2025-arXiv-AlphaSharpe: LLM 驱动的稳健风险调整金融指标
arXiv | https://arxiv.org/abs/2502.00029
代码 | https://anonymous.4open.science/r/alphasharpe
摘要:
金融指标(如夏普比率)在评估投资表现方面至关重要,它们通过平衡风险与收益来进行评价。然而,传统的金融指标在稳健性和泛化能力方面常常存在不足,特别是在动态和波动的市场条件下。
本文介绍了一种名为 AlphaSharpe 的新型框架,该框架利用 LLMs 迭代地进化和优化金融指标,以发现超越传统方法的增强型风险-收益指标。通过迭代交叉、变异和评估,AlphaSharpe 能够更好地与未来的绩效指标相关联,在稳健性方面表现出色。
一、引言
金融指标对于评估投资业绩至关重要,例如夏普比率等指标长期用于评估风险调整后的回报。尽管这些指标被广泛采用,但存在明显的局限性:
- **对极端值的敏感性:**可能会因收益率分布中的极端值而失真。
- **稳定性假设:**假定风险与收益关系是静态的,但在动态市场中这可能并不成立。
- **回顾性本质:**评估过去的表现而未能充分与未来结果相关联。
- **有限的泛化能力:**往往无法适应多种资产类别或市场条件,导致决策欠佳。
**概率性夏普比率(Probabilistic Sharpe Ratio, PSR)**改进了传统的夏普比率,通过纳入统计推断来应对绩效评估中的不确定性。通过考虑夏普比率估计值的分布,PSR 降低了噪声,并提供了绩效一致性的一种概率性解释。在金融投资绩效指标方面,人类发现的创新如PSR具有革命性意义,但仍存在鲁棒性和预测泛化的不足。
机器学习(ML)通过引入传统方法所缺乏的自适应和预测能力,已经彻底改变了金融分析。ML 方法在组合优化、风险管理以及指标设计方面得到了广泛应用。深度神经网络和强化学习等 ML 模型能够学习动态资产配置策略。这些模型在不同市场条件下优化风险调整后的回报,从而超越了静态组合策略。DNNs可以用于训练非线性指标,捕捉回报数据中的复杂关系,提供比传统方法更高的预测准确性。然而,这些方法极易发生过拟合,并且缺乏可解释性。
强化学习领域的进展,尤其是通过 AlphaTensor 和 AlphaCode 为迭代优化和创造性问题解决提供了范例。
-
AlphaTensor 利用多智能体强化学习对算法进行迭代优化,发现了矩阵乘法的高效方法。其迭代优化框架启发了对金融指标演变方法的研究。
-
AlphaCode 突显了大规模模型在生成高质量编程代码方面的潜力,它从示例中学习并通过迭代反馈精炼输出的能力,与为离样本鲁棒性优化的金融指标生成过程极为相似。
二、方法
LLMs 已在多个领域展示了生成创意和稳健算法代码的卓越能力。在本研究中,LLMs 被用于革新金融指标发现,具体方法包括:
- **少样本生成:**利用少量示例生成现有和已发现指标的创造性变体,结合领域专业知识与数据驱动的洞察。
- **迭代优化:**采用进化策略和反馈循环,逐步优化生成的指标,以提高稳健性和预测能力。
- **跨领域启发:**通过广泛的数据训练,LLMs 可以从其他学科引入概念,创新金融指标。
- **突变精炼:**借鉴进化算法的理念,LLMs 可以建议现有指标的变异,优化稳健性和泛化能力。
- **自动代码生成:**类似于 AlphaCode,LLMs 可以生成高质量的新金融指标的实现代码。
- **批判性思维和综合:**通过分析学术文献,LLMs 将理论洞察整合到指标设计中,确保新颖性和严谨性。
AlphaSharpe 旨在通过利用 LLMs 的创造力和批判性思维,逐步优化金融绩效指标(如夏普比率),以增强其在样本外的稳健性。该框架采用了一种结合 LLMs 隐含领域专业知识和进化策略的进化方法,设计出具有优异稳健性和泛化能力的指标。LLMs 通过借鉴学术文献和金融分析的最佳实践生成新颖的指标,少样本学习和提示工程指导LLMs生成相关且创新的指标。
2.1 架构
该工作流程包含一个迭代的四步过程,通过**交叉、变异、评分和排序(选择)**逐步细化金融指标。每个迭代旨在逐步提高指标的稳健性和预测能力。框架在一个循环管道中运行,每个迭代通过交叉和变异来精炼现有指标或生成新的指标:
- **交叉:**将多样化的顶级性能指标中的元素结合,创建能够继承所有指标优点的混合指标。
- **变异:**通过对交叉组合的指标进行小而有针对性的修改,LLM 生成有意义的变异版本,以增强预测能力(样本外稳健性)。
变异后的指标通过基于以下标准的评分函数进行评估:
- **稳健性:**对异常值和极端市场条件的敏感性。
- **一般化能力:**指标在历史数据中的得分与未来表现(例如,未来的夏普比率)之间的相关性。
- **预测能力:**在识别高绩效资产方面的统计相关性。
指标根据质量和多样性进行排名,仅保留排名靠前的候选指标用于后续迭代中的交叉。交叉过程将评分阶段中排名靠前的指标结合,创建融合其计算元素的混合指标。这一过程利用了单个指标的优点,同时减轻了其缺点。 排名靠后的指标被丢弃,确保只有多样化的高质量候选指标进入后续阶段。
2.2 LLM 用法
LLMs 在 AlphaSharpe 中发挥着核心作用,作为生成和优化指标的创意引擎。它们被训练理解基于研究论文、教科书和行业实践的上下文中的金融指标结构和目的。LLMs 模拟领域专家的思维过程,提出受现有方法启发的同时引入新颖元素的指标,以发现未被探索的维度。
为了有效利用LLMs的潜力,工作流程采用了精心设计的提示:
- 指导 LLMs 将领域特定的见解与上下文输入(如风险管理原则或投资组合策略)相结合;
- 鼓励创新和批判性思维,要求 LLMs **“跳出框框”**思考并提出更适用于未来的指标;
- 强调使用张量操作并避免资源密集型循环或冗余超参数。
2.3 评分函数
AlphaSharpe 采用稳健的评分机制来评估和优化金融指标。这些功能衡量所提出的指标对未来表现的泛化能力。 为了评估和排名表现最佳的指标,AlphaSharpe 采用以下工作流程:
(1)将所提出的指标应用于历史资产对数收益率数据集以计算得分;
(2)通过以下方式评估得分与未来夏普比率的一致性:
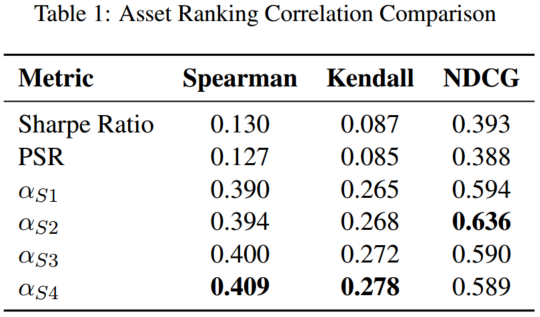
- **斯皮尔曼相关系数(Spearman’s Rho):**衡量历史数据中由指标产生的排名与实现的未来夏普比率之间的单调关系。
- **肯德尔相关系数(Kendall’s Tau):**评估指标得分与未来夏普比率之间序数关联的强度,提供一种稳健的排名相关性度量。
- **归一化折扣累积增益(NDCG):**评估资产排名的质量,更重视正确排名表现最佳的资产,这对于金融领域如投资组合选择等场景至关重要。
这些指标评估资产基于指标的排名与其基于未来表现的排名之间的一致性。通过依赖数据的秩而不是原始值,这些方法减少了对异常值和非线性的敏感性。
三、实验
时间序列交叉验证被用于验证和排名随时间演化的指标。
- 数据集包含 15 年来自 3,246 只美国股票和 ETF 的历史数据
- 在保留 20% 的数据作为外部测试集(3年)后,数据集被划分为多折。
指标根据其与交叉验证集内未来夏普比率的相关性进行演化,确保在不同时间段进行稳健评估。最终生成的指标(AlphaSharpe Ratio, α S \alpha_S αS)能够适应不同的市场条件,并提高对未来夏普比率的预测准确性。 α S 1 \alpha_{S1} αS1 至 α S 4 \alpha_{S4} αS4 指标是传统夏普比率的先进替代方案,解决了其在处理小样本量、极端值和非正态收益率分布方面的局限性。
- 基础指标 α S 1 \alpha_{S1} αS1:使用预期对数超额收益来强调复利效应,同时通过引入稳定性常数 ϵ \epsilon ϵ 来降低对极端值的敏感性,并确保在小数据集中的稳健性。
α S 1 = exp ( E [ log R − r f ] ) ( σ log R 2 + ϵ ) ⋅ ( σ log R + ϵ ) \alpha_{S1}=\frac{\exp(\mathbb{E}[\log R-r_f])}{\sqrt{(\sigma^2_{\log R}+\epsilon)\cdot(\sigma_{\log R}+\epsilon)}} αS1=(σlogR2+ϵ)⋅(σlogR+ϵ)exp(E[logR−rf])
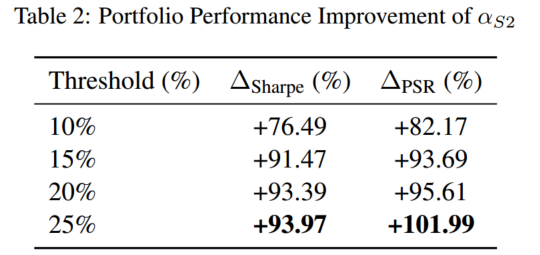
- 下行风险调整 & 预测波动率调整 α S 2 \alpha_{S2} αS2:在其父指标 α S 1 \alpha_{S1} αS1 的基础上,通过整合下行风险得以改进。这一改进考虑了负回报,并对其施以更重的惩罚,更好地反映了现实世界中的风险不对称性。同时, α S 2 \alpha_{S2} αS2也引入了预测波动率 V V V 作为前瞻性风险评估的额外组成部分。
α S 2 = exp ( E [ log R − r f ] ) σ log R 2 + ϵ + D R + V D R = σ R − + N R − ⋅ σ log R N R − + ϵ V = 1 n ∑ t = n / 4 n ( R t − E [ R ] ) 2 \alpha_{S2}=\frac{\exp(\mathbb{E}[\log R-r_f])}{\sqrt{\sigma^2_{\log R}+\epsilon}}+DR+V\\ DR=\frac{\sigma_{R^-}+\sqrt{N_{R^-}}\cdot\sigma_{\log R}}{N_{R^-}+\epsilon}\\ V=\sqrt{\frac{1}{n}\sum_{t=n/4}^n(R_{t}-\mathbb{E}[R])^2} αS2=σlogR2+ϵexp(E[logR−rf])+DR+VDR=NR−+ϵσR−+NR−⋅σlogRV=n1t=n/4∑n(Rt−E[R])2
- 高阶矩调整 α S 3 \alpha_{S3} αS3:在 α S 2 \alpha_{S2} αS2 的基础上进一步发展,通过纳入收益率分布的高阶矩(如偏度和峰度)并结合动态调整回撤风险,从而使得 α S 3 \alpha_{S3} αS3 能够更全面地评估风险调整后的绩效(MDD:最大回撤)。
α S 3 = α S 2 ⋅ ( 1 − K 12 ) ⋅ 1 + S 6 1 + M D D \alpha_{S3}=\alpha_{S2}\cdot(1-\frac{K}{12})\cdot\frac{1+\frac{S}{6}}{1+MDD} αS3=αS2⋅(1−12K)⋅1+MDD1+6S
- 制度因素调整 α S 4 \alpha{S4} αS4:通过引入依赖于制度的因子,动态调整以适应市场条件。
α S 4 = \alpha_{S4}= αS4=
α S 1 \alpha_{S1} αS1 至 α S 4 \alpha_{S4} αS4 指标特别适用于评估经过对数变换的收益率策略,尤其是在波动性市场或具有偏斜和厚尾收益率分布的场景中。
3.1 排名相关性
3.2 投资组合构建
top %,等权
四、LLM 投资组合优化
AlphaSharpe 投资组合是由大语言模型驱动的投资组合分配方法,通过整合逆协方差风险调整收益、稳定性调整权重、熵正则化和波动率归一化,显著提升了投资组合的表现。
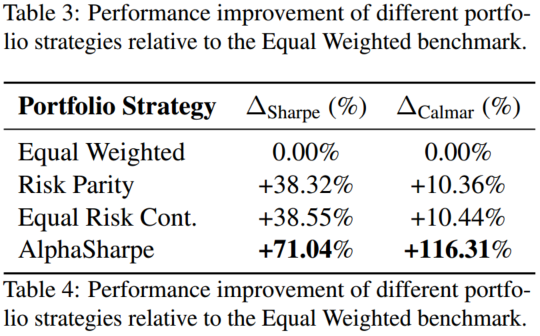
AlphaSharpe 投资组合优化方法采用结构化的方法,通过调整权重来实现稳定、波动性和分散性,同时保持最优的风险收益特征。
- 计算超额均值收益向量 μ \mu μ 和协方差矩阵,以及逆协方差调整后的风险收益向量。其中 R R R 是超额对数收益矩阵, λ \lambda λ 是一个常数。
μ = 1 T ∑ t = 1 T R t Σ = Cov ( R ) + λ I r = max ( 0 , Σ − 1 μ ) \mu = \frac{1}{T}\sum_{t=1}^T R_t\\ \Sigma=\text{Cov}(R)+\lambda I\\ r=\max(0,\Sigma^{-1}\mu) μ=T1t=1∑TRtΣ=Cov(R)+λIr=max(0,Σ−1μ)
- 引入一个稳定性因子,通过结合协方差调整后的风险收益向量的标准差来实现,并应用波动性归一化和 softmax 归一化方法,推导出初始资产配置。
r ′ = 1 + std ( r ) ⋅ r diag ( Σ ) + ϵ r'=\frac{1+\text{std}(r)\cdot r}{\sqrt{\text{diag}(\Sigma)+\epsilon}} r′=diag(Σ)+ϵ1+std(r)⋅r
- 引入熵正则化以确保多样化并惩罚主导资产。
H = − ∑ i w i log ( w i + ϵ ) w ′ = exp ( r ′ ) ∑ i exp ( r i ′ ) ⋅ e − H H=-\sum_i w_i\log(w_i+\epsilon)\\ w'=\frac{\exp(r')}{\sum_i\exp(r_i')}\cdot e^{-H} H=−i∑wilog(wi+ϵ)w′=∑iexp(ri′)exp(r′)⋅e−H
- 计算最终的投资组合权重,确保风险均衡分配的同时避免过度集中。
w
∗
=
max
(
0
,
w
′
)
∑
i
max
(
0
,
w
i
′
)
w^*=\frac{\max(0,w')}{\sum_i\max(0,w_i')}
w∗=∑imax(0,wi′)max(0,w′)
og(w_i+\epsilon)\
w’=\frac{\exp(r’)}{\sum_i\exp(r_i’)}\cdot e^{-H}
$$
- 计算最终的投资组合权重,确保风险均衡分配的同时避免过度集中。
w ∗ = max ( 0 , w ′ ) ∑ i max ( 0 , w i ′ ) w^*=\frac{\max(0,w')}{\sum_i\max(0,w_i')} w∗=∑imax(0,wi′)max(0,w′)