面试题总结
Mysql
聚簇索引和二级索引(非聚簇索引)


mysql创建索引的原则

mysql索引失效的场景
● 组合索引必须满足最左匹配原则
● 字符串不加单引号 (会进行类型转换导致失效)
● 模块查询以%开头会导致失效 在结尾可以走索引
● 在索引列上进行了范围查询 > < 右边的列是不走索引的 但是前面的列是走索引的
mysql事务特性

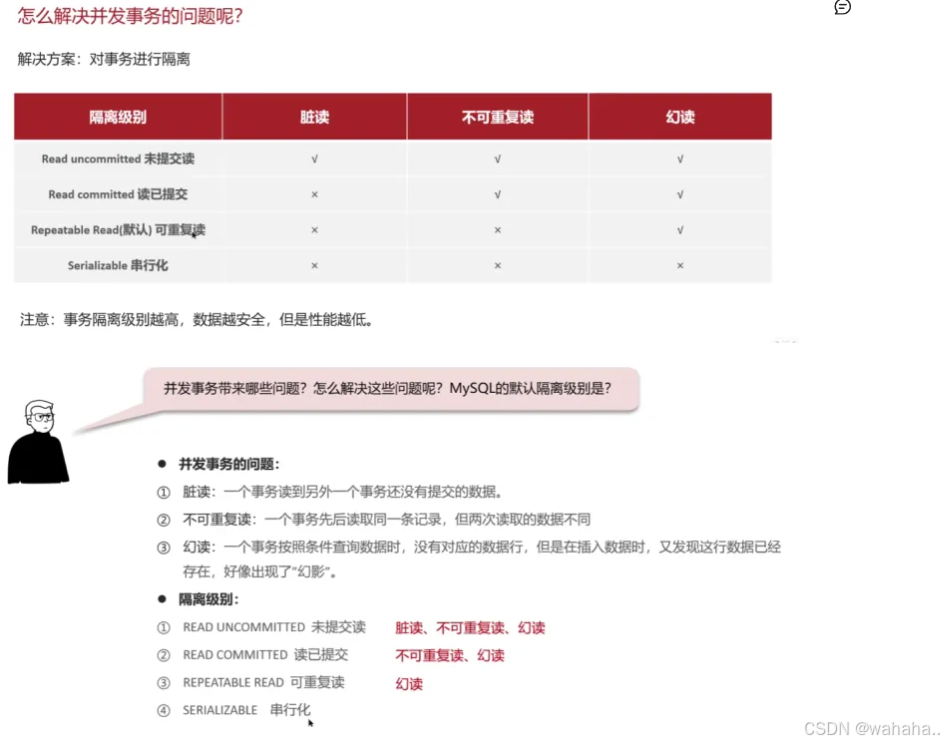
mysql隔离级别(并发事务问题 脏读 不可重复读 幻读) 默认可重复读
解决并发事务问题的办法就是事务隔离
读未提交
读已提交
可重复读
串行化
● 脏读: 一个事务读取到了另外一个还没有提交的事务
● 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读
● 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,会幻读 比如第一次查询 没有数据 同时另一个事务提交了数据 再次查询有数据 就幻读
Spring框架
spring用到了那些设计模式
工厂模式: beanFactory就用到了简单工厂模式。
单例模式: Bean默认为单例模式。
代理模式: AOP用到了JDK的动态代理模式。
模板模式: 减少代码冗余,Jdbc模板等。
观察者模式: 定义对象间的一对多的关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新。spring监听器的实现就用了观察者模式。
https://blog.csdn.net/zhzjn/article/details/143327633
Spring事务失效的场景

spring事务的传播行为
REQUIRED(默认):默认事务传播行为,存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
REQUIRE_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
NESTED:如果当前存在事务,就嵌套当前事务中去执行,如果当前没有事务,那么就新建一个事务,类似 REQUIRE_NEW这个样一个传播行为。
SUPPORTS:表示支持当前当前的事务,如果当前不存在事务,就以非事务的方式去执行。
NOT_SUPPORT: 总是非事务地执行,并挂起任何存在的事务。
MANDATORY:如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
NEVER:就是以非事务的方式来执行,如果存在事务则抛出一个异常。
Spring中Bean的声明周期
bean: 是由 Spring IoC 容器实例化、组装和管理的对象。
单例模式: spring中bean的生命周期分为:实例化Bean->Bean属性填充->初始化Bean->销毁Bean。

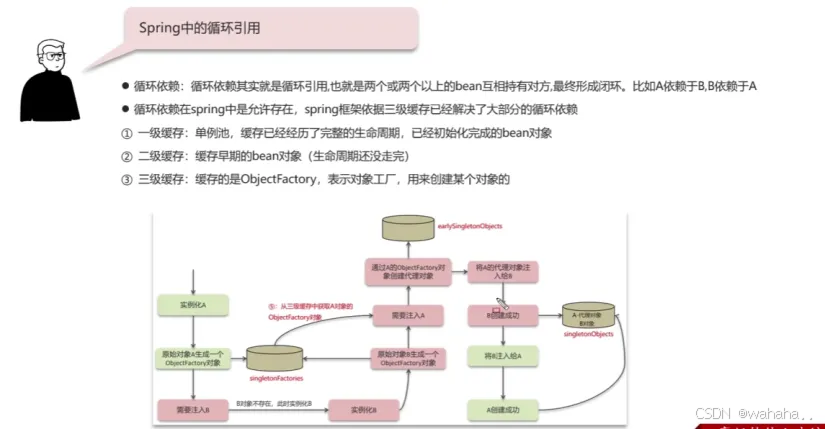
Spring中的循环依赖(使用三级缓存解决)
SpringMvc执行流程

SpringBoot自动装配原理

深拷贝与浅拷贝
浅拷贝:
基本数据类型字段的拷贝:值被复制,新对象和原对象的字段在内存中是不同的
引用类型字段的拷贝:对于引用类型,它们的引用被复制,他们指向同一个内存空间,是同一份数据
深拷贝
在 Java 中是指创建一个新对象,同时递归地复制所有引用类型的字段,这样使得新对象完全独立于原对象。新对象的引用类型字段指向新的的内存空间,基本类型字段也是新的内存空间
深拷贝和浅拷贝的区别:深拷贝把给引用类型字段申请新的内存空间,并将原对象的数据复制到新的对象的空间中。浅拷贝只是引用赋值,还是指向同一内存空间
浅拷贝还要考虑 可变引用类型字段 和 不可变引用类型字段
浅拷贝可以实现Cloneable接口,重写clone 方法实现浅拷贝
深拷贝的浅拷贝的基本类型字段拷贝时,都会创建新的空间
Redis面试题
缓存穿透
去查redis里面没有查到数据 直接去查了DB–造成库的压力过大 优化:设置临时值 为null 或者加布隆过滤器
缓存击穿
redis里面单个key过期了 优化:使用互斥锁 第一个线程上锁 去查数据 再set 第二个线程就查到了(性能差)
缓存雪崩
redis里面大量key同时过期或者是redis宕机 优化:给不同的key设置不同的失效时间
redis与mysql数据一致性
延迟双删 删除缓存–>修改数据库–>延时500毫秒–>删除缓存(也会有脏数据风险)
Redis的持久化(建议两种模式都开启)
RDB(默认 恢复较快) 读取rdb文件里面的数据进行恢复
AOF 修改redis.conf文件里面的appendonly yes 开启 记录每次命令
Redis的过期策略(建议两种配合使用)
惰性删除 当key过期以后,还是存在redis里面占用着内存,每次获取的时候 如果key过期 再删除
定时删除(不占用内存) 每隔一段时间去检查redis里面过期的key 有两种模式slow/fast