【漫话机器学习系列】229.特征缩放对梯度下降的影响(The Effect Of Feature Scaling Gradient Descent)
特征缩放对梯度下降的影响:为什么特征标准化如此重要?
在机器学习和深度学习中,梯度下降是最常用的优化算法之一。然而,很多人在训练模型时会遇到收敛速度慢、训练不稳定的问题,其中一个重要原因就是特征未进行适当的缩放。
本文通过一张直观的图,详细讲解特征缩放对梯度下降路径的影响,并配合示例代码,帮助你彻底理解这个概念。
1. 什么是特征缩放?
特征缩放(Feature Scaling)是将数据的特征值统一到一定范围(如 [-1,1] 或 [0,1])的过程。
常见的方法有:
-
归一化(Normalization):把数据缩放到固定范围(通常是[0,1])。
-
标准化(Standardization):使特征数据的均值为0,标准差为1。
常见的公式:
归一化:
标准化:
其中,μ 是均值,σ 是标准差。
2. 特征缩放对梯度下降的影响
看一下下面这张图(来源于 Chris Albon 的手绘):
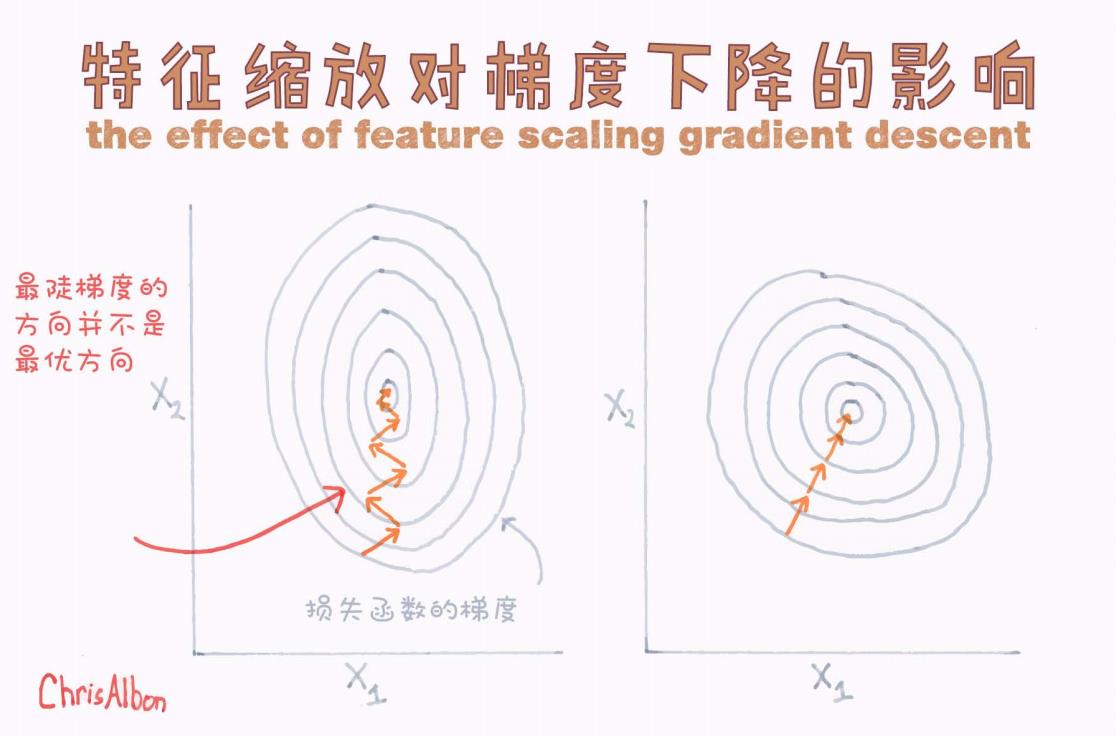
图的左半部分展示了未进行特征缩放的情况;右半部分展示了进行了特征缩放的情况。
2.1 未进行特征缩放
-
损失函数的等高线呈现出拉长的椭圆形(特征尺度不一致,X1、X2维度变化范围不同)。
-
梯度下降沿着最陡方向前进,但由于方向不正确,导致路径“之”字形前进。
-
整个收敛过程非常缓慢,且容易震荡。
图中左边橙色箭头清晰显示了这种曲折前进的轨迹。
总结:
特征缩放不一致 → 梯度下降“拐弯抹角” → 训练慢且不稳定。
2.2 进行了特征缩放
-
等高线接近圆形,各特征对损失的贡献在同一量纲。
-
梯度下降可以直接朝着最优解方向快速前进。
-
收敛速度大幅提升。
图中右边箭头直线指向中心,非常干脆利落。
总结:
特征缩放一致 → 梯度下降快速直奔最优解 → 训练稳定且高效。
3. 为什么会这样?——从数学角度理解
梯度下降更新公式:
其中:
-
θ:模型参数
-
η:学习率
-
∇J(θ):损失函数关于参数的梯度
如果各个特征的尺度差异很大,某些方向(例如 )的梯度变化非常快,而另一些方向(例如
)的变化非常慢,导致梯度下降需要在各个方向上不断地调整,非常低效。
当特征缩放后,各方向上的变化速度均衡,梯度下降可以更稳定地朝着全局最优点前进。
4. 示例代码:如何在 PyTorch 中应用特征缩放
下面用一个小示例说明如何在实际训练中进行特征标准化。
import torch
from sklearn.preprocessing import StandardScaler# 假设有一批特征数据
X = torch.tensor([[100.0, 1.0],[200.0, 2.0],[300.0, 3.0],[400.0, 4.0]
])# 使用sklearn进行标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X.numpy())print("原始数据:\n", X)
print("标准化后数据:\n", X_scaled)# 将标准化后的数据转回Tensor用于后续训练
X_scaled = torch.tensor(X_scaled, dtype=torch.float32)
输出:
原始数据:tensor([[100., 1.],[200., 2.],[300., 3.],[400., 4.]])
标准化后数据:[[-1.3416408 -1.3416408][ -0.4472136 -0.4472136][ 0.4472136 0.4472136][ 1.3416408 1.3416408]]
这样处理后的特征就不会因为数量级不同而影响梯度下降的速度和方向了!
5. 总结
-
特征缩放是训练深度学习模型时非常重要的一步。
-
特征未缩放时,梯度下降路径会变得弯曲,导致训练缓慢、不稳定。
-
特征缩放后,可以显著加速收敛速度,提高训练稳定性。
-
在实际建模中,始终推荐对输入特征进行标准化处理,尤其是在使用梯度下降优化器时。
建议:
今后在任何机器学习、深度学习项目中,在建模前加上特征缩放(尤其是标准化步骤)!这是最简单但效果最显著的性能提升方法之一!
如果你觉得这篇文章对你有帮助,别忘了点赞、收藏、关注哦!
未来我也会分享更多直观好懂的机器学习、深度学习知识!
如果你有其他想了解的内容,欢迎在评论区告诉我!