记一次pdf转Word的技术经历
一、发现问题
前几天在打开一个pdf文件时,遇到了一些问题,在Win10下使用WPS PDF、万兴PDF、Adobe Acrobat、Chrome浏览器打开都是正常显示的;但是在macOS 10.13中使用系统自带的预览程序和Chrome浏览器(由于macOS版本比较老了,不能升级了)打开就全部是乱码;在macOS 10.15中使用系统自带的预览程序打开是乱码,而使用Chrome浏览器打开正常显示。
由于是想在笔者的老MBP(macOS 10.13)上打开,可是不管是使用macOS系统自带的预览程序还是已经无法升级的Chrome浏览器打开都无法正常显示。所以得想个办法解决。
首先想到的就是目前各种PDF转WORD工具:
- Adobe Acrobat比较专业,转的WORD是乱码
- ABBYY FineReader,毛子出品,据说功能强大,转的WORD也是乱码
- 万兴PDF,国内新秀,功能也非常强大,性能比较高效,转的WORD也是乱码
- 国内办公老大WPS,转PDF功能都是线上的,国内的要求注册登录,貌似还需要VIP;海外版本可以免费试用,但是限制在10M内,超过10M需要付费升级到WPS Pro。好在笔者的这个PDF文件没超过10M,直接转WORD成功,显示正常,而且版面、字体这些都非常接近原PDF文件。还是得WPS啊!
使用WPS转WORD成功了,再使用WPS输出到PDF就可以了。
按说到此就可以结束了,但笔者为了一探究竟,继续深究!
二、分析问题
既然有某些情况下是可以正常显示的,说明是PDF中的文字编码问题,使用上述各种PDF工具除了FineReader,都可以查看PDF使用的字体情况:
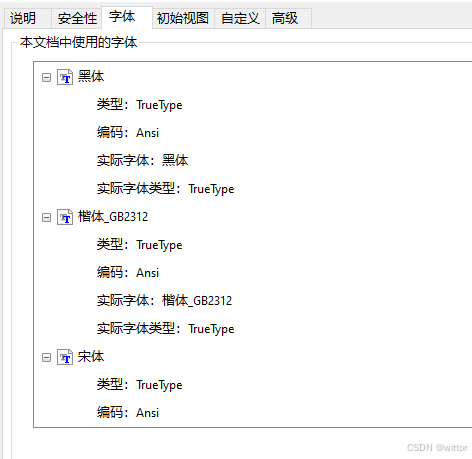
Adobe Acrobat:
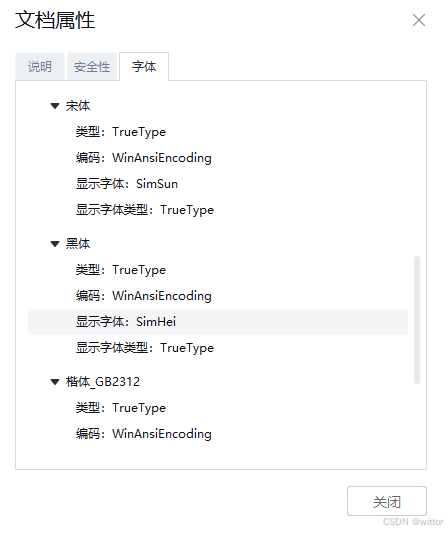
WPS PDF:
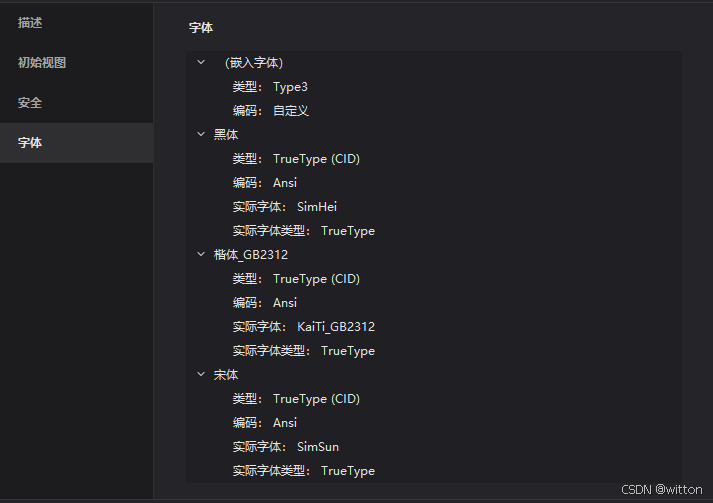
FineReader:
再看看正常WORD文档,使用WPS转PDF后的字体:
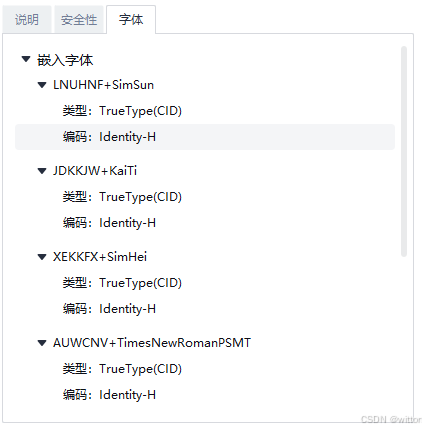
可以看到之前乱码的PDF是使用的非嵌入字体的中文字体,宋体、黑体、楷体GB2312,关键是编码是使用的ANSI编码。而后面的是使用的嵌入字体,使用的Identiy-H编码。ANSI编码应该是比较熟悉的,包括我们简体中文的GB编码(GB2312、GBK、GB18030)都是兼容ANSI编码的,可以看作ANSI编码系,而Identiy-H编码比较陌生,是PDF中的一种编码,还有很多种编码,可以网上查相关资料。
笔者在乱码的PDF信息中看到制作工具为S22PDF:
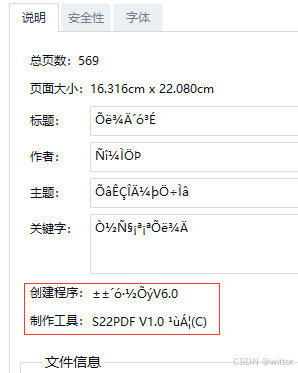
三、解决问题
1. 使用JS脚本
在网上查了不少资料,最后查到一个pdf库——mupdf中有一个JS脚本fix-s22pdf.js居然可以处理由S22PDF创建的PDF文字编码问题。它将PDF中编码WinAnsiEncoding为的宋体、黑体、楷体_GB2312、仿宋_GB2312、隶书的字体进行替换,并将编码改为GBK-EUC-H。
// A simple script to fix the broken fonts in PDF files generated by S22PDF.if (scriptArgs.length != 2) {print("usage: mutool run fix-s22pdf.js input.pdf output.pdf");quit();
}var doc = Document.openDocument(scriptArgs[0]);var font = new Font("zh-Hans");
var song = doc.addCJKFont(font, "zh-Hans", "H", "serif");
var heiti = doc.addCJKFont(font, "zh-Hans", "H", "sans-serif");
song.Encoding = 'GBK-EUC-H';
heiti.Encoding = 'GBK-EUC-H';var MAP = {"/#CB#CE#CC#E5": song, // SimSun,`/宋体`的GBK编码"/#BA#DA#CC#E5": heiti, // SimHei,`/黑体`的GBK编码"/#BF#AC#CC#E5_GB2312": song, // SimKai,`/楷体`的GBK编码"/#B7#C2#CB#CE_GB2312": heiti, // SimFang,`/仿宋`的GBK编码"/#C1#A5#CA#E9": song, // SimLi,`/隶书`的GBK编码
}var i, n = doc.countPages();
for (i = 0; i < n; ++i) {var fonts = doc.findPage(i).Resources.Font;if (fonts) {fonts.forEach(function (font, name) {if (font.BaseFont in MAP && font.Encoding == 'WinAnsiEncoding')fonts[name] = MAP[font.BaseFont];});}
}doc.save(scriptArgs[1]);
使用之前需要安装mupdf-tools:
apt install mupdf-tools
MinGW为:
pacman -S mingw-w64-x86_64-mupdf-tools
安装好后运行:
mutool run fix-s22pdf.js <源pdf> <目标pdf>
经过脚本转换后,可以正常显示中文了,但是实际上所有上述几种字体全部显示为宋体,也就是其它几种字体根本就不生效。
笔者跟了一下源码(mupdf master分支,目前为1.26-rc1),发现:
var font = new Font("zh-Hans");
新建了一种简体中文字体zh-Hans,但它使用了内置的一种叫Source Han Serif的字体,参见源码:
static void ffi_new_Font(js_State *J)
{fz_context *ctx = js_getcontext(J);const char *name = js_tostring(J, 1);const char *path = js_isstring(J, 2) ? js_tostring(J, 2) : NULL;fz_buffer *buffer = js_isuserdata(J, 2, "fz_buffer") ? js_touserdata(J, 2, "fz_buffer") : NULL;int index = js_isnumber(J, 3) ? js_tonumber(J, 3) : 0;fz_font *font = NULL;fz_try(ctx) {if (path)font = fz_new_font_from_file(ctx, name, path, index, 0);else if (buffer)font = fz_new_font_from_buffer(ctx, name, buffer, index, 0);else if (!strcmp(name, "zh-Hant"))font = fz_new_cjk_font(ctx, FZ_ADOBE_CNS);else if (!strcmp(name, "zh-Hans"))font = fz_new_cjk_font(ctx, FZ_ADOBE_GB);else if (!strcmp(name, "ja"))font = fz_new_cjk_font(ctx, FZ_ADOBE_JAPAN);else if (!strcmp(name, "ko"))font = fz_new_cjk_font(ctx, FZ_ADOBE_KOREA);elsefont = fz_new_base14_font(ctx, name);}fz_catch(ctx)rethrow(J);js_getregistry(J, "fz_font");js_newuserdata(J, "fz_font", font, ffi_gc_fz_font);
}
它使用的resources/fonts/han/SourceHanSerif-Regular.ttc。
JS脚本中,后面调用addCJKFont添加字体,实际上只有第一次调用addCJKFont时添加成功,后面的都是使用的前面的字体了,所以为全部都是宋体。
var song = doc.addCJKFont(font, "zh-Hans", "H", "serif");
var heiti = doc.addCJKFont(font, "zh-Hans", "H", "sans-serif");
addCJKFont函数:
- 第一个参数是字体
- 第二个参数是语系,简体中文为"zh-Hans"
- 第三个参数是模式,
V表示vertical,为竖排,否则为横排,这里使用对应的H来表示horizontal - 第四个参数,
sans或者sans-serif表示使用宋体,否则使用黑体
参见源码:
static void ffi_PDFDocument_addCJKFont(js_State *J)
{fz_context *ctx = js_getcontext(J);pdf_document *pdf = js_touserdata(J, 0, "pdf_document");fz_font *font = js_touserdata(J, 1, "fz_font");const char *lang = js_tostring(J, 2);const char *wm = js_tostring(J, 3);const char *ss = js_tostring(J, 4);int ordering;int wmode = 0;int serif = 1;pdf_obj *ind = NULL;ordering = fz_lookup_cjk_ordering_by_language(lang);if (!strcmp(wm, "V"))wmode = 1;if (!strcmp(ss, "sans") || !strcmp(ss, "sans-serif"))serif = 0;fz_try(ctx)ind = pdf_add_cjk_font(ctx, pdf, font, ordering, wmode, serif);fz_catch(ctx)rethrow(J);ffi_pushobj(J, ind);
}
pdf_obj *
pdf_add_cjk_font(fz_context *ctx, pdf_document *doc, fz_font *fzfont, int script, int wmode, int serif)
{pdf_obj *fref, *font, *subfont, *fontdesc;pdf_obj *dfonts;fz_rect bbox = { -200, -200, 1200, 1200 };pdf_font_resource_key key;int flags;const char *basefont, *encoding, *ordering;int supplement;switch (script){default:script = FZ_ADOBE_CNS;/* fall through */case FZ_ADOBE_CNS: /* traditional chinese */basefont = serif ? "Ming" : "Fangti";encoding = wmode ? "UniCNS-UTF16-V" : "UniCNS-UTF16-H";ordering = "CNS1";supplement = 7;break;case FZ_ADOBE_GB: /* simplified chinese */basefont = serif ? "Song" : "Heiti";encoding = wmode ? "UniGB-UTF16-V" : "UniGB-UTF16-H";ordering = "GB1";supplement = 5;break;case FZ_ADOBE_JAPAN:basefont = serif ? "Mincho" : "Gothic";encoding = wmode ? "UniJIS-UTF16-V" : "UniJIS-UTF16-H";ordering = "Japan1";supplement = 6;break;case FZ_ADOBE_KOREA:basefont = serif ? "Batang" : "Dotum";encoding = wmode ? "UniKS-UTF16-V" : "UniKS-UTF16-H";ordering = "Korea1";supplement = 2;break;}flags = PDF_FD_SYMBOLIC;if (serif)flags |= PDF_FD_SERIF;fref = pdf_find_font_resource(ctx, doc, PDF_CJK_FONT_RESOURCE, script, fzfont, &key);if (fref)return fref;font = pdf_add_new_dict(ctx, doc, 5);fz_try(ctx){pdf_dict_put(ctx, font, PDF_NAME(Type), PDF_NAME(Font));pdf_dict_put(ctx, font, PDF_NAME(Subtype), PDF_NAME(Type0));pdf_dict_put_name(ctx, font, PDF_NAME(BaseFont), basefont);pdf_dict_put_name(ctx, font, PDF_NAME(Encoding), encoding);dfonts = pdf_dict_put_array(ctx, font, PDF_NAME(DescendantFonts), 1);pdf_array_push_drop(ctx, dfonts, subfont = pdf_add_new_dict(ctx, doc, 5));{pdf_dict_put(ctx, subfont, PDF_NAME(Type), PDF_NAME(Font));pdf_dict_put(ctx, subfont, PDF_NAME(Subtype), PDF_NAME(CIDFontType0));pdf_dict_put_name(ctx, subfont, PDF_NAME(BaseFont), basefont);pdf_add_cid_system_info(ctx, doc, subfont, "Adobe", ordering, supplement);fontdesc = pdf_add_new_dict(ctx, doc, 8);pdf_dict_put_drop(ctx, subfont, PDF_NAME(FontDescriptor), fontdesc);{pdf_dict_put(ctx, fontdesc, PDF_NAME(Type), PDF_NAME(FontDescriptor));pdf_dict_put_text_string(ctx, fontdesc, PDF_NAME(FontName), basefont);pdf_dict_put_rect(ctx, fontdesc, PDF_NAME(FontBBox), bbox);pdf_dict_put_int(ctx, fontdesc, PDF_NAME(Flags), flags);pdf_dict_put_int(ctx, fontdesc, PDF_NAME(ItalicAngle), 0);pdf_dict_put_int(ctx, fontdesc, PDF_NAME(Ascent), 1000);pdf_dict_put_int(ctx, fontdesc, PDF_NAME(Descent), -200);pdf_dict_put_int(ctx, fontdesc, PDF_NAME(StemV), 80);}}fref = pdf_insert_font_resource(ctx, doc, &key, font);}fz_always(ctx)pdf_drop_obj(ctx, font);fz_catch(ctx)fz_rethrow(ctx);return fref;
}
所以理论上是可以添加两种字体:宋体与黑体,但是在实际运行中并不是这样,主要是下面的代码:
fref = pdf_find_font_resource(ctx, doc, PDF_CJK_FONT_RESOURCE, script, fzfont, &key);
if (fref)return fref;
查找字体时并不与什么具体的字体类型相关,而只与语系字体即"zh-Hans"相关,找到就返回了。
2. 使用python脚本
1. 配置环境
mupdf有一个python库pymupdf,可以直接使用下面的命令安装:
pip install PyMuPDF
MinGW下最好使用:
pacman -S mingw-w64-x86_64-python-pymupdf
需要注意的是MinGW下,根据版本不同可能不能使用
import pymupdf
也可能不能使用:
import fitz
而是需要使用:
import fitz_old as fitz
也有可能会报
DLL load failed while importing _fitz
则需要把MinGW中mingw64/bin/libgumbo-3.dll复制一份为mingw64/bin/libgumbo-2.dll
2. 工作
在pymupdf的PyMuPDF-Utilities库中有一个font-replacement专门用来进行字体替换的,作者还写了相应的文档进行说明。它有两个脚本repl-fontnames.py、repl-font.py,前者用于输出PDF文件中使用的字体信息到一个json文件,后者则使用该json中的配置来替换字体,参见它的readme.md。不过笔者使用它并不能正常工作。
所以笔者自己写了一个python脚本来实现:
# -*- coding: utf-8 -*-
import fitz_old as fitz
import sys# 构建需要替换的字体,Key为源PDF中使用的字体,Value为要替换为的系统中的字体文件路径
dict_new_font = {}
# 宋体替换为系统的宋体
dict_new_font['SimSun'] = 'c:/windows/fonts/simsun.ttc'
# 黑体替换为系统的黑体
dict_new_font['SimHei'] = 'c:/windows/fonts/simhei.ttf'
# 楷体及楷体GB2312替换为系统的楷体
dict_new_font['SimKai'] = 'c:/windows/fonts/simkai.ttf'def replace_page(page):span_list = []info = page.get_text('dict')for block in info['blocks']:lines = block.get('lines')if lines is None:continuefor line in lines:for span in line['spans']:font_name = span['font']name = font_name.lower()if name.startswith('simsun'):font_name = 'SimSun'elif name.startswith('simhei'):font_name = 'SimHei'elif name.startswith('simkai'):font_name = 'SimKai'else:continuespan['font'] = font_namepage.add_redact_annot(span['bbox'])span_list.append(span)page.apply_redactions()for target in span_list:text = target['text']font_name = target['font']page.insert_text(target['origin'], text, fontsize=target['size'], fontname=font_name,fontfile=dict_new_font[font_name])def replace_font(doc_path, save_path):doc = fitz.open(doc_path)n = len(doc)for page in doc:replace_page(page)print(f"{page.number}/{n}")print("清理字体")# 清理使用的字体doc.subset_fonts()print("保存文件")# 保存时,清理没使用的对象,减少文件大小doc.ez_save(save_path, clean=True)doc.close()print("完成")def main():if len(sys.argv) < 3:print(f"需要传入参数:格式:{sys.argv[0]} <源pdf> <目标pdf>")returnreplace_font(sys.argv[1], sys.argv[2])if __name__ == "__main__":main()
这个脚本能够完成功能,不过比较慢。
3.使用C语言
由于python运行起来比较慢,笔者想尝试一下直接使用C API是否会更快。但是很快就发现一个问题,C API的资料相比Python而言太少了,示例也比较少。尝试使用AI来辅助,发现AI给的代码完全不能编译通过,各种没有的函数(估计是学习的老版本的)。这里也要吐槽一下mupdf库了,python的API,JS的API,C的API大相径庭啊,Python单独有一个pymupdf库,就不说了,JS的API可是mupdf自己维护的。
1. 配置环境
Ubuntu Linux下使用下面命令安装:
apt install libmupdf-dev
MinGW使用下面命令安装:
pacman -S mingw-w64-x86_64-libmupdf
安装好开发包后就可以使用C API开发了。
2. 使用C API先尝试输出文本
创建CMakeLists.txt:
cmake_minimum_required(VERSION 3.25.0)project(t)add_compile_options(-gdwarf-4
)
set(CMAKE_C_STANDARD 23)add_executable(${PROJECT_NAME} main.c)
target_link_libraries(${PROJECT_NAME} mupdf mupdf-third freetype openjp2 jbig jbig2dec jpeg harfbuzz gumbo m z pthread iconv)
#include <iconv.h>
#include <locale.h>
#include <mupdf/fitz.h>
#include <mupdf/pdf.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#ifdef _WIN32
#include <windows.h>
#endif#ifdef NULL
#undef NULL
#define NULL nullptr
#endifstatic void handle_pdf(fz_context *ctx, fz_document *doc);
static void handle_page(fz_context *ctx, fz_document *doc, fz_page *page);int main(int argc, char **argv) {
#ifdef _WIN32// Windows控制台,需要设置成UTF8输出编码,以免显示乱码SetConsoleOutputCP(65001);
#endifif (argc < 3) {printf("需要传入参数:格式:%s <源pdf> <目标pdf>\n", argv[0]);return EXIT_FAILURE;}// 首先创建一个fz_contextfz_context *ctx = fz_new_context(NULL, NULL, FZ_STORE_UNLIMITED);if (!ctx) {printf("cannot create mupdf context\n");return EXIT_FAILURE;}// 注册默认的文档处理器fz_try(ctx) { fz_register_document_handlers(ctx); }fz_catch(ctx) {fz_report_error(ctx);printf("cannot register document handlers\n");fz_drop_context(ctx);return EXIT_FAILURE;}fz_document *doc = NULL;// 打开文档fz_try(ctx) { doc = fz_open_document(ctx, argv[1]); }fz_catch(ctx) {fz_report_error(ctx);printf("cannot open document\n");fz_drop_context(ctx);return EXIT_FAILURE;}fz_try(ctx) {// 处理文档handle_pdf(ctx, doc);// 保存文档pdf_save_document(ctx, (pdf_document *)doc, argv[2],&pdf_default_write_options);}fz_catch(ctx) {fz_report_error(ctx);printf("cannot count number of pages\n");fz_drop_document(ctx, doc);fz_drop_context(ctx);return EXIT_FAILURE;}// 清理资源fz_drop_document(ctx, doc);fz_drop_context(ctx);return EXIT_SUCCESS;
}static void handle_pdf(fz_context *ctx, fz_document *doc) {// 获取文档总页数int page_count = fz_count_pages(ctx, doc);// 遍历每一页for (int i = 0; i < page_count; ++i) {// 加载页面fz_page *page = fz_load_page(ctx, doc, i);// 处理页面handle_page(ctx, doc, page);// 释放页面fz_drop_page(ctx, page);}
}static void handle_page(fz_context *ctx, fz_document *doc, fz_page *page) {fz_stext_options opts = {FZ_STEXT_PRESERVE_IMAGES |FZ_STEXT_PRESERVE_LIGATURES};// 根据选项获取页面的结构化页面数据fz_stext_page *stext_page = fz_new_stext_page_from_page(ctx, page, &opts);// 文本转换用的临时空间// 由于文本字符的存储是一个unicode字符值,以int存储的所以一个8字节的空间足够了char buf[8];// 遍历结构化页面的块for (fz_stext_block *text_block = stext_page->first_block; text_block;text_block = text_block->next) {// 如果不是文本块,则不管它,只需要文本块if (text_block->type != FZ_STEXT_BLOCK_TEXT) {continue;}// 遍历文本块中的行for (fz_stext_line *text_line = text_block->u.t.first_line; text_line;text_line = text_line->next) {// 遍历行中的每一个字符for (fz_stext_char *text_char = text_line->first_char; text_char;text_char = text_char->next) {// 获取字符的值,是以Unicode存储的const int c = text_char->c;// 转换成UTF8编码const int num = fz_runetochar(buf, c);// 设置结束符buf[num] = 0;// 输出UTF8字符printf("%s", buf);}}printf("\n");}// 清理当前页资源fz_drop_stext_page(ctx, stext_page);
}
3. 使用C API替换字体
未完,待续。。。
如果本文对你有帮助,欢迎点赞收藏!