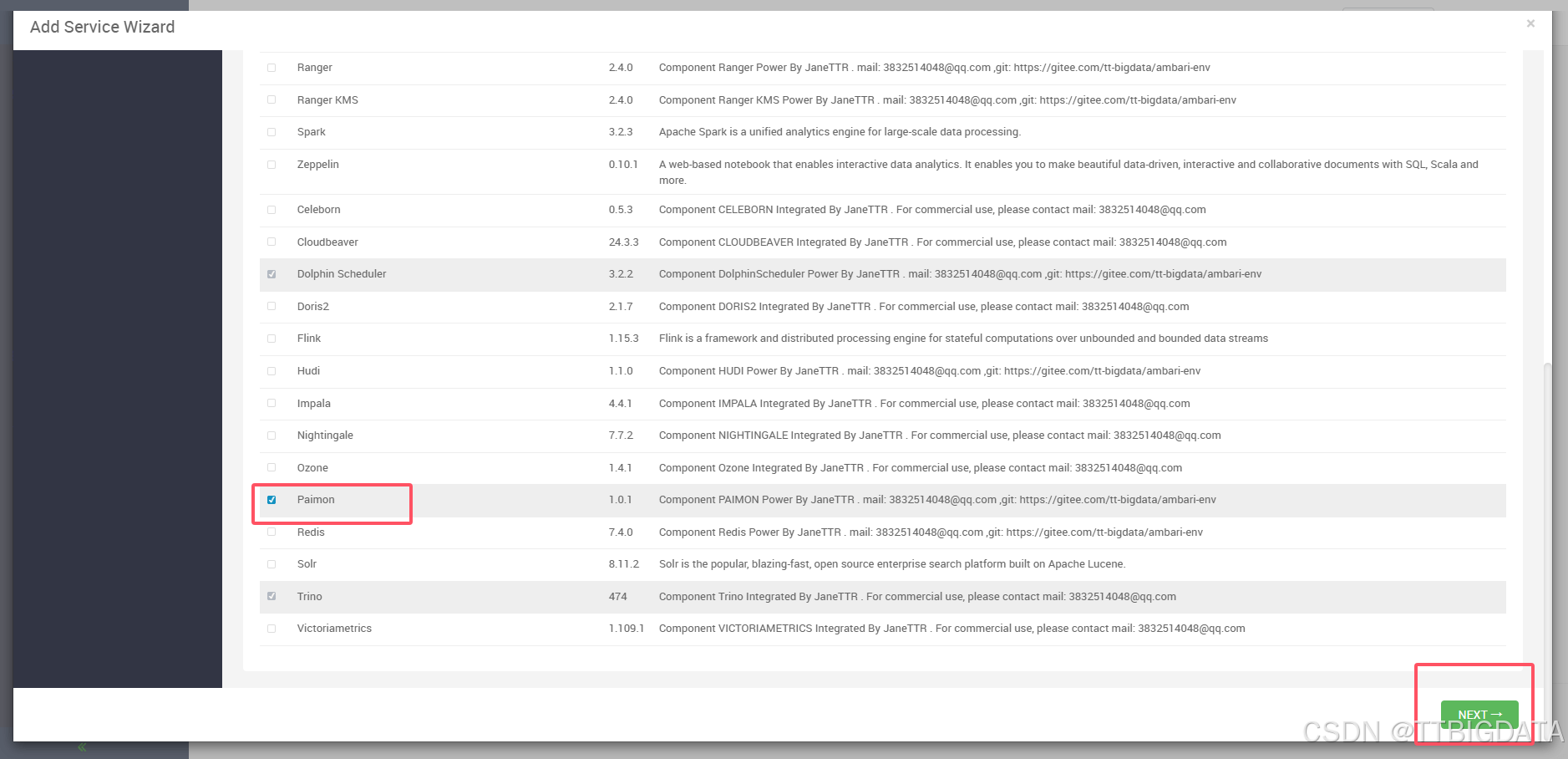
如下是部署过程截图示意👇:
-
服务选择:
-
安装完成:
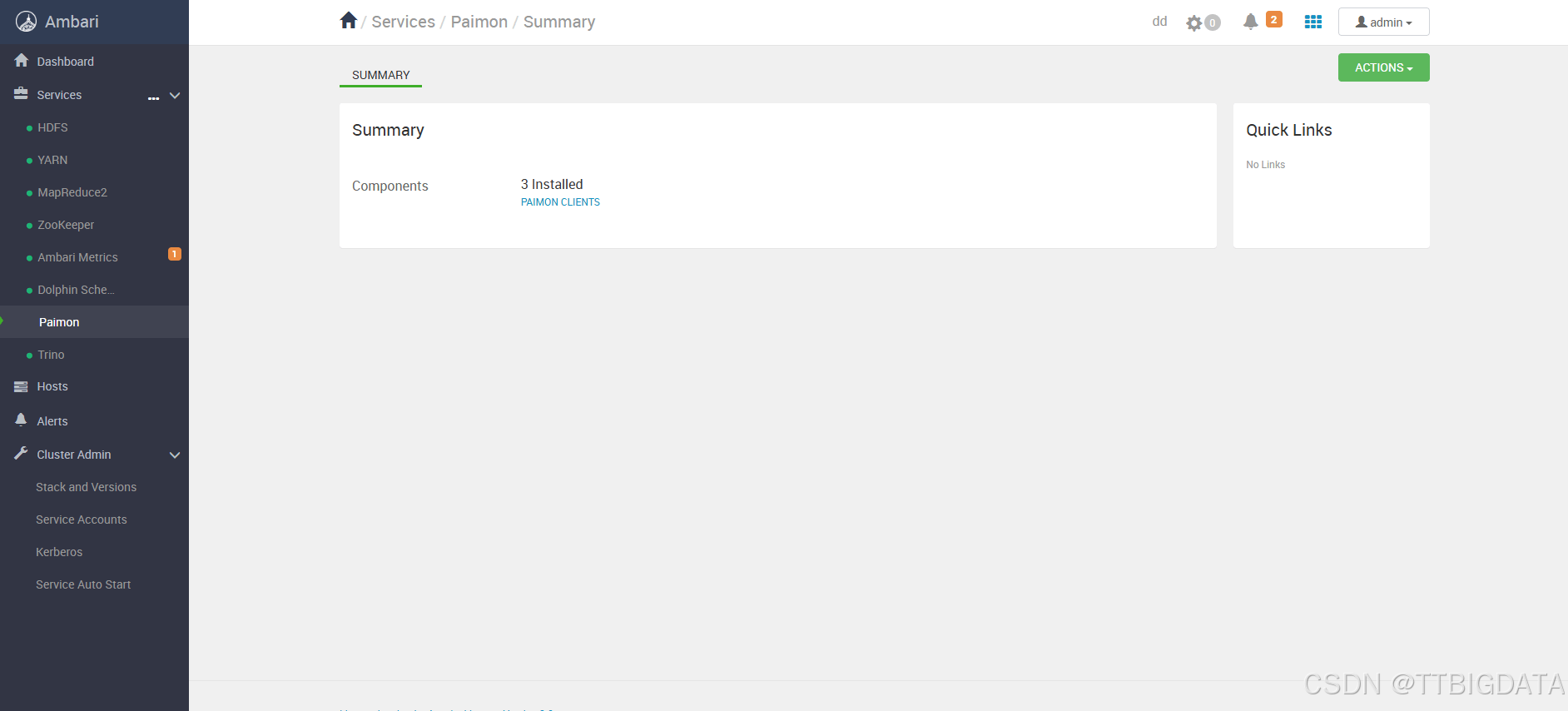
📚 如何安装
如果你也在做基于 Ambari 的组件扩展、数据湖架构实践,欢迎一起探讨。
如何安装可参考:https://doc.janettr.com/