C++笔记-模板进阶和继承(上)
一.模板进阶
1.1非模板类型参数
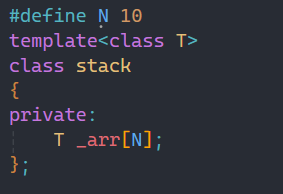
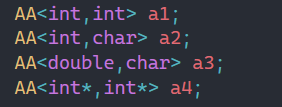
那之前学过的stack举例,在这之前我们如果要用N,就要用宏来定义,但是宏毕竟有局限性:

如果我要用到两个stack,一个要求10个空间,另一个要求100空间呢?
这时候有人可能会说把N定义为100不就行了。
确实,这样能解决当前的问题,但是会不会造成浪费?第一个stack是不是就浪费了90个空间。
所以为了解决这种问题,就引入了非模板类型参数:
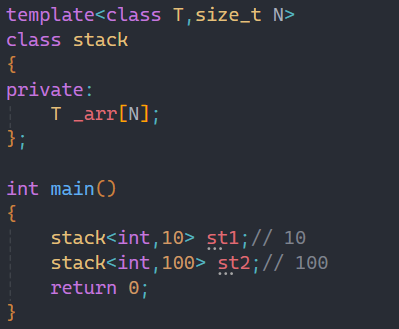
这样就可以完美解决这个问题,需要多少空间我就开多少空间,就避免了浪费的问题。
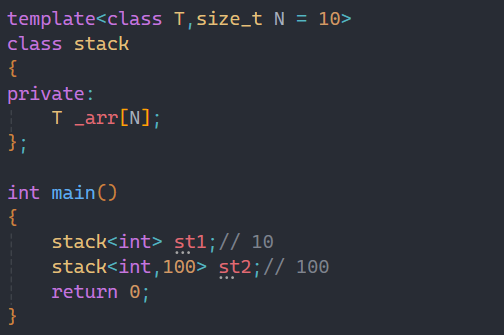
当然,也是可以给缺省值的。
那么哪里会用到这种用法呢?

在C++11中引入的容器array就需要用到这种方式,那么这个容器是干什么的呢?

这东西和我们平常用的静态数组差不多,底层也是一个数组。
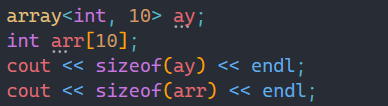
就连两个数组的大小也是一样的,基本没什么区别。

但是array是不允许你对数组进行修改,包括我们之前学的头部,尾部和中间的插入和删除,只能访问其中的数据,并且array并不会对数组中的数据进行初始化:
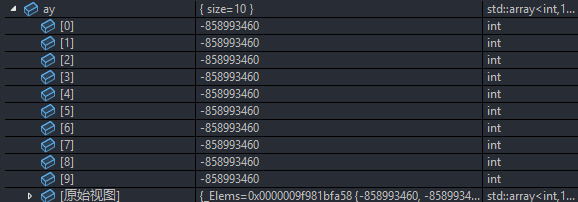
通过调试可以看出数组中的数据对视随机值。
这个容器呢用的不多,原因相信大家都知道:我有更好用的vector为什么不用呢?
那么array具体和我们日常用的静态数字有什么区别呢?
体现在越界的读和写方面:
在上面的代码中,很明显我们越界访问了,但是静态数组的越界读是不检查的,所以程序并不会报错。
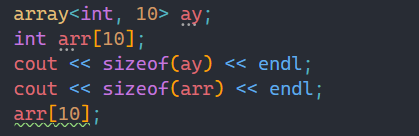
![]()
![]()

而静态数组的写是抽查,可能越界几个会检查出来,后面就不一定检查出来。
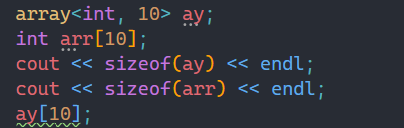
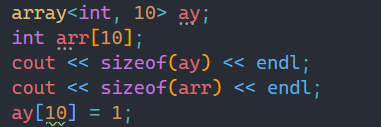
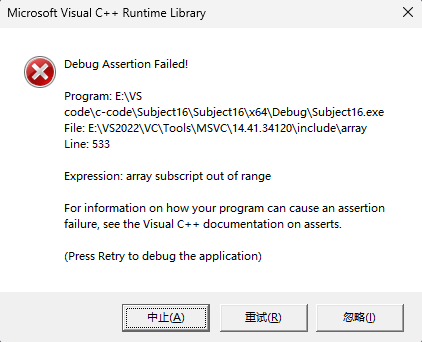
而array的读和写都会检查,一旦出现越界访问,就会因为断言而报错。
最后目前非模板类型参数一般只支持整型,最新的编译器会支持double等类型,像自定义类型都是不支持的。
1.2特化
1.2.1概念
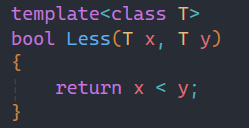
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能胡得到一些错误的结果,需要特殊处理,比如:是西安一个串门用来比较的函数模板:
1.2.2函数模板特化
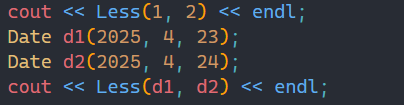
那我们之前写过的Date类举例,此时我们传过去来比较两个日期的大小事没有问题的。
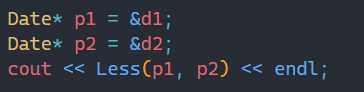

此时结果就出现错误,因为我们是用地址进行比较的,用地址去比较不是我们想要的,那么此时就需要用到特化:
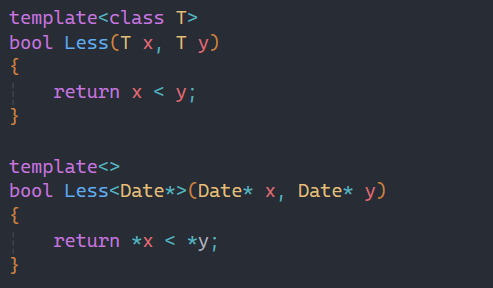
这就是特化的基本应用,下面是特化的基本格式:
1.必须先有一个基础的函数模板
2.关键字template后面接一对空的尖括号<>
3.函数名后跟一对尖括号,尖括号中指定需要特化的类型
4.函数形参表:必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误
看到这些规则是不是感觉特化很麻烦,还有更坑的地方:
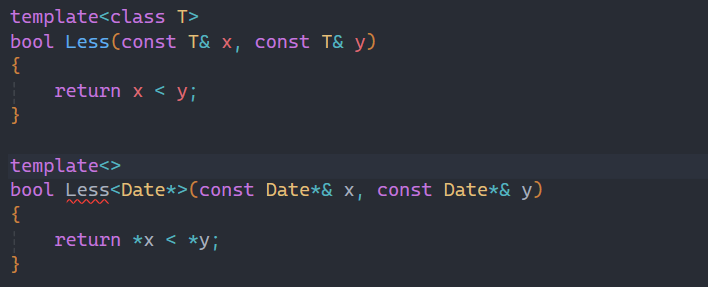
![]()
是不是感觉很奇怪,明明参数都是照着上面写的,却还是报错了。
其实这里出错的原因是:上面的const修饰的是x和y,而下面的const修饰的是*x和*y,导致类型不同报错。
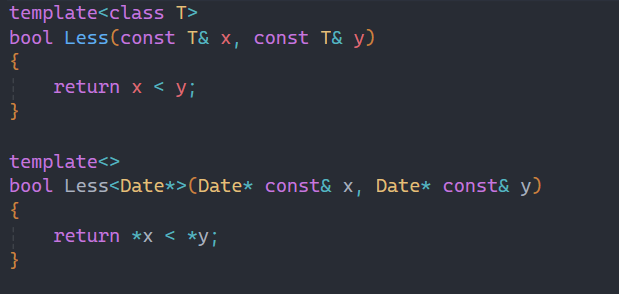
只有写成这样才是正确的,如果使用特化这里很容易出问题,而且问题还不好发现。
并且特化的这个功能完全可以自己在写一个函数,构成函数重载,也不用遵循那么多规则:
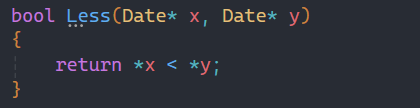
这样写更为简洁,也更好理解,所以特化在实际应用中用的并不多。
1.2.3类模板特化
1.全特化
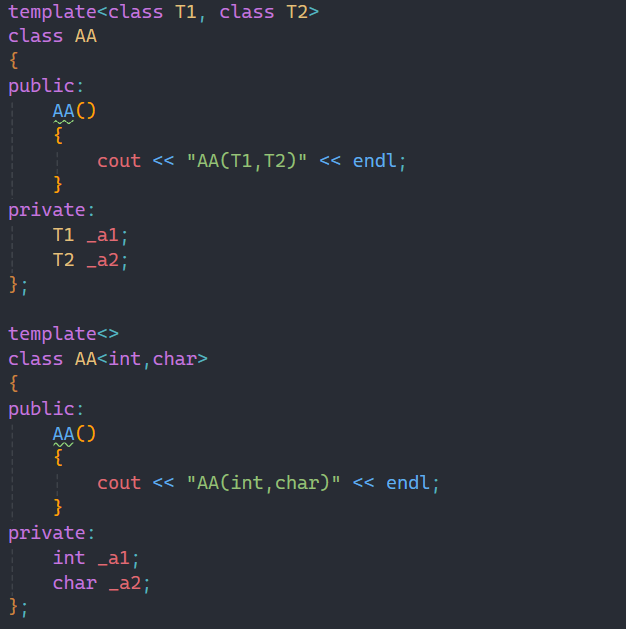
这就是全特化的类模板,也就是将所有的参数进行特化,只有传固定类型的参数才能进入到特化后的类模板。
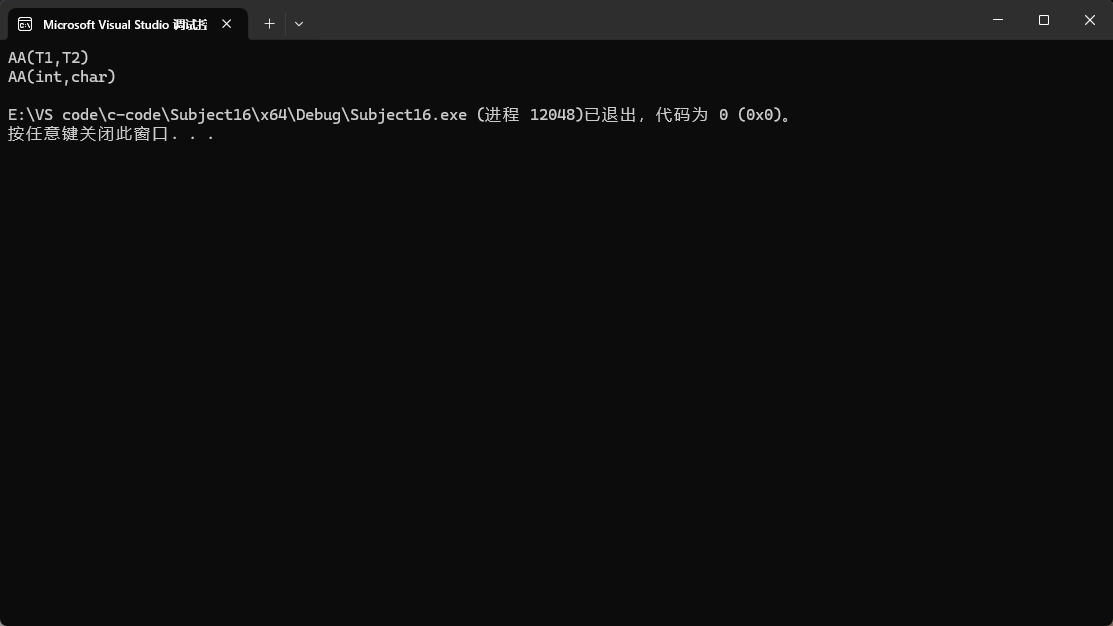
从输出结果也可以看出传不同参数调用的是不同的类模板。
2.偏特化/半特化
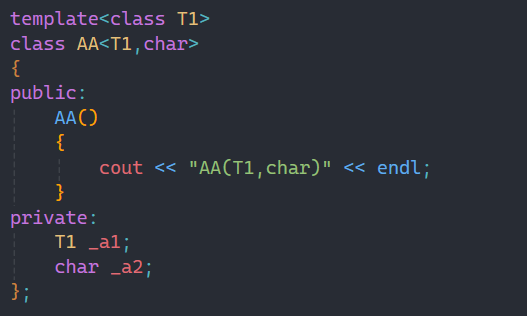
偏特化又叫半特化,顾名思义就是只特化部分类型,如上面这个所示:只要第二个参数类型是char就能进入到这个类里面。
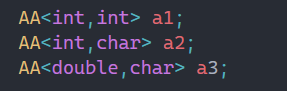
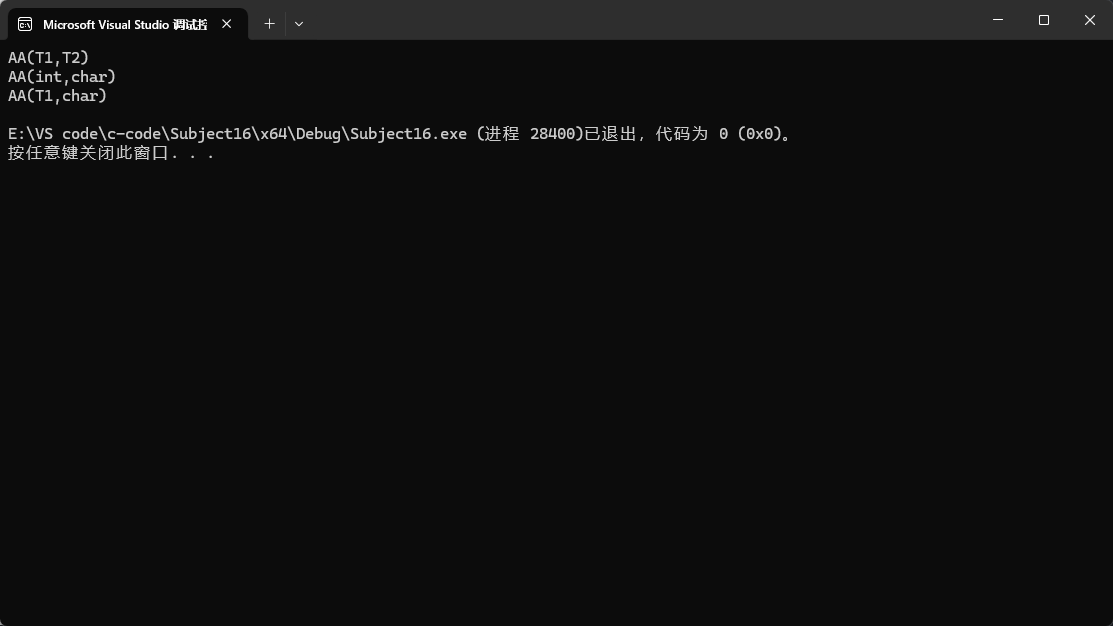
而偏特化还有一种玩法:
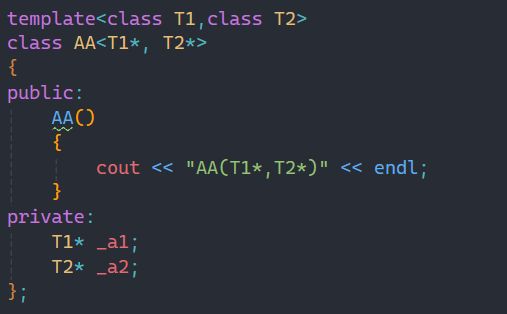
这种玩法的意思就是我不限制你传的参数的类型,但是我要求你传过来是的当前类型的指针才能进入。
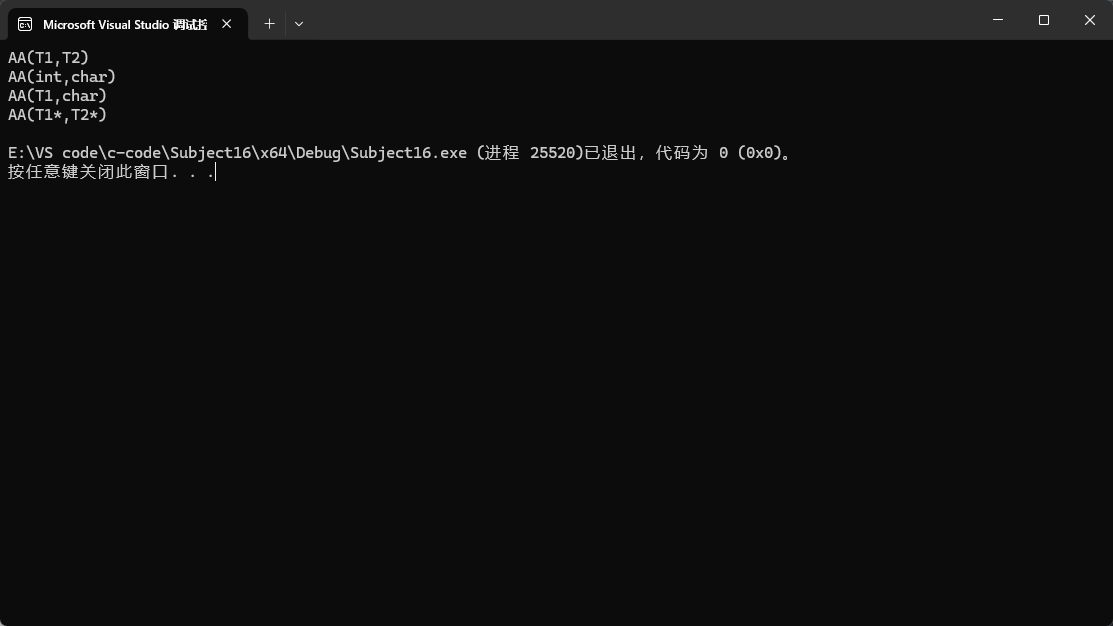
这种玩法也可以解决一种问题:
就比如上篇我们所讲的priority_queue,如果像这样我有的传Date*,有的传int*,那比较的都是地址,这种比较是没有意义的。
但是如果又不想写那么多仿函数的情况下就可以用这种玩法解决问题。
1.3模板分离编译
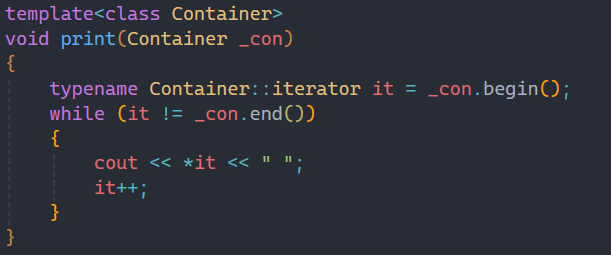
比如我们要写一个函数模板来打印出容器内的数据,正常来讲就是这样写的,而所谓的模板分离编译就如下方所示:
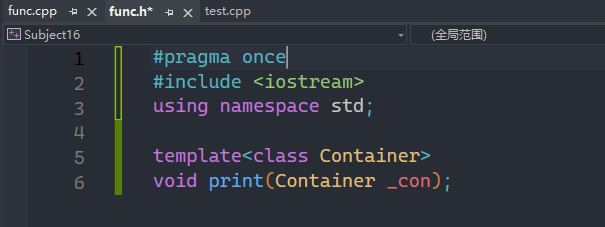
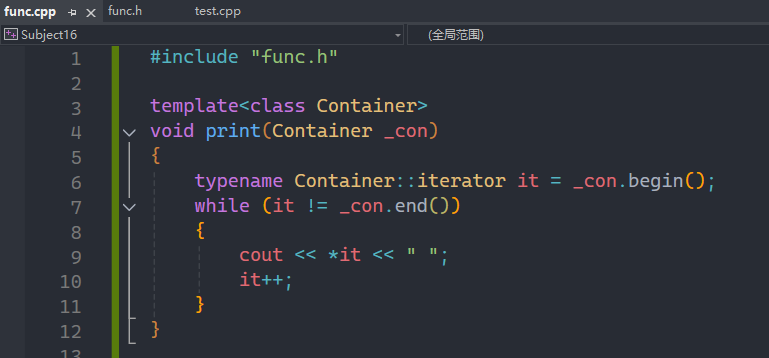
这就是模板的分离编译,声明在头文件,定义在c++文件,那么为什么把这个单独拿出来讲呢?
因为这样写是不对的,会出现链接错误:


这就是链接错误,这玩意儿报错你是看不懂的,那么为什么会报链接错误呢?
这里因为涉及到编译链接的知识,如果要细讲的话会扯出一大堆知识,所以这里我就简单来讲,毕竟这个知识点没那么重要,作为了解的知识即可。
根本原因就是没有实例化,编译阶段调用时知道实例化的是什么,但是只限于声明,此时定义并不知道实例化的是什么,就无法生成相应函数的指令,所以我们在调用时链接阶段发现定义没有实例化,就会报链接错误。
所以在写模板时尽量都把定义和声明写在同一个文件中,这样编译阶段声明和定义都知道实例化的是什么,就可以生成对应函数的指令。
那么如果非要声明和定义分离呢?
也是有解决方法的:
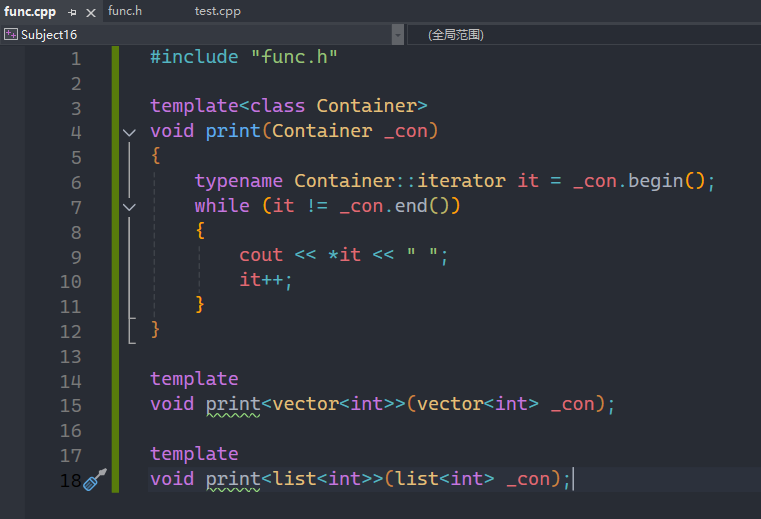
就是在定义的地方直接指明我要实例化的是什么,这样就可以解决问题,具体格式就如上图所示。
但是为什么不用这种方式呢?
设想如果我们要用的很多容器,并且一个容器中的数据还有不同类型,那是不是我们调用一个就要写一个这样的代码,那不是很麻烦吗?
所以在实际应用中,不要对模板进行分离编译。
再讲一个知识点:大家看到我在上面调用容器的迭代器之前写了typename关键字,这种方式是在告诉编译器我这里是类型,否则编译器不知道Container是什么,就会报错。
适用的场景就是模板在调用内嵌类型时要在类型前加上typename,就比如容器。
最后对模板进行一个总结
优点:
1.模板复用了代码,节省资源,更快的迭代开发,c++标准模板库(STL)因此而产生
2.增强了代码的灵活性
缺点:
1.模板会导致代码膨胀问题,也会导致编译时间变长
2.出现模板编译错误时,错误信息非常凌乱,不易定义错误(就如上面分离编译时报的错误)
二.继承
我们知道c++面向对象的三大特性:封装,继承和多态,接下来就要讲解第二大特性继承的相关知识。
2.1继承的定义
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许我们在保持原有类特性的基础上进行扩展,增加方法(成员函数)和属性(成员变量),这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的函数层次的复用,继承是类设计层次的复用。
继承理解起来也很简单,就比如说有人努力学习,最会父母告诉他自己家是亿万富翁,让他不用努力了,回家继承家业。
在c++中的继承和这个概念差不多,就是一个类继承了另一个类的内容。
那为什么要有继承这个东西呢?
就比如学校有学生,老师,保安和食堂阿姨,学校要统计他们的信息,除了一样要统计的姓名和年龄等,但是不同的身份也会有区别与其他人的信息,比如学生的学号,老师的职称等,这些东西我们如果都写在一个里面内容就太多了,这时就可以用到继承:
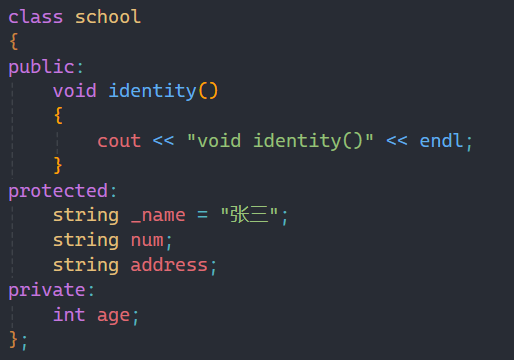
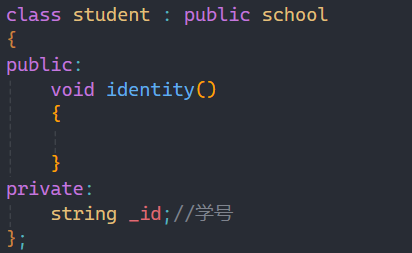
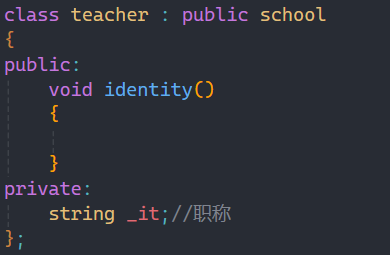
这就是继承的基本格式,要在类名后加:,再加上是什么类型的继承,最后加上要继承的类。
上面的school称为父类或者基类,下面的student和teacher称为子类或者派生类。
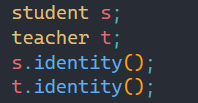
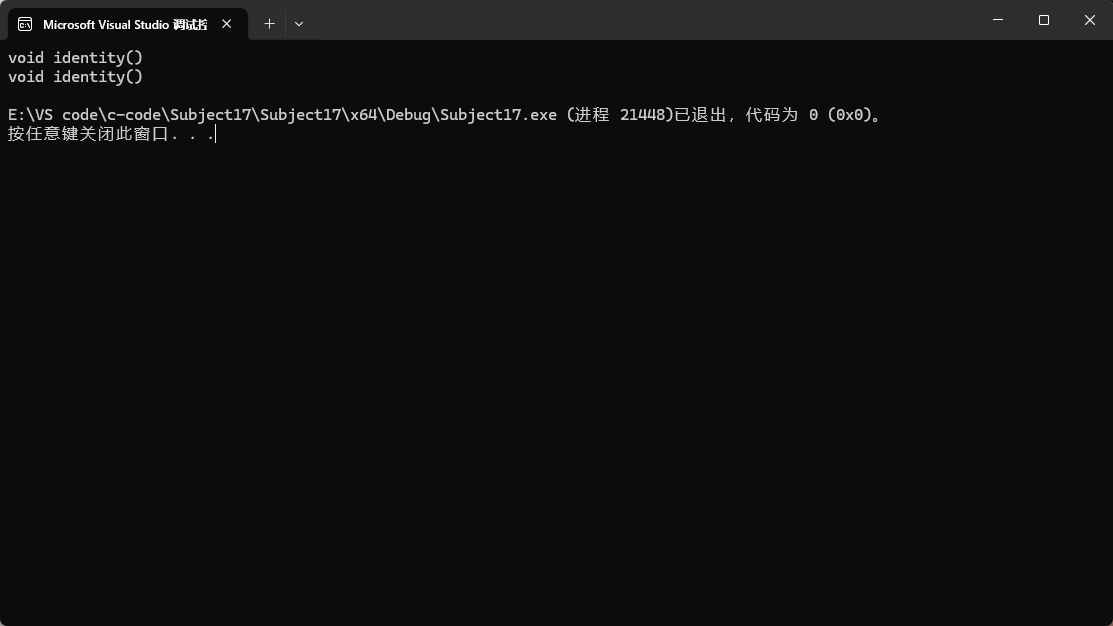
继承之后就可以调用父类的内容,至于能调用那些内容,就和下面的知识有关。
2.2继承基类成员访问方式的变化
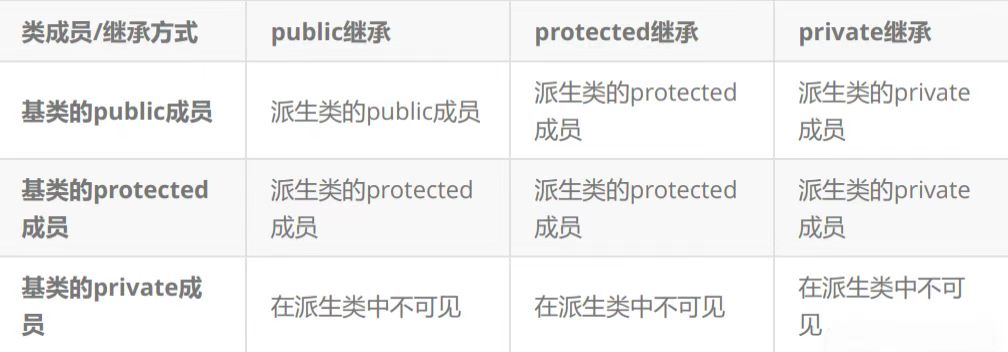
1.基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
2.基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
3.实际上面的表格我们进行一下总结会发现,基类的私有成员在派生类都是不可见。基类的其他成员在派生类的访问方式==Min(成员在基类的访问限定符,继承方式),public>protected > private。
4.使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显示的写出继承方式。
5.在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用
protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。
父类的各种类型成员和子类继承的方式合在一起总共有9种方式。
之前我们虽然提到了protected,但是从来没有用过,而在继承这里就要用,并用于区分。
先讲第一条:关于父类的private成员,不管你是什么继承方式都是子类和类外无法访问的,这就像每个人都有自己的隐私,你的父母也有自己的隐私,隐私当然是不能被其他人看的。
但是也不是说一定没法用,不能直接使用,那就间接使用就行:


可以在父类public中定义一个函数来返回private中的变量,在访问这个函数即可实现间接访问。
第二条就涉及到我们未讲的protected,和private不同的是,protected的成员在子类是可以访问的,但在类外不能访问。
第三条的意思是取继承方式和父类成员权限的较小值,这里权限只是一种说法,后面就是权限的大小关系,取其中的较小值后父类的成员或者函数就变成子类中的相应权限的成员和函数。
第四条:
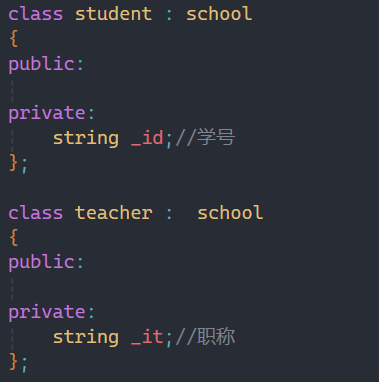
class如果不写具体的继承方式,就默认是private继承,相应的struct就是public继承。
第五条为什么protected和private很少用呢?
因为继承不就是让你用吗,不让用我继承你干嘛,话糙理不糙,大概就是这么个道理。所以我们呢一般使用public继承,这样继承之后在子类中的权限和父类就能保持一致,不会出现权限的变化。
2.3继承类模板
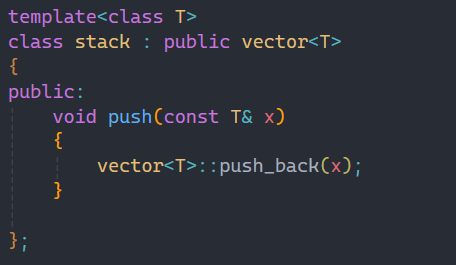

模板当然也是可以继承的,这里就以继承vector为例。如果要使用继承类模板,就要在要使用的函数前加上类域,否则就会报下面的错误:
![]()
找不到标识符其实也是没有实例化的结果,当stack<int>实例化时,vector<int>也实例化了,但是模板是按需实例化,push_back等函数并没有实例化,所以就会报这种错误。
这个也当一个了解的知识即可,想必大家也都能看出来使用起来是没有我们之前的用法方便的,所以用的也很少。
2.4基类和派生类之间的转换
1.public继承的派生类对象可以赋值给基类的指针/基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中基类那部分切出来,基类指针或引用指向的是派生类中切出来的基类那部分。
2.基类对象不能赋值给派生类对象。
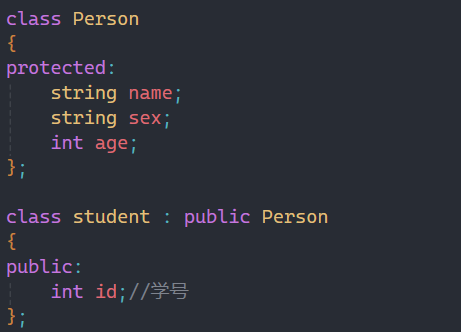
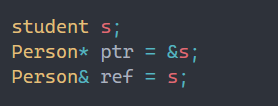
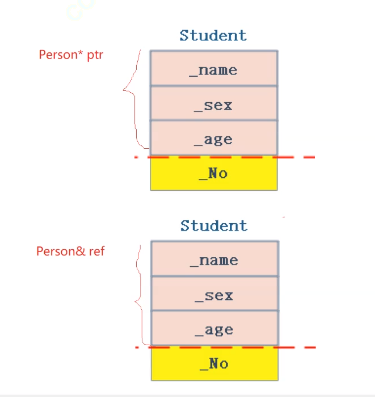
形象一点如上图所示,父类取得只是父类中含有的那一部分,也就相当于把子类给切割了,注意是public继承,如果是其他继承方式,就会报错:
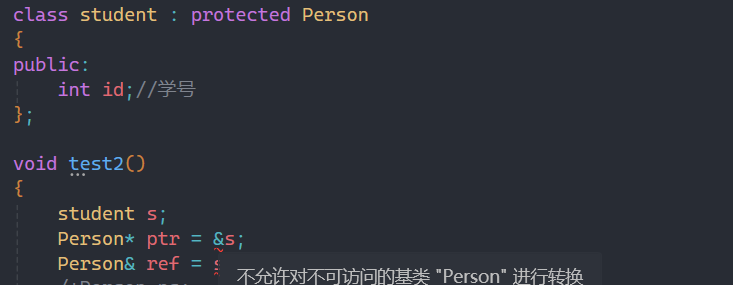
当然也正如第二条所说,父类对象是不能赋值给子类的,因为子类有的父类没有,不但没法切割还少东西。

![]()
就会报这种错误,并且强转也不行:

基类和派生类之间的转换涉及到我们之前学的隐式类型转换,正常来讲,不同类型的成员在赋值时会产生临时对象,这也是产生临时对象的三种情况之一,但是在积累和派生类之间进行转换时是不会产生临时对象的。
这也就是为什么上面引用没有加const也能通过的原因。
2.5继承中的作用域
隐藏规则:
1.在继承体系中基类和派生类都有独立的作用域。
2.派生类和基类中有同名成员,派生类成员将屏蔽基类对同名成员的直接访问,这种情况叫隐藏。
(在派生类成员函数中,可以使用基类::基类成员显示访问)
3.需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
4.注意在实际中在继承体系里面最好不要定义同名的成员。
第一条大家都耳熟能详,不同的类代表不同的作用域,也就能存在同名成员和同名函数。
第二条我用下面的例子来说明:
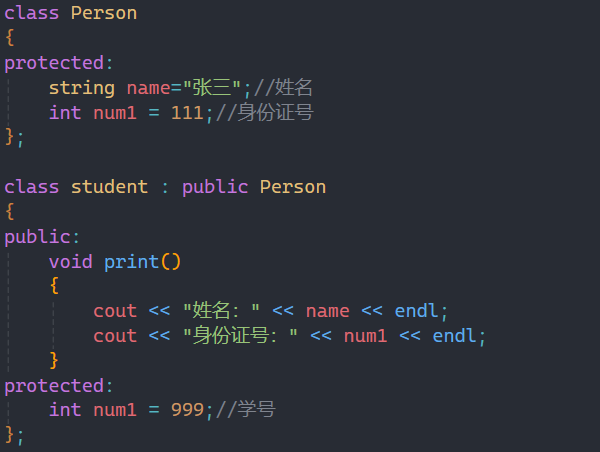
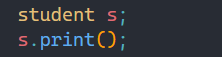
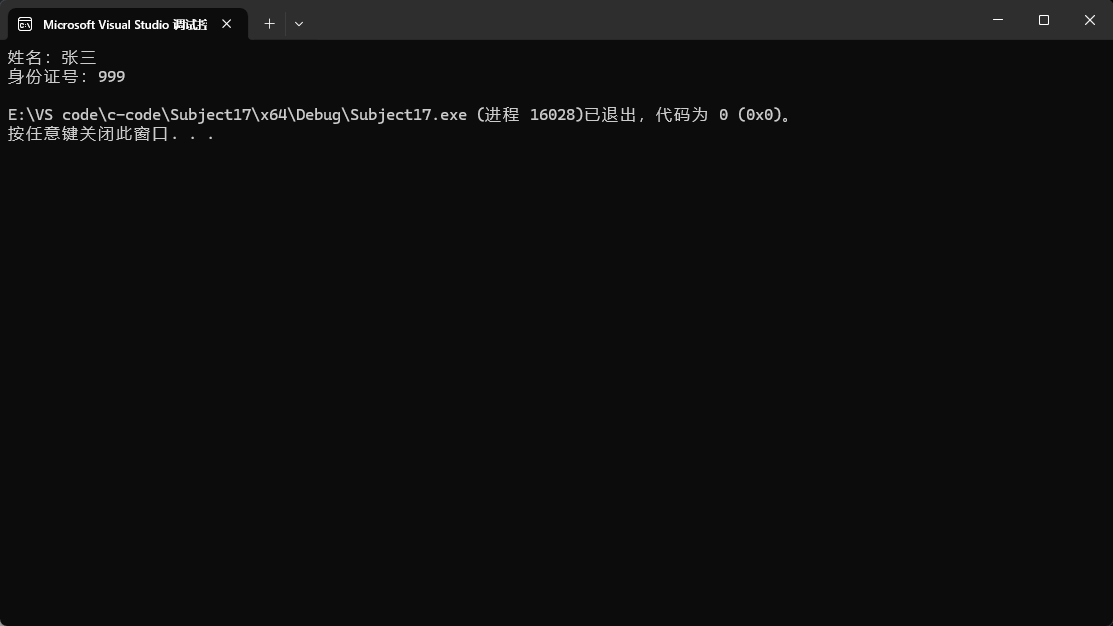
在上面的例子中,父类和子类中都有num1成员变量,但我们通过结果可知,输出的并不是父类中的num1,而是子类中的num1,此时就是子类把父类的同名成员给隐藏了。
而我们如果想要访问父类的num1,就要指定类域:
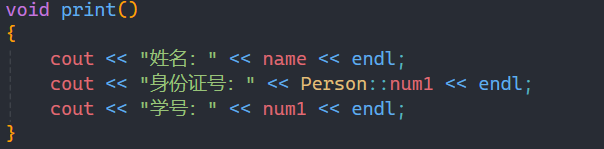
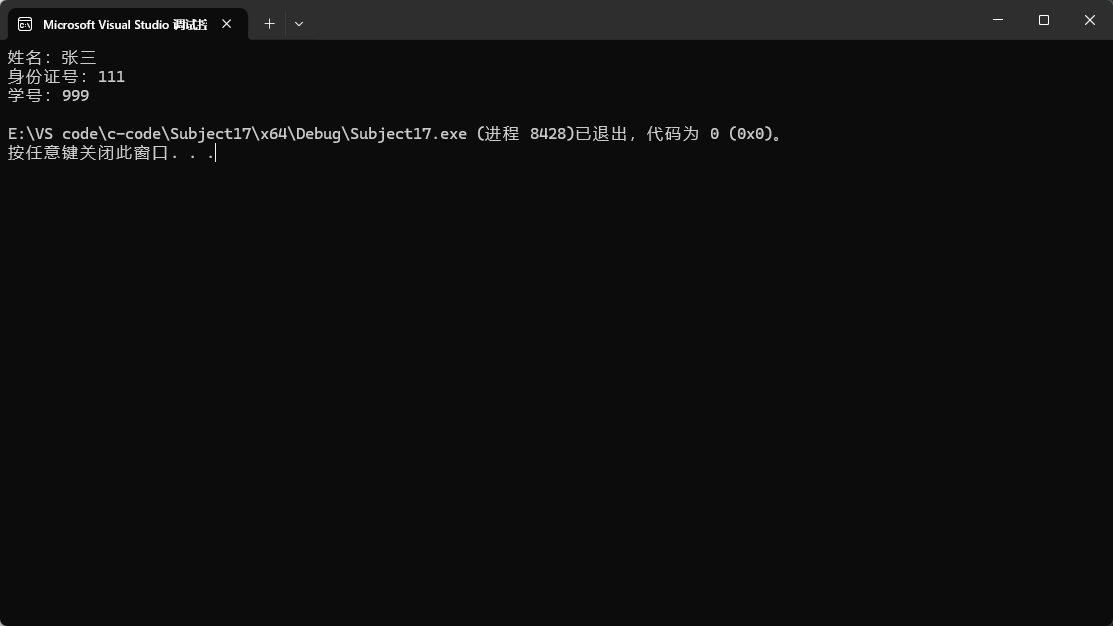
指定类域后,就可以访问相应的成员变量。
而第三点呢,我们先来看一道题:

1.A和B类中的func函数构成什么关系?
A.重载 B.隐藏 C.没关系
大家可以思考一下这个问题的答案。
答案选择B,可能有人会觉得这不就是函数重载吗,函数名相同,参数不同。
如果是同一作用域,确实如此,但是这是在不同的作用域,正如第三条所说,在继承中,同名函数只要名字相同就会隐藏。
我们再看一题:
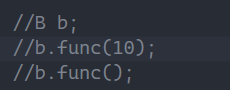
2.此时如果取消注释代码会出现什么问题?
A.编译错误 B.运行错误 C.正常运行
大家可以思考一下这个问题的答案。
答案选择A,这里因为子类的func对父类的func进行隐藏,所以父类的不需要传参的func就不能使用,所以程序就会报错:
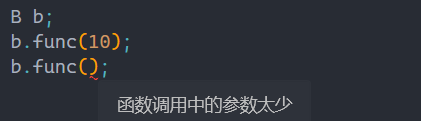
而想要访问的方法和上面一样,指定类域即可:
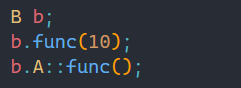

此时代码就没有问题了。
最后就如第四条所说,最好不要定义同名成员和函数,即使真的定义了,也要遵守对应的规则进行访问。
以上就是模板进阶和继承(上)的内容。