实战篇:在QEMU中编写和调试VHost/Virtio驱动
在云计算环境中,当多个虚拟机同时进行大规模数据传输时,这种通信瓶颈就会变得尤为明显,严重影响了云服务的性能和用户体验。同样,在大数据分析场景下,虚拟机需要频繁地读写存储设备,如果虚拟设备通信效率低下,就会导致数据分析的速度大幅下降,无法满足实时性的要求。
那么,有没有一种方法能够打破这种通信困境,让虚拟设备之间的通信更加高效、流畅呢?答案就是 vhost/virtio 技术。它就像是虚拟世界中的通信加速器,为解决虚拟设备通信难题带来了新的曙光。接下来,就让我们深入了解 vhost/virtio 技术的奥秘。
一、手写 Vhost/Virtio
1.1前期准备:搭建 “舞台”
在开始这场奇妙的手写 vhost/virtio 之旅前,我们首先需要搭建一个合适的开发环境,就如同搭建一个稳固的舞台,为后续的精彩表演做好充分准备。
我们要安装 Qemu,它可是虚拟化的基石。安装 Qemu 的方式有多种,对于追求便捷的开发者来说,可以使用系统自带的包管理器,比如在 Ubuntu 系统中,只需在终端输入 “sudo apt - get install qemu - system - x86” 即可轻松完成安装。但如果你想要更前沿的功能和性能优化,从源代码编译安装则是个不错的选择。你可以从 Qemu 的官方网站下载最新的源代码,然后按照官方文档的指引进行编译和安装 ,虽然这个过程可能稍微复杂一些,但能让你获得最适合自己需求的 Qemu 版本。
除了 Qemu,我们还需要一系列相关的开发工具和库文件。比如,GCC(GNU Compiler Collection)是必不可少的,它能将我们编写的 C 代码编译成可执行的程序。安装 GCC 也很简单,在大多数 Linux 系统中,通过包管理器就能快速完成安装。另外,还需要安装一些开发库,如 libvirt 开发库,它提供了与虚拟化管理相关的接口,方便我们在代码中对虚拟机进行各种操作;以及 libpciaccess 库,它有助于我们访问 PCI 设备,在处理虚拟设备相关的功能时发挥着重要作用。在安装这些库文件时,一定要注意它们的版本兼容性,不同版本之间可能存在接口差异,不兼容的版本可能会导致后续开发过程中出现各种难以调试的问题。
1.2初窥门径:理解关键数据结构
当我们搭建好开发环境后,就如同踏入了一座神秘的城堡,首先要熟悉城堡中的各种机关和暗道,也就是 vhost/virtio 中的关键数据结构。
在 vhost/virtio 的世界里,virtio_ring 数据队列是最为核心的数据结构之一,它就像是一座桥梁,连接着虚拟机(Guest)和宿主机(Host)之间的数据传输通道。virtio_ring 主要由描述符表(descriptor table)、可用环表(available ring)和已用环表(used ring)三部分组成。描述符表就像是一个货物清单,里面存放着真正的数据报文信息,每个描述符都记录了数据的起始地址、长度以及一些标志位等关键信息 ,这些信息就像是货物的标签,告诉接收方如何正确地处理这些数据。
可用环表则是 Guest 用来告知 Host 有哪些数据是可供处理的,它就像是一个待处理任务列表,Guest 将数据描述符的索引放入可用环表中,Host 从这里获取任务并进行处理。已用环表则是 Host 用来通知 Guest 哪些数据已经处理完成,Guest 可以回收相应的资源,就像是完成任务后的反馈清单。
在网络通信场景中,当 Guest 要发送网络数据包时,它会先将数据包的相关信息填充到描述符表中,然后将描述符的索引添加到可用环表中,Host 检测到可用环表有新的任务后,就会从描述符表中获取数据包并进行发送处理,处理完成后,将描述符的索引放入已用环表中,Guest 看到已用环表的反馈后,就知道哪些数据包已经成功发送,可以进行后续的操作了。理解这些数据结构的工作原理和相互之间的关系,是我们手写 vhost/virtio 的关键,只有掌握了它们,我们才能在后续的代码实现中得心应手。
1.3核心代码实现:构建 “通信桥梁”
①创建共享内存
共享内存是 vhost/virtio 实现高效通信的基础,它就像是一个公共的仓库,Guest 和 Host 都可以直接访问,从而避免了数据的多次拷贝,大大提高了通信效率。
在创建共享内存时,我们可以使用操作系统提供的相关函数,比如在 Linux 系统中,可以使用 shmget 函数来创建共享内存段。首先,我们需要定义共享内存的大小和一些权限标志 ,然后调用 shmget 函数,它会返回一个共享内存标识符,这个标识符就像是仓库的钥匙,后续我们对共享内存的操作都需要使用这个标识符。例如:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <stdio.h>#define SHM_SIZE 1024 * 1024 // 共享内存大小为1MBint main() {key_t key;int shmid;// 生成一个唯一的键值key = ftok(".", 'a'); if (key == -1) {perror("ftok");return 1;}// 创建共享内存段shmid = shmget(key, SHM_SIZE, IPC_CREAT | 0666); if (shmid == -1) {perror("shmget");return 1;}printf("共享内存创建成功,标识符为: %d\n", shmid);// 后续可以使用shmid进行共享内存的操作//...// 最后删除共享内存段if (shmctl(shmid, IPC_RMID, NULL) == -1) {perror("shmctl");return 1;}return 0;
}创建好共享内存后,还需要将其映射到进程的地址空间中,这样我们的代码才能直接访问共享内存中的数据。在 Linux 中,可以使用 shmat 函数来完成映射操作。映射完成后,就可以像访问普通内存一样对共享内存进行读写操作了。同时,我们还需要注意在适当的时候通知内核或者其他进程共享内存的相关信息,比如通过信号量或者其他同步机制,确保各个进程对共享内存的访问是安全和有序的。
②初始化 Virtio Ring
Virtio Ring 的初始化是确保数据能够正确传输的关键步骤,它就像是为桥梁设置正确的交通规则,让数据能够在 Guest 和 Host 之间顺畅地流动。
初始化 Virtio Ring 时,我们需要设置描述符、可用和已用索引等关键参数。首先,我们要为描述符表分配内存空间,并初始化每个描述符的内容,包括数据的起始地址、长度和标志位等。例如:
#include <stdint.h>#define QUEUE_SIZE 256// Virtio描述符结构
typedef struct {uint64_t addr;uint32_t len;uint16_t flags;uint16_t next;
} virtio_desc;// Virtio可用环结构
typedef struct {uint16_t flags;uint16_t idx;uint16_t ring[QUEUE_SIZE];
} virtio_avail;// Virtio已用环结构
typedef struct {uint16_t flags;uint16_t idx;struct {uint32_t id;uint32_t len;} ring[QUEUE_SIZE];
} virtio_used;// Virtio Ring结构
typedef struct {virtio_desc *desc;virtio_avail *avail;virtio_used *used;
} virtio_ring;// 初始化Virtio Ring
void init_virtio_ring(virtio_ring *ring) {// 分配描述符表内存ring->desc = (virtio_desc *)malloc(QUEUE_SIZE * sizeof(virtio_desc));if (ring->desc == NULL) {// 处理内存分配失败的情况return;}// 分配可用环内存ring->avail = (virtio_avail *)malloc(sizeof(virtio_avail));if (ring->avail == NULL) {free(ring->desc);return;}// 分配已用环内存ring->used = (virtio_used *)malloc(sizeof(virtio_used));if (ring->used == NULL) {free(ring->desc);free(ring->avail);return;}// 初始化描述符for (int i = 0; i < QUEUE_SIZE; i++) {ring->desc[i].addr = 0;ring->desc[i].len = 0;ring->desc[i].flags = 0;ring->desc[i].next = i + 1;}ring->desc[QUEUE_SIZE - 1].next = 0;// 初始化可用环ring->avail->flags = 0;ring->avail->idx = 0;// 初始化已用环ring->used->flags = 0;ring->used->idx = 0;
}在上述代码中,我们首先定义了 Virtio Ring 相关的结构,然后实现了一个初始化函数 init_virtio_ring。在函数中,我们为描述符表、可用环和已用环分配内存,并对它们进行初始化。描述符的 next 字段形成了一个环形链表,方便数据的管理和访问。可用环和已用环的 idx 字段初始化为 0,表示当前没有数据待处理或已处理。通过这样的初始化操作,Virtio Ring 就可以准备好进行数据的收发工作了。
③数据收发处理
数据的发送和接收是 vhost/virtio的核心功能,它就像是桥梁上车辆的行驶,实现了Guest 和Host之间的信息交互。
当 Guest 要发送数据时,它会首先填充数据到共享内存中,并将数据的相关信息(如数据长度、内存地址等)填充到 Virtio Ring 的描述符中。然后,Guest 将描述符的索引添加到可用环表中,并更新可用环表的 idx 索引,通知 Host 有新的数据需要处理。例如:
// Guest发送数据
void guest_send_data(virtio_ring *ring, const void *data, size_t len) {uint16_t desc_idx = ring->avail->idx;// 获取一个可用的描述符virtio_desc *desc = &ring->desc[desc_idx];// 设置描述符的地址和长度desc->addr = (uint64_t)data;desc->len = len;desc->flags = 0;// 将描述符索引添加到可用环表中ring->avail->ring[ring->avail->idx % QUEUE_SIZE] = desc_idx;// 更新可用环表的idx索引ring->avail->idx++;// 通知Host有新数据// 这里可以通过中断或者其他机制通知Host
}在发送数据的过程中,我们需要注意可用环表的索引管理,确保不会发生溢出。同时,要及时通知 Host 有新的数据到来,以便 Host 能够及时处理。
当 Host 接收到 Guest 的通知后,它会从可用环表中获取描述符的索引,然后根据索引从描述符表中获取数据的相关信息,并从共享内存中读取数据进行处理。处理完成后,Host 将描述符的索引添加到已用环表中,并更新已用环表的 idx 索引,通知 Guest 数据已经处理完成。例如:
// Host接收数据
void host_receive_data(virtio_ring *ring) {uint16_t used_idx = ring->used->idx;while (used_idx < ring->avail->idx) {uint16_t desc_idx = ring->avail->ring[used_idx % QUEUE_SIZE];virtio_desc *desc = &ring->desc[desc_idx];// 从共享内存中读取数据并处理// 这里省略具体的数据处理逻辑// 将描述符索引添加到已用环表中ring->used->ring[ring->used->idx % QUEUE_SIZE].id = desc_idx;ring->used->ring[ring->used->idx % QUEUE_SIZE].len = desc->len;// 更新已用环表的idx索引ring->used->idx++;}// 通知Guest数据已处理完成// 这里可以通过中断或者其他机制通知Guest
}在接收数据的过程中,Host 需要不断地检查可用环表和已用环表的索引,确保能够及时处理新的数据,并将处理结果反馈给 Guest。同时,也要注意已用环表的索引管理,避免出现错误。
④中断处理机制
中断处理在 vhost/virtio 中起着至关重要的作用,它就像是桥梁上的交通信号灯,能够及时通知对方有重要事件发生,从而实现高效的通信。
在 vhost/virtio 中,中断主要用于 Guest 通知 Host 有数据待处理,或者 Host 通知 Guest 数据已经处理完成。当 Guest 填充数据到共享内存并更新 Virtio Ring 后,它可以通过触发中断来通知 Host。在 Linux 系统中,可以使用 eventfd 来实现中断通知机制。
首先,Guest 创建一个 eventfd 对象,并将其与 Virtio Ring 的中断关联起来。当 Guest 需要通知 Host 时,它向 eventfd 对象写入一个值,这个值会触发 Host 的中断处理程序。例如:
#include <sys/eventfd.h>
#include <unistd.h>// Guest触发中断通知Host
void guest_notify_host(int eventfd) {uint64_t value = 1;if (write(eventfd, &value, sizeof(value)) == -1) {perror("write eventfd");}
}Host 在启动时,会监听这个 eventfd 对象,当接收到中断信号时,它会调用相应的中断处理函数来处理数据。例如:
#include <sys/eventfd.h>
#include <poll.h>// Host监听中断
void host_listen_interrupt(int eventfd, virtio_ring *ring) {struct pollfd fds[1];fds[0].fd = eventfd;fds[0].events = POLLIN;while (1) {int ret = poll(fds, 1, -1);if (ret == -1) {perror("poll");break;} else if (ret > 0 && (fds[0].revents & POLLIN)) {uint64_t value;if (read(eventfd, &value, sizeof(value)) == -1) {perror("read eventfd");continue;}// 处理数据host_receive_data(ring);}}
}在上述代码中,Guest 通过 write 函数向 eventfd 对象写入值来触发中断,Host 使用 poll 函数监听 eventfd 对象,当接收到 POLLIN 事件时,说明有中断发生,然后调用 host_receive_data 函数处理数据。通过这样的中断处理机制,Guest 和 Host 可以实现高效的数据交互,避免了不必要的轮询操作,提高了系统的性能和响应速度。
二、QEMU后端驱动
VIRTIO设备的前端是GUEST的内核驱动,后端由QEMU或者DPU实现。不论是原来的QEMU-VIRTIO框架还是现在的DPU,VIRTIO的控制面和数据面都是相对独立的设计。本文主要针对QEMU的VIRTIO后端进行分析。
控制面负责GUEST前端和VIRTIO设备的协商流程,主要用于前后端的feature协商匹配、向GUEST提供后端设备信息、建立前后端之间的数据通道。等控制面协商完成后,数据面启动前后端的数据交互流程;后面的流程中控制面负责一些配置信息的下发和通知,比如block设备capacity配置、net设备mac地址动态修改等。
QEMU负责设备控制面的实现,而数据面由VHOST框架接管。VHOST又分为用户态的vhost-user和内核态的vhost-kernel路径,前者是由用户态的dpdk接管数据路径,将数据从用户态OVS协议栈转发,后者是由内核态的vhost驱动接管数据路径,将数据从内核协议栈发送出去。本文主要针对vhost-user路径,以net设备为例进行描述。
如果要顺利的看懂QEMU后端VIRTIO驱动框架,需要具备QEMU的QOM基础知识,在这个基础上将数据结构、初始化流程理清楚,就可以更快的上手。如果只是对VIRTIO相关的设计感兴趣,可直接看下一章原理性的内容。
QEMU设备管理是非常重要的部分,后来引入了专门的设备树管理机制。而其参照了C++的类、继承的一些概念,但又不是完全一致,对于非科班出身的作者阅读起来有些吃力。因为框架相关的代码中时常使用内部数据指针cast的一些宏定义,非常影响可读性。
2.1VIRTIO设备创建流程
从实际的命令行示例入手,查看设备是如何创建的。
(1)virtio-net-pci设备命令行
首先从QEMU的命令行入手,创建一个使用virtio设备的虚拟机,可使用如下命令行:
gdb --args ./x86_64-softmmu/qemu-system-x86_64 \-machine accel=kvm -cpu host -smp sockets=2,cores=2,threads=1 -m 3072M \-object memory-backend-file,id=mem,size=3072M,mem-path=/dev/hugepages,share=on \-hda /home/kvm/disk/vm0.img -mem-prealloc -numa node,memdev=mem \-vnc 0.0.0.0:00 -monitor stdio --enable-kvm \-netdev type=tap,id=eth0,ifname=tap30,script=no,downscript=no -device e1000,netdev=eth0,mac=12:03:04:05:06:08 \-chardev socket,id=char1,path=/tmp/vhostsock0,server \-netdev type=vhost-user,id=mynet3,chardev=char1,vhostforce,queues=$QNUM -device virtio-net-pci,netdev=mynet3,id=net1,mac=00:00:00:00:00:03,disable-legacy=on其中,创建一个虚拟硬件设备,都是通过-device来实现的,上面的命令行中创建了一个virtio-net-pci设备
-device virtio-net-pci,netdev=mynet3,id=net1,mac=00:00:00:00:00:03,disable-legacy=on这个硬件设备的构造依赖于qemu框架里的netdev设备(并不会独立的对guest呈现)
-netdev type=vhost-user,id=mynet3,chardev=char1,vhostforce,queues=$QNUM上面的netdev设备又依赖于qemu框架里的字符设备(同样不会独立的对guest呈现)
-chardev socket,id=char1,path=/tmp/vhostsock0,server(2)命令行解析处理
QEMU的命令行解析在main函数进行,解析后按照qemu标准格式存储到本地。然后通过qemu_find_opts(“”)接口可以获取本地结构体中具有相应关键字的所有命令列表,对解析后的命令列表使用qemu_opts_foreach依次执行处理函数。
常用的用法,比如netdev的处理,qemu_find_opts找到所有的netdev的命令列表,qemu_opts_foreach则对列表里的所有元素依次执行net_init_netdev,初始化相应的netdev结构。
int net_init_clients(Error **errp)
{QTAILQ_INIT(&net_clients);if (qemu_opts_foreach(qemu_find_opts("netdev"),net_init_netdev, NULL, errp)) {return -1;}return 0;
}net_init_netdev初始化函数中,根据type=vhost-user,执行相应的net_init_vhost_user函数进行初始化,并为每个队列创建一个NetClientState结构,用于后续socket通信。对于"-device"参数的处理也是采用同样的方式,依次执行device_init_func,初始化相应的DeviceState结构。
if (qemu_opts_foreach(qemu_find_opts("device"),device_init_func, NULL, NULL)) {exit(1);}device后跟的第一个参数qemu称为driver,其实就是根据不同的设备类型(我们的场景为“virtio-net-pci")匹配不同的处理。而device采用的是通用的设备类,根据驱动的名字在device_init_func函数里调用qdev_device_add()接口,然后匹配到相应的DeviceClass(就是virtio-net-pci对应的DeviceClass)。
匹配到DeviceClass后,调用class里的instance_init接口,创建相应的实例,即DeviceState。
备注:看到了DeviceClass和DeviceState,这个是QEMU设备管理框架里的重要元素。
-
1)Class后缀表示一类方法实现,是相应设备类型的一类实现,对于同一设备类型的多个设备是通用的,不管创建几个virtio-pci-net设备,只需要一份VirtioPciClass。
-
2)State后缀表示具体的instance实体,每创建一个设备都要实例化一个instance结构。创建和初始化这个结构是由object_new()接口完成的,初始化还会调用相应的类定义的instance_init()接口。
Breakpoint 2, virtio_net_pci_instance_init (obj=0x5555575b8740) at hw/virtio/virtio-pci.c:3364
3364 {
(gdb) bt
#0 0x0000555555ab0c10 in virtio_net_pci_instance_init (obj=0x5555575b8740) at hw/virtio/virtio-pci.c:3364
#1 0x0000555555b270bf in object_initialize_with_type (data=data@entry=0x5555575b8740, size=<optimized out>, type=type@entry=0x5555563c3070) at qom/object.c:384
#2 0x0000555555b271e1 in object_new_with_type (type=0x5555563c3070) at qom/object.c:546
#3 0x0000555555b27385 in object_new (typename=typename@entry=0x5555563d2310 "virtio-net-pci") at qom/object.c:556
#4 0x000055555593b5c5 in qdev_device_add (opts=0x5555563d22a0, errp=errp@entry=0x7fffffffddd0) at qdev-monitor.c:625
#5 0x000055555593db17 in device_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at vl.c:2289
#6 0x0000555555c1ab6a in qemu_opts_foreach (list=<optimized out>, func=func@entry=0x55555593daf0 <device_init_func>, opaque=opaque@entry=0x0, errp=errp@entry=0x0) at util/qemu-option.c:1106
#7 0x00005555557d85d6 in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at vl.c:4593(3)设备实例初始化
在qdev_device_add函数中,首先会调用object_new,创建object(object是所有instance实例的根结构),最终是通过调用每个virtio-pci-net相应DeviceClass里的instance_init创建实例。
static void virtio_net_pci_instance_init(Object *obj)
{VirtIONetPCI *dev = VIRTIO_NET_PCI(obj);virtio_instance_init_common(obj, &dev->vdev, sizeof(dev->vdev),TYPE_VIRTIO_NET);object_property_add_alias(obj, "bootindex", OBJECT(&dev->vdev),"bootindex");
}VirtioNetPci结构体中包含其父类的实例VirtIOPCIProxy,其拥有的设备框架自定义的结构是VirtIONet的实例。对于netdev来说,它也利用了qemu的class和device框架,但netdev不像-device一样通过框架的qdev_device_add接口调用object_new完成。他的数据空间跟随在virtio_net_pci的自定义结构里,然后通过virtio_instance_init_com接口显式的调用object_initialize()函数实现“virtio-net-device”的instance初始化。
struct VirtIONetPCI {VirtIOPCIProxy parent_obj; //virtio-pci类<----继承pci-device<----继承deviceVirtIONet vdev; //virtio-net<----继承virtio-device<----继承device
};(4)virtio-net-pci设备realize流程
qdev_device_add接口中,还会调用realize接口,前面的instance_init只是实例的简单初始化,真实的设备相关的具体初始化动作都是从设备realize之后进行的。也就是相应class的realize接口。
首先在qdev_device_add()接口中,置位设备的realized属性,进而调用每一层class的realize函数。大家想一下,类似于内核驱动,设备肯定按照协议的分层从下向上识别的,先识别pci设备,然后是virtio,进而识别到virtio-net设备。所以qemu的识别过程也是这样,从最底层的realize层层调用至上层的realize接口。
参照VirtIO的Class结构,整个realize的流程整理如下:
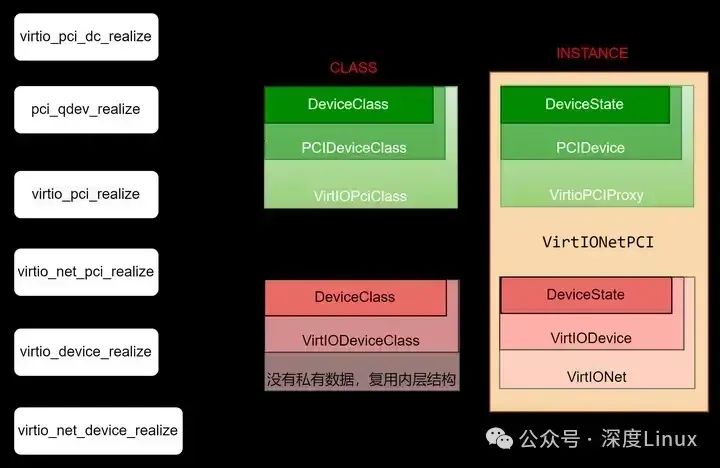
在初始化的过程中,对数据结构进行一一初始化。在pci设备的realize之前插入virtio_pci_dc_realize函数的原因是,如果是modern模式的pci设备必须是pci-express协议,所以需要置位PCIDevice里的pcie-capability标识,强行令pci设备为pcie类型。然后再进行pci层的设备初始化,初始化一个pcie设备。
virtio_pci_realize接口对VirtioPCIProxy数据结构进行了初始化,是virtio+pci需要的初始化。所以初始化了virtio设备的bar空间以及需要的pcie-capability。
virtio_net_pci_realize接口主要是触发VirtIONet里的VirtIODevice的realize流程,这才是virtio设备的realize流程(virtio_device_realize接口)。
virtio_device_realize接口实现调用了virtio_net_device_realize,对于特定virtio设备(net类型)的初始化都是在这里进行的。所以这部分是对VirtIONet及其包裹的VirtIODevice数据结构进行初始化,包括VirtIODevice结构里的vq指针就是在这里根据队列个数动态申请空间的。
virtio_device_realize接口还执行了virtio_bus_device_plugged接口,这是virtio总线上的virtio设备的plugged接口,这部分内容脱离了virtio-pci框架,进入到更上层的virtio框架。但virtio_bus派生了virtio_pci_bus,virtio_pci_bus将继承的virtio_bus的接口都设置成了自己的接口。所以最终还是调用了virtio-pci下的virtio_pci_device_plugged函数。
virtio_pci_device_plugged接口是最核心的初始化接口,modern模式初始化pci设备的bar空间读写操作接口,因为分多块读写,所以还引入了memory_region,然后添加相应的capability;legacy模式初始化pci的bar空间读写操作接口,至此virtio设备的初始化流程完成,等待与host的接口操作。
2.2VIRTIO设备实现
结合qemu的设备框架模型,分析了qemu从命令行到virtio设备创建的处理流程。现在设备创建出来了,是如何与host进行交互和操作的。本节主要讲述这部分内容,明确一点,所有的数据和操作接口都会汇聚到一个结构体,设备创建过程中的instance实例就承载了我们这个设备的所有数据和ops,所以分析这个VirtIONetPCI结构及其衍生辐射的其他数据就可以了。
struct VirtIONetPCI {VirtIOPCIProxy parent_obj; //VIRTIO-PCI数据VirtIONet vdev; //VIRTIO-NET数据
};对于VirtIOPCIProxy,选取比较重要的部分摘抄如下:
struct VirtIOPCIProxy {PCIDevice pci_dev;MemoryRegion bar; struct {VirtIOPCIRegion common;VirtIOPCIRegion isr;VirtIOPCIRegion device;VirtIOPCIRegion notify;};MemoryRegion modern_bar;MemoryRegion io_bar;uint32_t msix_bar_idx;bool disable_modern;uint32_t nvectors;uint32_t guest_features[2];VirtIOPCIQueue vqs[VIRTIO_QUEUE_MAX];VirtIOIRQFD *vector_irqfd;
};其实控制面主要就是用于协商操作,而这部分操作是通过bar空间的读写实现的。所以对virtio-pci来说,bar空间的读写操作接口是主线的流程,其余的数据结构都是围绕这组读写操作接口展开。
对于legacy设备,bar0用于virtio设备协商的空间。bar0在VirtIOPCIProxy中对应的是bar结构。bar0的读写接口对应virtio_pci_config_ops。
memory_region_init_io(&proxy->bar, OBJECT(proxy),&virtio_pci_config_ops,proxy, "virtio-pci", size);static const MemoryRegionOps virtio_pci_config_ops = {.read = virtio_pci_config_read,.write = virtio_pci_config_write,.impl = {.min_access_size = 1,.max_access_size = 4,},.endianness = DEVICE_LITTLE_ENDIAN,
};对于modern设备,采用了更灵活的方式,将virtio设备协商的空间分成4个(common、isr、device、notify)区间,每个区间的bar index和bar内offset由pci设备的capability指定。VIRTIO前端驱动解析capability识别不同的区间,进而与设备同步地址区间。
memory_region_init_io(&proxy->common.mr, OBJECT(proxy),&common_ops,proxy,"virtio-pci-common",proxy->common.size);
memory_region_init_io(&proxy->isr.mr, OBJECT(proxy),&isr_ops,proxy,"virtio-pci-isr",proxy->isr.size);
memory_region_init_io(&proxy->device.mr, OBJECT(proxy),&device_ops,virtio_bus_get_device(&proxy->bus),"virtio-pci-device",proxy->device.size);
memory_region_init_io(&proxy->notify.mr, OBJECT(proxy),¬ify_ops,virtio_bus_get_device(&proxy->bus),"virtio-pci-notify",proxy->notify.size);如上述代码所示,common区间、isr区间、device区间、notify区间的操作接口分别是common_ops、isr_ops、device_ops、notify_ops。
注册完上述ops后,GUEST对设备的bar空间进行访问,会进入相应的操作接口,VIRTIO控制面的初始化流程具体可以参见协议或者作者其他文章,文中主要是对代码的实现框架梳理,摘抄legacy模式的write接口部分内容示例说明。后端设备根据前端驱动写入的地址和数据进行相应的处理。
static void virtio_ioport_write(void *opaque, uint32_t addr, uint32_t val)
{VirtIOPCIProxy *proxy = opaque;VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus);hwaddr pa;switch (addr) {case VIRTIO_PCI_GUEST_FEATURES:/* Guest does not negotiate properly? We have to assume nothing. */if (val & (1 << VIRTIO_F_BAD_FEATURE)) {val = virtio_bus_get_vdev_bad_features(&proxy->bus);}virtio_set_features(vdev, val);break;case VIRTIO_PCI_QUEUE_PFN:pa = (hwaddr)val << VIRTIO_PCI_QUEUE_ADDR_SHIFT;if (pa == 0) {virtio_pci_reset(DEVICE(proxy));}elsevirtio_queue_set_addr(vdev, vdev->queue_sel, pa);break;case VIRTIO_PCI_QUEUE_NOTIFY:if (val < VIRTIO_QUEUE_MAX) {virtio_queue_notify(vdev, val);}break;case VIRTIO_PCI_STATUS:if (!(val & VIRTIO_CONFIG_S_DRIVER_OK)) {virtio_pci_stop_ioeventfd(proxy);}virtio_set_status(vdev, val & 0xFF);if (val & VIRTIO_CONFIG_S_DRIVER_OK) {virtio_pci_start_ioeventfd(proxy);}if (vdev->status == 0) {virtio_pci_reset(DEVICE(proxy));}break;default:error_report("%s: unexpected address 0x%x value 0x%x",__func__, addr, val);break;}
}VIRTIO_PCI_QUEUE_PFN字段是写入queue地址的,对于legacy模式,avail/used ring以及descriptor的空间连续,所以传入连续空间的首地址即可,实际传入的是页帧号。virtio_queue_set_addr接口负责将前端驱动传入的GPA记录到VirtioDevice->vq结构。
重点关注一下VIRTIO_PCI_STATUS,该位置置位VIRTIO_CONFIG_S_DRIVER_OK,说明前端驱动操作完成,可启动virtio-net设备的数据面操作。所以这个位置很重要,在virtio_set_status()接口中,会启动数据面的一系列操作,包括对VHOST的配置也是由这里触发。
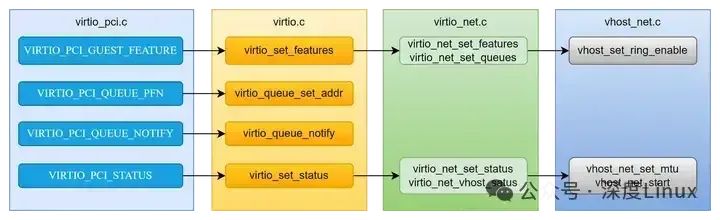
上图中就是从pcie---->virtio---->virtio-net----->vhost_net的调用关系。在设备初始化完成后,后续的操作都是由guest操作bar空间来触发,尤其是流程的推动都是对bar空间的写操作触发的。比如VIRTIO_COFNIG_S_DRIVER_OK的写入。
三、QEMU与VHOST接口描述
3.1vhost-user类型netdev设备创建
我们知道指定vhost设备的命令行如下,是根据type=vhost-user定义:
-netdev type=vhost-user,id=mynet3,chardev=char1,vhostforce,queues=$QNUM设备的命令行处理流程是统一的,也是在main函数里首先会解析命令行参数到本地的数组,然后进入标准的设备创建流程:
if (qemu_opts_foreach(qemu_find_opts("netdev"),net_init_netdev, NULL, errp)) {return -1;}所以netdev的设备创建入口就是net_init_netdev函数,在net_init_netdev函数里,根据type=vhost-user类型,执行net_init_vhost_user()接口创建设备。
该接口首先执行net_vhost_claim_chardev(),匹配其依赖的chardev,也就是命令行中的char1,找到相应的Chardev*设备。
然后调用net_vhost_user_init()接口进行真实的初始化操作。最终,vhost-user类型的netdev设备生成的结构实体是什么呢?
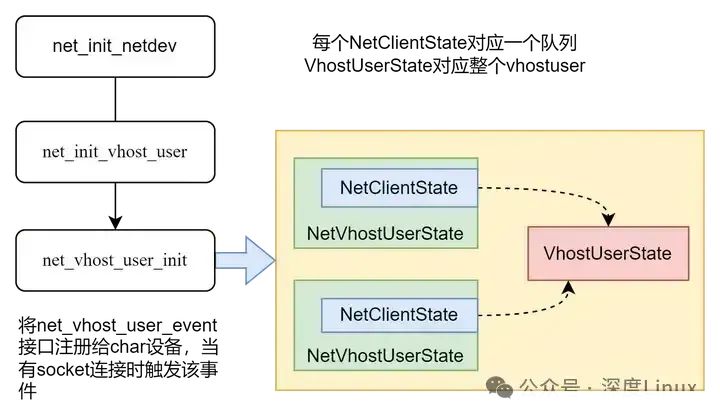
最终NetClientState被挂载到了全局变量net_clients链表中。另外,还有一组数据结构是在检测到vhost后端socket连接之后创建的。socket连接之后会调用上图中的事件处理函数net_vhost_user_event,进而调用vhost_user_start()接口。
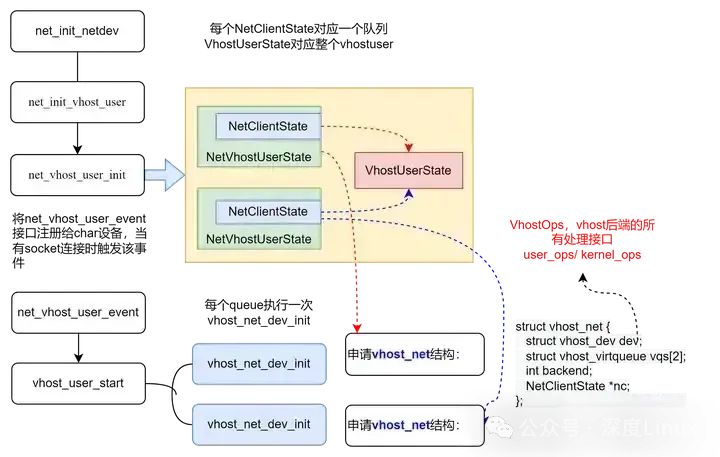
vhost-user的net设备申请的数据结构和框架,其中vhost_net中vhost_dev结构有一个重要的vhost_ops指针,对后端的接口都在这里。前面提到过vhost的后端有用户态和内核态两种,所以VhostOps的实现也有两种,因为我们指定了vhost_user类型的后端,实际vhost_ops会初始化为user_ops。VhostOps是与后端类型相关的不同的处理方式。
3.2QEMU与VHOST通信
qemu与vhost的通信是通过socket的方式。具体的实现都在vhost-user的backend接口里,以VhostOps的封装形式提供给virtio_net层使用。
(1)通信接口
VIRTIO_PCI_STATUS标识控制面协商的状态,当VIRTIO_CONFIG_S_DRIVER_OK置位时,说明控制面协商完成,此时启动数据面的传输。所以VHOST层面的交互是从这个状态启动的。而该状态通过virtio_set_status()接口调用到virtio_net_set_status()和virtio_net_vhost_status(),判断是第一次VIRTIO_CONFIG_S_DRIVER_OK标识置位,则此时认为需要启动数据面了,会调用vhost_net_start()接口启动与VHOST后端的交互,对于数据面来说,最主要的是队列相关的信息。如下图示:
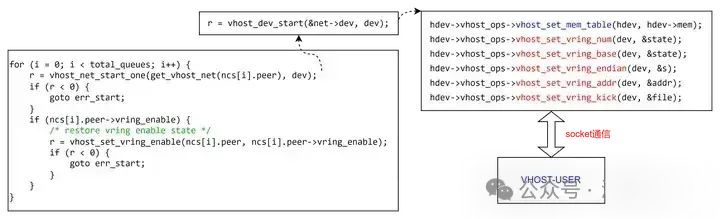
其实VhostOps里的每个接口根据名字都可以直观的推断出实现的作用,比如:
-
vhost_set_vring_num是设置队列的大小
-
vhost_set_vring_addr是设置ring的基地址(GPA)
-
vhost_set_vring_base设置last_avail_index
-
vhost_set_vring_kick是设置队列kick需要的eventfd信息
vhost_set_mem_table接口,我们知道qemu里获取的guest的地址都是GUEST地址空间的,一般是GPA,那么qemu在创建虚拟机的时候是知道GPA到HVA的映射关系的,所以根据GPA可以轻松获得HVA,进而操作进程地址空间的VA即可。但作为独立的进程,VHOST-USER拥有独立的地址空间,是不可以使用QEMU进程的VA的。所以QEMU需要将自己记录的一组或多组[GPA,HVA,size,memfd]通知给VHOST-USER。VHOST_USER收到这几个信息后将这片内存空间通过mmap映射到本地进程的地址空间,然后一并记录到记录到本地的memory table。
mmap_addr = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE,MAP_SHARED | populate, reg->fd, 0);对于为何可以使用qemu里的文件句柄fd,具体原理没有深究,看起来内核是允许这样一种共想文件句柄的方式的。注意需要在qemu的命令行里指定memory share=on的方式就可以。
-object memory-backend-file,id=mem,size=3072M,mem-path=/dev/hugepages,share=on等后续接收到vring address的配置时,VHOST-USER就通过传入的GPA,查表找到memory table里的表项,获取自有进程空间的VA,就可以访问真实的地址空间了。
(2)数据通信格式
具体的数据通信格式来说,QEMU与VHOST-USER的消息通过socket的方式,QEMU和VHOST-USER一个作为client,另一个作为server。socket文件路径是在qemu命令行里传入的。
数据通信的格式是固定的,都是一个标准的header后面跟着payload:
typedefstruct{
VhostUserRequestrequest;
uint32_tflags;
uint32_tsize;/* the following payload size */
}QEMU_PACKEDVhostUserHeader;typedefunion{
uint64_tu64;
structvhost_vring_statestate;
structvhost_vring_addraddr;
VhostUserMemorymemory;
VhostUserLoglog;
structvhost_iotlb_msgiotlb;
VhostUserConfigconfig;
VhostUserCryptoSessionsession;
VhostUserVringAreaarea;
}VhostUserPayload;typedefstructVhostUserMsg{
VhostUserHeaderhdr;
VhostUserPayloadpayload;
}QEMU_PACKEDVhostUserMsg;
其中request字段是一个union类型,标识具体的命令类型,所有的命令类型:
typedefenumVhostUserRequest{
VHOST_USER_NONE=0,
VHOST_USER_GET_FEATURES=1,
VHOST_USER_SET_FEATURES=2,
VHOST_USER_SET_OWNER=3,
VHOST_USER_RESET_OWNER=4,
VHOST_USER_SET_MEM_TABLE=5,
VHOST_USER_SET_LOG_BASE=6,
VHOST_USER_SET_LOG_FD=7,
VHOST_USER_SET_VRING_NUM=8,
VHOST_USER_SET_VRING_ADDR=9,
VHOST_USER_SET_VRING_BASE=10,
VHOST_USER_GET_VRING_BASE=11,
VHOST_USER_SET_VRING_KICK=12,
VHOST_USER_SET_VRING_CALL=13,
VHOST_USER_SET_VRING_ERR=14,
VHOST_USER_GET_PROTOCOL_FEATURES=15,
VHOST_USER_SET_PROTOCOL_FEATURES=16,
VHOST_USER_GET_QUEUE_NUM=17,
VHOST_USER_SET_VRING_ENABLE=18,
VHOST_USER_SEND_RARP=19,
VHOST_USER_NET_SET_MTU=20,
VHOST_USER_SET_SLAVE_REQ_FD=21,
VHOST_USER_IOTLB_MSG=22,
VHOST_USER_SET_VRING_ENDIAN=23,
VHOST_USER_GET_CONFIG=24,
VHOST_USER_SET_CONFIG=25,
VHOST_USER_CREATE_CRYPTO_SESSION=26,
VHOST_USER_CLOSE_CRYPTO_SESSION=27,
VHOST_USER_POSTCOPY_ADVISE=28,
VHOST_USER_POSTCOPY_LISTEN=29,
VHOST_USER_POSTCOPY_END=30,
VHOST_USER_MAX
}VhostUserRequest;
四、VHOST-USER框架设计
VHOST-USER是DPDK一个重要的功能,主要的代码在lib/librte_vhost下。
VHOST的框架还是比较直接的,整体看起来DPDK的代码框架比QEMU的简洁很多,更加容易理解。DPDK主要是作为一个接口库使用,所以lib下面也是对外提供操作接口,供调用方使用。
4.1VHOST初始化流程
VHOST模块初始化流程的关键接口有三个:
①rte_vhost_driver_register(const char *path, uint64_t flags)
申请并初始化vhost_user_socket结构,vsocket指针存入全局数组vhost_user.vsockets[]中;
打开path对应的socket文件,fd存入vsocket->socket_fd中。②rte_vhost_driver_callback_register(const char *path, struct vhost_device_ops const * const ops)
注册vhost_device_ops到vsocket->ops中。③rte_vhost_driver_start(const char *path)
根据VHOST是client或者server,选择vhost_user_start_client()/vhost_user_start_server()两种路径,看一下vhost作为client的路径。vhost_user_start_client():
1)vhost_user_connect_nonblock,连接socket;
2)vhost_user_add_connection(int fd, struct vhost_user_socket *vsocket)a、申请vhost_user_connection结构体;b、申请virtio_net结构体,存储到全局数组vhost_devices,返回其在数组中的索引vid;c、conn配置,conn->fd =fd; conn->vsocket=vsocket; conn->vid =vid;d、注册socket接口的处理函数fdset_add(&vhost_user.fdset, fd, vhost_user_read_cb, NULL, conn);整个初始化流程到这里就结束了,后面就开始等待qemu的消息,对应的消息处理函数就是vhost_user_read_cb函数。
4.2VHOST与QEMU通信流程
初始化流程创建了vsocket结构(与qemu的socket实体),创建了virtio_net结构(设备实体),并注册了socket消息的处理函数,后面就可以监听socket的信息,作为qemu的后端完善和建立整个流程。作为virtio设备的backend,vhost在初始化完成后,所有的动作都是由前端的socket消息触发的。
所有的消息处理函数以MSG的request请求类型字段作为索引,记录在vhost_message_handlers数组中。具体的处理不详细描述,主要就是将接收到的信息记录到本地,供数据面启动后使用。
VHOST_CONFIG:/tmp/vhostsock0:connected
VHOST_CONFIG:newdevice,handleis0
VHOST_CONFIG:readmessageVHOST_USER_GET_FEATURES
VHOST_CONFIG:readmessageVHOST_USER_GET_PROTOCOL_FEATURES
VHOST_CONFIG:readmessageVHOST_USER_SET_PROTOCOL_FEATURES
VHOST_CONFIG:negotiatedVhost-userprotocolfeatures:0xcbf
VHOST_CONFIG:readmessageVHOST_USER_GET_QUEUE_NUM
VHOST_CONFIG:readmessageVHOST_USER_SET_SLAVE_REQ_FD
VHOST_CONFIG:readmessageVHOST_USER_SET_OWNER
VHOST_CONFIG:readmessageVHOST_USER_GET_FEATURES
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_CALL
VHOST_CONFIG:vringcallidx:0file:53
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_CALL
VHOST_CONFIG:vringcallidx:1file:54
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:0
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:1
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:0
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:1
VHOST_CONFIG:readmessageVHOST_USER_SET_FEATURES
VHOST_CONFIG:negotiatedVirtiofeatures:0x140408002
VHOST_CONFIG:readmessageVHOST_USER_SET_MEM_TABLE
VHOST_CONFIG:guestmemoryregion0,size:0xc0000000
guestphysicaladdr:0x0
guestvirtualaddr:0x7fff00000000
hostvirtualaddr:0x2aaac0000000
mmapaddr:0x2aaac0000000
mmapsize:0xc0000000
mmapalign:0x40000000
mmapoff:0x0
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_NUM
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_BASE
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ADDR
VHOST_CONFIG:reallocatevqfrom0to1node
VHOST_CONFIG:reallocatedevfrom0to1node
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_KICK
VHOST_CONFIG:vringkickidx:0file:56
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_CALL
VHOST_CONFIG:vringcallidx:0file:57
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_NUM
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_BASE
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ADDR
VHOST_CONFIG:reallocatevqfrom0to1node
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_KICK
VHOST_CONFIG:vringkickidx:1file:53
VHOST_CONFIG:virtioisnowreadyforprocessing.
VHOST_DATA:(0)devicehasbeenaddedtodatacore1
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_CALL
VHOST_CONFIG:vringcallidx:1file:58
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:0
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:1
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:0
VHOST_CONFIG:readmessageVHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG:setqueueenable:1toqpidx:1
VHOST_DATA:liufengTXvirtio_dev_tx_split:dev(0)queue_id(1),soc_queue(1)
从上面的日志中找到一条消息“virtio is now ready for processing”,说明从这里开始VHOST启动数据面的收发。查看上面的日志,是在两个队列的地址信息配置完成之后。对应到QEMU的流程,就是QEMU里的VIRTIO设备device_status的VIRTIO_CONFIG_S_DRIVER_OK状态标志置位时,调用virtio_net_start()接口做了这个动作。
至此,整个数据通道完全建立。
一般的使用场景是在OVS添加一个端口,关联到刚刚分析的VHOST-USER(指定与qemu的socket-path),实现对GUEST网口的数据收发。VHOST-USER作为client的场景,可以使用如下的命令行建立一个端口。
ovs-vsctl add-port br0 vhost-client-1 \-- set Interface vhost-client-1 type=dpdkvhostuserclient \options:vhost-server-path=$VHOST_USER_SOCKET_PATH五、用QEMU实现的virtio网卡
virtio network device是一个虚拟以太网卡,它支持 TX/RX 多队列。空缓冲区放置在RX virtqueue中用于接收数据包,而输出的数据包则放在TX virtqueue中进行传输。另一个 virtqueue 用于driver, device之间的管理通信,如设置mac 地址或修改队列的数量。virtio network device支持许多卸载功能,如checksum计算,GSO/GRO,并让真实物理网络设备来做这些。
为了发送数据包,driver在available ring中填入一个描述符,其中包含卸载信息和数据帧缓冲区, 数据帧可以以SG(scatter/gather)形式由多个描述串联组成。Descriptor table/available ring/used ring这些数据结构由guest中的driver分配并管理,但由于device实际位于qemu内,而qemu可以访问所有guest内存,所以device能够定位缓冲区并读取或写入它们。
发送一个报文时 virtio-net device和 virtio-net driver的处理流程:
-
qemu启动guest后由guest内部的pci总线机制发现virtio设备并加载virtio-net driver。
-
guest内部的virtio-net driver分配好Descriptor table/available ring/used ring等核心数据结构,并写入PCI MMIO寄存器,进而后端virtio-net device也知道了virtqueue的内存布局。
-
driver填充完要发送的数据包后,它会触发“available ring notification”(写PCI MMIO中的notification),将控制权返回给 QEMU。
-
virtio-net device通过sendmsg系统调用将数据包写入到内核tun设备上,在host kernel看来,网络协议栈从tun设备上收到一个来自VM的报文。进一步的host kernel网络协议栈可以使用OVS等转发机制转发这个报文。
-
Qemu 中的virtio-net device通知guest缓冲区操作(读取或写入)已完成,它通过将数据放入虚拟队列并发送used ring notification来触发guest vCPU 中的中断。
接收数据包的过程与发送数据包的过程类似。唯一的区别是,在这种情况下,空缓冲区由guest预先分配并供device使用,以便它可以将传入数据写入它们。
Qemu实现virtio-net device的缺点:
-
性能开销:虚拟化技术本身会引入一定的性能开销。尽管virtio-net是为了提高虚拟网络设备性能而设计的,但与原生网络设备相比仍然会有一些额外的开销。
-
虚拟化复杂性:QEMU是一个强大而复杂的虚拟化软件,实现和配置virtio-net设备需要一定的技术和经验。对于不熟悉QEMU或者虚拟化技术的人来说,可能会面临一定的学习曲线和困难。
-
驱动兼容性:虽然virtio-net已经得到了广泛支持,并且常见操作系统都提供了对其驱动程序的支持,但仍然可能存在某些情况下驱动程序不完全兼容或出现问题。这可能导致网络功能不稳定或无法正常工作。
-
虚拟化依赖:使用virtio-net需要依赖QEMU等虚拟化软件,在某些环境中可能存在限制或约束。例如,在嵌入式系统或特殊硬件平台上,可能无法轻松地部署和运行QEMU。
5.1Vhost协议
为了解决qemu实现virtio-net device的限制,设计了 vhost 协议。vhost API 是一种基于消息的协议,它允许hypervisor (qemu)将数据平面卸载到另一个更有效地执行数据转发的组件(handler)。使用此协议, hypervisor向handler发送以下配置信息:
hypervisor的内存布局。这样,handler可以在hypervisor的内存空间中定位虚拟队列和缓冲区。
一对文件描述符(kick fd/call fd),用于handler发送和接收 virtio 规范中定义的通知。这些文件描述符在handler和 KVM 之间共享,因此它们可以直接通信而无需hypervisor的干预。请注意,每个虚拟队列仍然可以动态禁用此通知。
在此过程之后, hypervisor将不再处理数据包(从虚拟队列读取或写入/从虚拟队列写入)。相反,数据平面将完全卸载到handler,它现在可以直接访问 virtqueues 的内存区域以及直接向guest发送和接收通知。
vhost 消息可以在任何主机本地传输协议中交换,例如 Unix 套接字或字符设备,并且虚拟机管理程序可以充当服务器或客户端(在通信通道的上下文中)。hypervisor是协议的领导者,卸载设备是handler,它们中的任何一个都可以发送消息。Vhost protocol并没有规定数据面一定要卸载至哪里,它既可以是host kernel(vhost-net), 也可以是host用户态(vhost-user),还可以是硬件。以下主要针对卸载至host kernel即vhost-net。
5.2vhost-net虚拟化网络技术
vhost-net是一个内核驱动程序,它实现了 vhost 协议的handler,以实现高效的数据平面,即数据包转发。在这个实现中,qemu 和 vhost-net 内核驱动程序(处理程序)使用 ioctls 来交换 vhost 消息,并且使用几个称为 irqfd 和 ioeventfd 的类似 eventfd 的文件描述符来与guest交换通知。
当加载 vhost-net 内核驱动程序时,它会创建/dev/vhost-net字符设备。当 qemu启动参数支持vhost-net 时,它会打开此字符设备并使用多个 ioctl调用初始化 vhost-net 实例。这些对于将hypervisor与 vhost-net 实例相关联、准备 virtio 功能协商并将guest物理内存映射传递给 vhost-net 驱动程序是必需的。在初始化期间,vhost-net 内核驱动程序创建了一个名为 vhost-$pid 的内核线程,其中 $pid 是管理程序进程 pid。该线程称为“vhost 工作线程”。
Tap 设备仍然用于guest将报文发送至host kernel,但现在是vhost工作线程处理 I/O 事件,即它轮询guest drvier的通知或tap事件,并转发数据。
Qemu 分配一个eventfd并将其注册到 vhost 和 KVM 以实现通知绕过。vhost-$pid 内核线程轮询它,当guest写特定PCI MMIO地址时触发vm-exit进入KVM,此时KVM检测到地址关联了一个ioeventfd,所以写入此fd。这种机制被命名为 ioeventfd。这样,对特定guest内存地址的简单读/写操作不需要经过昂贵的 QEMU 进程唤醒,可以直接路由到 vhost 工作线程。这样做也有异步的好处,不需要 vCPU 停止(所以不需要立即进行上下文切换)。
另一方面,qemu 分配另一个 eventfd 并将其再次注册到 KVM 和 vhost 以进行直接 vCPU 中断注入。这种机制称为irqfd,它允许主机中的任何进程通过写入irqfd来将 vCPU 中断注入guest,具有相同的优点(异步、不需要立即上下文切换等)。
请注意,virtio 数据包处理后端中的此类更改对于仍然使用标准 virtio 接口的guest来说是完全透明的。
在QEMU中,virtio是一种用于虚拟机和宿主机之间进行高性能数据传输的标准化接口。而virtio-net则是基于virtio标准实现的一种虚拟网络设备,用于连接虚拟机和宿主机的网络通信。
具体来说,在使用QEMU创建虚拟机时,可以通过以下步骤实现virtio-net网卡:
-
启动QEMU命令时添加参数 "-device virtio-net" 或者 "-netdev user,id=net0 -device virtio-net,netdev=net0",其中"net0"为网络设备的名称。
-
QEMU将会创建一个名为"net0"的virtio-net网卡,并将其与虚拟机关联起来。
-
虚拟机内部操作系统会将这个virtio-net网卡识别为一个正常的物理网卡,并加载相应的驱动程序。
-
宿主机上运行的QEMU负责处理从虚拟机发送过来的数据包,并转发到宿主机上与该网卡对应的物理网络设备上,或者反向地将从物理网络设备接收到的数据包传递给虚拟机。
通过使用virtio-net网卡,可以提供高性能、低延迟和可扩展性好的网络通信,在虚拟化环境中更加有效地利用计算资源,并提供与原生网络设备相当的性能。
QEMU命令行参数:
qemu-system-x86_64 -netdev user,id=net0 -device virtio-net,netdev=net0启动脚本示例(bash):
#!/bin/bash
qemu-system-x86_64 \-netdev user,id=net0 \-device virtio-net,netdev=net0 \[其他QEMU参数]请注意,上述代码只是一个简单的示例,具体的QEMU参数和配置可能因实际情况而有所不同。你可以根据自己的需求进行相应的修改和调整。
此外,还需要确保在虚拟机内部操作系统中加载了virtio-net驱动程序,并正确配置网络设置。具体步骤和操作方式取决于虚拟机所使用的操作系统。