爬虫学习笔记(二)--web请求过程
Web请求全过程(重要)
从输入完网址(如输入百度网址)到返回页面以及页面中的数据这一完整的过程发生了什么事情?
服务器端渲染
在服务器端直接把数据和html整合,统一返回给浏览器,在页面源代码中能看到数据
例子:百度搜索某一明星信息
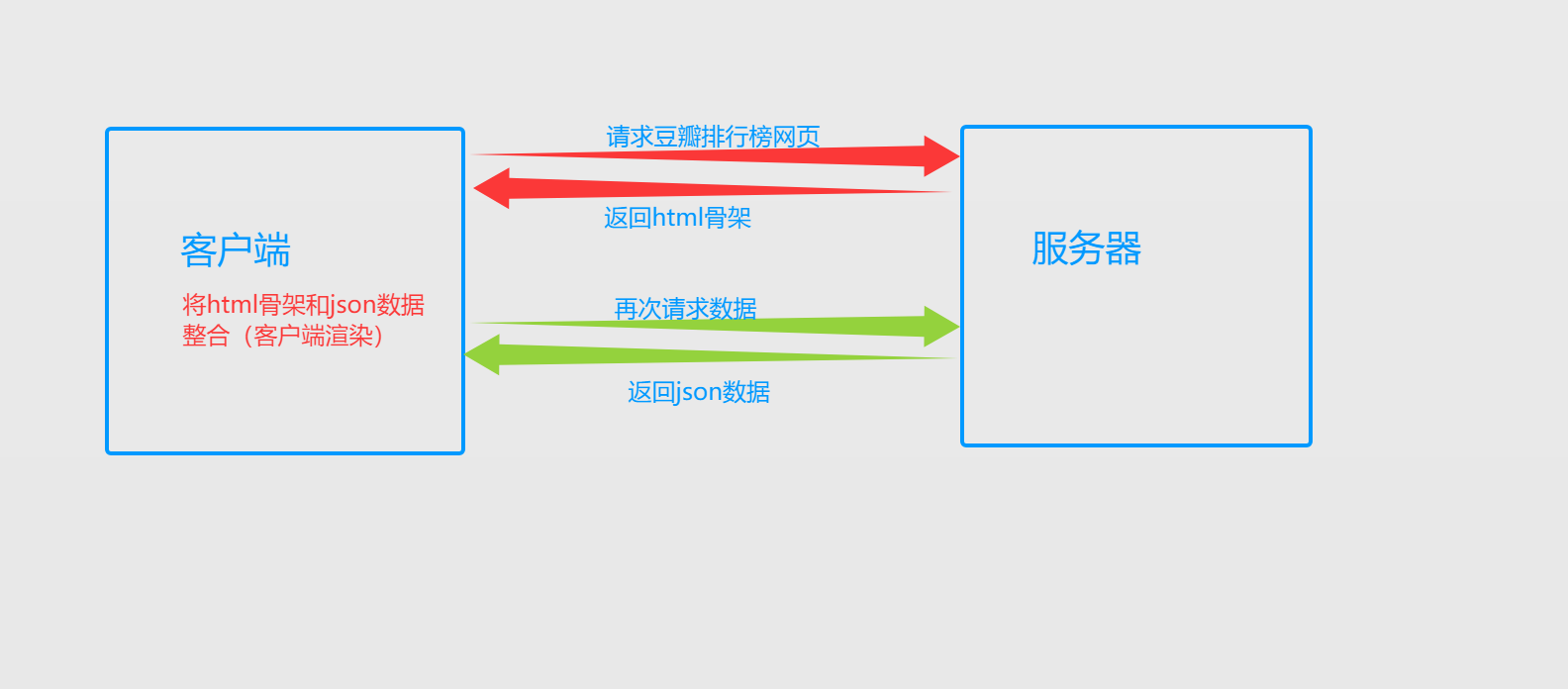
客户端渲染
数据和Html在客户端整合,第一次请求只要一个html骨架,第二次请求拿到数据,在客户端整合html和数据后进行统一页面展示,而在页面源代码中(仅有html页面)看不到数据
例子:请求豆瓣排行榜网页
浏览器抓包工具
打开抓包工具的方法:
右键->检查
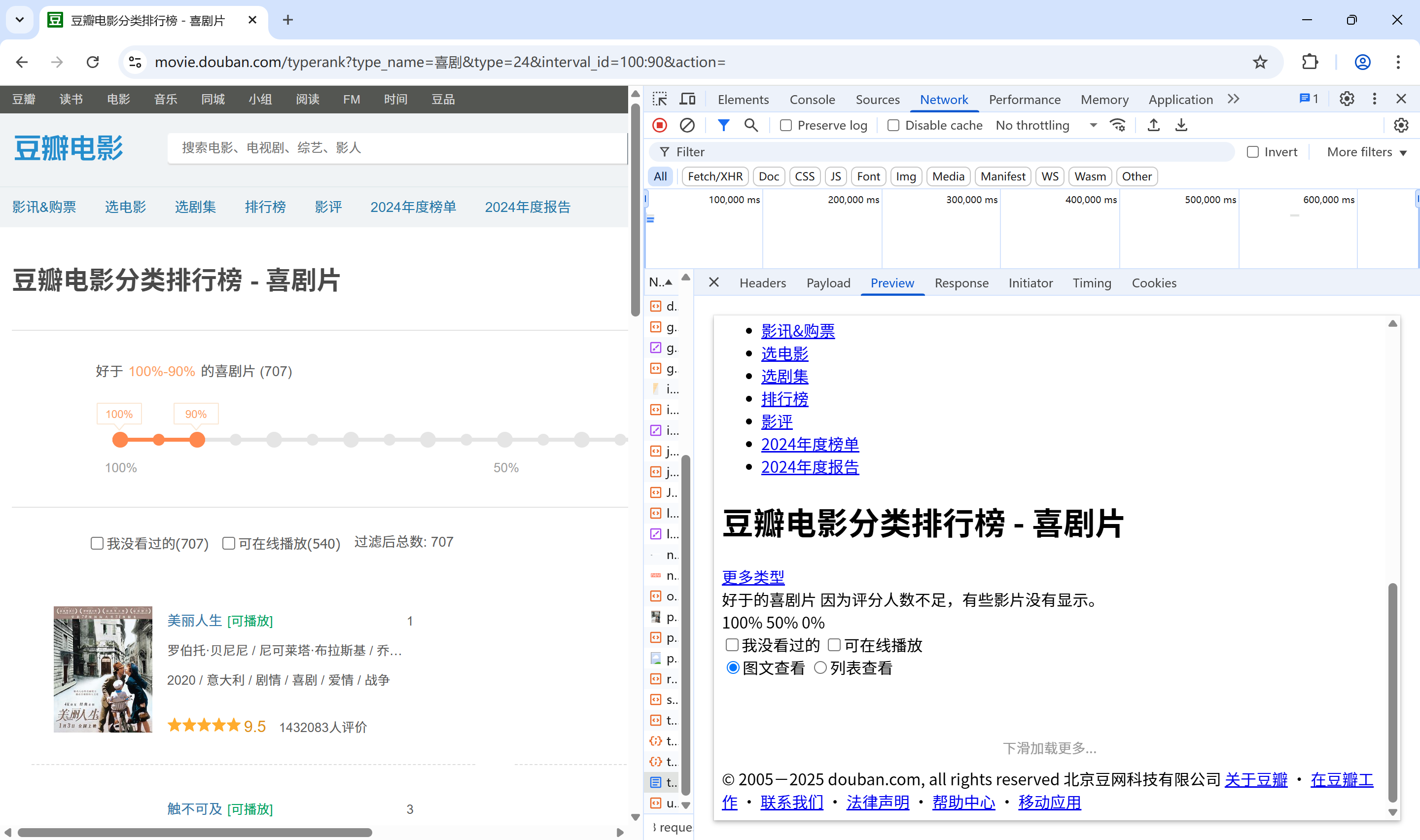
重新回车上面的url地址,下面network就会显示这次完整的url请求的各种数据图片,找到左下角typerank这一个url请求,点击右面的header查看,发现这个请求的url地址与这个网页首页面的url地址相同,这个就是第一次的请求
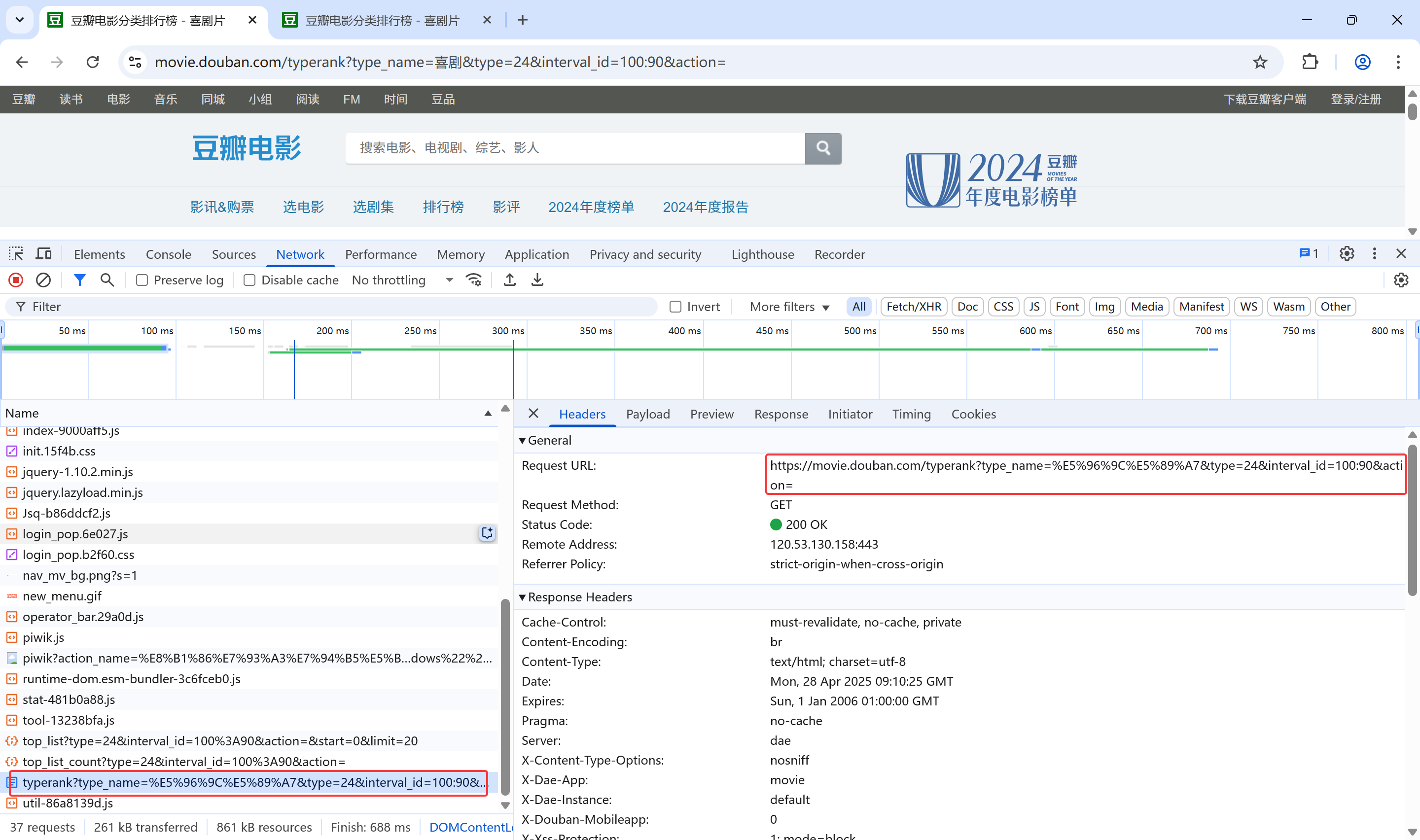
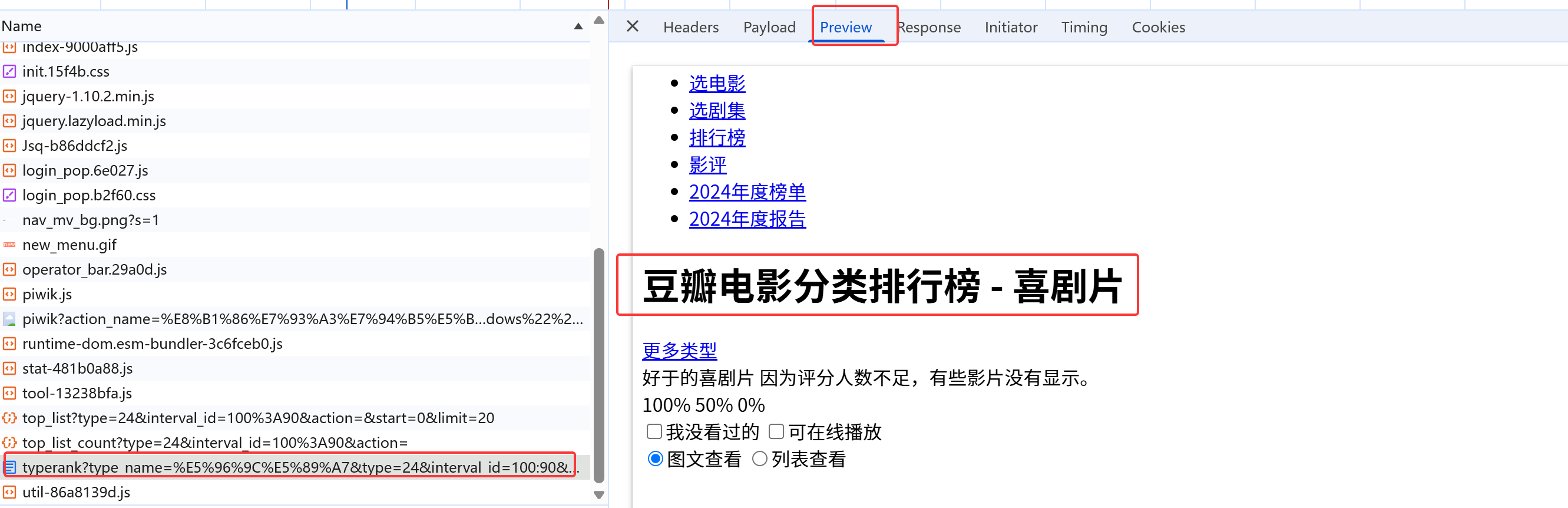
第一次请求响应的页面(骨架)
点击preview提前预览这个页面,查看第一次请求返回的内容 ,发现这里面内容很简陋,像电影排行的具体电影信息等并未出现,说明第一次url请求只是返回一个框架,并没有真正想要查看的具
体的数据
下面是提前预览的与实际页面的对比,左边实际的页面有具体的电影信息如下图美丽人生(相关的放映年份、主演人员、豆瓣评分),右边的首次访问页面返回的数据中没有这些信息,右边没有任何的统计数据信息,只有分类等级的一些框架显示
真正的数据在哪里? (第二次请求-数据)
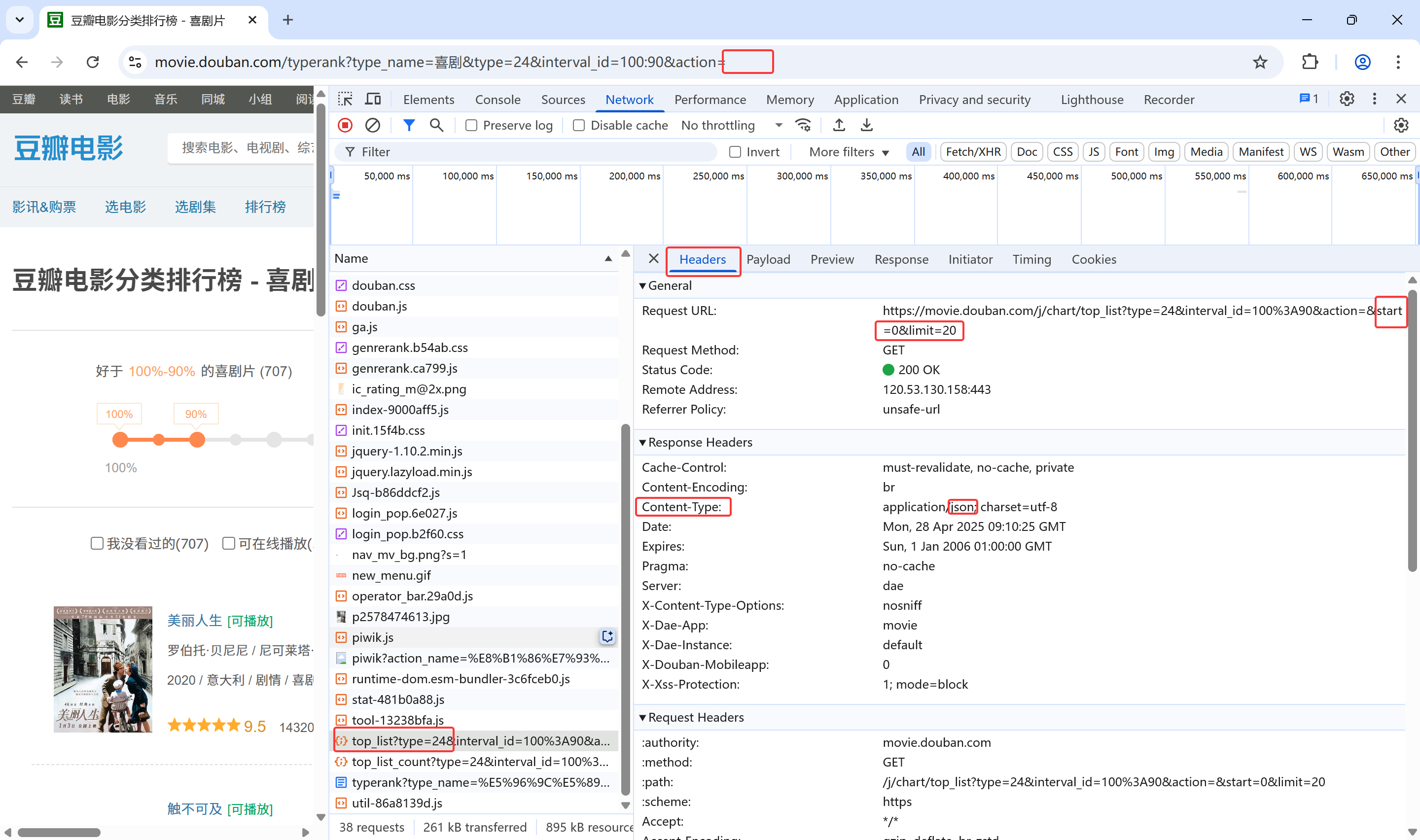
点击name为"top-list?type=248*"的字样,找到header信息,查看请求的url,发现该url与顶部请求信息的url相比多了&start=0&limit=20字样的信息,返回数据内容的类型content-type为json格式的数据
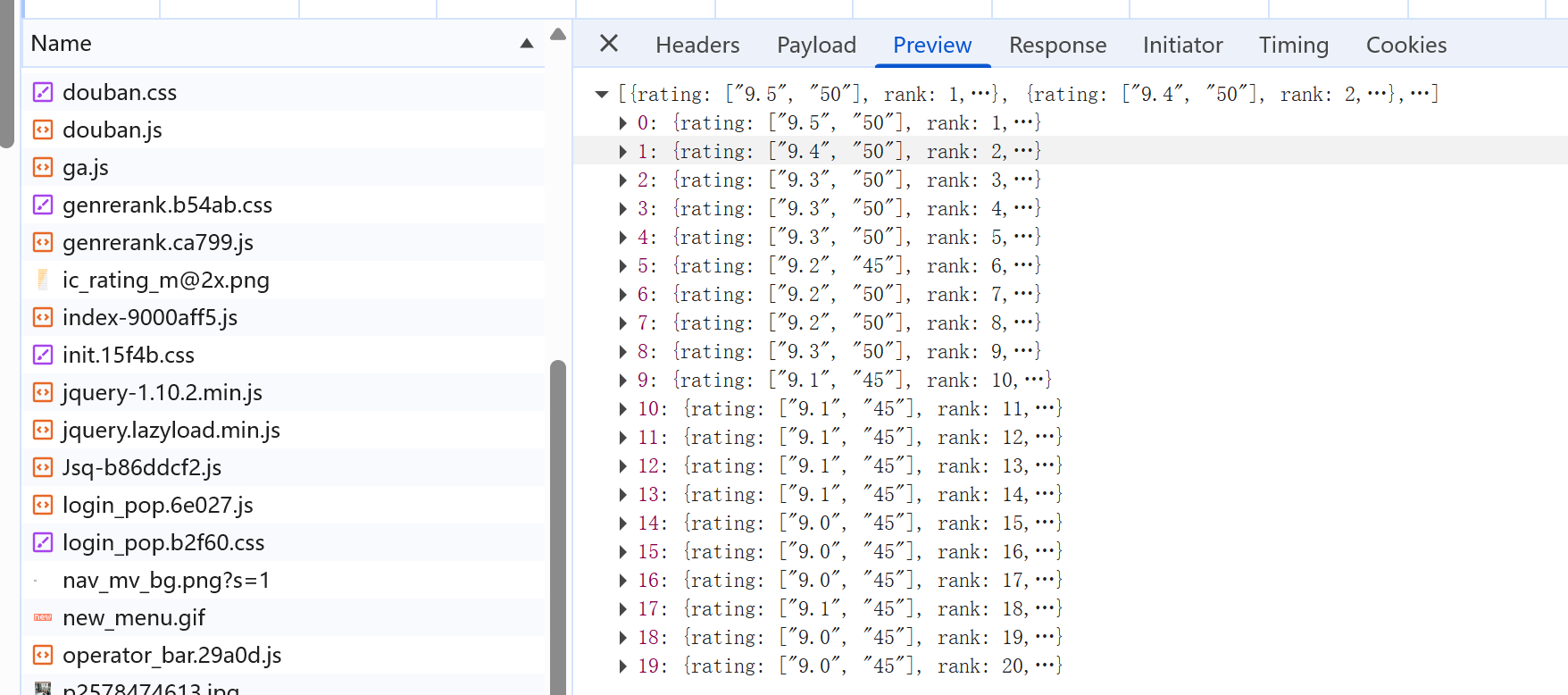
点击preview,如下图返回的是20个json序列
点击第0个序列查看具体数据,如下图所示,第0个序列的数据就是排名第一的电影的数据信息,主演、电影名、电影类型都可以一一对应上
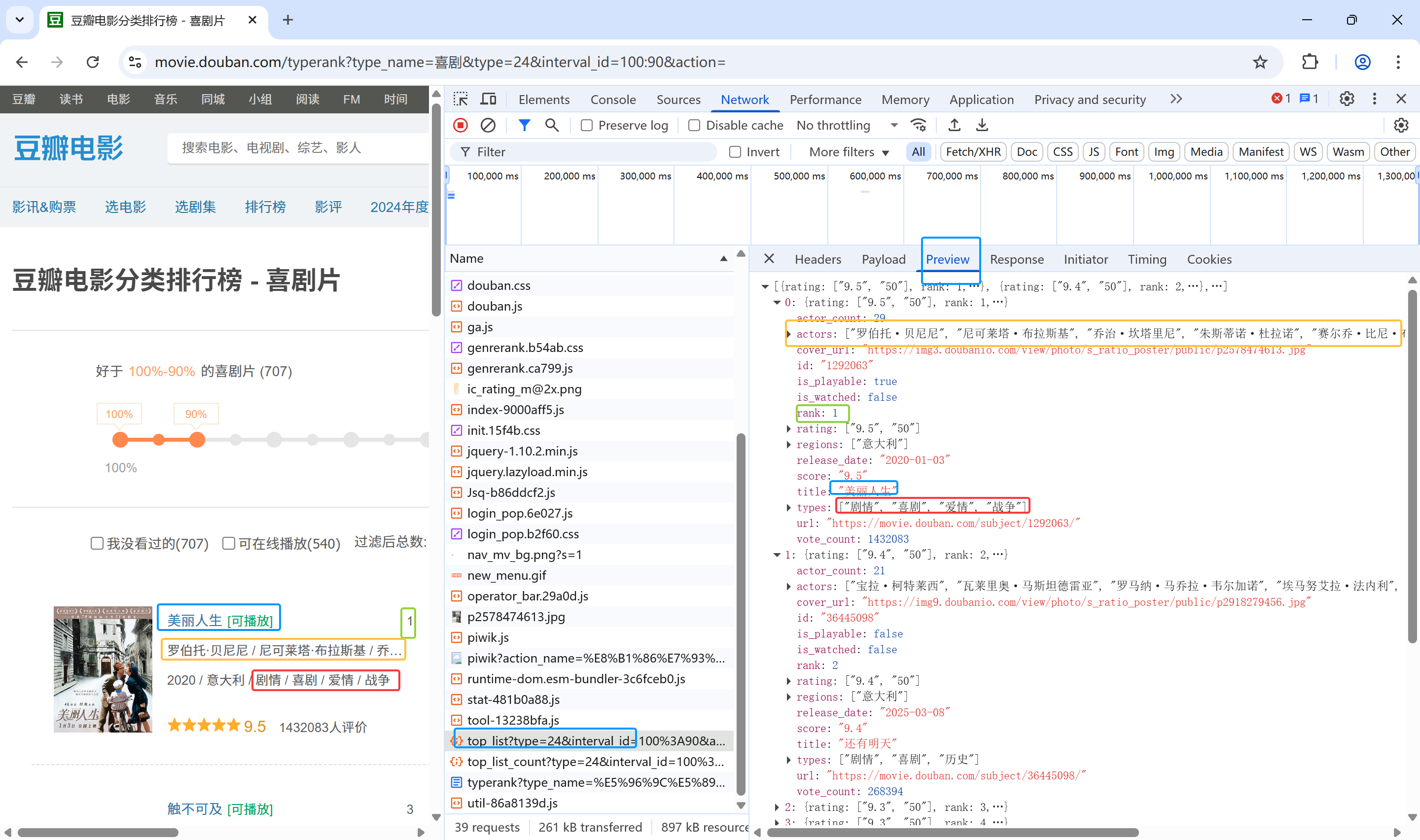
爬虫需要爬取的
所以如果想爬虫爬到数据,就没必要把第一次请求的骨架爬取,只需要爬取第二次请求返回的json数据(正好是规整的数据)如下图所示