AI 数据中心 vs 传统数据中心:从硬件架构到网络设计的全面进化
过去,数据中心主要负责储存与处理企业级应用,例如电子邮件、数据库、网站服务等。 然而,随着 AI 的崛起,整个数据中心的架构正经历一场剧烈变革。 现在的 AI 数据中心,已经不只是传统的存储与运算环境,而是针对高效能运算(HPC, High-Performance Computing) 进行优化,以满足 AI 训练和推理的需求。
这场变革主要体现在运算核心、网络架构、带宽需求与延迟控制等多个方面。 让我们来看看,AI 数据中心与传统数据中心究竟有什么不同。

AI数据中心 – 运算核心架构的转变:CPU vs GPGPU/ASIC
传统数据中心 – x86 CPU专门负责串行运算
传统数据中心跟 AI 数据中心最大的差别之一,就是使用的运算核心不同:前者使用 CPU,后者则大量使用 GPGPU 或特制的 AI 芯片(ASIC)。 这两者差异在哪?

传统数据中心主要负责
- 数据库管理
- 企业应用(ERP、CRM)
- 网站与云端应用
- 虚拟机(VM)
这些工作属于串行运算,串行运算的意思很简单,就是要按照顺序,一步一步慢慢做,每一步之间都有相依性。 比如说你今天去银行提款,你的账户一定要先确认余额够不够,才能提款,然后再更新余额,每一步骤都不能跳过。 这种工作的运算核心主要是通过x86架构的CPU。 CPU 擅长处理比较复杂、相依性强的指令,它就像一个超级聪明的主管,能够有效地依序处理各种问题。 主要的芯片有Intel Xeon或AMD EPYC服务器处理器。
AI数据中心 – GPGPU提供大规模平行运算
但当 AI 需要大量的数据并行运算时,CPU 的表现就显得力不从心。 AI 模型的训练跟推理,都是在做大量的矩阵运算,而矩阵运算的特色就是它可以同时执行大量简单计算。 这就好比一个人单独解 1,000 道数学题 vs. 1,000 人同时解 1,000 题,后者速度当然快很多。
与CPU相比,GPU有更多的运算核心,擅长平行运算,对于短时间需要大量重复运算的AI训练与推理功能无疑是大大地加分。 这也使得显卡芯片王者nVIDIA成为这一波AI浪潮里最火热的当红炸子鸡。 股价在短短几年暴冲了好几倍! 也因为有超级稳定的现金流,可以巩固其在产业的地位,在2024年已经把芯片的Roadmap画到2027年去了(伟哉Jensen)。
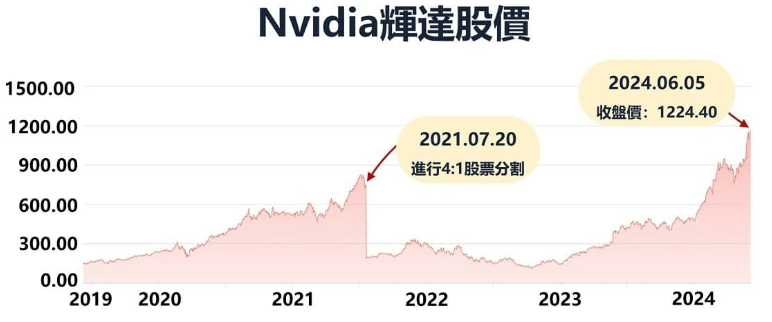
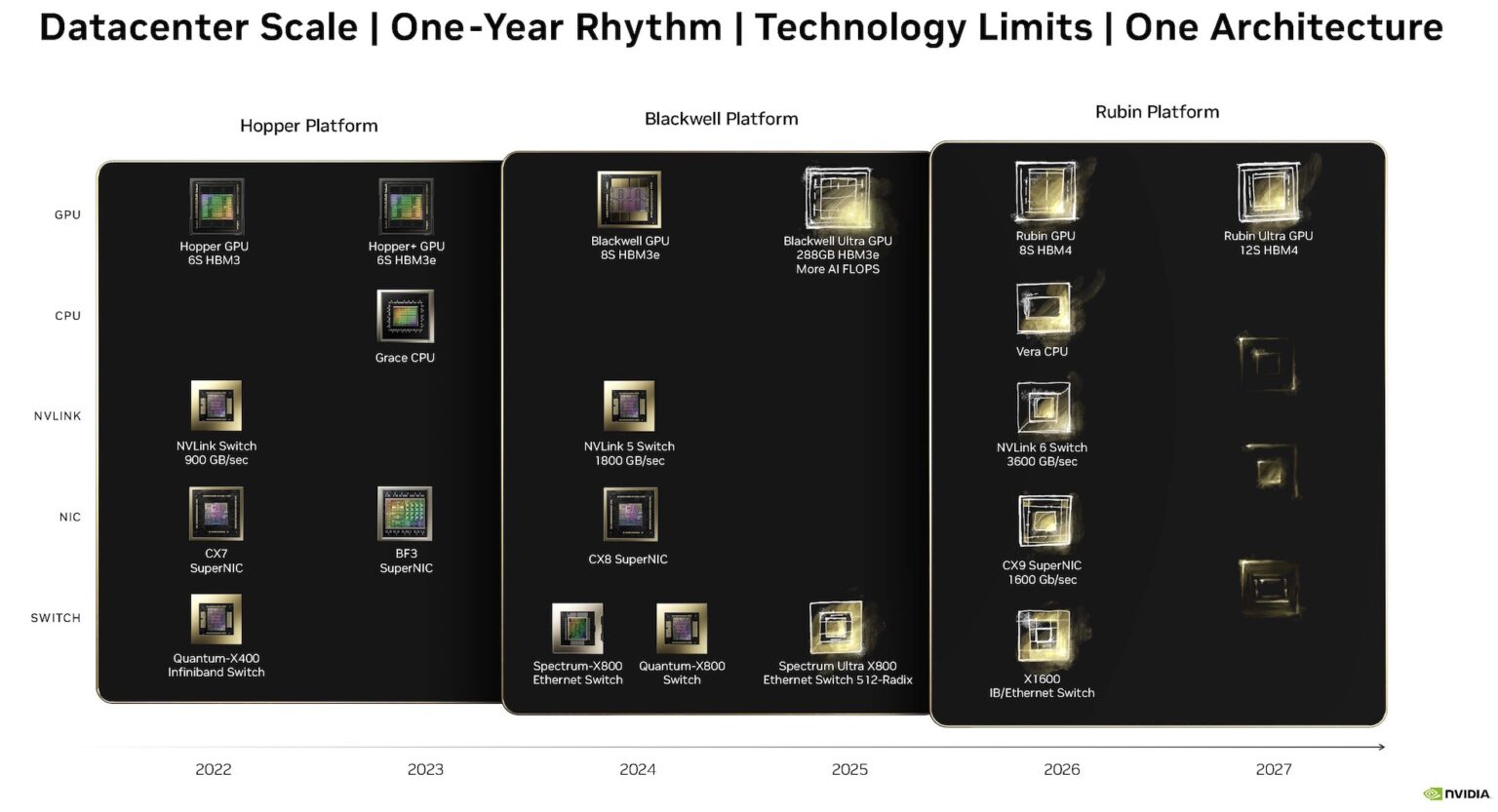
目前(2025 Q1),按照nVIDIA计划走,市场上的GPU已经进展到Blackwell系列,也就是HGX B100、B200以及GB200。 而今年业界焦点除了持续关注正在如火如荼出货的GB200 Rack上,目光也望着GB300,也就是Blackwell Ultra这颗新的芯片上。
Screenshot
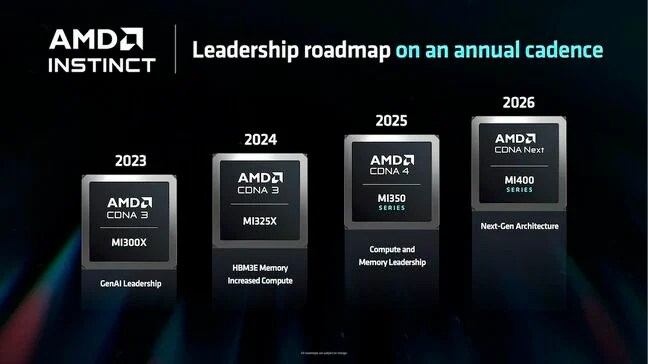
当然作为传统显示芯片的二当家,AMD也是紧跟着nVIDIA的脚步走,相关GPU Roadmap已经开到MI400,一些ODM也已经着手进行MI450的讨论。 对AMD而言,现在最大的问题不是GPU的能力,好歹AMD也是最早拥抱Chiplet设计观念的公司,设计的技术水平是很高的,所以其单颗GPU能力并不会输给nVIDIA。 对这间公司而言最大的问题是目前没办法将GPU的带宽冲出来,不像nVIDIA有NVLink5.0这种网络拓朴,可以将它所有的芯片做成超大的Cluster,AMD自有IP偏向PCIe架构,我们先前讨论过,PCIe数据传输速度还是不够快。 因此有可能在MI450,AMD会导入Broadcom的TH6网络芯片,把带宽放大,以对抗nVIDIA!
AI数据中心 – 定制ASIC,提供更好的效率
除了通用GPU以外,现在这些大型CSP业者为了提升自有的AI算法的效率,有些大公司甚至特别开发(或是找伙伴一起开发,例如OpenAI找Broadcom、Amazon找Marvell与Alchip)专用的 AI 芯片(或称 AI ASIC)。 例如 Google 的 TPU,或是 META 的 MTIA 系列芯片,就是专门为 AI 计算设计的。 这些特制芯片比通用GPU更有效率,因为它们不需要考虑其他用途,专注于AI运算上面,对于电源功耗、散热、整体效率又提升了不少。
Meta的MTIA(Meta Training and Interference Accelerator):
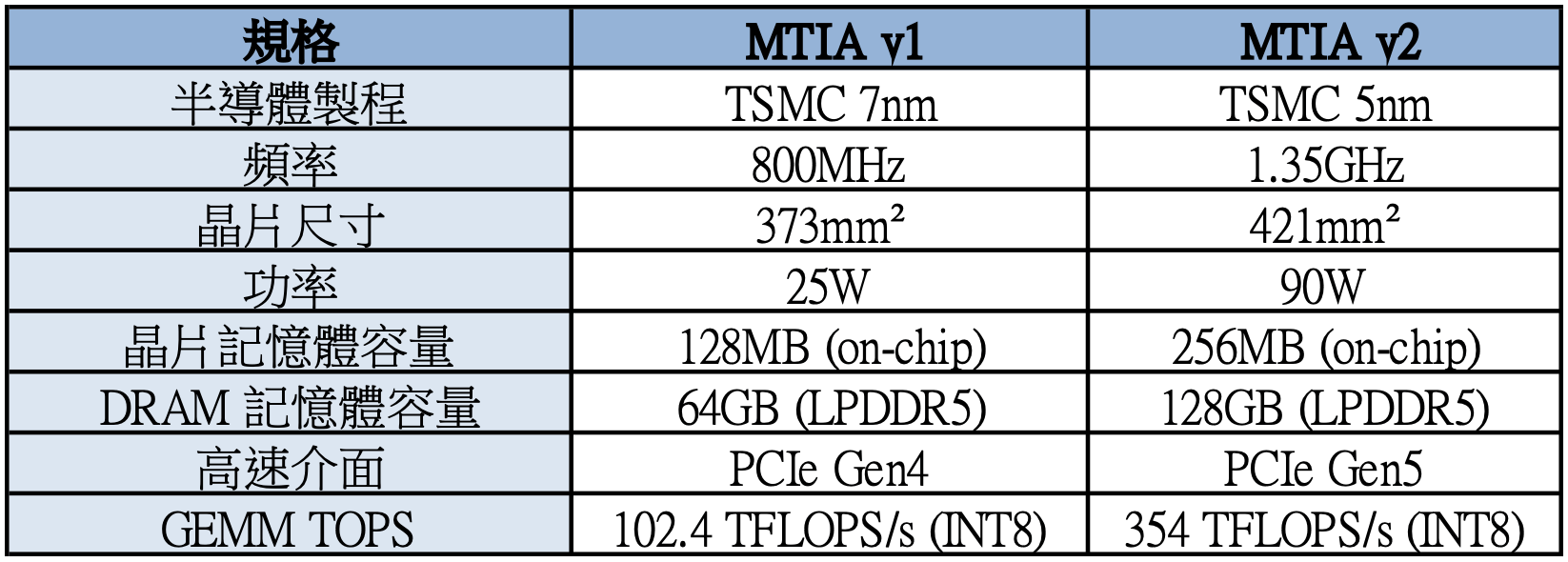
Amazon的Trainium 2:
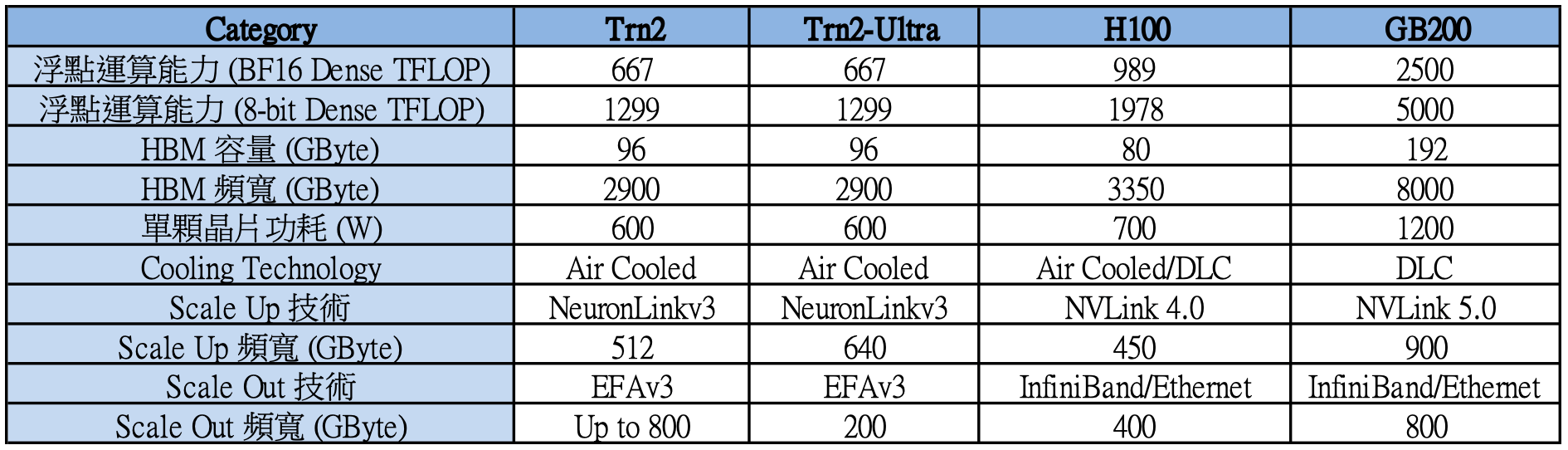
除了核心运算芯片的不同外,对AI数据中心而言,还有许多架构上的转变,例如储存设备的变化、电力与散热的需求暴增等等,在这边就不多赘述。
GPU/ASIC 打团体战! AI 数据中心内部网络的重要性
AI 需要规模化平行计算,同时间越多的运算核心一起工作是必要的。 因此怎么将所有的芯片连起来,让GPU/ASIC去扩展(Scalability),进而变成一台「超级 AI 计算机」,就是关键中的关键!
而这一切的扩展核心,就是高速网络。 透过这些网络技术,AI 训练时可以快速传递数据,确保 GPU 之间的梯度更新(Gradient Exchange) 和模型同步(Model Synchronization) 不会成为瓶颈,让 AI 训练更有效率。
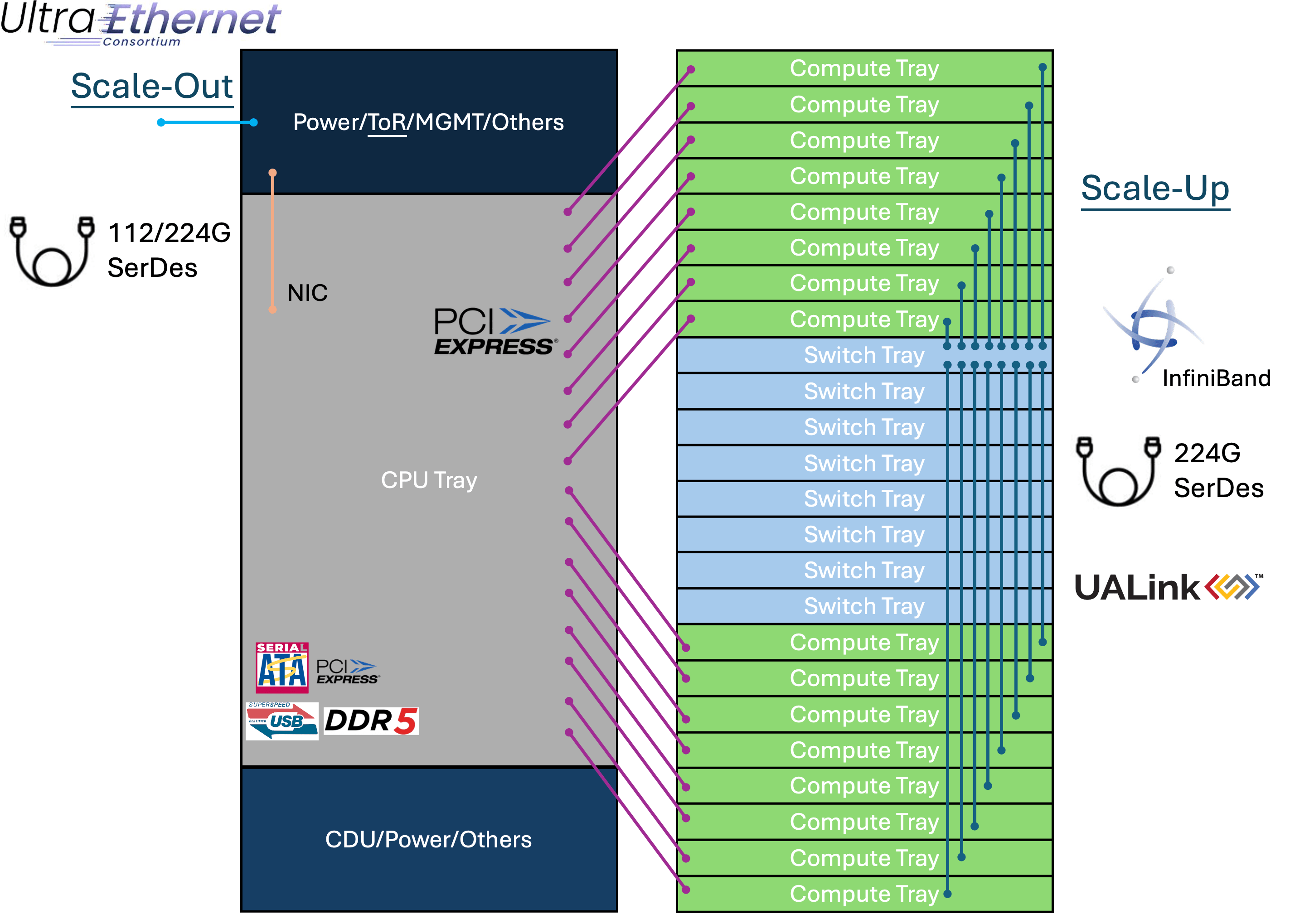
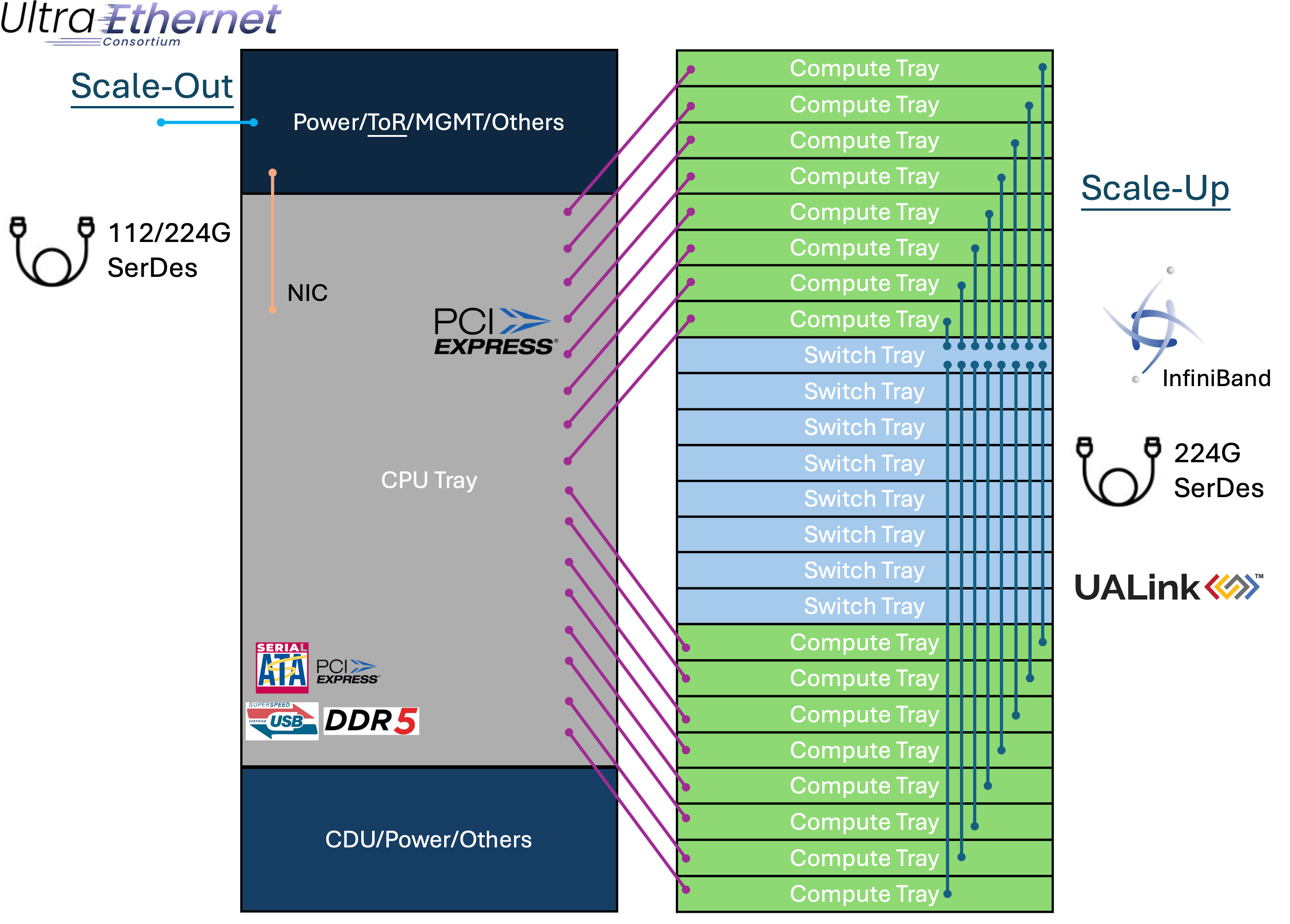
例如,以nVIDIA的NVL72 GB200来看,有72个Blackwell GPU,单一GPU的理论带宽为1.8TB/s,透过NVLink将72个GPU串起来,理论总带宽可以高达129.6TB/s。 或是说像图上的这种架构,利用8个具备高速网络224G SerDes的Switch tray,透过背板连接器,经由Copper cable并接16个Compute tray做资料传输的Scale-Up,图上仅以单台Switch tray做范例,实际上每台Switch tray都会用相同方式接到Compute tray, 这样连接就可以达成一个完整的矩阵! 若以一台预计2026年要推出载着Broadcom TH6网通芯片的Switch tray总带宽102.4T来看,整个Rack总带宽可以高达819.2T! 这会是目前AI数据中心里面较有效率且妥善利用Rack空间的一种规划。 这只是其中一种idea,每家CSP业者的想法不尽相同,不过可以确定的是网路的重要性不亚于GPU与ASIC的能力!
这也是为什么nVIDIA早早要收购Mellanox这家网络公司,咱家老黄早就看到网络对于GPU扩展的重要性!
这边顺便提一下这些高速讯号的不同应用:
- Ethernet or InfiniBand:用于Scale-Out的对外网络或是Scale-Up的内部网络,目前发展到224G-PAM4。
- UALink:几家大公司如Broadcom、AMD、Apple筹组的联盟,目的是为了对抗nVIDIA的NVLink而开发的高速接口,目前UALink 1.0规范快要完成了! 预计也是采用224G SerDes。
- PCIe:由PCI-SIG推出的高速接口,初期应用在消费型电子,例如CPU-Storage的连接、CPU-GPU的连接等等,目前进展到PCIe Gen6,由于被消费型电子的多种应用绑架,规范更新速度过慢,才导致nVIDIA推出NVLink自己玩自己的!
- UEC:也是由一堆国际大厂筹组的联盟,目标是要定义出高低延迟的网络生态系,已满足AI/ML的应用。
网络数据流量模式 – Scale-Up and Scale-Out
我们一直在AI数据中心领域,一直在讲Scale-Up与Scale-Out,这两者到底是什么? 是不是雾煞煞?
传统数据中心:东西向与南北向流量并重
- 南北向流量(North-South Traffic):
- 外部跟内部的数据传递
- 客户端(例如用户、浏览器)与服务器之间的请求与响应流量。
- 用户访问云端应用、企业内部系统连接、网站请求等。
- 由于要将大量数据往外部送,网络交换器的带宽需求较高(400G up)。
- 东西向流量(East-West Traffic):
- 内部机台间的资料传递
- 服务器之间的数据交换,例如微服务架构、数据库同步。
- 但这类流量通常不会过于密集,100G/400G网络即可应付大多数情境。 (多数为100G)
AI 数据中心:极端东西向流量
AI 训练过程中,服务器之间必须大量交换数据,此种东西向流量主要来自:
- GPU 服务器之间的数据同步
- 深度学习训练时的梯度更新
- 多机 GPU 丛集的跨节点通信
这些数据传输量巨大,数百台GPU必须以极低延迟进行通讯,因此InfiniBand与400G/800G Ethernet变成标准配置。
网络带宽需求
传统数据中心:100G/400G 是主流
- 目前许多企业与云端数据中心仍然采用 100G 网络交换机。
- 部分高性能应用(例如 HPC)才会用到 200G/400G 网络。
- 网络带宽需求主要来自应用层,单一应用通常不会瞬间爆发大量流量。
AI 数据中心:400G/800G 是新标准
AI 训练时,GPU 之间的数据同步带宽需求极高,以 GPT-4 训练为例,AI Cluster 可能需要数千张 H100 互联,这时候:
- InfiniBand HDR/ NDR(200G/400G)或 Ethernet 400G/800G 是标配
- 使用 NVLink 加速 GPU 内部通讯
- 如果网络带宽不足,AI训练时间将大幅增加,甚至 GPU 会处于等待数据的状态,无法充分利用。
网络延迟需求
传统数据中心:毫秒级(ms)延迟
传统 IT 应用(例如网页服务器、电子邮件)对于延迟容忍度较高,数毫秒(ms) 的延迟影响不大。
例如:
- 企业ERP系统:10-50ms延迟几乎没感觉
- 网页请求:数十 ms 影响不大
- 虚拟机/云端应用:主要关心吞吐量,不太受延迟影响
AI 数据中心:微秒级(μs)延迟
AI 训练时,GPU 之间的通讯频繁,如果网络延迟高,会严重影响计算效率,甚至造成 GPU 闲置。
例如:
- GPU 训练需要 <10μs 延迟的InfiniBand 或 NVLink
- 以太网 400G/800G 延迟也必须控制在 <50μs
- 低延迟 RDMA(Remote Direct Memory Access)技术被广泛使用
- 因此 AI 数据中心会特别优化网络,以最小化通讯延迟。
224G SerDes – 当前最高速的数据传输IP
AI产业的高带宽需求,势必使高速讯号得迅速地进步。 原本业界最高规格的传输IP 112G SerDes已经无法满足,224G SerDes应运而生成为当前产业界最新的高速讯号规格。 其采用了PAM4编码技术,让带宽可以在有限的频谱范围内大幅提升,让我们这些SI工作者只需要顾虑到53GHz的Nyquist Frequency,而不是106GHz。 然而,即便如此,两倍于 112G 的带宽 依旧带来了许多设计上的新难题,对 材料选择、PCB 布局、SI与功耗管理 都提出了更严苛的要求。 :
- 高频材料损耗与系统损耗管控:系统损耗计算、连接器与测试治具的选用以及PCB CCL材料选择
- 更严苛的阻抗控制:更严苛(5%)的过孔阻抗控制
- 更难解决的Crosstalk:BGA pin map的排列与Ground via shielding的设计直接主导Via Crosstalk的优劣
最后做个简单的总结:

讲真的,讯号完整性是越来越重要了,已经不单单只是SI工程师要处理的,如果每个人都对SI有简单的认识,那处理高速讯号产品就会更容易些喔,就跟着我们一起理解SI的奥秘之处吧!