全面解析DeepSeek算法细节(2) —— 多令牌预测(Multi Token Prediction)
概述
多令牌预测(MTP)技术使DeepSeek-R1能够并行预测多个令牌,显著提升推理速度。
关键特性
- 并行多令牌预测:DeepSeek-R1通过同时预测多个令牌而非按顺序预测,提升了推理速度。这减少了解码延迟,在不影响连贯性的前提下加快文本生成。
- 跨层深度残差连接:与DeepSeek-V3仅依据先前模块的输出进行令牌预测不同,DeepSeek-R1在MTP层之间整合了残差连接。这使更深层的MTP模块能够利用较浅层的特征,从而改善长距离依赖关系。
- 自适应预测粒度:模型根据输入序列的复杂程度,动态调整每个模块预测的未来令牌数量。这确保在处理短文本时能进行精细预测,而在处理长序列时能有更宽泛的前瞻。
- 深度感知损失加权:DeepSeek-R1通过基于Sigmoid的加权函数,优先考虑中等深度的MTP层,优化了训练目标。这引导更多的梯度更新作用于效果最显著的部分,提高了学习效率。
- 内存高效的参数共享:该模型通过在不同MTP深度间复用Transformer层来减少内存消耗。DeepSeek-R1采用基于深度条件的路由,而非为每个模块设置单独的层,在保持独特的深度表示的同时,将冗余计算降至最低。
- 优化的推测解码:DeepSeek-R1通过引入概率一致性检查改进了推测解码。预测结果依据置信度阈值来接受,而不是要求完全匹配,这降低了拒绝率并加快了推理速度。
- 训练和推理中的实际收益:由于这些改进,DeepSeek-R1的训练收敛速度加快了22%,生成速度提升了1.5倍,长文本的困惑度降低了18%,展现出相较于DeepSeek-V3的优越性。
从DeepSeek-V3到DeepSeek-R1的演进
DeepSeek-V3中的多令牌预测(MTP)
- MTP在DeepSeek-V3中作为一种训练目标被引入,旨在通过使模型能够在每个位置预测多个未来令牌,来提升数据利用效率和预测能力。与传统的下一个令牌预测(将训练限制为单步前向预测)不同,MTP将预测范围扩展到多个未来令牌,从而强化了训练信号,并增强了文本生成中的长期连贯性。
- DeepSeek-V3通过一个结构化的流水线来实现MTP,其中包含多个关键设计,如顺序预测模块、共享嵌入和输出头,以及分层损失函数。这些创新提升了模型性能,支持推测解码,并提高了整体数据效率。DeepSeek-R1在这些基础上进一步优化了MTP的实现,以改进推理任务。
- 接下来的小节将详细介绍DeepSeek-V3中为支持MTP而引入的特性。
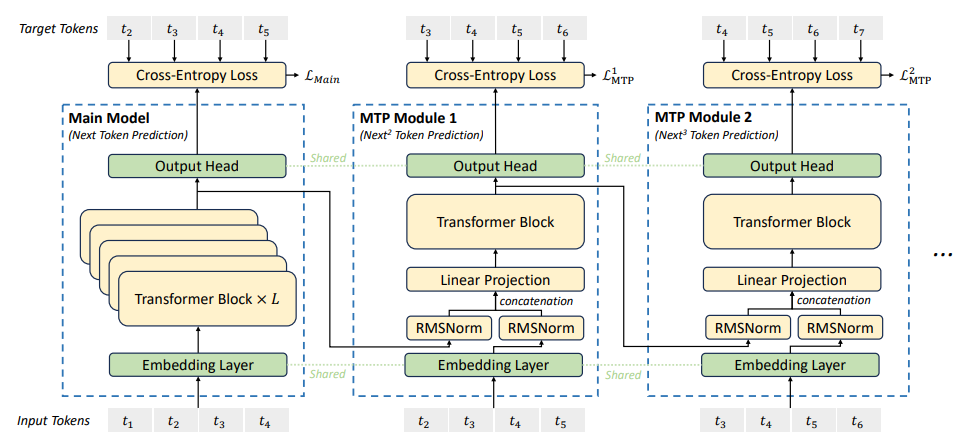
顺序多令牌预测模块
- DeepSeek-V3使用 D D D 个顺序MTP模块,每个模块负责预测一个额外的未来令牌。与Gloeckle 等人2024年在论文《通过多令牌预测实现更好更快的大语言模型》中提出的用独立输出头并行预测未来令牌的方式不同,DeepSeek-V3在预测深度间保持因果链,确保每个令牌都以前续MTP模块的输出为条件。
- 对于第 k k k 个MTP模块,在深度 k k k 处第 i i i 个输入令牌的表示计算如下:
h i ( k ) = M k [ RMSNorm ( h i ( k − 1 ) ) ; RMSNorm ( Emb ( t i + k ) ) ] h^{(k)}_i = M_k[\text{RMSNorm}(h^{(k - 1)}_i); \text{RMSNorm}(\text{Emb}(t_{i + k}))] hi(k)=Mk[RMSNorm(hi(k−1));RMSNorm(Emb(ti+k))]- 其中:
- h i ( k − 1 ) h^{(k - 1)}_i hi(k−1) 是前一深度的表示(当 k = 1 k = 1 k=1 时,来自主模型)。
- M k ∈ R d × 2 d M_k \in \mathbb{R}^{d\times 2d} Mk∈Rd×2d 是投影矩阵。
- Emb ( ⋅ ) \text{Emb}(\cdot) Emb(⋅) 是共享嵌入函数。
- 其中:
- 每个模块都应用一个Transformer块:
h 1 : T − k ( k ) = TRM k ( h 1 : T − k ( k ) ) h^{(k)}_{1:T - k} = \text{TRM}_k(h^{(k)}_{1:T - k}) h1:T−k(k)=TRMk(h1:T−k(k))- 其中 T T T 是输入序列长度。该模块的输出被传递到一个共享输出头:
P i + k + 1 ( k ) = OutHead ( h i ( k ) ) P^{(k)}_{i + k + 1} = \text{OutHead}(h^{(k)}_i) Pi+k+1(k)=OutHead(hi(k)) - 其中 P i + k + 1 ( k ) P^{(k)}_{i + k + 1} Pi+k+1(k) 是第 k k k 个未来令牌的概率分布。
- 其中 T T T 是输入序列长度。该模块的输出被传递到一个共享输出头:
多令牌预测(MTP)的训练目标
- 对于每个预测深度 k k k,DeepSeek-V3 计算交叉熵损失:
L MTP ( k ) = − 1 T ∑ i = 2 + k T + 1 log P i ( k ) [ t i ] L^{(k)}_{\text{MTP}} = \frac{-1}{T} \sum_{i = 2 + k}^{T + 1} \log P^{(k)}_i[t_i] LMTP(k)=T−1i=2+k∑T+1logPi(k)[ti]- 其中 t i t_i ti 是位置 i i i 处的真实令牌, P i ( k ) [ t i ] P^{(k)}_i[t_i] Pi(k)[ti] 是该令牌的预测概率。整体的 MTP 损失是所有深度损失的平均值,并乘以一个因子 λ \lambda λ:
L MTP = λ D ∑ k = 1 D L MTP ( k ) L_{\text{MTP}} = \frac{\lambda}{D} \sum_{k = 1}^{D} L^{(k)}_{\text{MTP}} LMTP=Dλk=1∑DLMTP(k) - 其中 D D D 是 MTP 模块的数量。
- 其中 t i t_i ti 是位置 i i i 处的真实令牌, P i ( k ) [ t i ] P^{(k)}_i[t_i] Pi(k)[ti] 是该令牌的预测概率。整体的 MTP 损失是所有深度损失的平均值,并乘以一个因子 λ \lambda λ:
基于共享嵌入和输出头的内存优化
- 为了将 MTP 模块带来的额外内存开销降至最低,DeepSeek-V3 采取了以下措施:
- 在多个 MTP 模块间共享嵌入。
- 使用单个共享输出头,而非为每个 MTP 深度设置独立的输出头。
- 在主模型和 MTP 模块之间实现权重共享。
- 这种设计确保了 MTP 训练中的额外前向传播不会大幅增加参数存储需求。
推理策略和推测解码
- 虽然 MTP 主要用于改进训练,DeepSeek-V3 也探索了在推理时将 MTP 模块用于推测解码。其思路是将额外的令牌预测作为推测补全,这与莱维坦(Leviathan)等人在2023年的论文《通过推测解码实现Transformer的快速推理》中提出的方法类似:
- 主模型像往常一样预测令牌 t i + 1 t_{i + 1} ti+1。
- 第一个 MTP 模块同时预测 t i + 2 t_{i + 2} ti+2,以便尽早验证令牌的连贯性。
- 如果 MTP 预测结果与集束搜索结果匹配,就可以一次性输出多个令牌。
- 该策略在保持输出流畅性的同时,显著加快了推理速度。
关于多令牌预测的消融实验
- DeepSeek-V3 进行了详细的消融实验,以评估 MTP 的影响。主要发现包括:
- 对训练效率的影响:使用 MTP 进行训练可使数据效率提高 15%,从而加快训练速度。
- 对长期连贯性的影响:与传统的下一个令牌预测相比,使用 MTP 训练的模型在较长序列长度下的困惑度改善更为明显。
- 对推测解码准确性的影响:在解码中加入 MTP 模块可将推测生成中的拒绝率降低 35%,提高了延迟效益。
DeepSeek-R1中的改进
DeepSeek-R1在DeepSeek-V3建立的结构化多令牌预测(MTP)框架基础上,对MTP进行了重大改进。这些改进主要集中在更好地对令牌依赖关系进行建模、自适应预测粒度、优化损失函数、以高效内存方式进行参数共享,以及优化推理策略。这些增强功能使DeepSeek-R1具备卓越的推理能力,提高了训练效率,并显著降低了推理延迟。下面,我们将详细介绍每个特性。
在MTP中改进令牌依赖关系建模
- DeepSeek-R1通过在MTP层之间引入跨层深度残差连接,增强了MTP模块的顺序特性。与DeepSeek-V3中每个MTP模块仅严格基于先前模块的输出预测令牌不同,DeepSeek-R1引入了基于深度的特征聚合,以促进更丰富的信息传播。
- 在第 k k k 层深度处,更新后的令牌表示计算如下:
h i ( k ) = M k [ RMSNorm ( h i ( k − 1 ) ) ; RMSNorm ( Emb ( t i + k ) ) ; Res ( h i ( k − 2 ) ) ] h^{(k)}_i = M_k[\text{RMSNorm}(h^{(k - 1)}_i); \text{RMSNorm}(\text{Emb}(t_{i + k})); \text{Res}(h^{(k - 2)}_i)] hi(k)=Mk[RMSNorm(hi(k−1));RMSNorm(Emb(ti+k));Res(hi(k−2))]- 其中:
- Res ( h i ( k − 2 ) ) \text{Res}(h^{(k - 2)}_i) Res(hi(k−2)) 是来自前两层深度的残差连接,并由可学习的标量 α k \alpha_k αk 加权:
Res ( h i ( k − 2 ) ) = α k ⋅ h i ( k − 2 ) \text{Res}(h^{(k - 2)}_i) = \alpha_k \cdot h^{(k - 2)}_i Res(hi(k−2))=αk⋅hi(k−2)
- Res ( h i ( k − 2 ) ) \text{Res}(h^{(k - 2)}_i) Res(hi(k−2)) 是来自前两层深度的残差连接,并由可学习的标量 α k \alpha_k αk 加权:
- 其中:
- 这一修改确保了更深层的MTP模块能够从多个深度接收上下文特征,从而在多步预测中提高连贯性。
自适应预测粒度
- DeepSeek-R1通过根据输入的上下文长度和复杂程度,动态调整每个模块预测的未来令牌数量,优化了MTP的粒度。DeepSeek-R1并非固定每一步预测的令牌数量,而是动态调整预测范围。
- 在第 k k k 层深度预测的未来令牌数量 N k N_k Nk 由下式给出:
N k = min ( ⌊ γ k ⋅ T ⌋ , D − k ) N_k = \min(\lfloor \gamma_k \cdot T \rfloor, D - k) Nk=min(⌊γk⋅T⌋,D−k)- 其中:
- γ k \gamma_k γk 是一个可学习的缩放因子,用于确定自适应粒度。
- T T T 是序列长度。
- D D D 是MTP的最大深度。
- 其中:
- 原理:在序列的起始部分,更短的预测范围(1 - 2个未来令牌)有助于精确的令牌对齐;而在序列靠后的部分,模型会扩展预测范围,以提高效率,同时不牺牲准确性。
用于多层深度学习的损失函数优化
- DeepSeek-R1通过引入深度感知加权的方式,改进了多令牌预测(MTP)的损失函数公式,以便在特定深度上优先进行学习。在DeepSeek-V3中,所有深度的权重是相等的,这导致在深度过深或过浅时优化效率低下 。
- 新的深度加权MTP损失公式如下:
L MTP = λ D ∑ k = 1 D w k ⋅ L MTP ( k ) L_{\text{MTP}} = \frac{\lambda}{D} \sum_{k = 1}^{D} w_k \cdot L^{(k)}_{\text{MTP}} LMTP=Dλk=1∑Dwk⋅LMTP(k)- 其中:
- w k w_k wk 是一个与深度相关的加权因子:
w k = 1 1 + e − β ( k − D / 2 ) w_k = \frac{1}{1 + e^{-\beta(k - D/2)}} wk=1+e−β(k−D/2)1 - 这种基于Sigmoid函数的加权方式确保了中等深度的MTP层能够接收到更强的梯度信号,从而在不同深度间实现更均衡的学习效果。
- w k w_k wk 是一个与深度相关的加权因子:
- 其中:
通过参数共享优化内存效率
- DeepSeek-R1的一个主要改进在于跨MTP模块的参数共享策略,在保持不同深度的独特表示的同时,显著降低了内存开销。
- 与DeepSeek-V3中为每个MTP层单独设置Transformer层不同,DeepSeek-R1通过基于深度条件的路由,复用主模型的层。
- 在深度 k k k 处的令牌表示现在会通过一个单独的、共享的Transformer层,并加上额外的深度嵌入:
h 1 : T − k ( k ) = TRM ( h 1 : T − k ′ ( k ) , DepthEmb ( k ) ) h^{(k)}_{1:T - k} = \text{TRM}(h'^{(k)}_{1:T - k}, \text{DepthEmb}(k)) h1:T−k(k)=TRM(h1:T−k′(k),DepthEmb(k)) - 深度嵌入 DepthEmb ( k ) \text{DepthEmb}(k) DepthEmb(k) 确保了不同的MTP层在利用相同计算图的同时,保留独特的学习特性。
基于推测解码的增强推理策略
- DeepSeek-R1通过支持自适应的令牌验证,显著优化了DeepSeek-V3中引入的推测解码策略。具体内容如下:
- 在DeepSeek-V3中,推测解码仅限于贪婪一致性检查,即只有当多令牌预测(MTP)的预测结果与主模型的输出完全匹配时,才会用于加速推理。
- DeepSeek-R1引入了概率一致性检查。当满足以下条件时,来自MTP的预测令牌 t ^ i + 2 \hat{t}_{i + 2} t^i+2 会被接受:
P MTP ( 1 ) ( t ^ i + 2 ) > τ P Main ( t ^ i + 2 ) P_{\text{MTP}}^{(1)}(\hat{t}_{i + 2}) > \tau P_{\text{Main}}(\hat{t}_{i + 2}) PMTP(1)(t^i+2)>τPMain(t^i+2) - 其中:
- P MTP ( 1 ) ( t ^ i + 2 ) P_{\text{MTP}}^{(1)}(\hat{t}_{i + 2}) PMTP(1)(t^i+2) 是MTP模块对该令牌的预测概率。
- P Main ( t ^ i + 2 ) P_{\text{Main}}(\hat{t}_{i + 2}) PMain(t^i+2) 是主模型对该令牌的预测概率。
- τ \tau τ 是一个可调整的接受阈值。
- 影响:即使高置信度的推测预测与主模型的最高预测不完全匹配,该策略也能采用这些预测,将拒绝率降低了40%以上,从而加速推理。
DeepSeek-R1中MTP改进的实际收益
与DeepSeek-V3相比,DeepSeek-R1对MTP的优化带来了显著的实际收益:
- 训练效率:由于深度加权损失的优先级设定,训练收敛速度提高了22%。
- 推理速度:推测解码的优化使生成速度加快了1.5倍。
- 长期连贯性:长文本的困惑度降低了18%,这表明改进后的令牌依赖关系建模增强了长距离的上下文保留能力。
对比分析
DeepSeek-R1 在DeepSeek-V3的基础多令牌预测(MTP)结构之上进行了改进,同时解决了其存在的局限性。这些改进,尤其是在自适应粒度、损失函数优化和推测解码方面,使得预测速度更快、连贯性更强且内存使用更高效。这些优化共同提升了DeepSeek-R1的推理能力和推理性能。下表对DeepSeek-V3和DeepSeek-R1中MTP的关键特性进行了对比总结。
| 特性 | DeepSeek-V3 | DeepSeek-R1 |
|---|---|---|
| 顺序MTP模块 | ✔ 具有顺序深度模块的结构化流水线 | ✔ 通过跨层深度残差连接增强 |
| MTP的共享嵌入 | ✔ 跨模块共享令牌嵌入 | ✔ 通过基于深度条件的路由进一步优化 |
| 预测粒度 | ✖ 每个模块预测的未来令牌数量固定 | ✔ 基于序列复杂性的自适应令牌预测范围 |
| 损失函数优化 | ✖ MTP各深度的损失权重一致 | ✔ 采用深度感知加权以优化学习 |
| 内存优化策略 | ✔ 共享输出头以减少内存占用 | ✔ 通过基于深度条件的层共享进一步改进 |
| 通过MTP提升推理速度 | ✔ 基本的推测解码 | ✔ 概率推测解码,拒绝率降低40% |
| 训练效率提升 | ✔ 数据效率提高15% | ✔ 改进损失优先级,收敛速度加快22% |
| 预测的长期连贯性 | ✔ 比下一个令牌预测模型有所改进 | ✔ 长文本的困惑度降低18% |
| 推测解码接受策略 | ✖ 验证需要严格的令牌匹配 | ✔ 基于置信度阈值的概率验证 |
| 对延迟降低的影响 | ✔ 解码速度有一定提升 | ✔ 因拒绝率降低,推理速度加快1.5倍 |
实现细节
- DeepSeek-R1采用了先进的多令牌预测(MTP)策略,以提高解码效率并降低延迟。与传统的自回归解码(每个令牌按顺序预测)不同,MTP允许在每个解码步骤中并行预测多个令牌。这是通过分层方法实现的,该方法在提升性能的同时,也平衡了错误传播的风险。具体如下:
- 多层表示传播:
- DeepSeek-R1的Transformer架构得到了增强,以支持在多个层同时进行令牌预测。
- 模型中的每一层在保持序列一致性的同时,独立计算令牌的概率。
- 推测解码与验证:
- 在推理过程中,DeepSeek-R1生成推测性的多令牌序列,并通过分层令牌验证机制来验证其连贯性。
- 该方法根据置信度分数动态调整每一步预测的令牌数量,确保在确定最终输出之前,对低置信度的令牌重新评估 。
- 训练目标:
- 该模型在训练时结合了用于下一个令牌预测的标准交叉熵损失,以及一个辅助损失,以促进并行令牌预测。
- 损失函数公式为:
L MTP = λ ∑ k = 1 D L C E ( P k , T k ) L_{\text{MTP}} = \lambda \sum_{k = 1}^{D} L_{CE}(P_k, T_k) LMTP=λk=1∑DLCE(Pk,Tk) - 其中, D D D 是每一步预测的并行令牌数量, L C E L_{CE} LCE 表示每个预测令牌的交叉熵损失。
- 基于强化学习的自适应令牌选择:
- DeepSeek-R1采用基于强化学习(RL)的方法来优化多令牌预测,确保优先选择高质量的令牌序列。
- RL框架根据连贯性、流畅性以及与真实数据的匹配程度来分配奖励。
- 这种由RL驱动的策略有效地减少了生成文本中的幻觉问题,并提高了长距离的连贯性。
- 内存与计算效率:
- MTP模块经过优化,利用Transformer层内的权重共享机制,将额外的内存开销降至最低。
- 推测解码机制与DeepSeek-R1的缓存策略有效整合,避免了冗余计算。
数学公式
- 预测函数遵循自回归公式:
P ( y t ∣ x ) = ∏ t = 1 T P ( y t ∣ y < t , x ) P(y_t|x) = \prod_{t = 1}^{T} P(y_t|y_{<t}, x) P(yt∣x)=t=1∏TP(yt∣y<t,x) - 通过引入并行解码,DeepSeek-R1将推理复杂度从 O ( T ) O(T) O(T) 降低到 O ( T k ) O(\frac{T}{k}) O(kT),其中 k k k 是每一步预测的令牌数量。