《Masked Autoencoders Are Scalable Vision Learners》---CV版的BERT
目录
一、与之前阅读文章的关系?
二、标题:带掩码的自auto编码器是一个可拓展的视觉学习器
三、摘要
四、核心图
五、结果图
六、不同mask比例对比图
七、“Introduction” (He 等, 2021, p. 1) 引言
八、“Related Work” (He 等, 2021, p. 3)相关工作
九、“Approach” (He 等, 2021, p. 3)MAE模型
1.Masking 如何掩码的?
2.Encoder 编码器架构
3.Decoder 解码器
4.Reconstruction Target 如何重构原始像素?
5.Simple implementation 简单实现
十、“. ImageNet Experiments” 实验部分
十一、结论
论文:Masked Autoencoders Are Scalable Vision Learners
参考博文:MAE 论文逐段精读【论文精读】 - 哔哩哔哩
作者: Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick
会议: ICLR 2022代码:https://github.com/facebookresearch/mae
一、与之前阅读文章的关系?
Transformer:纯基于注意力机制的编码器和解码器,在机器翻译任务上比基于RNN的架构好很多
BERT:使用transformer的编码器,拓展到一般的NLP任务上,使用完形填空类似的自监督的训练机制,可以在一个大规模无标号的数据上训练出非常好的模型,加速了transformer架构在NLP领域的应用
VIT:将transformer用到CV上面,把图片割成16*16的小方块,每个方块做一个词,然后放到transformer进行训练---->训练数据足够大时精度越高
MAE:BERT的一个CV版本,基于VIT的这篇文章,但是把整个训练拓展到没有没有标号的数据上面(和BERET一样),通过完形填空来获取图片的一个理解【但不是第一个将BERT拓展到CV上的工作】
二、标题:带掩码的自auto编码器是一个可拓展的视觉学习器
auto:代表自模型,这一大类模型的特点是标号y和样本x来自同一个东西【如语言模型:每次用前面的词去预测下面一个词,在一个样本中,预测的词既是标号,也是另外一个样本的x本身】。。。。本篇图片的标号也是图片本身【和之前很多工作区分开来了】
三、摘要
核心思想:随机挡住图片的大部分区域,然后让模型根据剩下的碎片猜出被挡住的部分
【来源于BERT带掩码的语言模型,patch===》image的一个块,预测的是这一个块的所有像素】
核心设计一:非对称的encoder-decoder架构,MAE的编码器只编码可见的patches,被masked的块不编码,而解码器需要重构所有块。
-
encoder只作用在可见的patch上,被mask掉的patch不做计算,可节约计算,提升训练速度
-
decoder用于重构被mask掉的像素
(“非对称”意味着编码器和解码器在结构或功能上不是完全对称的,它们的复杂度、层数、参数数量或其他方面有所不同。在MAE(Masked Autoencoder)中,编码器只处理未被遮挡的图像块25%,而解码器需要处理所有块100%,包括被遮挡的部分。Decoder更加轻量的)
核心设计二:高掩码率,掩盖很大一部分输入图像,例如 75%,才能得到一个比较好的自监督训练效果====》构造了一个比较有挑战的任务
(就像考试时题目越难,复习效果越好。大范围遮挡迫使模型深入理解图像的整体结构,而不是死记局部细节。)
实际效果:
-
图像分类:用MAE训练的模型,在ImageNet数据集(1000类图片分类)上准确率达到87.8%,无需人工标注,超过了传统需要人工标注的方法。
-
MAE只用小规模数据集,并且使用自监督方法就可以达到很好的效果
-
迁移学习:比如将预训练模型用于医学影像分析或自动驾驶,MAE训练的模型表现更好,因为它学到的是通用的图像理解能力,而非特定任务的死记硬背。
-
扩展性强:模型越大(比如参数更多),效果提升越明显,MAE适合训练超大规模视觉模型。
对比:
-
传统方法:给它看1000张标注好的猫狗图片,机器人只能记住这些特征。
-
MAE方法:把图片撕掉一大半,让机器人根据剩下的碎片猜是什么动物。经过大量练习,它不仅能认出猫狗,还能理解“耳朵尖的是猫,耳朵圆的是狗”这种深层规律,甚至能辨认没见过的动物。
四、核心图
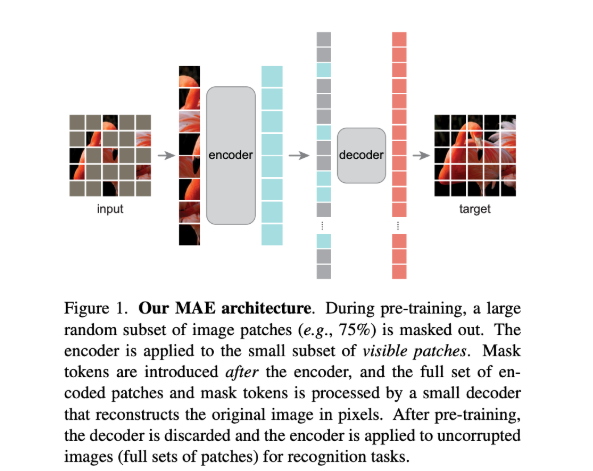
对输入图像切分patch,然后对部分patch进行mask操作,把未被mask掉的部分取出来组成输入序列--->输入序列放入一个encoder里面(vit)得到每一个patch的向量表示--->把encoder输出的序列拉长,因为需要把mask掉的patch放回原位置;没被mask掉的patch就是填上ViT后输出的特征,被mask掉的patch就只有位置信息----->将整合好的输入到decoder中,解码器会把里面的像素信息重构回来---->target训练处理即为原始的没有被掩码盖住的图片
-
主要计算量来自编码器,最重要的就是对图片的像素进行编码,对于编码器一张图片只要看到1/4的像素就行了,计算量降低
-
接下游任务时只需要用到encoder,并且图片也不需要做mask,直接切patch,送入encoder得到每个patch的向量表示
五、结果图
掩蔽图像--MAE重建图像---原图

有些图片mask后人都分辨不出来,MAE恢复的很好,作者可能是挑选了一些重构比较好的例子放在了论文中。
六、不同mask比例对比图

mask 95%时看起来也很玄学,哇塞,那么几小块像素就可恢复成那样
七、“Introduction” (He 等, 2021, p. 1) 引言
-
CV领域的任务仍然需要百万级甚至更多的有标签数据来训练
-
NLP领域的GPT、BERT等都是在无标签数据上通过自监督方式学习得到不错的效果
-
CV里已有的maksed autoencoder带掩码的自编码器,如denoising autoencoder(一张图片里加入很多噪音,通过去噪来学习对这张图片的理解)
-
最近有将BERT迁移至CV领域任务的工作,但是结果均不如在NLP领域的效果好
Bert用到cv邻域会有什么问题?What makes masked autoencoding different between vision and language?
-
在CNN中,卷积窗口使得不好将mask放进去:因为在transformer中,mask是一个特定的词[MASK],它始终是和其它词区分开的,并且一直保留到最后;而CNN中如果对图像块做mask,卷积窗口进行滑动时是无法区分这个mask个边界的(从而无法和其它未被mask的部分区分开),导致掩码部分的信息最后很难还原---VIT已经解决了
-
语言和图像的信息密度不同:在NLP中,一个词就是一个语义的实体,所以对于一句话假如去掉几个词再回复会比较难;在图像中,如果简单去掉一些像素,可以很容易通过邻域的像素进行插值还原:
所以,MAE的做法是非常高比例(75%)的随机mask掉一些块,极大降低图片的冗余性,提高任务难度,使得学习得到的模型有看到全局信息的能力,而不是只关注局部信息
-
NLP中,decoder的作用是还原出被mask掉的词,词是一个高语义的东西(所以只需一个MLP即可,预测出词的标签);而CV中,decoder的任务是还原出被mask掉的像素,它是比较低层次的表示,一个MLP是不够的
基于以上问题,MAE的做法
-
随机mask掉大量的块,然后去重构被mask掉的像素信息,使用一个非对称的encoder-decoder架构
-
encoder只计算未被mask掉的块,decoder计算encoder的输出以及被mask掉的信息
八、“Related Work” (He 等, 2021, p. 3)相关工作
DAE:带去噪的自编码
“Our MAE is a form of denoising autoencoding, but different from the classical DAE in numerous ways.” (He 等, 2021, p. 3)MAE其实也是一种denoising encoder的一种形式,把一些块mask可以看作是加了很多噪声,但是和传统的DAE不一样毕竟是基于VIT,基于整个transformer架构。
“Masked image encoding” (He 等, 2021, p. 3)带掩码的编码器在计算机视觉上的应用之前有igpt (gpt在图像上的应用)、beit(BERT在image上的应用)
“Self-supervised learning” 自监督学习,contrastive learning: 主要使用的是数据增强来实现自监督学习的
九、“Approach” (He 等, 2021, p. 3)MAE模型
MAE是一个简单的自编码器【即看到部分观察的数据,用它来重构完整的原始信号】,输入的是未被mask的部分图像,然后重构完整的图像区域;比较特别的是使用非对称的架构,编码器只能看到可见的那些块,不可见的就不看了节省开销
1.Masking 如何掩码的?
mask操作与ViT的方式相同,先对图像切patch,然后随机均匀的采样出来少量的一些patch,剩余的用掩码mask掉。其中关键点是mask率要高(75%),减少冗余
2.Encoder 编码器架构
MAE的encoder其实就是一个ViT,但是它只作用在未被mask掉的patch上。每个patch做线性投影再加上位置信息,patch embedding + position embedding -> Transformer
3.Decoder 解码器
Decoder会接收两部分的信息:
-
未被mask的patch,经encoder编码之后的输出
-
被mask的patch,没有进入编码器的
Decoder只在预训练阶段使用,在微调下游任务时并不需要,只需要编码器对一个图片编码即可,这样比较灵活了
MAE中decoder的计算量不到encoder的1/10
4.Reconstruction Target 如何重构原始像素?
MAE的目标是重构被mask掉的图像像素
-
decoder的最后一层是MLP,输出是每一个patch的向量表示;假如patch大小为(16, 16),那么向量的维度就是256,然后再将其reshape至(16, 16)作为最终还原的像素
-
损失函数为MSE,只在被mask掉的部分使用(预测和原始真正的像素相减再平方和)
-
训练的时候对mask掉的部分的预测输出做normalization(每个patch),数值更加稳定
5.Simple implementation 简单实现
-
首先把切好的patch构成一个序列,然后做(线性投影+位置信息)patch embedding + position embedding
-
随机采样出25%:把序列random shuffle,只保留前25%,送入encoder
-
解码时,需要把之前mask掉的的patch加进来,此时序列长度和原始相同,然后再unshuffle操作恢复原始序列的顺序,这样算误差 的时候和原始的patch能够一一对应
十、“. ImageNet Experiments” 实验部分
1.ImageNet-1k实验
-
MAE通过自监督的方式可以从ImageNet上学习到额外的信息
2.消融实验
-
微调时参数全部参与训练比只调最后一层效果更好
-
送入encoder的块不包含mask部分会更好
-
预测时,如果对patch内的像素值做归一化,效果会更好
-
MAE对数据增强不敏感,只做resize和随机裁剪就可以
-
mask操作随机采样的方式效果更好
十一、结论
-
MAE在小规模数 据集ImageNet-1k上,通过自监督学习的方法得到了可以媲美有监督方法的结果
-
在NLP中,一个token是一个语义单元,包含较多的语义信息;而MAE中的图像patch并不是一个语义的segment(一个patch并不一定包含一个物体或者patch是一个物体的一块);即使如此,MAE也可以学的比较好的隐藏的语义表达
-
broader impacts(如果该工作出圈可能带来的影响):只用了图像本身的信息去学习,如果数据集中有一些bias,可能会趋向于学习数据中不好的部分;MAE是生成式模型,可以生成不存在的内容,和GAN一样可能得到误导大家的结果;