实验一:统计字符个数
集群测试
1.
cd ~
vim data.txt2.编辑data.txt
3.在HDFS创建lotusinput文件夹
hdfs dfs -mkdir /lotusinput4.将data.txt上传到HDFS
hdfs dfs -put data.txt /lotusinput
5.查看是否上传成功
hdfs dfs -ls /lotusinput6.运行MapReduce WordCount例子
cd ~/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /lotusinput /lotusoutput
hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /lotusinput/**.txt /lotusoutput
/lotusinput/**.txt 输入路径
/lotusoutput 输出路径
7.查看结果
hdfs dfs -cat /lotusoutput/part-r-00000可以在端口中查看
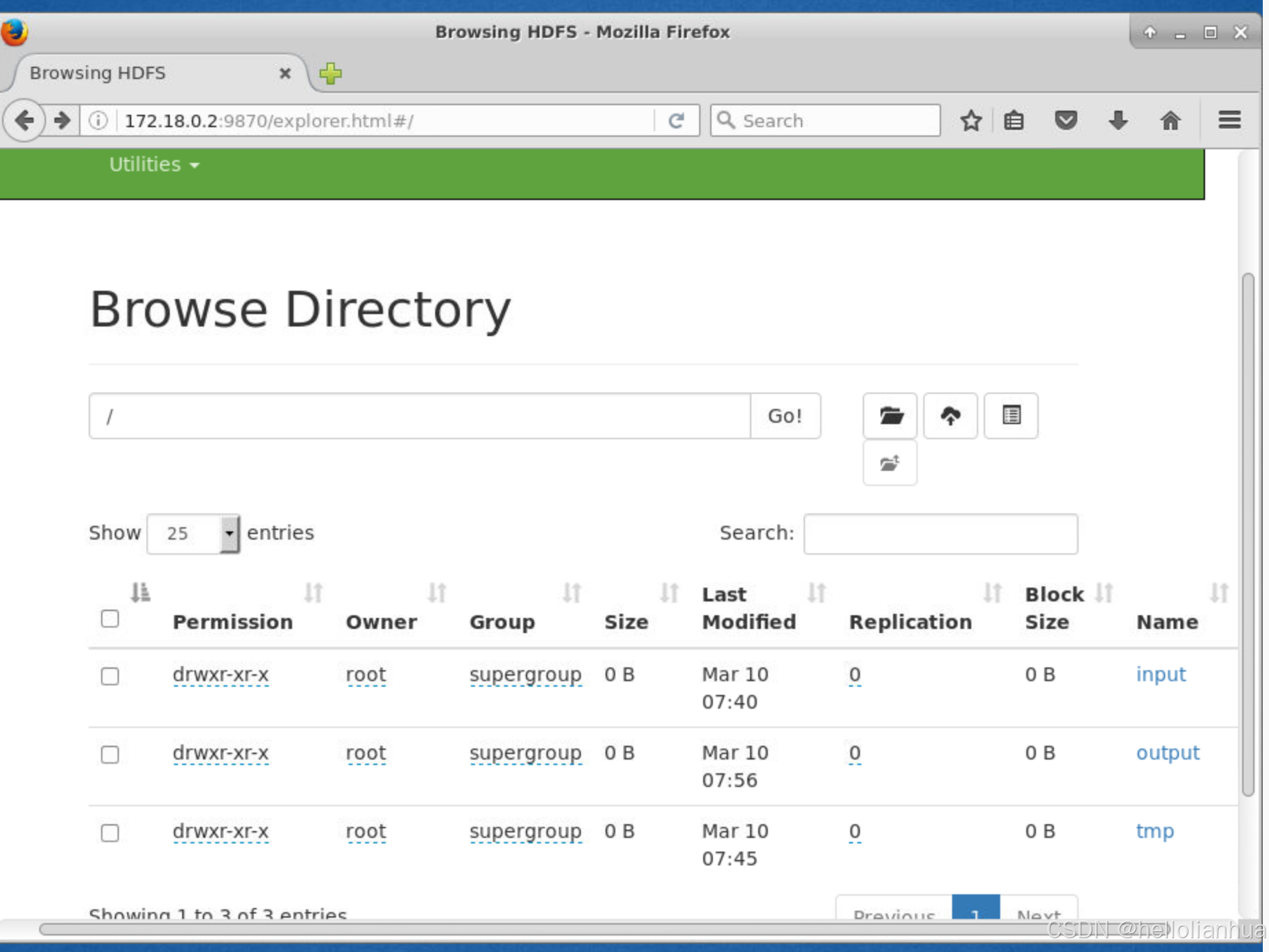
这只是一个方便查看的页面,这里存储的可以理解为指针。
实际的文件namenode地址为:
文件内容存储地址
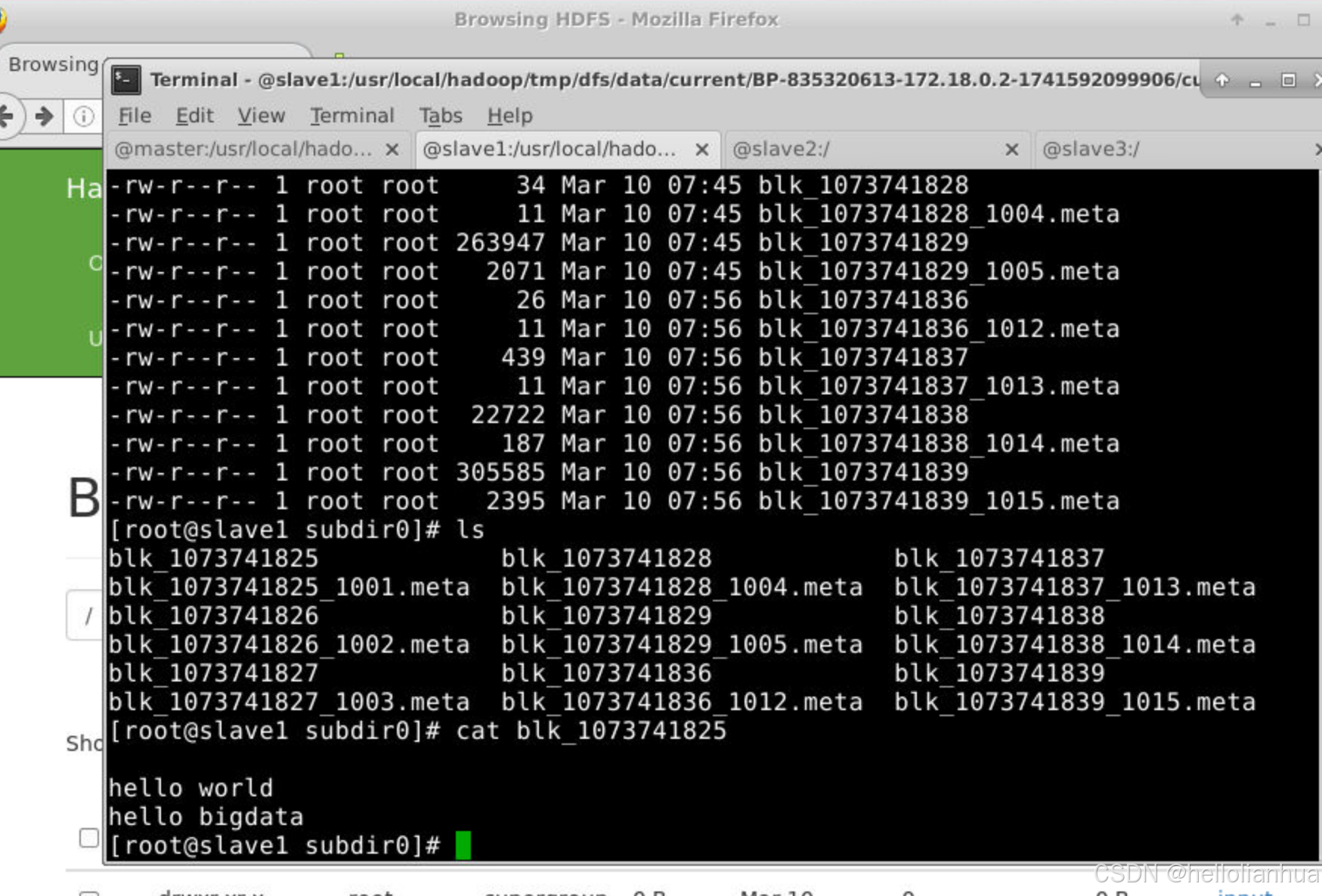
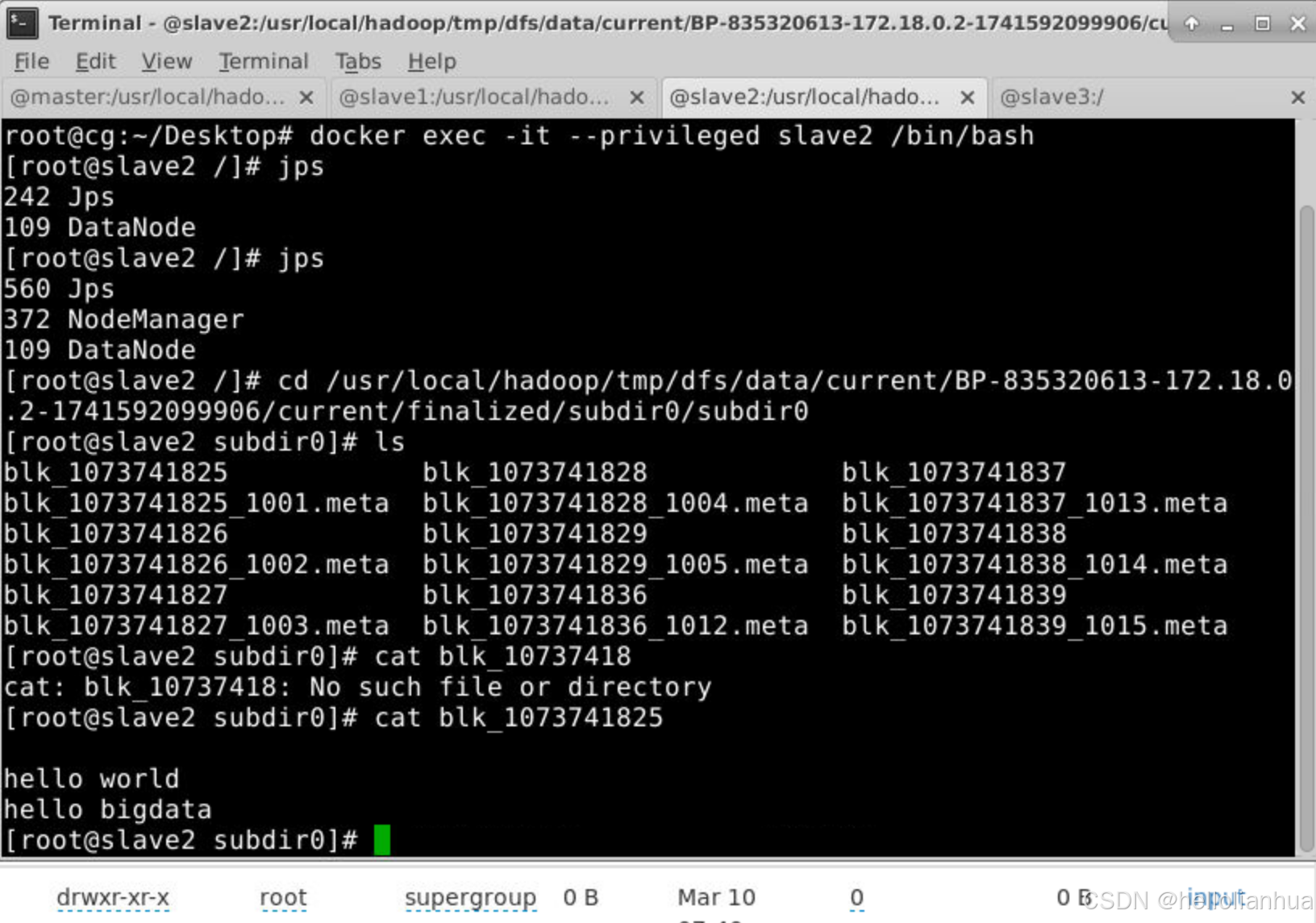
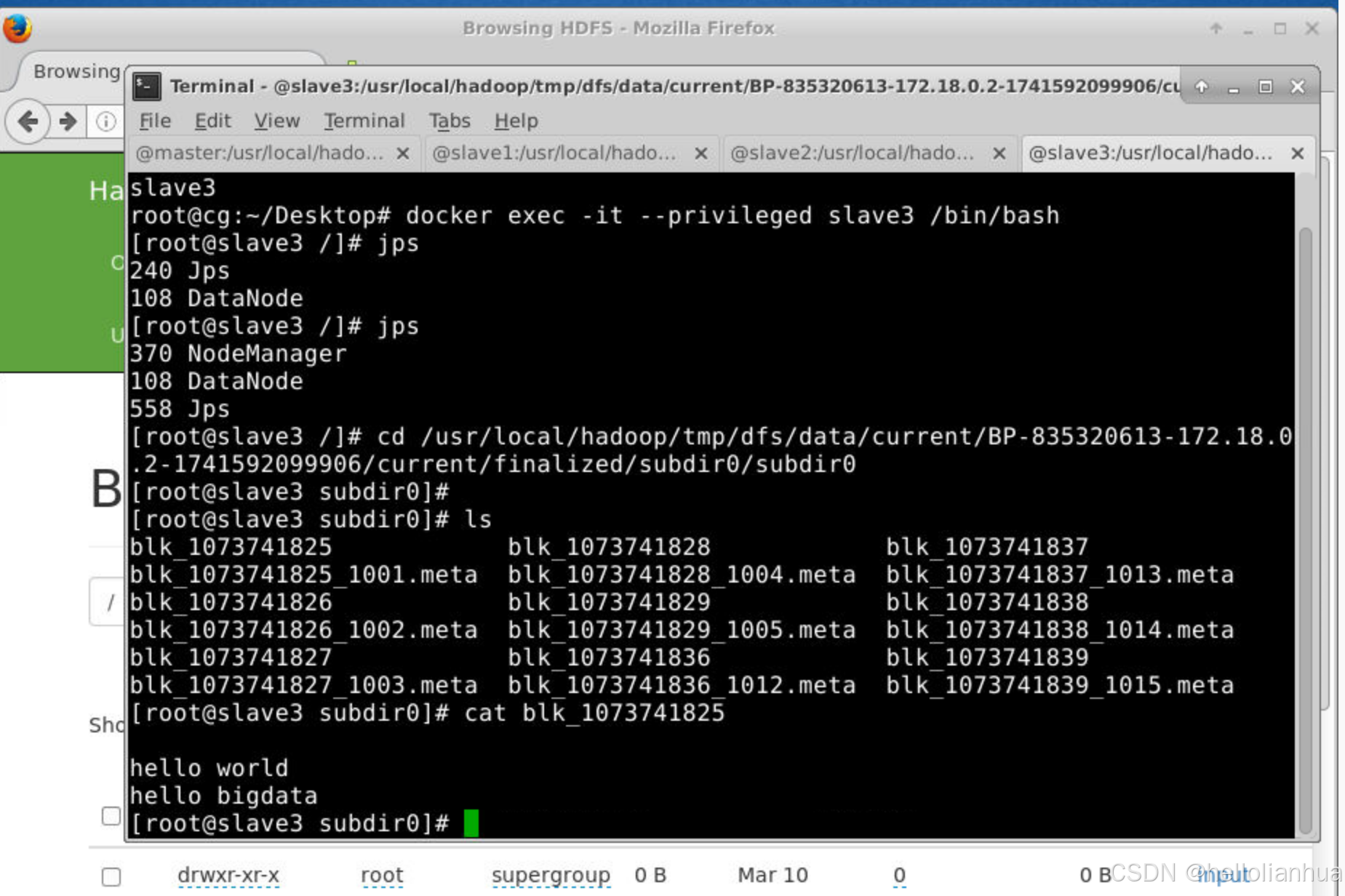
/usr/local/hadoop/tmp/dfs/data/current/BP-835320613-172.18.0.2-1741592099906/current/finalized/subdir0/subdir0。 注意:这里有三台服务器都有这个文件,因为我们的配置文件里面复印的分数是3份。如果我的集群存储datanoded的机器有4台,那么只有三台服务器有。