剑指Offer(数据结构与算法面试题精讲)C++版——day21
剑指Offer(数据结构与算法面试题精讲)C++版——day21
- 题目一:数据流的第k大数字
- 题目二:出现频率最高的k个数字
- 题目三:和最小的k个数对
- 附录:源码gitee仓库
题目一:数据流的第k大数字
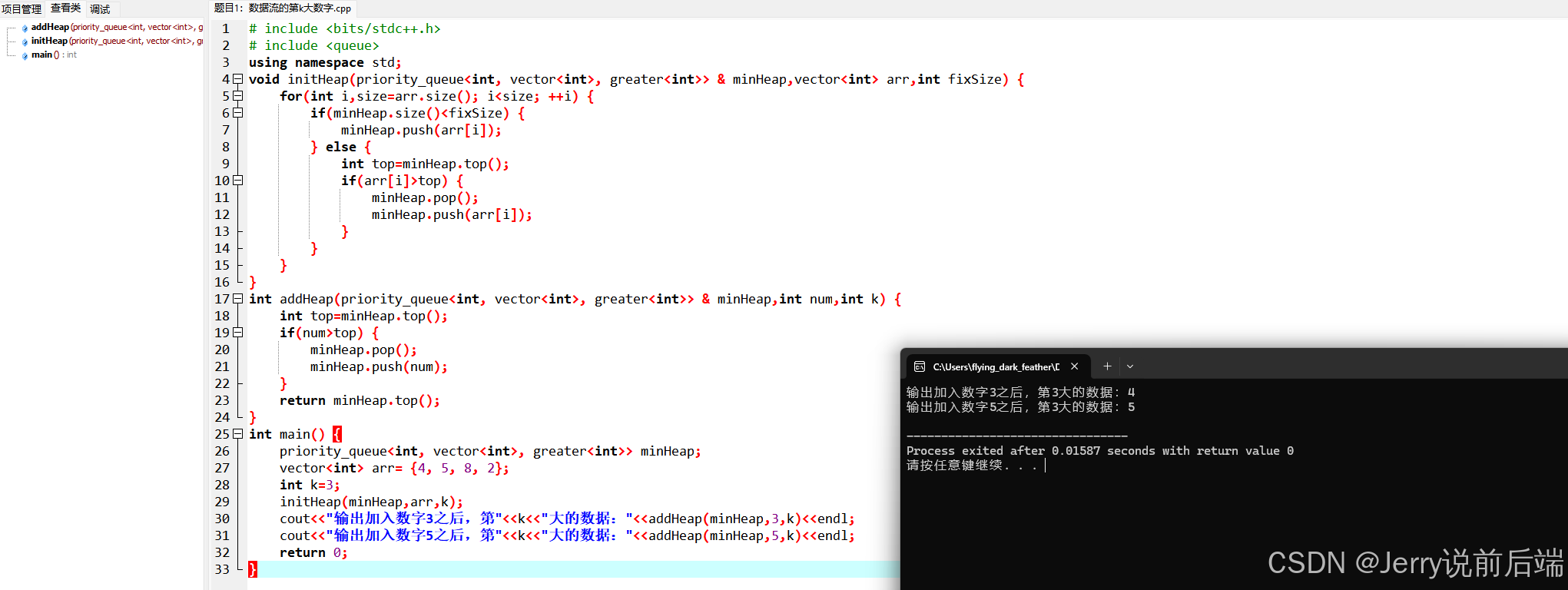
题目:请设计一个类型KthLargest,它每次从一个数据流中读取一个数字,并得出数据流已经读取的数字中第k(k≥1)大的数字。该类型的构造函数有两个参数:一个是整数k,另一个是包含数据流中开始数字的整数数组nums(假设数组nums的长度大于k)。该类型还有一个函数add,用来添加数据流中的新数字并返回数据流中已经读取的数字的第k大数字。
例如,当k=3且nums为数组[4, 5, 8, 2]时,调用构造函数创建类型KthLargest的实例之后,第1次调用add函数添加数字3,此时已经从数据流中读取了数字4、5、8、2和3,第3大的数字是4;第2次调用add函数添加数字5时,则返回第3大的数字5。
如果不考虑时间复杂度那么可以直接暴力处理,直接对每次加入的数据排序,固定返回第k个即可。但是由于这里题意中给出的是数据流,排序的话需要对所有数据处理,空间可能不够用,并且这类型场景都需要考虑时间复杂度。
分析发现,这里存在类似于堆的结构,比如在大根堆中,可以很方便的找到一组动态变化的数中最大的一个,并且维护的时间复杂度较低。于是借鉴这里的思路,可以构建一个大小固定为k的优先级队列,这k个元素是这组数据中最大的k个元素,并且让这k个数构成一个小根堆,这样每次取出堆顶元素就可以得到第k大的数字。在维护上,C++中有可以使用的库,直接利用库来实现即可,最终得到如下代码:
void initHeap(priority_queue<int, vector<int>, greater<int>> & minHeap,vector<int> arr,int fixSize) {for(int i=0,size=arr.size(); i<size; ++i) {if(minHeap.size()<fixSize) {minHeap.push(arr[i]);} else {int top=minHeap.top();if(arr[i]>top) {minHeap.pop();minHeap.push(arr[i]);}}}
}
int addHeap(priority_queue<int, vector<int>, greater<int>> & minHeap,int num,int k) {int top=minHeap.top();if(num>top) {minHeap.pop();minHeap.push(num);}return minHeap.top();
}
题目二:出现频率最高的k个数字
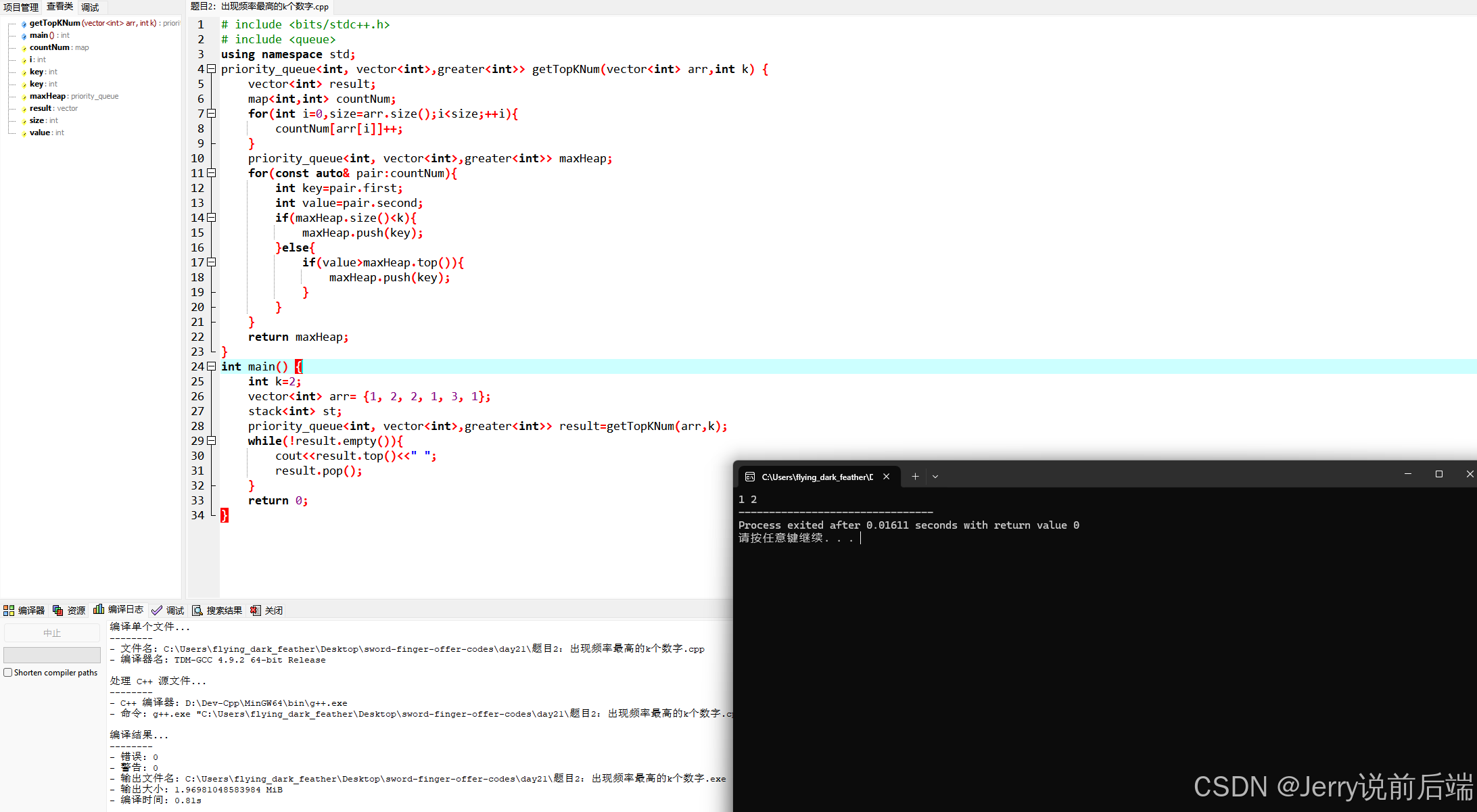
题目:请找出数组中出现频率最高的k个数字。例如,当k等于2时,输入数组[1, 2, 2, 1, 3, 1],由于数字1出现了3次,数字2出现了2次,数字3出现了1次,因此出现频率最高的2个数字是1和2。
因为这里提到了需要统计每个数的出现频次,因此立即会想到利用map构建hash表结构。现在的关键点在于如何保证拿到<数字,出现次数>的映射关系之后,返回出现频次最高的k个数。和前面的方法一样构建一个大小为k小根堆,如果当前小根堆中的元素个数小于k,直接加入到小根堆中,如果当前的已经有k个元素了,那么取出小根堆堆顶元素判断,如果待加入元素频次高于已有堆顶元素频次,那么新元素入堆。于是得到如下代码:
priority_queue<int, vector<int>,greater<int>> getTopKNum(vector<int> arr,int k) {vector<int> result;map<int,int> countNum;for(int i=0,size=arr.size();i<size;++i){countNum[arr[i]]++;}priority_queue<int, vector<int>,greater<int>> maxHeap;for(const auto& pair:countNum){int key=pair.first;int value=pair.second;if(maxHeap.size()<k){maxHeap.push(key);}else{if(value>maxHeap.top()){maxHeap.push(key);}}}return maxHeap;
}
这里需要补充说明,由于这里小根堆中存储的都是<数字,出现次数>的键值key,因此构建的堆中频次只能确定堆顶频次最小。之后依次找出这k个结果的时候,由于小根堆的特点,所以是按照键值key导出的。不能够保证按照频次倒叙排列。由于题目没有对这k个数的输出顺序要求,所以这里直接频次乱序输出即可。如果还要求对这k个数按照频次倒叙输出应该怎么办呢?其实也不难实现,可以将问题简化成知道了一组<数字,出现次数>键值对,需要将这些键值对按照出现次数倒序排序。这样可以使用大根堆来实现,相当于将键值反向,按照出现的次数作为键,将原先的键作为值,由于出现相同次数的值可能对应多个键,因此使用数组存储。得到如下代码:
priority_queue<int, vector<int>> maxHeap;
while(!minHeap.empty()) {int key=minHeap.top();maxMap[countNum[key]].push_back(key);minHeap.pop();
}
priority_queue<int, vector<int>> maxHeap;
for(const auto& pair:maxMap) {int key=pair.first;maxHeap.push(key);
}
while(!maxHeap.empty()) {vector<int> values=maxMap[maxHeap.top()];for(int i=0,size=values.size(); i<size; ++i) {cout<<values[i]<<" ";}maxHeap.pop();
}
题目三:和最小的k个数对
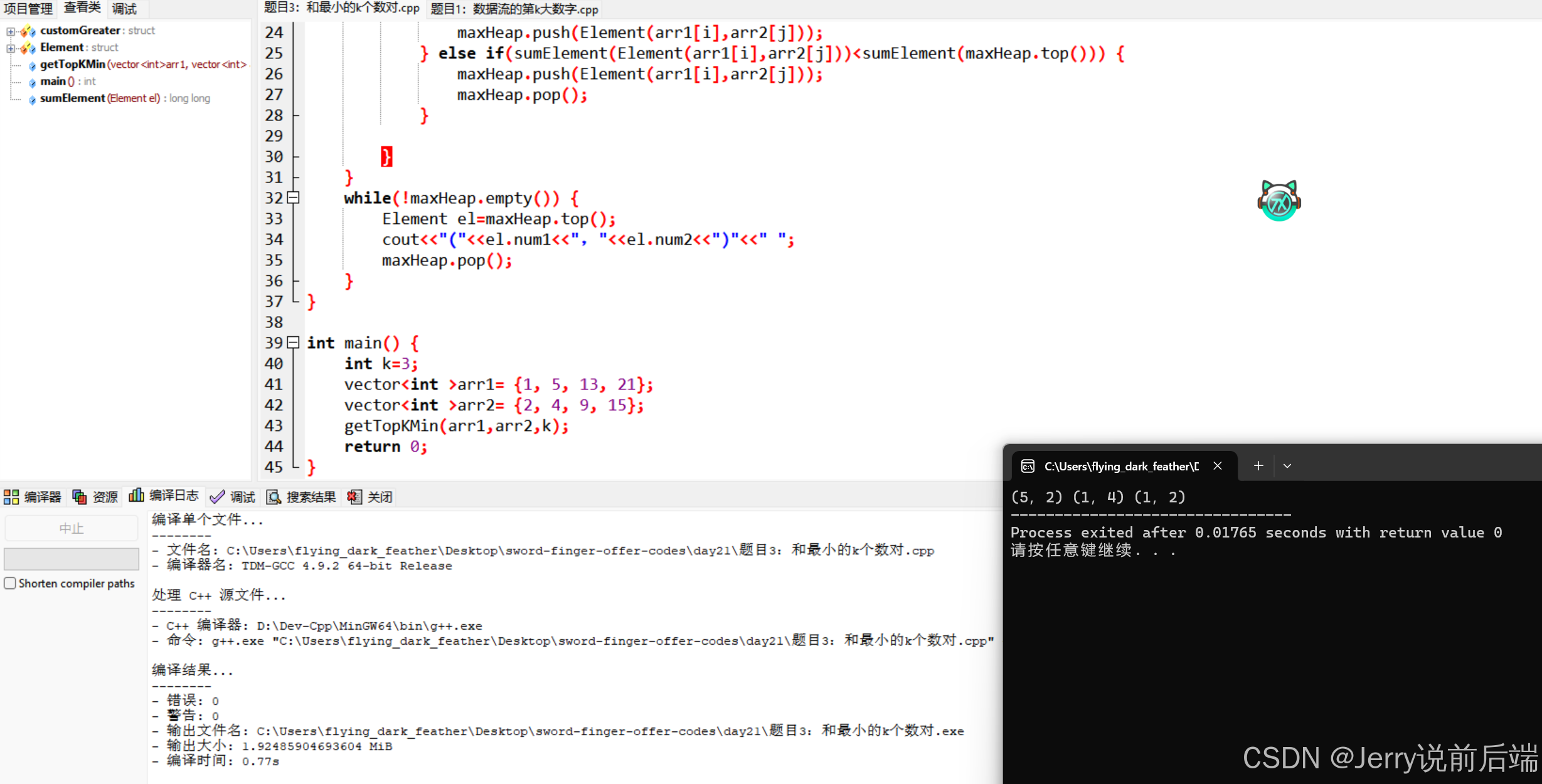
题目:给定两个递增排序的整数数组,从两个数组中各取一个数字u和v组成一个数对(u,v),请找出和最小的k个数对。例如,输入两个数组[1, 5, 13, 21]和[2, 4, 9, 15],和最小的3个数对为(1,2)、(1,4)和(2,5)。
由分析可知,这里的依旧可以按照题目一的方式来统计,由于k的数值不确定,可能k的值比较大,包括了两个数组中的所有可能。因此需要遍历两个数组的所有组合。需要考虑一个问题,这样的数对是否可能重复,比如两个数组分别为:[1,2,3]和[1,2,3],两个数组都满足严格递增,答案是否定的,可以利用一个数组作为参照,比如这里固定第一个数组的第一个元素,扫描后面数组的所有元素构成组合,可以得到3种情况,之后偏移第一个数组的指向元素。由于这个过程中得到的数对第一个元素递增,并且在相同第一个元素下,第二个元素同样满足递增,因此最终所有可能的数对不可能重复。结合题目一,这里可以先构建一个大小为k的大根堆,如果一个元素小于根节点,那么说明这个元素需要应该进入k大根堆种替换,最终可以得到如下代码:
void getTopKMin(vector<int>arr1,vector<int> arr2,int k) {map<int,vector<Element>> numMap;priority_queue<Element,vector<Element>,customGreater> maxHeap;int size1=arr1.size(),size2=arr2.size();for(int i=0; i<size1; ++i) {for(int j=0; j<size2; ++j) {cout<<"当前探测:"<<arr1[i]<<" "<<arr2[j]<<endl;if(maxHeap.size()<k) {maxHeap.push(Element(arr1[i],arr2[j]));} else if(sumElement(Element(arr1[i],arr2[j]))<sumElement(maxHeap.top())) {maxHeap.push(Element(arr1[i],arr2[j]));maxHeap.pop();}}}while(!maxHeap.empty()) {Element el=maxHeap.top();cout<<"("<<el.num1<<","<<el.num2<<")"<<" ";maxHeap.pop();}
}
另外这里对于C++可以积累一个自定义节点的优先级队列构建方法,还能够自定义优先级队列的大根堆、小根堆比较方法:
struct Element {int num1;int num2;Element(int a,int b):num1(a),num2(b) {}
};
long long sumElement(Element el) {return el.num1+el.num2;
}
struct customGreater {bool operator()(Element a, Element b) const {return sumElement(a) < sumElement(b);}
};
//用法
priority_queue<Element,vector<Element>,customGreater> maxHeap;
附录:源码gitee仓库
考虑到有些算法需要模拟数据,如果全部放进来代码显得过长,不利于聚焦在算法的核心思路上。于是把所有的代码整理到了开源仓库上,如果想要看详细模拟数据,可在开源仓库自取:【凌空暗羽/剑指Offer-C++版手写代码】。
我是【Jerry说前后端】,本系列精心挑选的算法题目均基于经典的《剑指 Offer(数据结构与算法面试题精讲)》。在如今竞争激烈的技术求职环境下,算法能力已成为前端开发岗位笔试考核的关键要点。通过深入钻研这一系列算法题,大家能够系统地积累算法知识和解题经验。每一道题目的分析与解答过程,都像是一把钥匙,为大家打开一扇通往高效编程思维的大门,帮助大家逐步提升自己在数据结构运用、算法设计与优化等方面的能力。
无论是即将踏入职场的应届毕业生,还是想要进一步提升自身技术水平的在职开发者,掌握扎实的算法知识都是提升竞争力的有力武器。希望大家能跟随我的步伐,在这个系列中不断学习、不断进步,为即将到来的前端笔试做好充分准备,顺利拿下心仪的工作机会!快来订阅吧,让我们一起开启这段算法学习之旅!