Spark知识总结
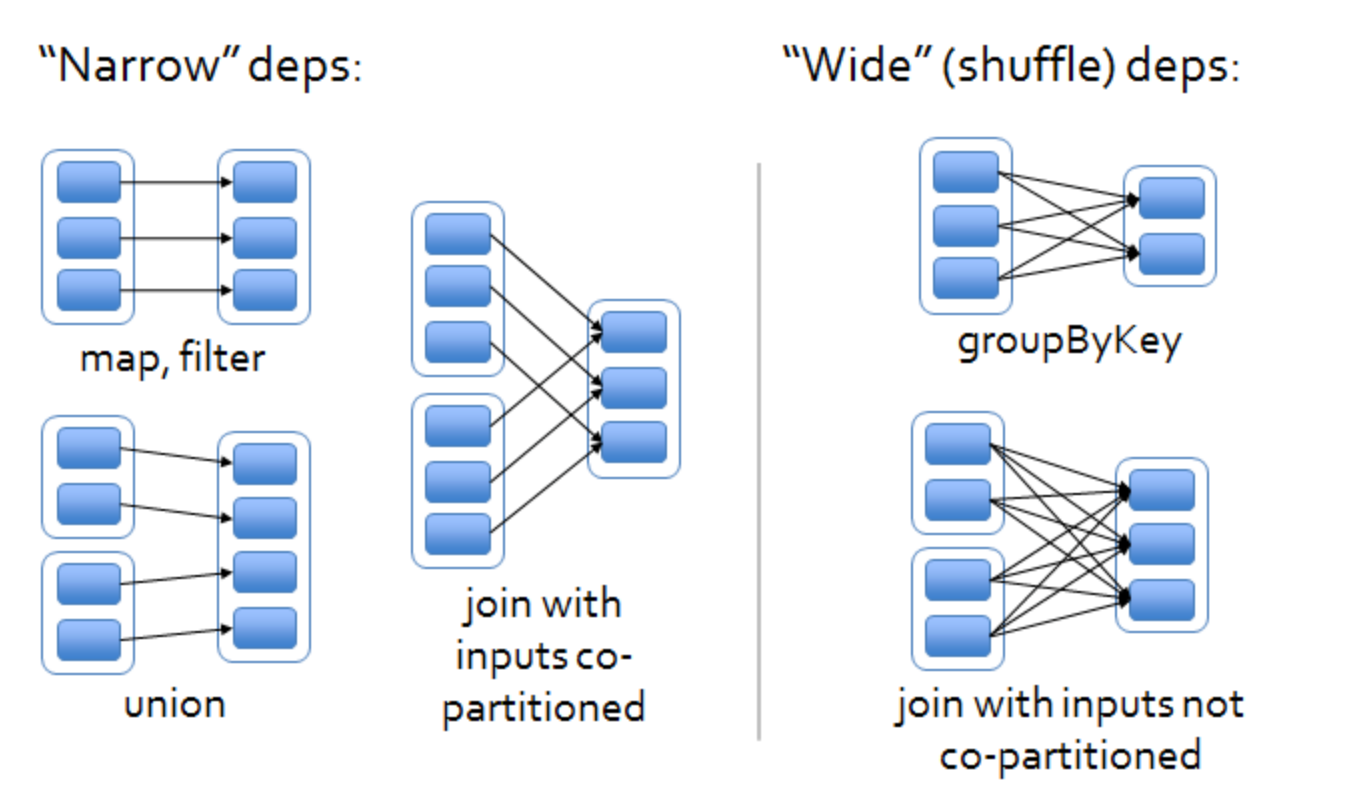
宽窄依赖:父RDD的分区只对应下面子RDD的一个分区,为窄依赖。其余为宽依赖
| 维度 | 窄依赖 | 宽依赖 |
|---|---|---|
| 数据传输 | 无shuffle,本地处理14 | 需shuffle,跨节点传输14 |
| 并行度 | 高(允许流水线并行)57 | 低(需等待父任务完成)28 |
| 容错恢复成本 | 仅需重算单个父分区57 | 需重算多个父分区8 |
| 典型操作 | map、filter、union4 | groupByKey、join4 |
其实就是父RDD的一个分区会被传到几个子RDD分区的区别。如果被传到一个子RDD分区,就可以不需要移动数据(移动计算);如果被传到多个子RDD分区,就需要进行数据的传输。
如何计算job, stage, task可以参考这篇博客:[Spark] 手撕Job、Stage、Task划分机制_spark根据什么分task-CSDN博客