Pycharm(十七)生成器
一、生成器介绍
1.1 概述
生成器指的是Generator对象,它不再像以往一样,一次性生成所有的数据,而是用一个,再生成一个,基于用户写的规则(条件)来生成数据,如果条件不成立,则生成结束。
1.2 实现方式
方式1:推导式;
方式2:yield关键字实现。
1.3 名词解释:迭代
迭代指的是 逐个的从容器类型中获取每一个元素的过程,称之为:迭代(遍历)
例如:列表,集合,字典,生成器等,都是可以遍历(迭代)的,所以它们也称之为:可迭代对象。
1.4 目的/好处
节约内存资源,减少内存占用。
1.5 如何从生成器中获取数据?
方式1:next()函数
next()函数是移动指针的,获取下一个元素。
方式2:遍历
1.6 示例代码
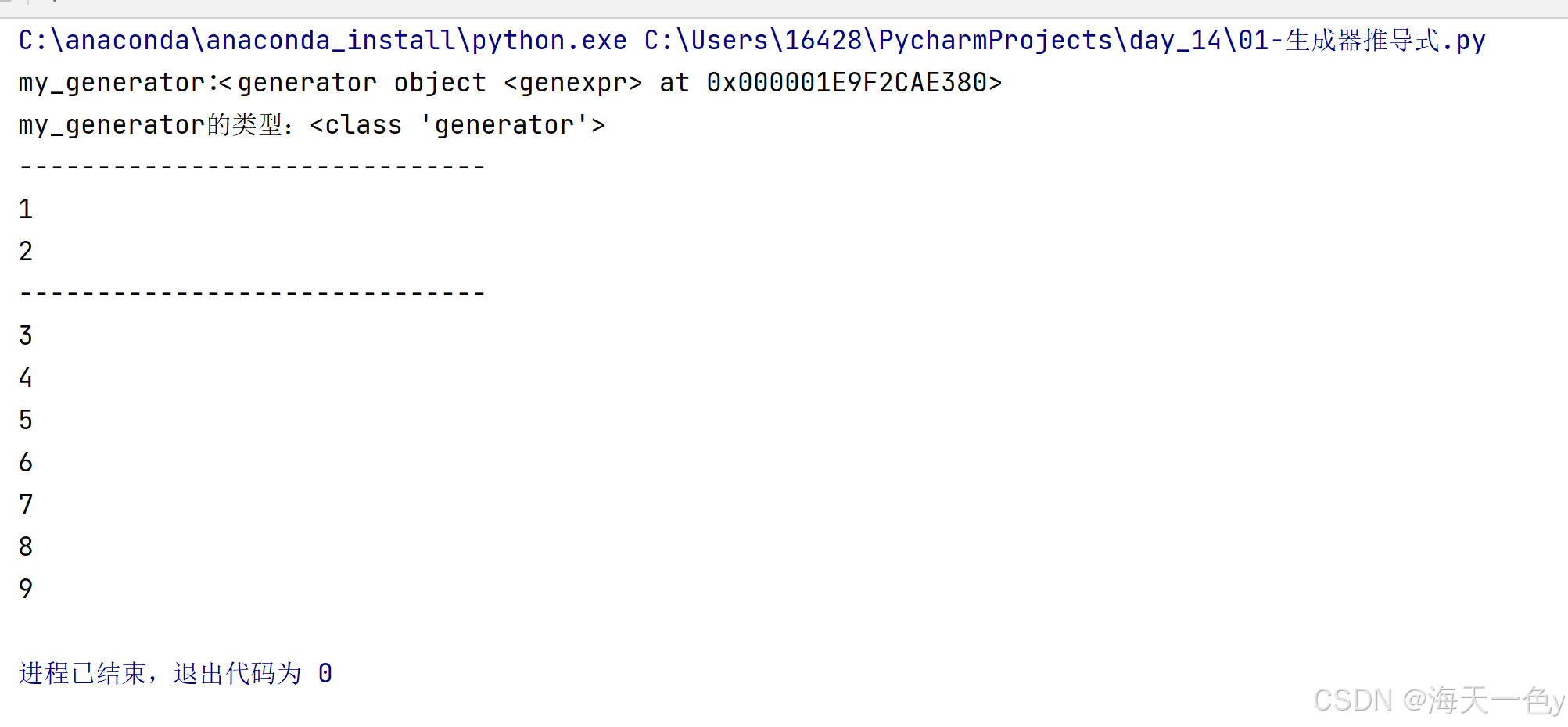
#案例:演示生成器推导式写法,获取生成器对象。
if __name__ == '__main__':#1.生成器写法1:推导式写法my_generator=(i for i in range(1,10))print(f'my_generator:{my_generator}')print(f'my_generator的类型:{type(my_generator)}')print('-'*30)#2.生成器不是一下生成所有的数据,二十用一个再生成1个#如何从生成器中获取数据?#1.next()函数 2.for循环遍历#方式1.next()函数#next()是移动指针的,获取下一个元素print(next(my_generator))#1 range(1,10) 1->2print(next(my_generator))#2 2->3print('-'*30)for i in my_generator:#print(i)
运行结果:
二、yield关键字介绍
概述:
yield可以创建生成器对象,逐个地把每个元素放到生成器对象中,函数结束时,返回生成器对象。
示例代码:
'''
yield写法示例
'''
#需求:获取1~10之间的整数,生成器写法。
#1.定义函数,获取:生成器对象
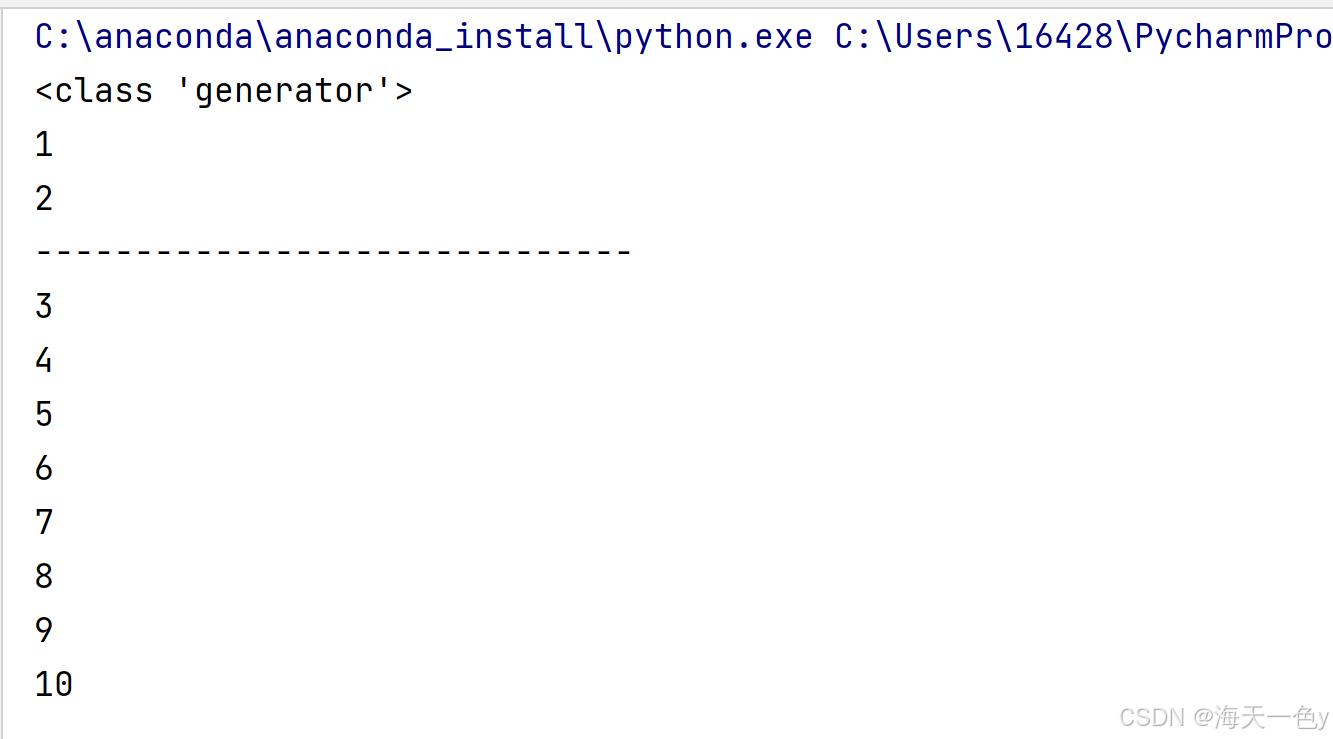
def get_generator():#yield写法,返回的是生成器对象for i in range(1,11):yield i
#2.测试上述代码
if __name__ == '__main__':#3.调用函数,获取生成器对象my_generator=get_generator()print(type(my_generator))#4.从生成器对象中,获取数据#方式1.next()函数print(next(my_generator))# 1print(next(my_generator))# 2print('-'*30)# 方式2.遍历for i in my_generator:print(i)运行结果:
三、生成器案例
案例
自定义数据迭代器,按照指定的条数生成批次数据。在AI模型的训练过程中,是把数据分批次喂给模型的,而不是一次性投喂。
需求:
自定义数据迭代器(dataloader),实现根据指定的数据条数,获取每批次的数据。
示例代码:
import math
#math.ceil()函数,获取天花板数,即:比这个数字大的所有整数中,最小的那个整数
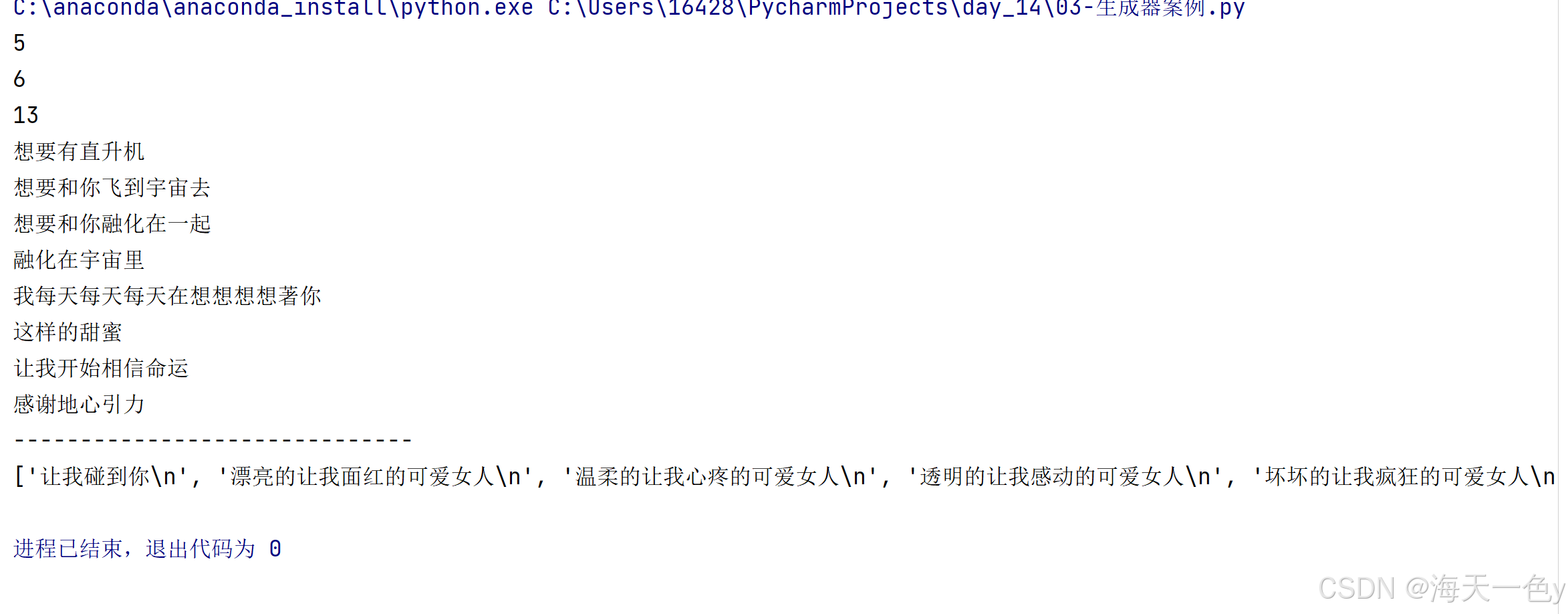
print(math.ceil(5)) #5
print(math.ceil(5.1))#6
print(math.ceil(100/8))#13
def dataset_loader(batch_size):'''自定义函数,获取批次数据:param batch_size: 每批次数据的条数:return: 生成器对象,每个数据=1批的数据'''#1.读取源文件,获取到所有的数据with open('./jaychou_lyrics.txt','r',encoding='utf-8') as src_f:#一次性读取所有的行,并放到列表里.list_data=src_f.readlines()#2.获取数据的总条数.line_count=len(list_data)#3.根据数据的总条数,结合每批次的数据条数,计算:总批次数.batch_count=math.ceil(line_count/batch_size)#4,遍历 总批次数,获取到:每个批次的 编号,然后生成:该批次的数据.for batch_idx in range(batch_count):'''推理过程:假设batch_size=8,batch_count=13,即:13批,8条/批,则:batch_idx=0,代表第1批数据,数据为:第1条~第8条,[0:8]batch_idx=1,代表第2批数据,数据为:第9条~第16条,[8:16]batch_idx=2,代表第3批数据,数据为:第17~24条,[16:24]...'''yield list_data[batch_idx*batch_size:(batch_idx+1)*batch_size]
if __name__ == '__main__':#5.获取生成器对象.data_loader=dataset_loader(batch_size=8)#6.获取第1批次的数据.batch_data1=next(data_loader)for line in batch_data1:print(line,end='')print('-'*30)print(next(data_loader))运行结果:
 下期继续分享~
下期继续分享~