【大模型学习】第十六章 模型微调技术综述
目录
一、技术起源:为什么我们需要模型微调?
1.1 深度学习发展的分水岭
1.2 生物学启示:迁移学习的力量
1.3 工业实践的倒逼
二、通俗解读:模型微调就像装修二手房
2.1 日常生活的类比
2.2 学生培养的启示
三、技术深潜:微调的核心方法论
3.1 参数冻结策略对比
3.2 学习率设置的黄金法则
3.3 损失函数的动态加权
四、架构演进:从CNN到Transformer的微调革命
4.1 计算机视觉的进化之路
4.1.1 模型概述
4.1.2 微调参数比例的变化趋势
4.1.3参数比例变化示意图
4.2 NLP领域的范式转移
一、技术起源:为什么我们需要模型微调?
1.1 深度学习发展的分水岭
2012年ImageNet竞赛中,AlexNet以超越第二名10%的准确率震惊世界,标志着深度学习时代的到来。但鲜为人知的是,当时的冠军模型训练需要两周时间——使用两个NVIDIA GTX 580 GPU(各1.5GB显存)。这个细节暴露了深度学习的两个关键痛点:训练成本高昂与数据需求巨大。
2018年,Google发布BERT模型时,训练成本估算高达6.1万美元(TPU v3芯片运行4天)。这种指数级增长的计算需求,使得普通研究者和企业难以承受从头训练模型的代价。正是这种背景下,模型微调(Fine-tuning)技术逐渐成为深度学习应用的标配。
1.2 生物学启示:迁移学习的力量
人类的学习过程天然具有迁移特性。一个学会骑自行车的人,学习骑摩托车时会自然迁移平衡控制能力,而不需要重新学习地球引力定律。神经科学研究表明,大脑皮层不同区域存在功能特化与知识共享机制,这与深度学习中的特征迁移具有惊人的相似性。
1.3 工业实践的倒逼
某医疗AI初创公司的真实案例极具代表性:他们试图用10万张肺部X光片训练肺炎检测模型,但最终准确率仅68%。当改用ImageNet预训练的ResNet-50进行微调后,准确率跃升至92%,训练时间从3天缩短到6小时。这个案例揭示了微调技术的核心价值——在特定领域实现专家级性能,而不需要领域专家的数据量。
二、通俗解读:模型微调就像装修二手房
2.1 日常生活的类比
想象你要装修房子:
- 从头训练:买地皮→打地基→砌墙→装修(耗时2年,成本300万)
- 微调:购买精装房→改造厨房→更换软装(耗时2月,成本30万)
预训练模型就像开发商提供的精装房,已经具备良好的基础功能(空间布局、水电管线)。微调就是根据你的个性化需求进行改造,保留通用功能的同时优化特定区域。
2.2 学生培养的启示
清华大学计算机系的教学改革提供了另一个视角:
- 传统教学:四年完整课程体系(200学分)
- 微调模式:接收其他高校转学生(已修150学分基础课)+ 定制专业课程(50学分)
这显著降低了培养成本,同时保证专业深度。模型微调正是这种"转学生培养方案"的机器学习版本。
三、技术深潜:微调的核心方法论
3.1 参数冻结策略对比
| 策略 | 训练参数占比 | 适用场景 | 典型案例 |
|---|---|---|---|
| 全网络微调 | 100% | 数据充足(>10万样本) | 医学影像分析 |
| 顶层微调 | 5-10% | 小样本(<1千样本) | 工业缺陷检测 |
| 分层解冻 | 20-50% | 中等数据量 | 金融风控模型 |
| 适配器微调 | 3-5% | 多任务持续学习 | 对话系统 |
3.2 学习率设置的黄金法则
BERT微调的经典配置揭示了一个重要规律:微调学习率通常比预训练小1个数量级。数学表达为:
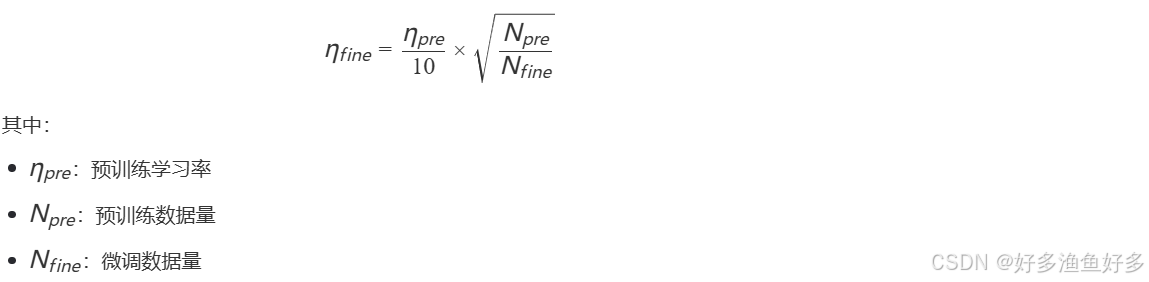 这个公式平衡了参数更新幅度与数据分布差异,在实践中可将收敛速度提升2-3倍。
这个公式平衡了参数更新幅度与数据分布差异,在实践中可将收敛速度提升2-3倍。
3.3 损失函数的动态加权
在多任务微调中,损失函数设计至关重要。假设我们有主任务L1和辅助任务L2,动态加权策略可以表示为:
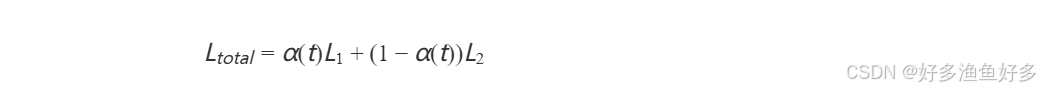
其中α(t)α(t)随时间t变化 。
四、架构演进:从CNN到Transformer的微调革命
4.1 计算机视觉的进化之路
4.1.1 模型概述
-
AlexNet: AlexNet是2012年提出的一个经典的卷积神经网络(CNN),它有8层(5个卷积层和3个全连接层),总共有约6000万个参数。
-
Vision Transformer (ViT): ViT是一个基于Transformer架构的模型,用于处理图像数据。与传统的CNN不同,ViT将输入图像分割成固定大小的块,并将这些块线性嵌入为序列,然后通过标准的Transformer编码器进行处理。ViT的参数数量根据其配置(如Base、Large等)而异,但一个典型的ViT-B/16配置大约包含8600万个参数。
4.1.2 微调参数比例的变化趋势
从AlexNet到ViT,随着模型复杂度和深度的增加,直接微调整个模型变得不那么实际,尤其是当目标任务的数据集相对较小的时候。因此,微调策略也发生了变化:
-
AlexNet:由于其相对较少的参数量,对于许多应用来说,可以对整个网络进行微调。但是,在一些情况下,为了防止过拟合,人们可能会选择只微调最后几层(通常是全连接层)。
-
Vision Transformer:鉴于ViT庞大的参数量,直接对所有参数进行微调往往不是最优选择,特别是当目标任务的数据量有限时。因此,更常见的做法是冻结大部分预训练权重,仅微调顶层或添加一个新的分类头进行微调。
4.1.3参数比例变化示意图
| 模型类型 | 初始微调比例 (%) | 随着数据集增大可能的微调比例 (%) |
|--------------|------------------|-----------------------------------|
| AlexNet | 100% 或 10%-50% | 可能接近100%,取决于具体任务 |
| Vision Transformer | 1%-10% | 根据数据集大小和任务需求增加 |-
在AlexNet中,如果数据集足够大且多样化,可以直接微调全部参数;否则,可能会选择仅微调部分层(例如,最后的全连接层),这意味着微调的比例可能是10%-50%甚至更高。
-
对于Vision Transformer,初始阶段可能只微调非常小的一部分参数(如新的分类头或者顶层的少量参数),这可能只占总参数的1%-10%。随着更多标注数据的可用性增加,这个比例可能会逐渐上升,但仍然倾向于保持较低水平以避免过拟合。
4.2 NLP领域的范式转移
Transformer架构的涌现带来了微调方式的根本变革。以BERT为例的两种微调范式对比:
传统方式:
bert = BertModel.from_pretrained('bert-base-uncased')
classifier = nn.Linear(bert.config.hidden_size, num_labels)
# 微调所有参数
optimizer = AdamW(bert.parameters(), lr=5e-5)
现代参数高效微调:
from peft import get_peft_model, LoraConfig
peft_config = LoraConfig(
task_type="SEQ_CLS",
r=8,
lora_alpha=32,
target_modules=["query", "value"]
)
bert = get_peft_model(bert, peft_config) # 仅训练0.5%参数
这种LoRA(Low-Rank Adaptation)方法在GLUE基准测试中,使用1%的训练参数即可达到全参数微调97%的性能。