LLM - 白话向量模型和向量数据库
文章目录
- 向量是什么
- 向量的用途
- 向量相似 vs 文本相似
- 传统关键词搜索的匹配逻辑
- 匹配过程分析
- 语义搜索的向量化解析
- 语义关联分析
- 搜索结果对比
- 从关键词到语义的搜索演进路线
- 向量如何比较相似性
- 向量模型的技术原理
- 计算向量 ---- 嵌入模型
- 嵌入模型的工作原理
- 文本嵌入:让计算机理解语言
- 图像嵌入:让计算机“看懂”图片
- 音频嵌入:让计算机“听懂”声音
- 存储和比较向量 ---- 向量数据库
- 向量模型的应用
- 大模型中向量模型的核心应用
- 优缺点
- 小结

向量是什么
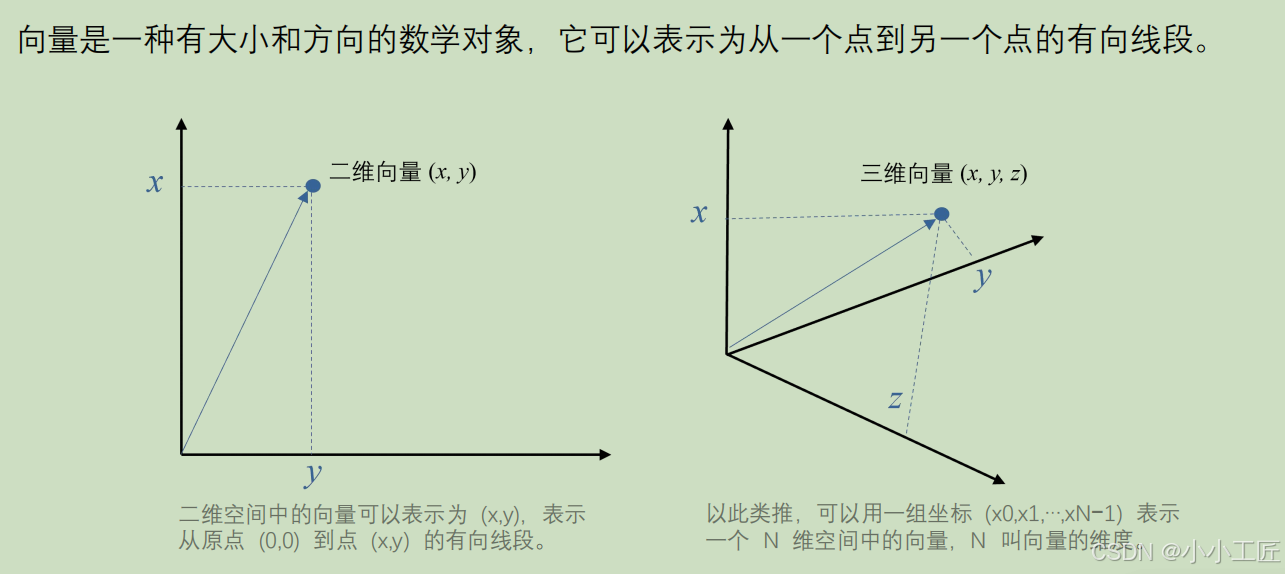
从数学的角度看,向量是一个“有方向和大小的东西”,可以用数字坐标来描述。在计算机世界中,我们可以把向量简单地理解为一组“有意义的数字”,用来表示事物的特征。
比如,我们要描述一只鸟,可以说:
“它有红色羽毛。它会唱歌。它的大小和手掌差不多。”
这些信息就可以被转化成向量,比如:
[红色: 0.913, 唱歌: 0.823, 大小: 0.534]
每个数字代表一项特性,这样鸟的特性就被数字化了。
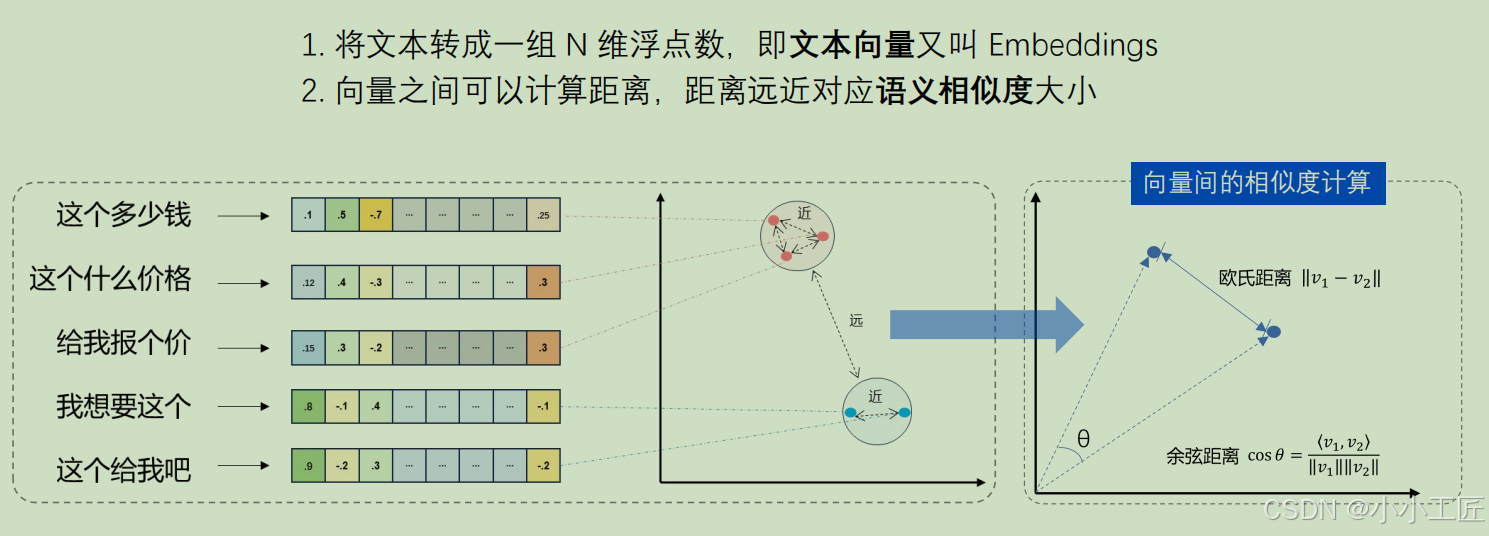
无论是鸟、图片还是一句话,都可以用向量来描述。这种“通用的数字化语言”让计算机能理解复杂事物,也更利于AI中复杂的算法进行处理。
向量的用途
向量除了有利于数学算法处理外,核心特点是能表示事物之间的“相似性”。
比如两个水果的向量:
苹果:[红色: 0.92, 甜度: 0.83, 圆形: 0.78]
草莓:[红色: 0.85, 甜度: 0.75, 圆形: 0.62]
虽然苹果和草莓是不同的水果,但它们的向量很接近。这表明它们有相似的特性,比如颜色和甜度。但如果把“老虎”表示成向量,则和苹果的向量就不接近。通过比较向量的“距离”,计算机能快速判断哪些事物是相关的。

如果事物是用自然语言或者图片描述,当然也就可以比较文本或图片之间的相似性。
向量相似 vs 文本相似
假设用户想查询**“如何缓解儿童感冒鼻塞”**,现有两个医疗知识库文档:
- 文档1:“使用生理盐水喷雾清洁鼻腔可减轻儿童感冒时的鼻塞症状。”
- 文档2:“夜间抬高婴儿头部15°-30°,配合加湿器保持空气湿度,有助于呼吸道通畅。”
传统关键词搜索的匹配逻辑
用户查询词提取:“缓解”、“儿童”、“感冒”、“鼻塞”
匹配过程分析
| 文档 | 关键词命中情况 | 匹配结果 |
|---|---|---|
| 文档1 | 包含"儿童"、“感冒”、"鼻塞"三个关键词 | ✔️ 完全匹配 |
| 文档2 | 仅包含"儿童"("婴儿"未匹配) | ❌ 匹配失败 |
搜索结果排序:
- 文档1(关键词全匹配)
- 文档2(因缺少"感冒""鼻塞"被过滤)
实际缺陷:
文档2虽未明确提及"感冒鼻塞",但其内容(呼吸道通畅方法)对解决用户问题具有实操价值,但传统搜索机制无法识别。
语义搜索的向量化解析
通过大模型将文本映射到768维向量空间:
# 伪代码示例:向量相似度计算
query_vector = model.encode("如何缓解儿童感冒鼻塞") # 查询向量:[0.82, 0.15, ..., 0.73]
doc1_vector = model.encode(文档1内容) # 向量相似度:0.92
doc2_vector = model.encode(文档2内容) # 向量相似度:0.85
语义关联分析
-
文档1
- 关键词显性匹配:“鼻塞”、“感冒”
- 向量空间位置:与查询向量在症状处理子空间高度重叠
-
文档2
- 关键词隐性关联:
- “呼吸道通畅” → 与"鼻塞"形成反向语义关联
- “婴儿” → 与"儿童"在年龄关联子空间相邻
- 向量空间位置:位于家庭护理方法子空间,与查询意图部分重叠
- 关键词隐性关联:
搜索结果对比
| 搜索类型 | 返回结果 | 用户实际需求覆盖度 |
|---|---|---|
| 传统搜索 | 仅文档1:“生理盐水喷雾用法” | 60%(仅对症方案) |
| 语义搜索 | 文档1(第1位)+ 文档2(第2位) | 95%(对症+护理环境优化) |
从关键词到语义的搜索演进路线
关键突破点:
- 2017年Google推出BERT模型,首次实现搜索词与文档的上下文语义匹配
- 2023年Meta发布多模态向量模型ImageBind,支持文本、图像、音频的跨模态语义关联
向量如何比较相似性
向量的相似性通常通过计算向量之间的距离来比较。距离越小,相似性越高。常用的算法比如余弦相似度来判断向量距离
假设我们有两个文本的向量:
文本1:“AI帮助医生诊断疾病” → 向量为 [0.82, 0.61, 0.97]
文本2:“人工智能协助医疗诊断” → 向量为 [0.90, 0.73, 0.98]
计算余弦相似性,根据余弦相似度计算公式(不懂也没关系):
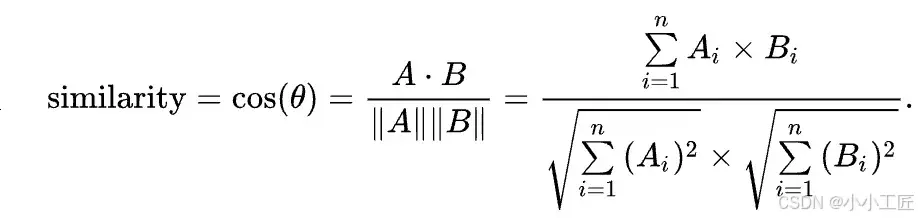
假设计算出相似度 = 0.99,非常接近1,说明两个文本的语义高度相似。
当然 ,在实际应用中,还有其他的相似度算法,可根据实际情况做选择。
向量模型的技术原理
在大模型(Large Language Models, LLMs)的架构中,向量模型(Vector Models)是支撑语义理解、知识表示和跨模态任务的核心技术组件。其核心目标是将离散的符号化数据(如文本、图像、音频)转化为连续的高维向量空间中的数学表示,从而为模型提供可计算的语义基础。
-
嵌入(Embedding)技术
向量模型通过嵌入层(Embedding Layer)将输入符号(如单词、像素、音素)映射到稠密向量空间。这一过程利用神经网络自动学习数据的内在特征,例如:- 文本领域:词嵌入(Word Embedding)将单词映射为向量,使语义相似的词在向量空间中距离更近(如“猫”与“犬”向量夹角较小)。
- 多模态场景:通过对比学习(Contrastive Learning)或跨模态注意力机制(Cross-Modal Attention),将文本、图像等不同模态数据映射到统一向量空间,实现跨模态语义对齐。
-
高维空间中的语义表示
向量模型通常采用数百至数千维的向量空间(例如768维或1024维),高维度特性使得模型能够捕捉细粒度的语义差异。例如,BERT等Transformer模型通过自注意力机制动态调整上下文相关的向量表示,解决一词多义问题(如“苹果”在“水果”与“公司”场景下的不同向量)。 -
相似性度量与运算
向量模型依赖余弦相似度、欧氏距离等度量方式评估向量间的关联性。此外,向量空间支持线性代数运算(如向量加减),可直观实现语义类比(如“国王 - 男 + 女 ≈ 女王”)。
计算向量 ---- 嵌入模型
嵌入模型是一种专门负责把复杂信息转化为数字向量的工具。它的核心任务是将人类能理解的信息(如文字、图片、音频)转换成计算机能处理的数学表示。比如:
- 一句话:“我喜欢看电影。” → 向量:
[0.7, 0.2, 0.5, 0.9] - 一张狗的图片 → 向量:
[0.8, 0.6, 0.4, 0.7]
这些数字不是随机的,而是包含了信息的核心特征。比如,向量中的某些数字可能代表“喜欢”“电影”或“狗”“毛发”等语义。
嵌入模型的工作原理
文本嵌入:让计算机理解语言
当我们输入一句话时,嵌入模型会分析每个词的语义,并将其转化为向量。例如:
- 输入:“我喜欢看电影。”
- 输出:
[0.7, 0.2, 0.5, 0.9]
这里的数字可能代表:
- 0.7:情感倾向(“喜欢”)
- 0.2:主题(“电影”)
- 0.5:句子长度
- 0.9:语境权重
通俗理解:嵌入模型就像一个“翻译官”,把人类语言翻译成计算机能理解的“数字语言”。
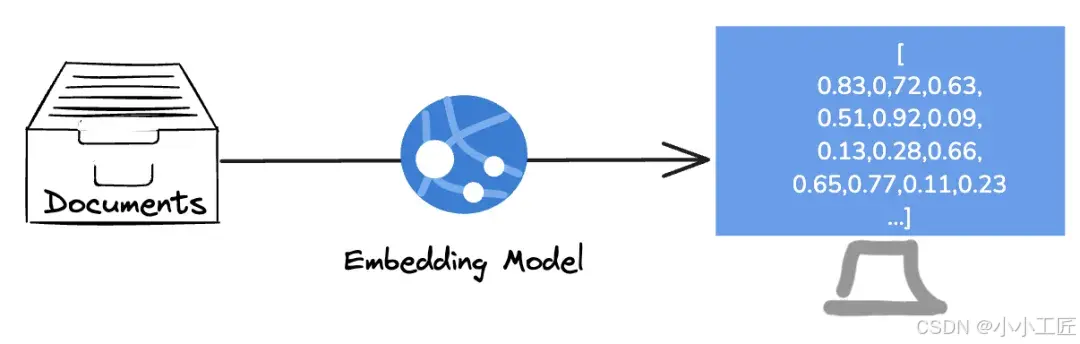
图像嵌入:让计算机“看懂”图片
当输入一张图片时,嵌入模型会提取图片的颜色、形状、轮廓等特征,并将其转化为向量。例如:
- 输入:一张狗的图片
- 输出:
[0.8, 0.6, 0.4, 0.7]
这里的数字可能代表:
- 0.8:动物类别(“狗”)
- 0.6:毛发特征
- 0.4:背景信息
- 0.7:图片清晰度
通俗理解:嵌入模型就像一个“画家”,把图片的特征用数字“画”出来。
音频嵌入:让计算机“听懂”声音
当输入一段音频时,嵌入模型会提取音高、节奏、语调等特征,并将其转化为向量。例如:
- 输入:一段钢琴曲
- 输出:
[0.9, 0.3, 0.6, 0.8]
这里的数字可能代表:
- 0.9:乐器类型(“钢琴”)
- 0.3:节奏快慢
- 0.6:情感强度
- 0.8:音频质量
通俗理解:嵌入模型就像一个“音乐家”,把声音的特征用数字“谱写”出来。
存储和比较向量 ---- 向量数据库
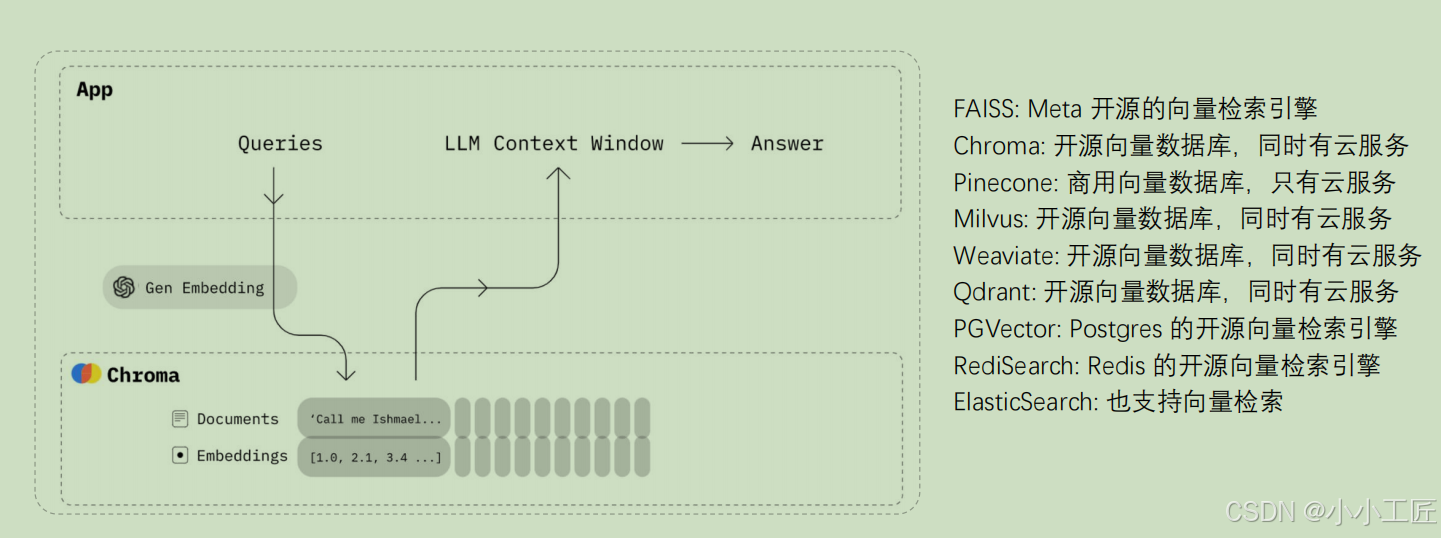
向量数据库是一种专门用于存储、管理和检索高维向量数据的数据库系统。它的核心任务是:
- 存储向量:将嵌入模型生成的向量(如文本、图片、音频的向量)持久化保存。
- 相似性搜索:根据用户输入的查询向量,快速找到数据库中与之最相似的向量。
与传统数据库的区别:
- 传统数据库:存储结构化数据(如姓名、年龄、地址),支持精确查询(如“年龄=30”)。
- 向量数据库:存储高维向量数据,支持相似性查询(如“找到与这张图片最相似的图片”)。
向量模型的应用
大家最熟知的是RAG应用中使用向量来查询相似资料
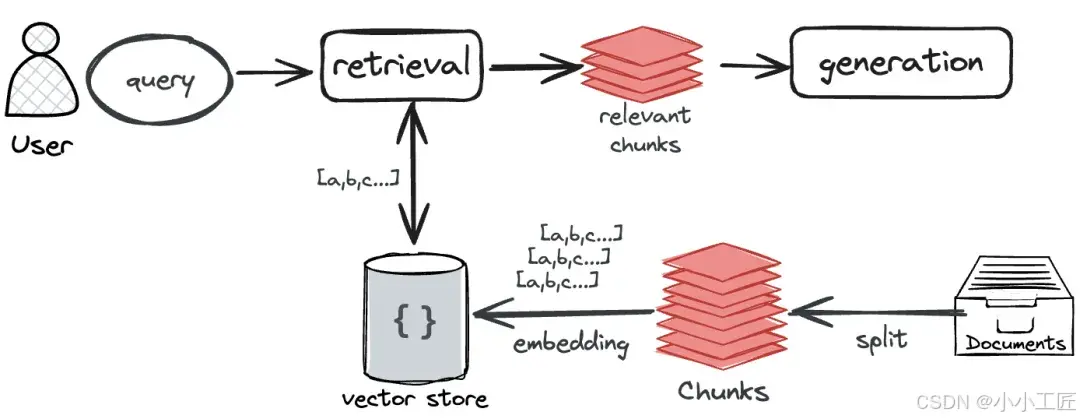
由于RAG应用是一种“边查边答”的应用,比如你问RAG应用:“C-RAG的基本原理是什么” 它需要检索出相关的资料段落(比如C-RAG论文),然后根据这些资料生成答案。
这时候,向量派上了用场:
首先把知识库里的文档分段转化成向量。比如:
段落1:[0.1, 0.7, 0.2]
段落2:[0.9, 0.1, 0.4]
段落3:[0.3, 0.8, 0.2]
然后,把问题“C-RAG的基本原理是什么”转化成一个向量。比如:
[0.2, 0.8, 0.1] (只是示例,真实的向量通常是几百甚至几千维的)。
接着,比较它与段落向量之间的“距离”(比如余弦相似度)。模型就能判断哪个段落最相关。
最后,大模型就可以使用最相关的段落来回答问题。
好比在图书馆找书时,根据书的分类和关键词找到了最合适的参考书。而RAG本质上不就是“看着参考书回答问题”吗?
当然,除了在RAG应用中外,向量其实是贯穿整个大模型推理过程的重要角色。在大模型的推理计算过程中,输入输出其实都是以向量形式来进行的。毕竟,数值计算才是计算机擅长的工作。
大模型中向量模型的核心应用
-
语义理解与推理
在预训练阶段,模型通过掩码语言建模(MLM)等任务学习上下文敏感的向量表示,使下游任务(如问答、摘要)能基于向量间的语义关联进行推理。 -
检索增强生成(RAG)
向量模型通过编码外部知识库(如维基百科)为向量索引,在生成阶段实时检索相关段落并融合到生成过程中,显著提升事实准确性和时效性。 -
多模态对齐
在多模态大模型(如GPT-4o、DALL·E)中,向量模型对齐文本与图像/视频的语义空间,支持跨模态生成(以文生图)和检索(以图搜文)。 -
模型微调与适配
通过冻结主干网络、仅微调顶层向量映射层(Adapter Layers),可高效适配领域特定任务(如医疗文本分类),降低训练成本。
优缺点
优势:
- 可扩展性:向量模型可处理海量异构数据,支撑大模型泛化能力。
- 高效检索:结合近似最近邻(ANN)算法(如Faiss、HNSW),实现毫秒级大规模向量检索。
- 可解释性:向量空间可视化工具(如t-SNE、UMAP)辅助分析模型语义分布。
挑战:
- 维度灾难:高维向量导致计算复杂度上升,需权衡维度与性能。
- 语义偏差:训练数据偏差可能导致向量空间中的刻板印象(如性别偏见)。
- 动态更新:静态向量难以适应实时变化的知识(如新闻事件),需结合增量学习优化。
小结
向量是现代人工智能的核心工具,用数字化方式描述数据特性,让计算机能够理解和比较复杂信息。从大模型的推理到 RAG 技术的应用,向量技术无处不在
