C++实时统计数据均值、方差和标准差
文章目录
- 1. 算法原理
- 2. 类设计
- 3. 完整代码实现
- 4. 总结
本文采用了一种递推计算方法(Welford 算法)实时更新数据的均值、方差和标准差,其算法原理及实现如下。
1. 算法原理
Welford算法是由B.P.Welford于1962年提出的,用于计算样本均值和样本方差的算法。该算法通过一次遍历数据即可更新方差,减少了计算时间和舍入误差,具有更好的数值稳定性。
Welford算法通过以下递推公式计算样本均值和方差:
初始化:
M 1 = x 1 , S 1 = 0 M_1 = x_1, S_1 = 0 M1=x1,S1=0
对于接下来的样本值x_k,使用递推公式:
M k = M k − 1 + ( x k − M k − 1 ) / k M_k = M_{k-1} + (x_k - M_{k-1}) / k Mk=Mk−1+(xk−Mk−1)/k
S k = S k − 1 + ( x k − M k − 1 ) ( x k − M k ) S_k = S_{k-1} + (x_k - M_{k-1}) (x_k - M_k) Sk=Sk−1+(xk−Mk−1)(xk−Mk)
其中,2 ≤ k ≤ n,第k个样本方差估计为
s 2 = S k / ( k − 1 ) s^2 = S_k / (k - 1) s2=Sk/(k−1)
Welford算法相比传统的Two-pass和Naive方法有以下优势:
- 一次遍历
传统方法需要遍历两次数据(Two-pass方法)或一次遍历但需要保存所有数据(Naive方法),而Welford算法只需一次遍历即可完成计算。 - 数值稳定性
传统方法在处理大数据集时容易产生舍入误差,而Welford算法通过增量方式更新,减少了误差积累。 - 减少计算时间
由于减少了遍历次数和计算步骤,Welford算法在计算效率和速度上更具优势。 - 应用场景
Welford算法广泛应用于各种需要在线计算统计量的场景,特别是在深度学习中,如PyTorch的LayerNorm实现中就采用了Welford算法来计算方差。LayerNorm在深度学习模型中用于归一化层输出,帮助模型更好地收敛和学习
2. 类设计
-
成员变量:
m_num:已处理的数据点数量。m_mean:当前均值。m_sum:递推计算的平方和(用于方差计算)。
-
方法:
update(double x):更新统计量。currentMean(),variance(),stdDev():获取当前统计值。reset():重置统计状态。
3. 完整代码实现
StatisticMethod.h
#pragma onceclass StatisticMethod
{
public:StatisticMethod();~StatisticMethod();void update(double x);double currentMean() const;double variance() const;double stdDev() const;void reset();private:int m_num; // 数据点数量double m_mean; // 当前均值double m_sum; // 平方和
};
StatisticMethod.cpp
#include "stdafx.h"
#include <iostream>
#include <cmath>
#include "StatisticMethod.h"StatisticMethod::StatisticMethod() : m_num(0), m_mean(0.0), m_sum(0.0)
{//使用参数列表初始化
}
StatisticMethod::~StatisticMethod()
{}
// 添加新数据点,更新统计量
void StatisticMethod::update(double x)
{m_num++;double delta = x - m_mean;m_mean += delta / m_num; // 递推更新均值double delta2 = x - m_mean;m_sum += delta * delta2; // 递推更新平方和
}// 获取当前均值
double StatisticMethod::currentMean() const
{return m_mean;
}// 计算样本方差(无偏估计)
double StatisticMethod::variance() const
{if (m_num < 2) return 0.0; // 避免除以0return m_sum / (m_num - 1);
}// 计算标准差
double StatisticMethod::stdDev() const
{return std::sqrt(variance());
}// 重置统计量
void StatisticMethod::reset()
{m_num = 0;m_mean = 0.0;m_sum = 0.0;
}
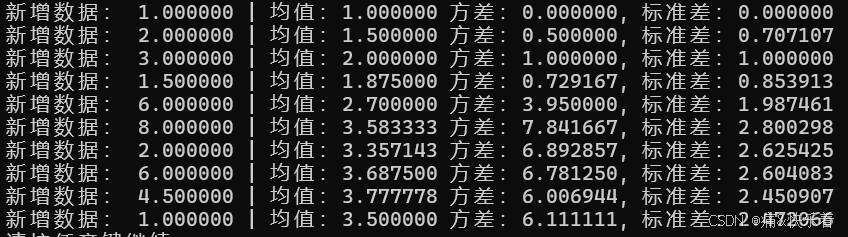
int main()
{StatisticMethod stats;double data[10] = { 1.0, 2.0, 3.0, 1.5, 6.0, 8.0, 2.0, 6.0, 4.5, 1.0 };for (int i = 0; i < 10; i++){stats.update(data[i]);printf("新增数据: %f | 均值:%f 方差:%f, 标准差:%f\n", data[i], stats.currentMean(), stats.variance(), stats.stdDev());}system("pause");return 0;
}
4. 总结
- 采用Welford 算法:避免传统方法(如先计算总和再求均值)的浮点数精度损失,保证了数值稳定性。
- 处理边界条件:当数据量(
n < 2)时,方差返回0.0。 - 本文算法的优势:内存效率高,仅需要维护3个成员变量,适合实时或大数据场景。
- 对比传统算法:避免存储全部数据,计算复杂度O(1)。