Pacman-Multi-Agent Search
文档
代码及文档:通过网盘分享的文件:code
链接: https://pan.baidu.com/s/1Rgo9ynnEqjZsSP2-6TyS8Q?pwd=n99p 提取码: n99p


补充核心代码
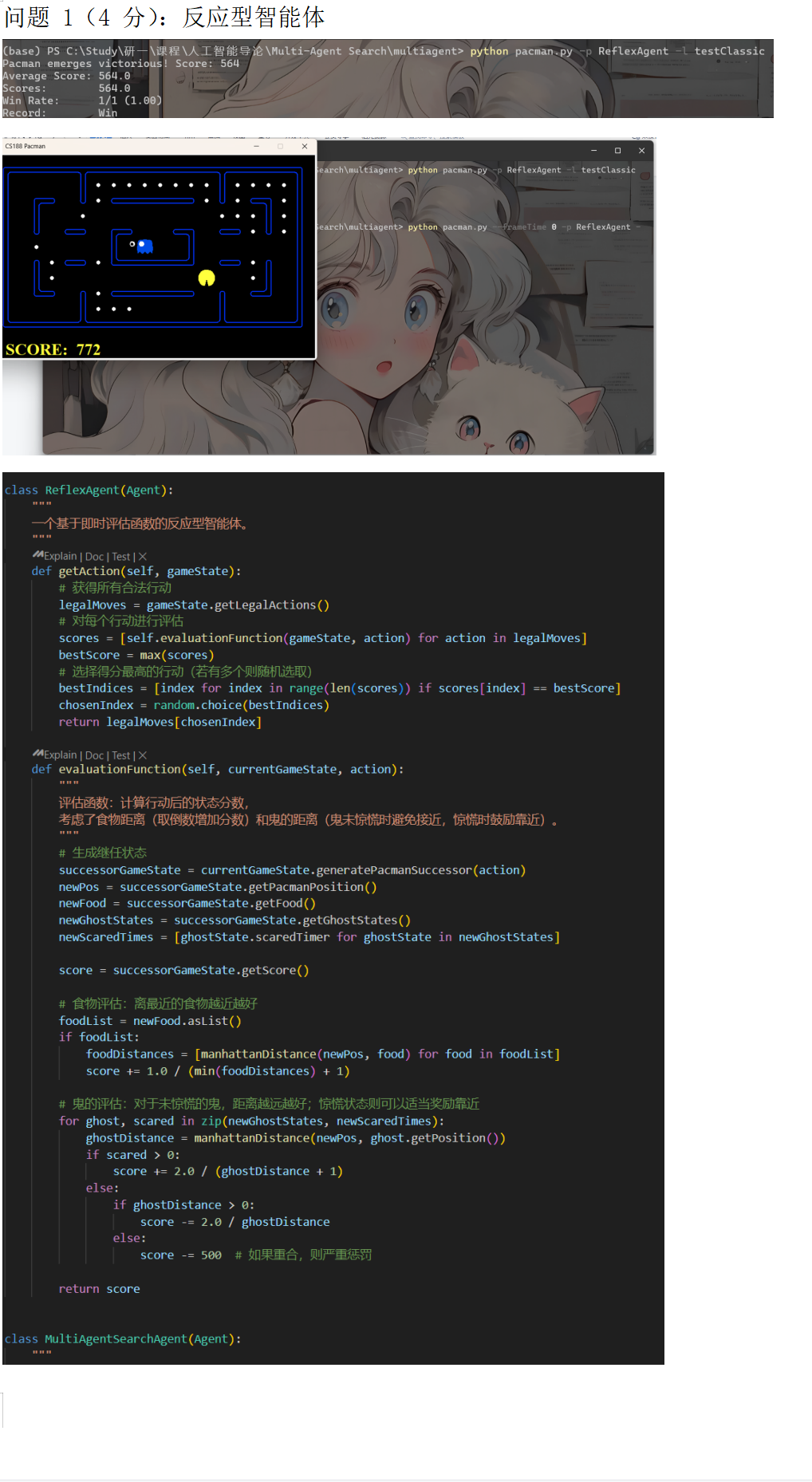
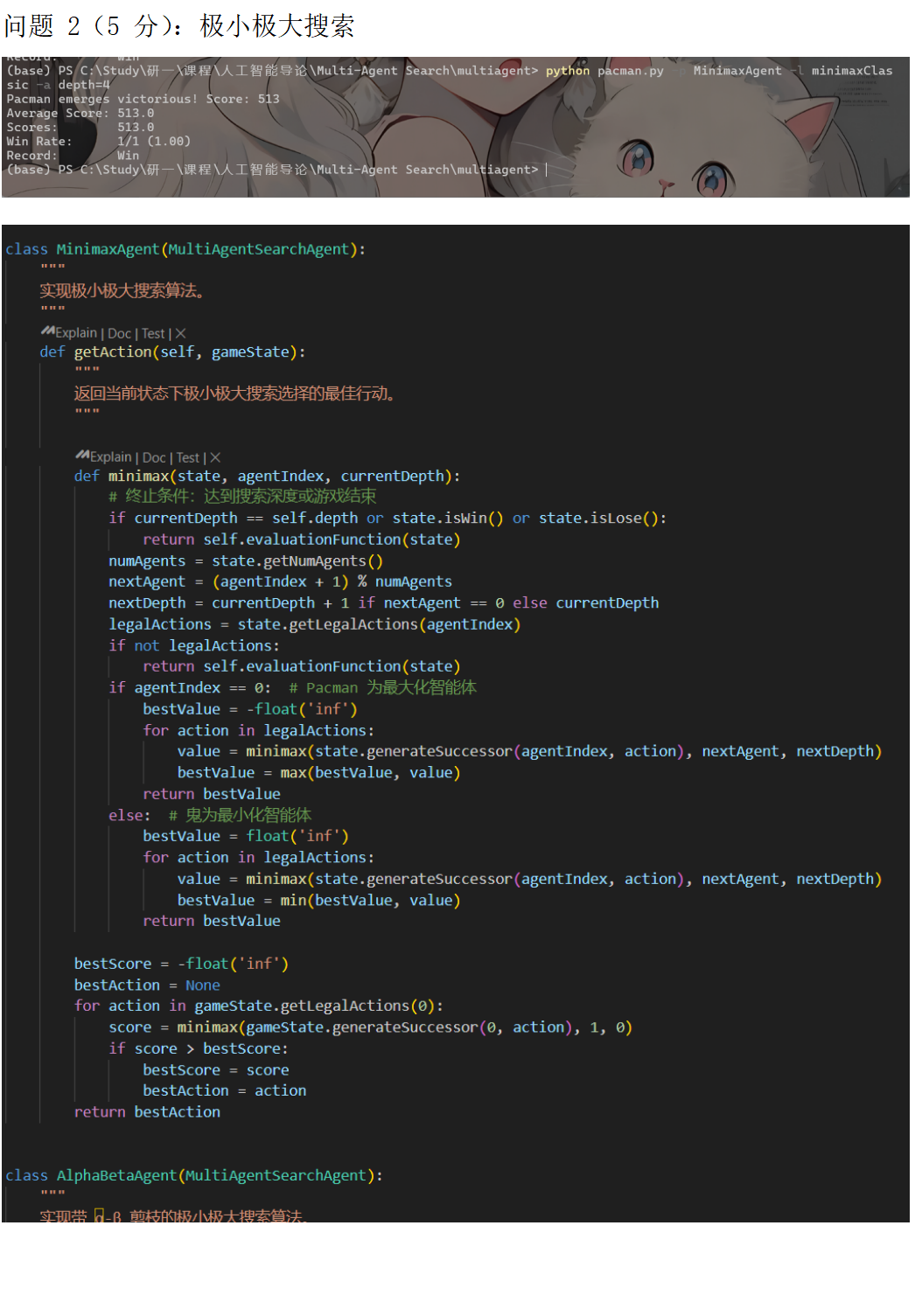
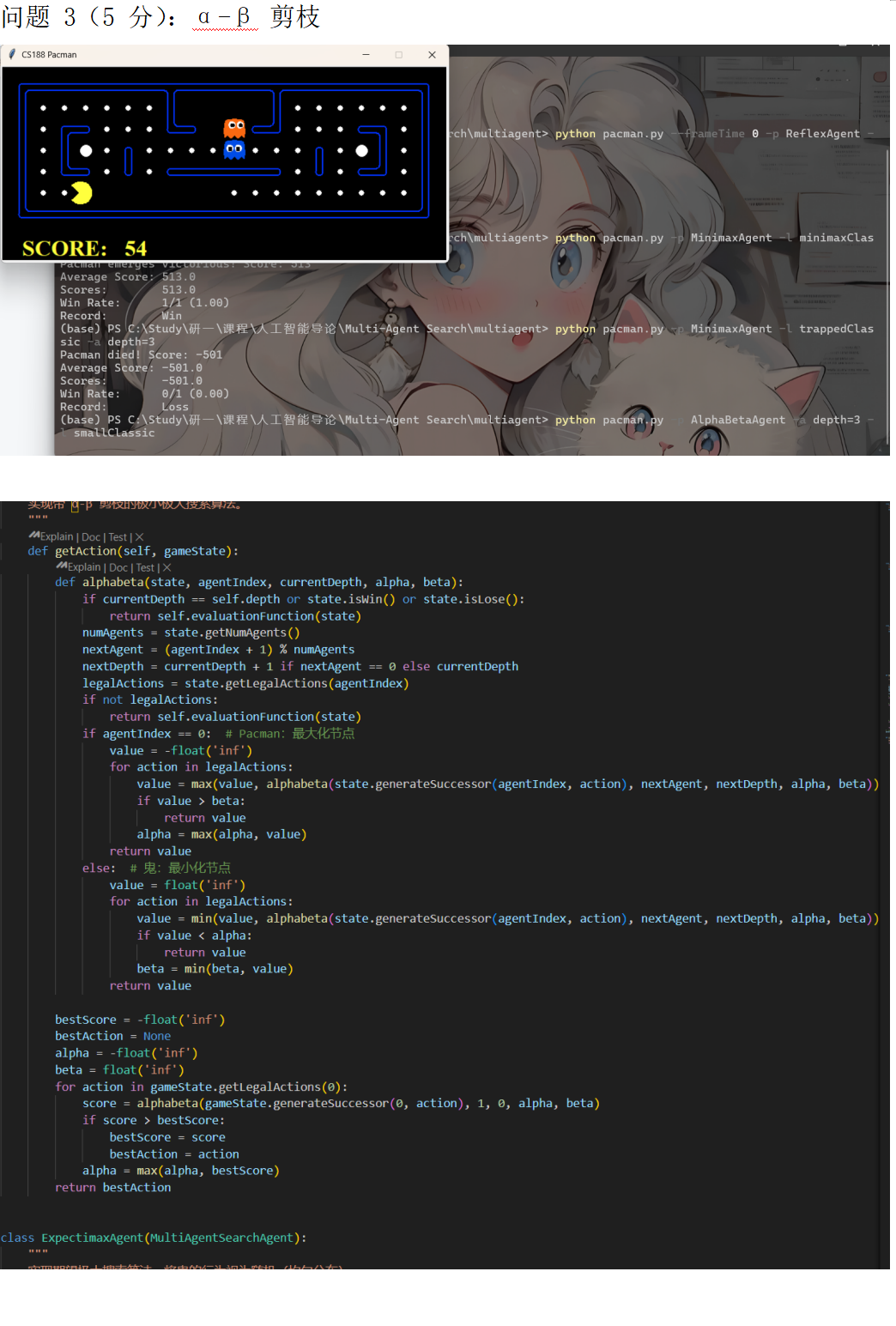
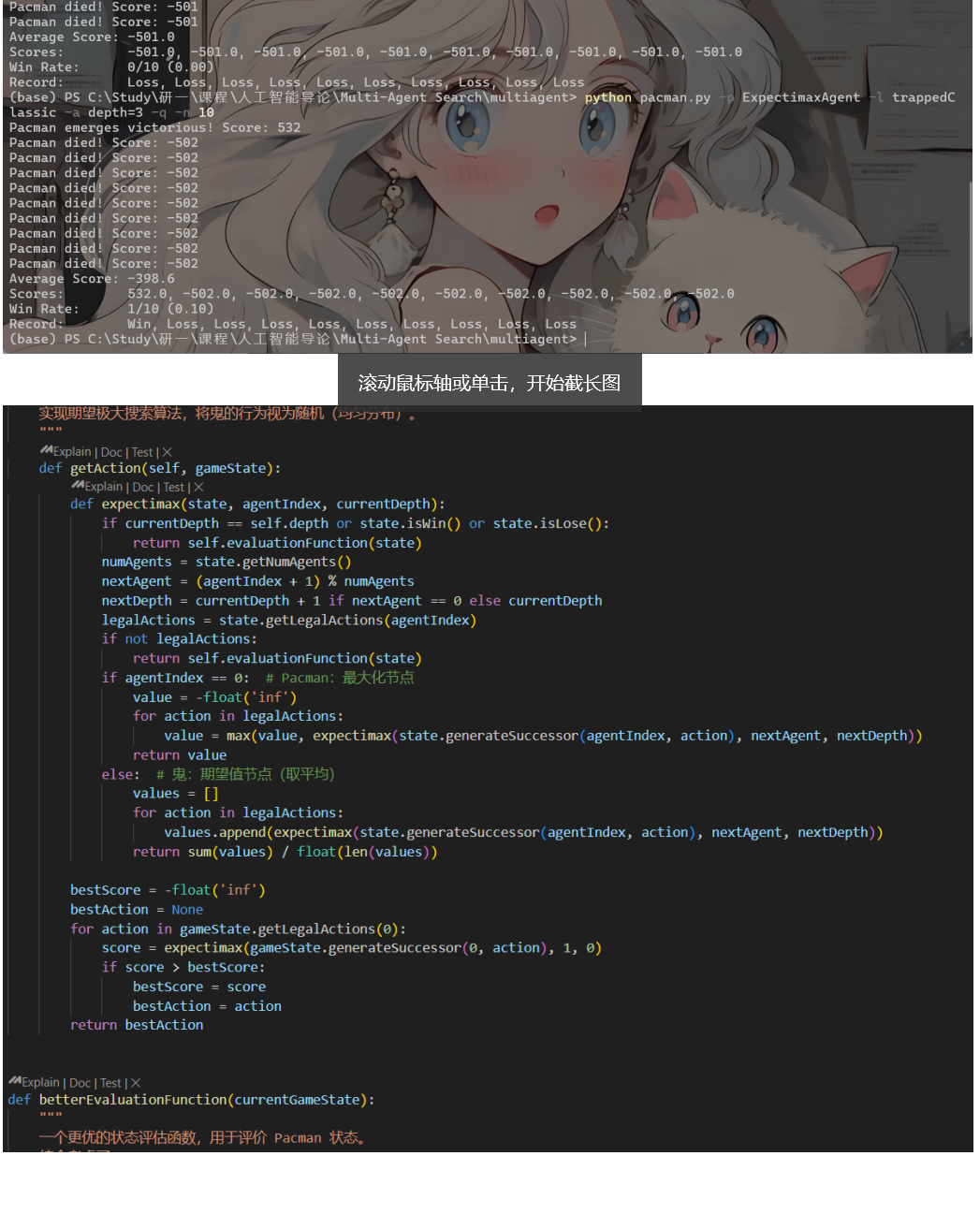
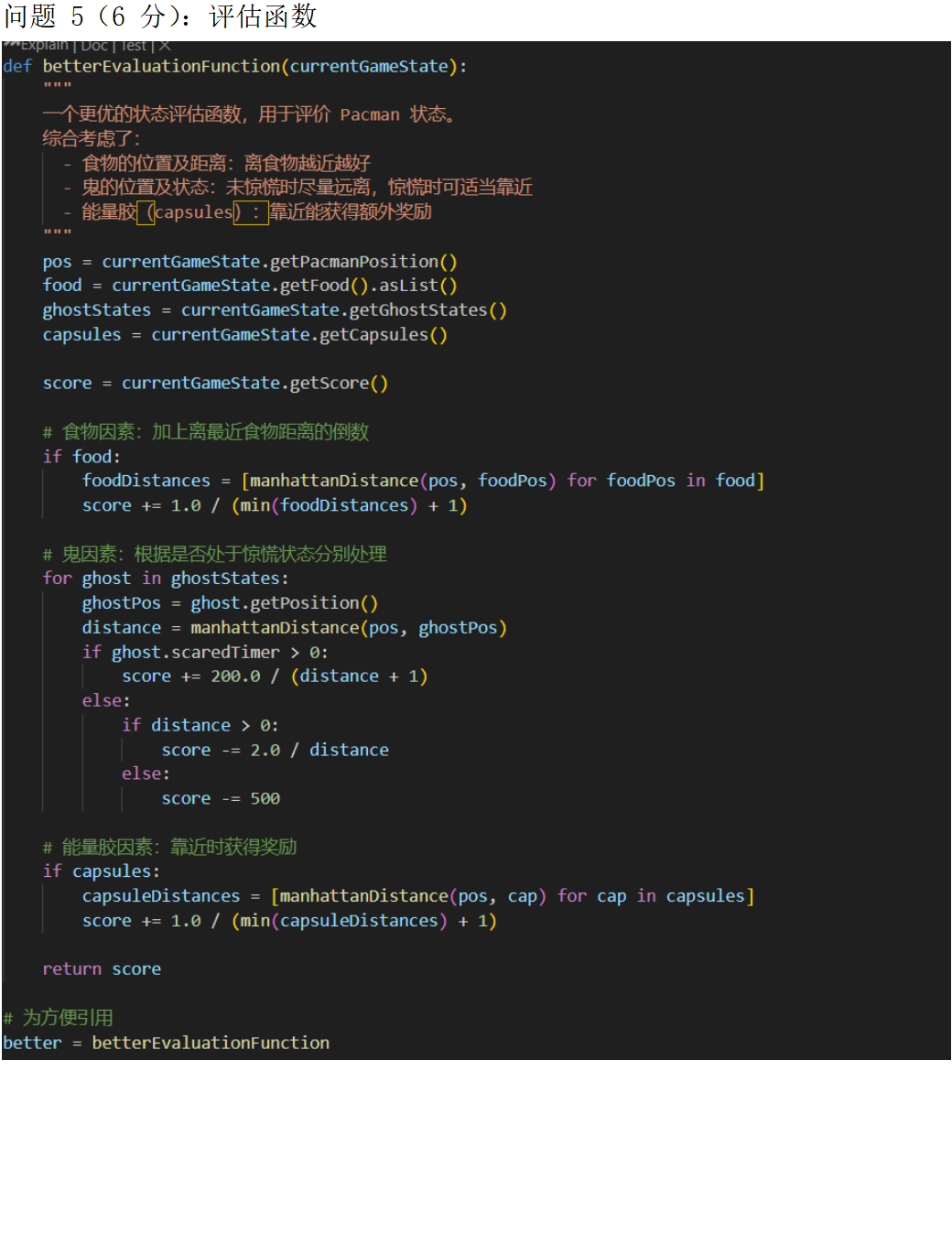
核心代码内容:
multiAgents.py
"""
multiAgents.py
--------------
This file contains the agents for the Pacman multi-agent search project.
根据项目要求,实现了以下内容:
1. ReflexAgent:改进了评估函数,考虑食物和鬼的距离。
2. MinimaxAgent:采用递归实现的极小极大搜索,支持任意数量的鬼。
3. AlphaBetaAgent:在 Minimax 的基础上加入了 α-β 剪枝加速搜索。
4. ExpectimaxAgent:实现了期望极大搜索,对于鬼的行动取均值。
5. betterEvaluationFunction:设计了更优的评估函数,用于评价状态。
"""from util import manhattanDistance
from game import Directions, Agent
import random, utilclass ReflexAgent(Agent):"""一个基于即时评估函数的反应型智能体。"""def getAction(self, gameState):# 获得所有合法行动legalMoves = gameState.getLegalActions()# 对每个行动进行评估scores = [self.evaluationFunction(gameState, action) for action in legalMoves]bestScore = max(scores)# 选择得分最高的行动(若有多个则随机选取)bestIndices = [index for index in range(len(scores)) if scores[index] == bestScore]chosenIndex = random.choice(bestIndices)return legalMoves[chosenIndex]def evaluationFunction(self, currentGameState, action):"""评估函数:计算行动后的状态分数,考虑了食物距离(取倒数增加分数)和鬼的距离(鬼未惊慌时避免接近,惊慌时鼓励靠近)。"""# 生成继任状态successorGameState = currentGameState.generatePacmanSuccessor(action)newPos = successorGameState.getPacmanPosition()newFood = successorGameState.getFood()newGhostStates = successorGameState.getGhostStates()newScaredTimes = [ghostState.scaredTimer for ghostState in newGhostStates]score = successorGameState.getScore()# 食物评估:离最近的食物越近越好foodList = newFood.asList()if foodList:foodDistances = [manhattanDistance(newPos, food) for food in foodList]score += 1.0 / (min(foodDistances) + 1)# 鬼的评估:对于未惊慌的鬼,距离越远越好;惊慌状态则可以适当奖励靠近for ghost, scared in zip(newGhostStates, newScaredTimes):ghostDistance = manhattanDistance(newPos, ghost.getPosition())if scared > 0:score += 2.0 / (ghostDistance + 1)else:if ghostDistance > 0:score -= 2.0 / ghostDistanceelse:score -= 500 # 如果重合,则严重惩罚return scoreclass MultiAgentSearchAgent(Agent):"""所有多智能体搜索算法智能体的父类。"""def __init__(self, evalFn='scoreEvaluationFunction', depth='2'):self.index = 0 # Pacman 的索引始终为 0self.evaluationFunction = util.lookup(evalFn, globals())self.depth = int(depth)class MinimaxAgent(MultiAgentSearchAgent):"""实现极小极大搜索算法。"""def getAction(self, gameState):"""返回当前状态下极小极大搜索选择的最佳行动。"""def minimax(state, agentIndex, currentDepth):# 终止条件:达到搜索深度或游戏结束if currentDepth == self.depth or state.isWin() or state.isLose():return self.evaluationFunction(state)numAgents = state.getNumAgents()nextAgent = (agentIndex + 1) % numAgentsnextDepth = currentDepth + 1 if nextAgent == 0 else currentDepthlegalActions = state.getLegalActions(agentIndex)if not legalActions:return self.evaluationFunction(state)if agentIndex == 0: # Pacman 为最大化智能体bestValue = -float('inf')for action in legalActions:value = minimax(state.generateSuccessor(agentIndex, action), nextAgent, nextDepth)bestValue = max(bestValue, value)return bestValueelse: # 鬼为最小化智能体bestValue = float('inf')for action in legalActions:value = minimax(state.generateSuccessor(agentIndex, action), nextAgent, nextDepth)bestValue = min(bestValue, value)return bestValuebestScore = -float('inf')bestAction = Nonefor action in gameState.getLegalActions(0):score = minimax(gameState.generateSuccessor(0, action), 1, 0)if score > bestScore:bestScore = scorebestAction = actionreturn bestActionclass AlphaBetaAgent(MultiAgentSearchAgent):"""实现带 α-β 剪枝的极小极大搜索算法。"""def getAction(self, gameState):def alphabeta(state, agentIndex, currentDepth, alpha, beta):if currentDepth == self.depth or state.isWin() or state.isLose():return self.evaluationFunction(state)numAgents = state.getNumAgents()nextAgent = (agentIndex + 1) % numAgentsnextDepth = currentDepth + 1 if nextAgent == 0 else currentDepthlegalActions = state.getLegalActions(agentIndex)if not legalActions:return self.evaluationFunction(state)if agentIndex == 0: # Pacman:最大化节点value = -float('inf')for action in legalActions:value = max(value, alphabeta(state.generateSuccessor(agentIndex, action), nextAgent, nextDepth, alpha, beta))if value > beta:return valuealpha = max(alpha, value)return valueelse: # 鬼:最小化节点value = float('inf')for action in legalActions:value = min(value, alphabeta(state.generateSuccessor(agentIndex, action), nextAgent, nextDepth, alpha, beta))if value < alpha:return valuebeta = min(beta, value)return valuebestScore = -float('inf')bestAction = Nonealpha = -float('inf')beta = float('inf')for action in gameState.getLegalActions(0):score = alphabeta(gameState.generateSuccessor(0, action), 1, 0, alpha, beta)if score > bestScore:bestScore = scorebestAction = actionalpha = max(alpha, bestScore)return bestActionclass ExpectimaxAgent(MultiAgentSearchAgent):"""实现期望极大搜索算法,将鬼的行为视为随机(均匀分布)。"""def getAction(self, gameState):def expectimax(state, agentIndex, currentDepth):if currentDepth == self.depth or state.isWin() or state.isLose():return self.evaluationFunction(state)numAgents = state.getNumAgents()nextAgent = (agentIndex + 1) % numAgentsnextDepth = currentDepth + 1 if nextAgent == 0 else currentDepthlegalActions = state.getLegalActions(agentIndex)if not legalActions:return self.evaluationFunction(state)if agentIndex == 0: # Pacman:最大化节点value = -float('inf')for action in legalActions:value = max(value, expectimax(state.generateSuccessor(agentIndex, action), nextAgent, nextDepth))return valueelse: # 鬼:期望值节点(取平均)values = []for action in legalActions:values.append(expectimax(state.generateSuccessor(agentIndex, action), nextAgent, nextDepth))return sum(values) / float(len(values))bestScore = -float('inf')bestAction = Nonefor action in gameState.getLegalActions(0):score = expectimax(gameState.generateSuccessor(0, action), 1, 0)if score > bestScore:bestScore = scorebestAction = actionreturn bestActiondef betterEvaluationFunction(currentGameState):"""一个更优的状态评估函数,用于评价 Pacman 状态。综合考虑了:- 食物的位置及距离:离食物越近越好- 鬼的位置及状态:未惊慌时尽量远离,惊慌时可适当靠近- 能量胶(capsules):靠近能获得额外奖励"""pos = currentGameState.getPacmanPosition()food = currentGameState.getFood().asList()ghostStates = currentGameState.getGhostStates()capsules = currentGameState.getCapsules()score = currentGameState.getScore()# 食物因素:加上离最近食物距离的倒数if food:foodDistances = [manhattanDistance(pos, foodPos) for foodPos in food]score += 1.0 / (min(foodDistances) + 1)# 鬼因素:根据是否处于惊慌状态分别处理for ghost in ghostStates:ghostPos = ghost.getPosition()distance = manhattanDistance(pos, ghostPos)if ghost.scaredTimer > 0:score += 200.0 / (distance + 1)else:if distance > 0:score -= 2.0 / distanceelse:score -= 500# 能量胶因素:靠近时获得奖励if capsules:capsuleDistances = [manhattanDistance(pos, cap) for cap in capsules]score += 1.0 / (min(capsuleDistances) + 1)return score# 为方便引用
better = betterEvaluationFunctiondef scoreEvaluationFunction(currentGameState):"""这个评估函数简单地返回当前状态的得分。"""return currentGameState.getScore()