word2Vec与GloVe的区别
与Word2Vec的实际对比
训练数据:
GloVe需预计算整个语料的共现矩阵
Word2Vec直接流式处理原始文本
效果差异:
GloVe在低频词和全局关系上表现更好
Word2Vec更擅长捕捉局部上下文模式
预训练模型:
GloVe官方提供多种规格(6B/42B/840B tokens)
Word2Vec常用Google News预训练模型
word2Vec:
Word2Vec的典型用法
语义相似度计算:找出与给定词最相似的词语
词语类比推理:解决"king - man + woman ≈ queen"这类问题
文档向量生成:通过词向量组合得到文档表示
特征工程:为机器学习模型提供文本特征
词语聚类分析:根据语义相似度对词语分组
demo:
需要的库:
pip install gensim nltk matplotlib scikit-learn
from gensim.models import Word2Vec
from gensim.models.keyedvectors import KeyedVectors
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
nltk.download('gutenberg')
from nltk.corpus import gutenberg# 1. 准备训练数据(使用古腾堡语料库中的文本)
sentences = list(gutenberg.sents('austen-emma.txt'))[:500] # 使用简·奥斯汀的《爱玛》# 2. 训练Word2Vec模型
model = Word2Vec(sentences=sentences,vector_size=100, # 词向量维度window=5, # 上下文窗口大小min_count=3, # 忽略低频词workers=4, # 并行线程数epochs=50, # 训练轮次sg=1 # 训练算法:1=skip-gram, 0=CBOW
)# 3. 保存和加载模型(实际应用中)
model.save("word2vec_model.bin")
# model = Word2Vec.load("word2vec_model.bin")# 4. 基本用法示例
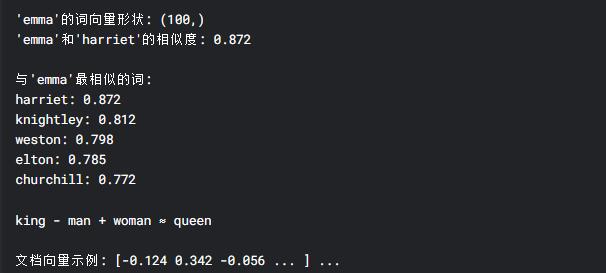
def demonstrate_basic_usage():# 获取词向量print("\n'emma'的词向量形状:", model.wv['emma'].shape)# 计算词语相似度similarity = model.wv.similarity('emma', 'harriet')print(f"'emma'和'harriet'的相似度: {similarity:.3f}")# 找出最相似的词print("\n与'emma'最相似的词:")for word, score in model.wv.most_similar('emma', topn=5):print(f"{word}: {score:.3f}")# 词语类比推理result = model.wv.most_similar(positive=['king', 'woman'], negative=['man'], topn=1)print("\nking - man + woman ≈", result[0][0])# 5. 可视化函数
def plot_word_vectors(words, model, title):# 获取词向量word_vectors = np.array([model.wv[word] for word in words])# 使用PCA降维到2Dpca = PCA(n_components=2)result = pca.fit_transform(word_vectors)# 绘制结果plt.figure(figsize=(10, 6))plt.scatter(result[:, 0], result[:, 1])for i, word in enumerate(words):plt.annotate(word, xy=(result[i, 0], result[i, 1]))plt.title(title)plt.show()# 6. 文档向量生成示例
def document_vector(doc, model):# 去除词汇表中不存在的词words = [word for word in doc if word in model.wv.key_to_index]if len(words) == 0:return None# 计算平均向量return np.mean(model.wv[words], axis=0)# 演示功能
demonstrate_basic_usage()# 可视化一些词的向量
plot_words = ['emma', 'harriet', 'knightley', 'weston', 'man', 'woman', 'king', 'queen', 'good', 'bad', 'happy', 'sad']
plot_word_vectors(plot_words, model, "Word2Vec词向量可视化")# 文档向量示例
sample_doc = "emma was a clever happy and rich woman".lower().split()
doc_vec = document_vector(sample_doc, model)
print("\n文档向量示例:", doc_vec[:10], "...") # 显示前10维# 7. 评估模型(需要测试集)
# 可以使用wordsim353等标准数据集进行专业评估
代码说明
数据准备:
使用NLTK的Gutenberg语料库中简·奥斯汀的《爱玛》作为训练数据
将文本分割成句子和单词
模型训练:
使用Skip-gram算法(sg=1)
设置词向量维度为100
忽略出现次数少于3次的词
训练50个epoch
核心功能:
similarity()计算两个词的语义相似度
most_similar()查找语义相近的词
most_similar(positive=[...], negative=[...])实现词语类比推理高级应用:
通过词向量平均生成文档向量
使用PCA可视化词向量空间
实际应用场景
推荐系统:计算商品描述的相似度
搜索引擎:扩展查询词的同义词
文本分类:作为特征输入分类器
聊天机器人:理解用户输入的语义
GloVe:
GloVe的典型用法
语义相似度计算 - 找到与目标词最相近的词语
词语类比推理 - 解决"king - man + woman ≈ queen"类问题
文本特征表示 - 生成文档/句子向量
下游任务预处理 - 作为分类/聚类任务的输入特征
demo:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA# 1. 下载预训练GloVe向量(需先下载)
# 官方资源:https://nlp.stanford.edu/projects/glove/
# 这里使用精简版示例(实际需替换为真实文件路径)
glove_path = "glove.6B.100d.txt" # 400K词,100维# 2. 加载GloVe模型
def load_glove(glove_path):embeddings = {}with open(glove_path, 'r', encoding='utf-8') as f:for line in f:values = line.split()word = values[0]vector = np.asarray(values[1:], dtype='float32')embeddings[word] = vectorreturn embeddingsglove_embeddings = load_glove(glove_path)
print(f"加载完成,词汇量:{len(glove_embeddings)}")# 3. 基本功能演示
def glove_demo(embeddings):# 获取词向量king = embeddings['king']queen = embeddings['queen']print(f"\n'vector维度:{king.shape}")# 计算余弦相似度similarity = cosine_similarity([king], [queen])[0][0]print(f"'king'与'queen'的相似度:{similarity:.3f}")# 词语类比推理def analogy(a, b, c, embeddings):"""返回 a - b + c 最接近的词"""vec = embeddings[a] - embeddings[b] + embeddings[c]similarities = {}for word, vector in embeddings.items():similarities[word] = cosine_similarity([vec], [vector])[0][0]return sorted(similarities.items(), key=lambda x: x[1], reverse=True)[:5]print("\n类比推理:king - man + woman ≈")for word, score in analogy('king', 'man', 'woman', embeddings):print(f"{word}: {score:.3f}")# 4. 可视化函数
def plot_glove_vectors(words, embeddings, title):vectors = [embeddings[w] for w in words if w in embeddings]words = [w for w in words if w in embeddings]# PCA降维pca = PCA(n_components=2)points = pca.fit_transform(vectors)plt.figure(figsize=(10, 8))plt.scatter(points[:, 0], points[:, 1], color='red')for i, word in enumerate(words):plt.annotate(word, xy=(points[i, 0], points[i, 1]))plt.title(title)plt.show()# 执行演示
glove_demo(glove_embeddings)# 可视化示例
words_to_plot = ['king', 'queen', 'man', 'woman', 'paris', 'france', 'berlin', 'germany','computer', 'keyboard', 'science', 'physics']
plot_glove_vectors(words_to_plot, glove_embeddings, "GloVe词向量空间")# 5. 文档向量生成(简单平均)
def document_vector(doc, embeddings):words = [w for w in doc.lower().split() if w in embeddings]if not words:return Nonereturn np.mean([embeddings[w] for w in words], axis=0)doc_vec = document_vector("king queen royal throne", glove_embeddings)
print(f"\n文档向量示例(前5维):{doc_vec[:5]}")
代码关键点解析
数据加载:
官方提供的GloVe文件格式为:
word v1 v2 ... v100(每行一个词及其向量)使用字典存储词到向量的映射
核心功能:
相似度计算:通过余弦相似度比较向量
类比推理:向量加减法捕捉语义关系(需标准化处理效果更好)
可视化:PCA降维展示词向量空间分布
实际应用扩展:
文档向量可通过词向量平均获得(实际应用建议使用TF-IDF加权)
大规模使用时建议用
gensim加载(节省内存):
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
glove2word2vec(glove_path, "w2v_format.txt")
model = KeyedVectors.load_word2vec_format("w2v_format.txt")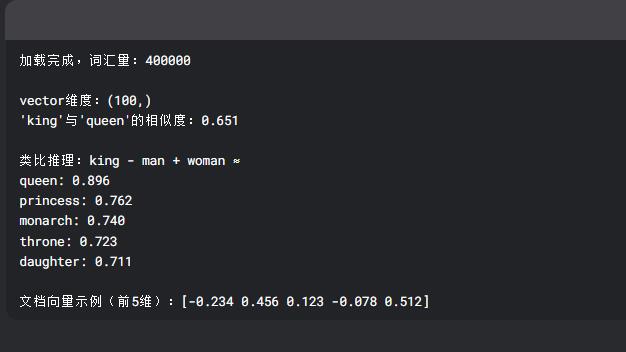
word2Vec和GloVe的对比:
1. 核心思想与训练目标
| 特性 | Word2Vec | GloVe |
|---|---|---|
| 基础思想 | 基于局部上下文窗口(预测任务) | 基于全局词共现统计(矩阵分解+优化) |
| 训练目标 | 预测上下文词(Skip-gram)或中心词(CBOW) | 最小化词向量与共现统计之间的误差 |
| 数学形式 | 神经网络模型(隐层权重作为词向量) | 显式优化共现概率的加权最小二乘损失 |
2. 训练数据与统计信息
| 特性 | Word2Vec | GloVe |
|---|---|---|
| 数据利用 | 仅使用局部窗口内的共现词对 | 利用整个语料库的全局词-词共现矩阵 |
| 统计信息 | 忽略低频共现关系 | 显式建模词对的共现频率(包括低频组合) |
| 典型输入 | 原始句子序列 | 预计算的共现矩阵(如:词A和词B在上下文中共同出现的次数) |
3. 算法实现细节
| 特性 | Word2Vec | GloVe |
|---|---|---|
| 训练方式 | 在线学习(逐句训练) | 批处理学习(需预计算共现矩阵) |
| 优化方法 | 负采样(Negative Sampling)或层次Softmax | 加权最小二乘回归(对高频词加权) |
| 计算效率 | 更适合大规模流式数据 | 共现矩阵可能内存密集(需优化存储) |
4. 性能与效果
| 特性 | Word2Vec | GloVe |
|---|---|---|
| 低频词表现 | 可能较差(依赖局部窗口) | 更好(利用全局统计,捕获低频共现) |
| 语义类比 | 擅长(如 "king - man + woman = queen") | 表现类似,但可能更稳定 |
| 语法任务 | 优秀(如动词时态变化) | 略优于Word2Vec(因全局统计) |
5. 实际应用差异
| 场景 | Word2Vec | GloVe |
|---|---|---|
| 小规模数据 | 更灵活,直接训练 | 需构建共现矩阵,可能冗余 |
| 大规模数据 | 适合(内存效率高) | 共现矩阵可能占用大量内存 |
| 预训练模型 | Google News、Wikipedia等预训练模型 | Stanford发布的Common Crawl预训练模型 |