【技术追踪】DiffDGSS:基于扩散模型的确定性表示进行泛化性视网膜图像分割(MICCAI-2024)
分割分割,基于 DDIM 的分割~
论文:DiffDGSS: Generalizable Retinal Image Segmentation with Deterministic Representation from Diffusion Models
0、摘要
获取视网膜图像的完整分割图,是开发可解释性视网膜病变诊断工具的首要步骤。然而,视网膜解剖结构和病变的固有复杂性,加之数据的异质性和标注的稀缺性,给开发准确且可泛化的模型带来了挑战(这普遍的挑战~)。最近,去噪扩散概率模型(DDPM)在多种医学影像应用中展现出了良好的前景。
为了充分利用强大的预训练去噪扩散概率模型(DDPM),本文提出了一种名为 DiffDGSS 的新框架,旨在挖掘扩散模型的潜在表示,以实现域泛化语义分割(Domain Generalizable Semantic Segmentation, DGSS)。
特别是,本文证明了扩散模型的确定性反演可以产生稳健的表示,从而实现强大的域外泛化能力。随后,本文开发了一个自适应语义特征解释器,用于将这些表示投影到精确的分割图上(有点高级的样子)。在各种任务(视网膜病变和血管分割)和设置(跨域和跨模态)中进行的广泛实验表明,DiffDGSS 方法具有 SOTA 结果。
1、引言
1.1、当前不足
(1)视网膜解剖结构和病变的复杂性,不同数据集的可变性,以及标注的缺乏性,为视网膜分割任务带来挑战;
(2)从给定领域生成数据的能力意味着对该领域语义的深刻理解,一系列研究开始探讨从生成对抗网络(GANs)中获得的中间表征。研究表明,这些表征可以被解码,以生成图像的语义分割图;
(3)目前的 GANs 反演技术要么是重建质量有限,要么是需要显著的更高的计算成本;
(4)扩散模型有数千个噪声水平,难以确定训练过程中每一步学习什么特征,故难以确定时间步的优先级;
1.2、本文贡献
(1)提出 DiffDGSS,一种基于表示的创新方法,旨在实现精确的视网膜图像分割和鲁棒的域外泛化;
(2)设计了一个自适应的语义特征解释器来解码多尺度表示,并在采样时间步长上动态调整其行为;
(3)在各种任务和设置下进行的定性和定量实验,DiffDGSS 具有 SOTA 结果;
2、方法
Figure 1 | DiffDGSS 框架概述:给定一个现成的扩散模型,通过对确定性去噪扩散隐式模型(DDIM)进行反演,从网络中获取图像的稳健潜在表示。随后,在这个多尺度且依赖于时间步长的表示之上训练一个特征解释器分支,以预测分割图;
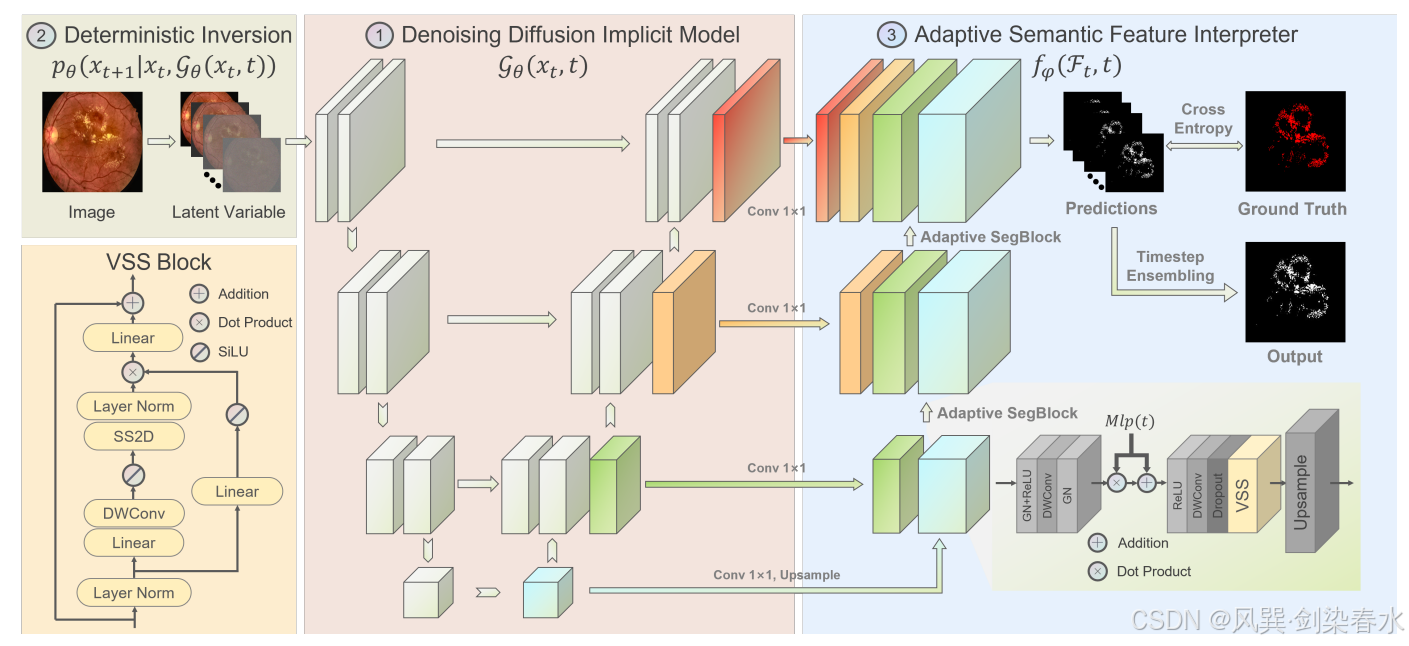
2.1、去噪扩散概率模型(DDPM)
略,详见【Diffusion综述】医学图像分析中的扩散模型(一)中 2.2.1 节
2.2、基于扩散模型的确定性表示法
Song 等通过非马尔可夫扩散过程引导相同的训练目标推广 DDPM,提出了一类更有效的迭代隐式概率模型 DDIM,该模型具有以下确定性后验分布:
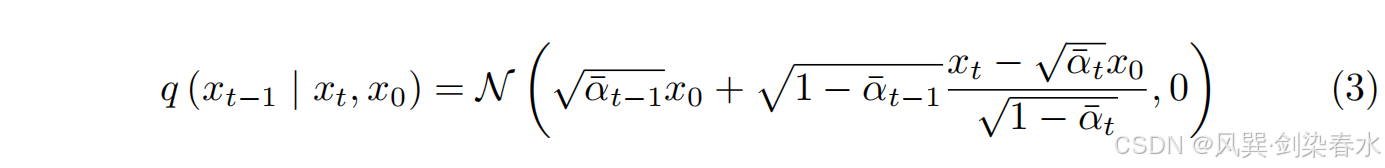
其中,
α
ˉ
t
=
∏
s
=
1
t
α
s
{{\bar \alpha _t} = \prod _{s=1}^{t}{\alpha _s}}
αˉt=∏s=1tαs,
α
t
=
1
−
β
t
{{\alpha _t} = 1 - {\beta _t}}
αt=1−βt ,由初始噪声
x
t
x_t
xt 开始的 DDIM 采样(生成)过程,形成一个隐式潜在空间,这与前向过程执行 ODE 积分相对应:
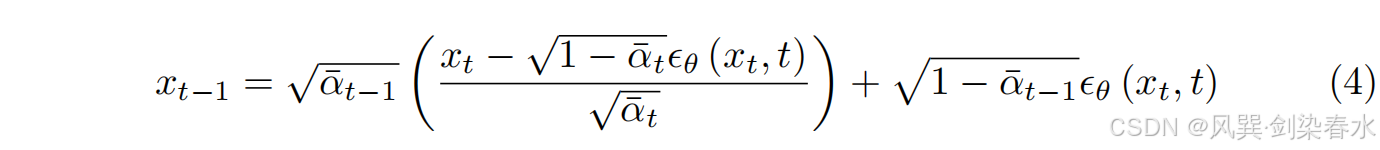
重要的是,可以反向运行这个生成过程(称为 DDIM 确定性反演),以检索能够高保真重建真实图像的潜在编码。尽管在每步中都引入了一个轻微的错误,但它在没有无分类器指导的情况下工作得很好。
本文的关键思想是,在潜在空间和图像空间之间有一个确定性的映射,因此可以用一个图像生成器
G
θ
(
x
t
,
t
)
{\mathcal G_θ(x_t,t)}
Gθ(xt,t) 参数化
μ
θ
(
x
t
,
t
)
{\mu_θ(x_t,t)}
μθ(xt,t),它将一系列潜在变量映射到一个特定的图像:
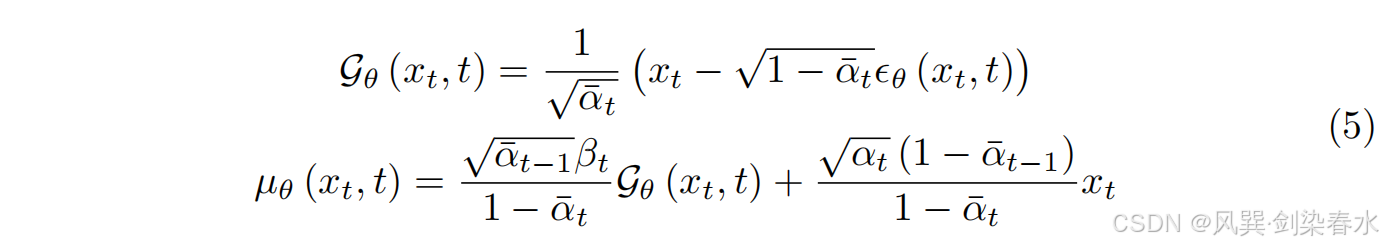
换言之,该网络预测一个给定
x
t
x_t
xt 的干净输入
x
0
x_0
x0,它在执行 DDIM 确定性反演时,以中间特征映射的形式生成一组不同的潜在表示:
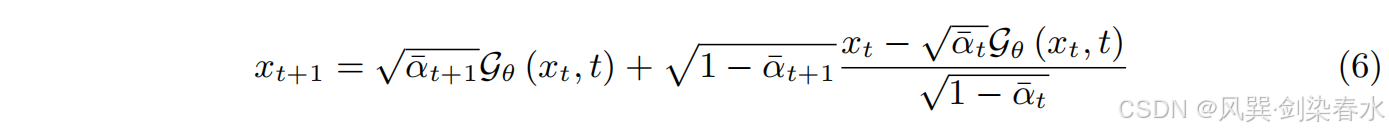
这种依赖于时间步长的表示允许将它们视为
x
0
x_0
x0 的确定性表示,用于语义分割。
2.3、自适应语义特征解释器
开发了一个自适应语义特征解释器
f
φ
(
F
t
,
t
)
{f_φ(\mathcal F_t,t)}
fφ(Ft,t) 来解释多尺度表示
F
t
{\mathcal F_t}
Ft,并在采样时间步长
t
t
t 上动态调整。它采用自适应组归一化层(AdaGN)对时间步长依赖的表示进行调整,通过对归一化特征图
h
∈
R
c
×
h
×
w
h \in \mathcal R^{c×h×w}
h∈Rc×h×w 应用通道缩放和移动来扩展组归一化:
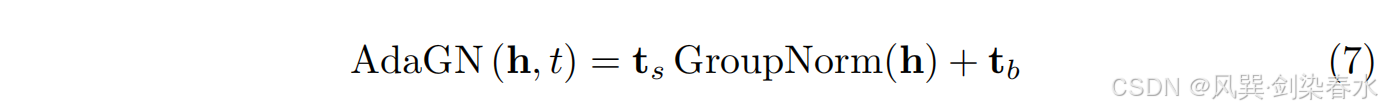
其中
(
t
s
,
t
b
)
∈
R
2
×
c
=
M
L
P
(
ψ
(
t
)
)
(t_s,t_b) \in R^{2×c} = MLP(ψ(t))
(ts,tb)∈R2×c=MLP(ψ(t)) 是一个具有正弦编码函数
ψ
ψ
ψ 的多层感知机的输出。自适应分段模块包括两个连续的 DWConv 模块,然后是基于 VSS 的 Mamba 模块,用于短期和长期依赖建模。在推理时,使用多数投票机制对每个时间步相关表示的预测图进行集成,得到最终的分割图。
3、实验与结果
3.1、数据集与评价指标
【1】数据集
(1)EyePACS 数据集(88702 张图)预训练 DDPM;
(2)病变分割数据集:IDRID
(3)血管分割数据集:STARE,HRF,DRIVE,CHASEDB1;
(4)跨膜态血管分割 OCTA 数据集:OCTA-500,ROSE;
【2】评价指标
(1)病变分割性能:AUC,PR,ROC;
(2)血管分割性能:DSC
3.2、实施细节
(1)去除黑色边界区域,将大小调整到 512×512;
(2)CLAHE 提高图像对比度;
(3)数据增强:翻转;
(4)DDPM 总迭代次数为 120K,扩散步长为 4000;
(5)特征解释器训练:在第10个模块之后的 DDPM 解码器中,在时间点步长 {1, 10, 100, 500} 时提取的;
(6)Adam 优化器,学习率设置为 0.0002,batch size 为 4;
3.3、DGSS 的确定性表示法
Figure 2 | 两个真实图像之间的语义插值:利用DDIM确定性反演技术得到给定图像的潜在码,并对它们进行线性插值,然后将它们解码到图像空间中;
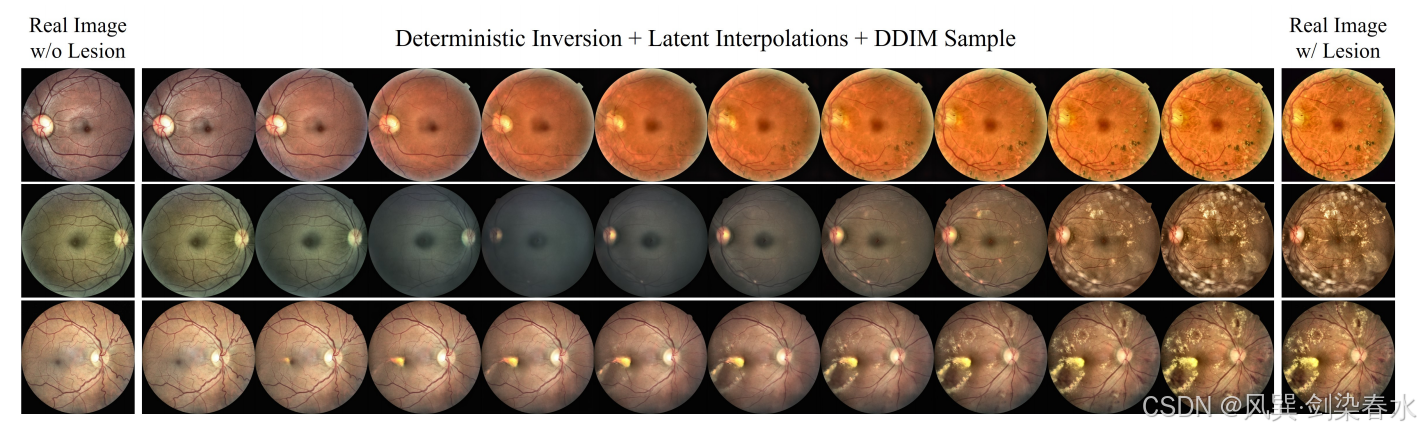
确定性反演能够生成潜在表示,即使仅使用少数步骤也能实现合理的重建。重要的是,这些发现还展示了潜在空间在训练域之外的泛化能力,能够成功保留并重建来自先前未遇到领域或模态的视网膜图像的语义复杂性。有趣的是,即使使用 ImageNet 预训练的 DDPM,它也能产生具有一定保真度的重建图像,这与随机 DDPM 采样的输出形成鲜明对比,后者的输出仅保留了极少量的语义相关性。
Figure 3 | 视网膜图像重建中域外泛化的可视化:在广泛的时间步长和数据设置范围内的 DDIM 确定性反演和采样的全面分析;
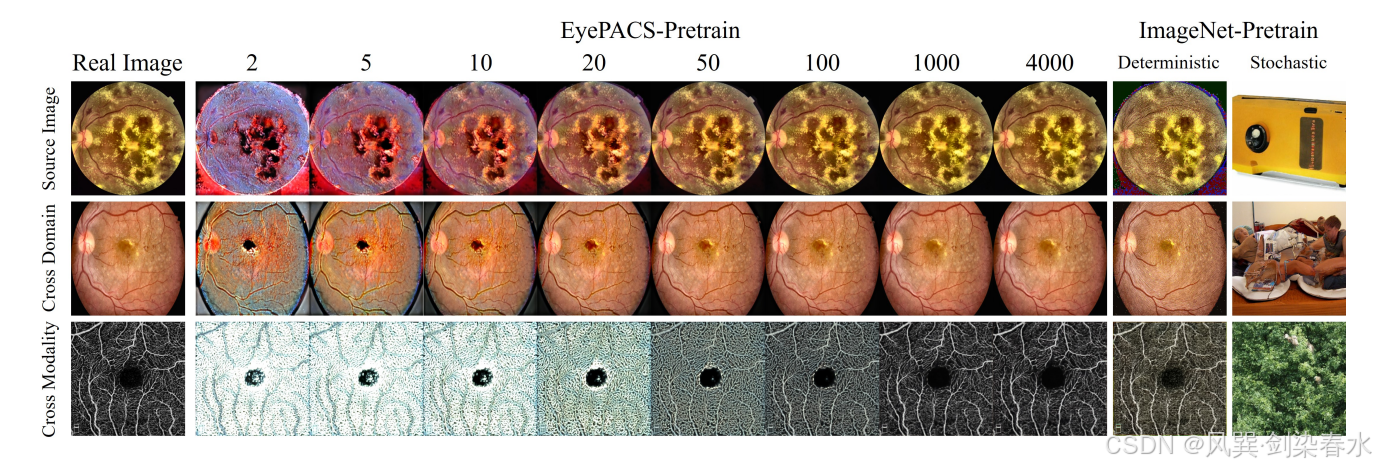
Figure 4 | 在扩散步骤 {1, 10, 50, 100, 500, 1000} 中,对 DDPM 解码器中的 {8, 12, 16, 20} 块生成的表示进行 k-means 聚类 (k=5) 的可视化:

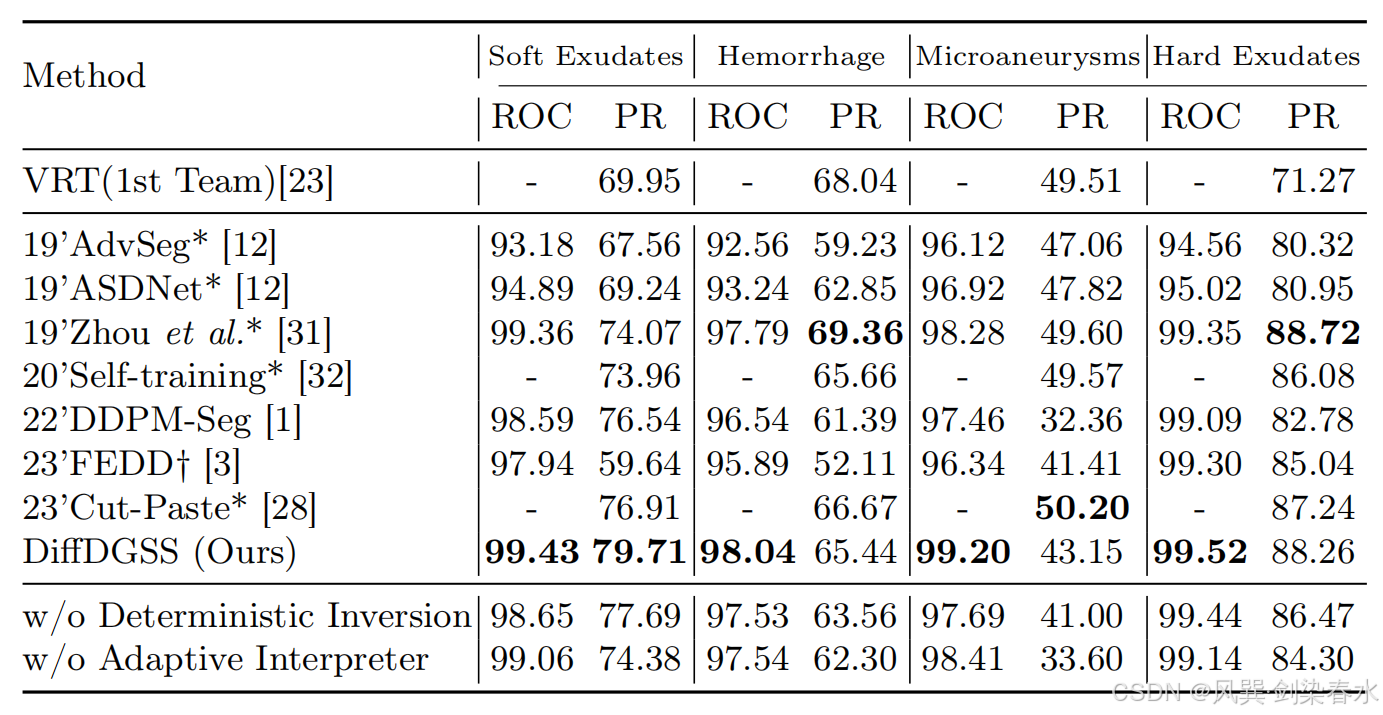
3.4、IDRID 数据集的比较与消融研究
Table 1 | 在 IDRID 数据集上与最先进方法的比较结果:
3.5、视网膜血管分割的跨域和跨模态泛化
Table 2 | 在视网膜血管分割上与最先进 DGSS 方法的定量比较:

待我回忆一下 DDIM ٩(๑•̀ω•́๑)۶