《C和C++安全编码》课程笔记——第六章 并发
一、多线程
核心特性
- 共享内存空间:同一进程内的线程共享代码段、数据段和堆区
- 轻量级切换:创建/销毁开销远小于进程(Linux线程切换成本约1-2μs)
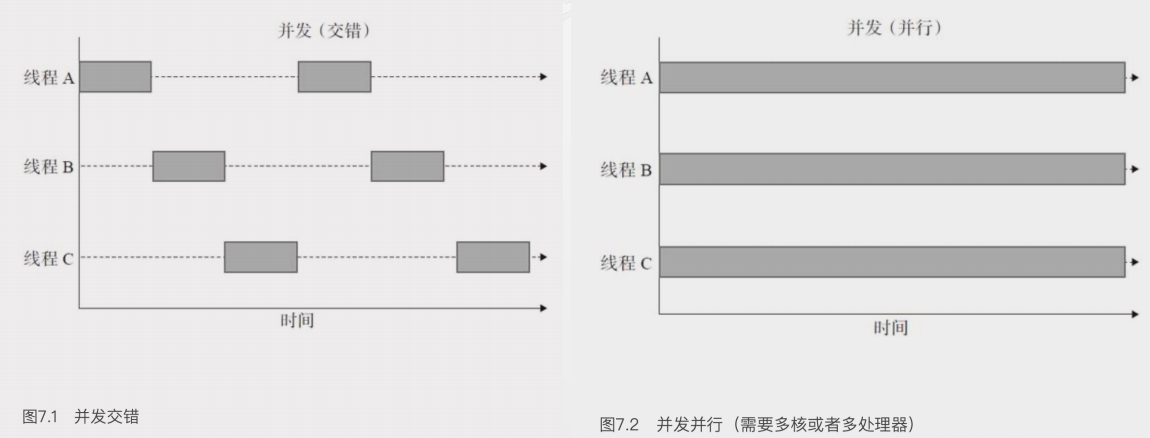
- 并发执行:单核通过时间片轮转(通常10-100ms/次),多核实现真并行
超线程技术
- 单物理核心模拟双逻辑核心(Intel Hyper-Threading)
- 安全风险:可能通过缓存侧信道泄露数据(如Spectre漏洞),云服务器常禁用
单线程并发问题
- 信号处理函数可能打断主线程,导致:
- 数据破坏(如
malloc/free被打断) - 死锁
- 数据破坏(如
- 异步信号安全函数:
write()、_exit()、close()等
二、并行
| 类型 | 定义 | 实现方式 | 示例 |
|---|---|---|---|
| 数据并行 | 相同操作处理数据分块 | SIMD指令(SSE/AVX)、向量寄存器 | 矩阵运算分行处理 |
| 任务并行 | 不同任务由不同线程执行 | 多线程分工协作 | 同时计算均值/最小值 |
编译器优化:
- 向量化(
/Qvec-report):标量→SIMD指令(如SSE2处理4个int) - 并行化(
/Qpar):循环迭代分配到多线程
并行计算模型对比
| 模型 | 数据并行 | 任务并行 |
|---|---|---|
| 划分维度 | 数据分块(同构) | 功能分解(异构) |
| 加速比 | 受Amdahl定律限制 | 受任务依赖关系限制 |
| 硬件利用 | SIMD+多核 | 多核/分布式 |
| 典型场景 | 矩阵运算(OpenMP) | 生产者-消费者模型 |
三、性能目标
1. Amdahl定律量化分析
# 实际测量并行比例P
T_serial = 10.0 # 串行总耗时
T_parallel = 2.0 # 并行总耗时(N=8核)
P = (T_serial - T_parallel) / (T_serial * (1 - 1/8)) # 反推P≈85%2. 工作-跨度模型
- 工作(T₁):单核总执行时间
- 跨度(T∞):最长依赖路径时间
- 并行度:T₁/T∞(最大加速比)
四、常见错误
| 错误类型 | 场景 | 后果 |
|---|---|---|
| 竞争条件 | 多线程无同步修改共享变量(如银行余额) | 数据损坏/安全漏洞 |
| 死锁 | 循环等待锁(线程A持锁1等锁2,线程B反之) | 程序永久阻塞 |
| ABA问题 | 无锁数据结构中值从A→B→A,CAS误判未修改 | 逻辑错误/悬垂指针 |
| 单例模式缺陷 | 双重检查锁因指令重排序返回未初始化实例 | 程序崩溃 |
1. 竞争条件(Race Condition)
- 典型场景:多线程无同步修改共享变量(如银行余额)
- 三要素:
// 伪代码示例if (balance >= amount) { // 竞争窗口开始balance -= amount; // 非原子操作} // 竞争窗口结束
- 后果:数据损坏、安全漏洞(如并发提款导致负余额)
2. 死锁(Deadlock)
- 必要条件(四个必须同时满足):
- 互斥条件
- 持有并等待
- 不可抢占
- 循环等待
// 线程A // 线程Block(mutex1); lock(mutex2);lock(mutex2); lock(mutex1); // 形成循环等待
3. ABA问题
- 无锁数据结构中的典型表现:
CAS操作前: 值A → 被改为B → 又被改回A
CAS操作时: 误判值未被修改
- 风险:悬垂指针、逻辑错误
4. 过早释放锁
{std::lock_guard<std::mutex> lock(mtx);data = new_value; // 受保护操作
} // 锁在此释放
process(data); // 非受保护操作可能访问不一致状态
五、缓解策略
| 机制 | 适用场景 | 示例 |
|---|---|---|
| 原子操作 | 简单变量保护 | std::atomic<int> count; |
| 互斥锁 | 临界区独占访问 | std::lock_guard<std::mutex> lock(mtx); |
| 条件变量 | 线程间事件通知 | cv.wait(lock, []{ return ready; }); |
| 信号量 | 控制资源访问数量 | std::counting_semaphore<10> sem(2); |
| 内存屏障 | 防止指令重排序 | std::atomic_thread_fence(std::memory_order_release); |
1. 原子操作(C++11)
std::atomic<int> counter(0);
counter.fetch_add(1, std::memory_order_relaxed);
2. 锁机制对比
| 机制 | 适用场景 | 示例 |
|---|---|---|
| 互斥锁(std::mutex) | 强独占需求 | std::lock_guard<std::mutex> lk(mtx); |
| 读写锁 | 读多写少 | std::shared_mutex |
| 自旋锁 | 短期等待 | while(lock.test_and_set()); |
3. 条件变量范式
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk, []{ return data_ready; }); // 避免虚假唤醒
4. 内存屏障
std::atomic_thread_fence(std::memory_order_release);
六、缓解陷阱
1. 锁顺序不一致导致的死锁
- 问题本质:多个线程以不同顺序获取相同的锁集合
// 线程1 // 线程2lock(mutex1); lock(mutex2);lock(mutex2); lock(mutex1); // 循环等待
- 解决方案:
- 强制统一锁获取顺序(如按内存地址升序)
- 使用
std::scoped_lock(C++17)自动管理多锁顺序
2. 信号量误用
- 典型错误:
sem.acquire();if (!condition) {return; // 忘记release导致资源泄漏}sem.release();
- 文档建议:
- 采用RAII包装器(如C++20的
std::counting_semaphore) - 确保所有代码路径都释放资源
- 采用RAII包装器(如C++20的
3. 双重检查锁的指令重排序
危险实现:
if (!instance) { // 第一次检查std::lock_guard lk(mtx);if (!instance) { // 第二次检查instance = new Singleton(); // 可能重排序}
}
推荐方案:
- 使用C++11的
std::call_once - 或采用magic static模式:
static Singleton& getInstance() {static Singleton instance; // 线程安全初始化return instance;
}
4. 过早释放锁
{std::lock_guard lk(mtx);data = new_value; // 受保护操作
} // 锁在此释放
process(data); // 非原子操作可能访问不一致状态
- 扩展锁作用域至完整逻辑单元
- 使用
std::adopt_lock策略管理复杂锁生命周期
5. 原子操作误用
- 常见错误:
std::atomic<int> x, y;
x.store(1); // 内存序不明确
y.load(); // 可能看到乱序执行
显式指定内存序:
x.store(1, std::memory_order_release);
y.load(std::memory_order_acquire);
- 避免混合使用不同内存序的原子操作
6. 条件变量虚假唤醒
- 错误处理:
cv.wait(lock); // 可能因系统信号意外唤醒
标准范式:
cv.wait(lock, []{ return data_ready; }); // 添加谓词检查
7. ABA问题缓解
| 方案 | 实现方式 | 适用场景 |
|---|---|---|
| 版本号标记 | std::atomic<pair<ptr, version>> | 无锁数据结构 |
| Hazard Pointer | 延迟释放内存机制 | 内存敏感型应用 |
| 引用计数 | std::shared_ptr | 共享所有权模型 |
| 锁机制 | std::mutex | 简单场景(牺牲性能) |
| 特性 | 原子操作 (std::atomic) | 互斥锁 (std::mutex) | 条件变量 (std::condition_variable) | 信号量 (std::counting_semaphore) | 内存屏障 (std::atomic内存序) |
|---|---|---|---|---|---|
| 并发线程数 | 无限制(依赖硬件原子指令) | 1(独占) | 需配合互斥锁使用 | N(由初始计数值控制) | 无直接限制(控制指令顺序,非线程数) |
| 主要用途 | 无锁编程、简单共享变量 | 保护临界区 | 线程间事件通知/等待条件满足 | 资源池管理、流量控制 | 防止指令重排序,保证内存可见性 |
| 灵活性 | 仅限简单操作(需硬件支持) | 必须由加锁线程解锁 | 必须与unique_lock配合 | 可由任意线程释放 (release()) | 需显式指定内存序(如 relaxed, seq_cst) |
| 性能开销 | 极低(CPU原子指令) | 中等(系统调用/上下文切换) | 高(涉及线程阻塞/唤醒) | 中等(计数器原子操作) | 极低(编译器/CPU指令约束) |
| 线程阻塞 | 无(CAS可能自旋) | 是(未获锁时阻塞) | 是(wait()主动阻塞) | 是(acquire()时可能阻塞) | 无 |
| 典型场景 | 计数器、标志位 | 临界区数据保护 | 生产者 - 消费者模型 | 连接池/限流 | 无锁数据结构、跨线程同步 |
| C++标准 | C++11 | C++11 | C++11 | C++20 | C++11 |
| 底层实现 | CPU原子指令(如x86 LOCK XADD) | 操作系统级互斥(如futex) | 依赖互斥锁+线程调度 | 原子计数器+线程阻塞队列 | CPU内存屏障指令(如x86 MFENCE) |
七、著名的漏洞
1. Therac-25医疗事故(1985)
- 根本原因:竞争条件导致辐射剂量超标
- 后果:3人死亡,多人重伤
2. Android Binder死锁(CVE-2013-6272)
- 机制:内核驱动未正确处理锁顺序
- 影响:系统级拒绝服务
3. OpenSSL心跳漏洞(CVE-2014-0160)
- 并发关联:未同步处理内存越界读取
- 攻击面:可远程泄露64KB内存(包含私钥等敏感信息)
4. 单例模式失效案例
- 场景:双重检查锁在C++03环境的失效
- 后果:返回未完全初始化的对象实例