Flink集群部署
1. 集群角色
| 节点服务器 | node1 | node2 | node3 |
| 角色 | JobManager TaskManager | TaskManager | TaskManager |
2. 集群部署
2.1 下载并解压安装包
tar -zxf flink-1.17.0-bin-scala_2.12.tgz -C /export/server/
cd /export/server/
mv flink-1.17.0/ flink2.2 修改集群配置
cd flink/conf/
vim flink-conf.yaml
--修改如下几个配置
# JobManager节点地址,需要配置为当前机器名
jobmanager.rpc.address: node1
jobmanager.bind-host: 0.0.0.0
rest.address: node1
rest.bind-address: 0.0.0.0
# TaskManager节点地址,需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node1
vim workers
--修改为如下内容
node1
node2
node3
vim masters
--修改为如下内容
node1:80812.3 分发安装目录
cd /export/server/
scp -r flink node2:`pwd`/
scp -r flink node3:`pwd`/2.4 修改其余节点配置文件
cd /export/server/flink/conf/
vim flink-conf.yaml
--node2
taskmanager.host: node2
--node3
taskmanager.host: node32.5 启动集群
在node1节点服务器上执行start-cluster.sh启动Flink集群
cd /export/server/flink/
bin/start-cluster.sh
--停止集群
bin/stop-cluster.sh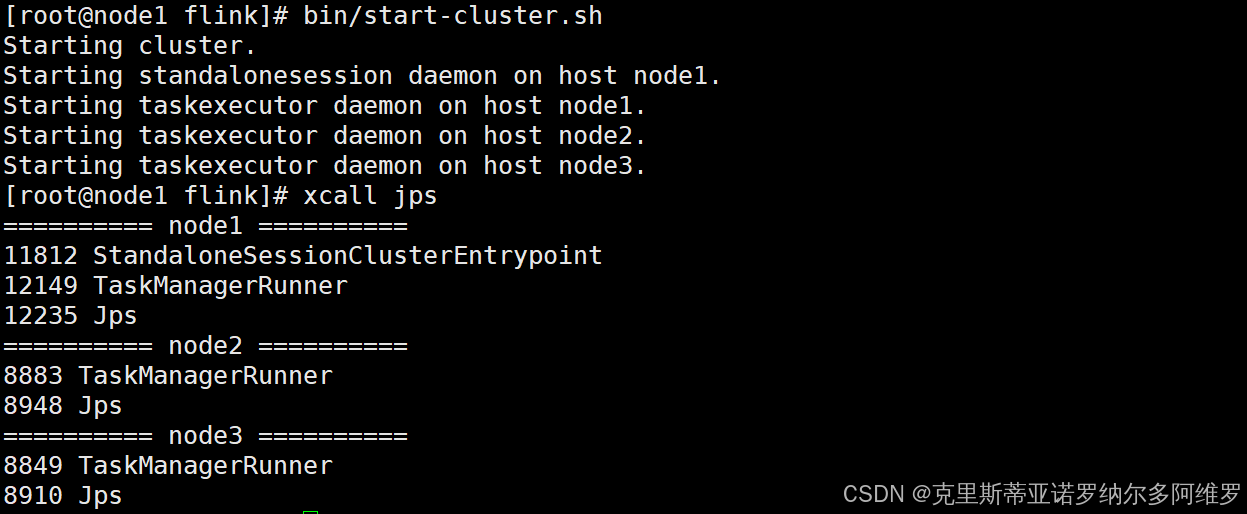
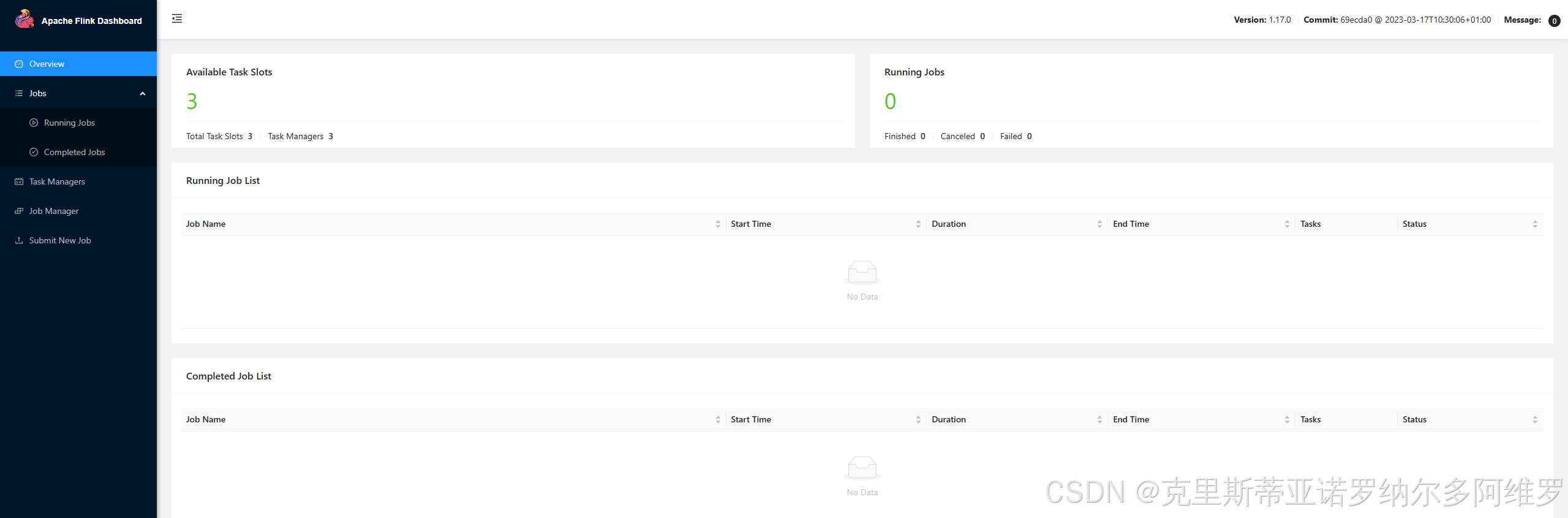
2.6 访问Web UI
启动成功后,同样可以访问http://node1:8081对flink集群和任务进行监控管理。
3. Web提交作业
在node1中执行以下命令启动netcat
nc -lk 7777我们需要一个读取socket发送的单词并统计单词的个数程序jar包。
新建Maven项目,pom文件中的依赖如下:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>核心代码如下:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流:node1表示发送端主机名、7777表示端口号
DataStreamSource<String> lineStream = env.socketTextStream("node1", 7777);
// 3. 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(data -> data.f0)
.sum(1);
// 4. 打印
sum.print();
// 5. 执行
env.execute();
}
}
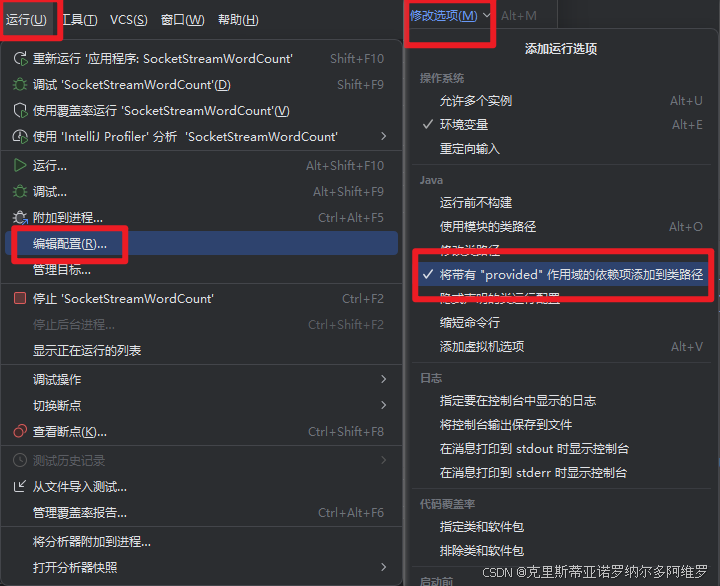
使用Maven先clean后package,打包后在WebUI上传该jar包,打包时需要注意勾选添加provided
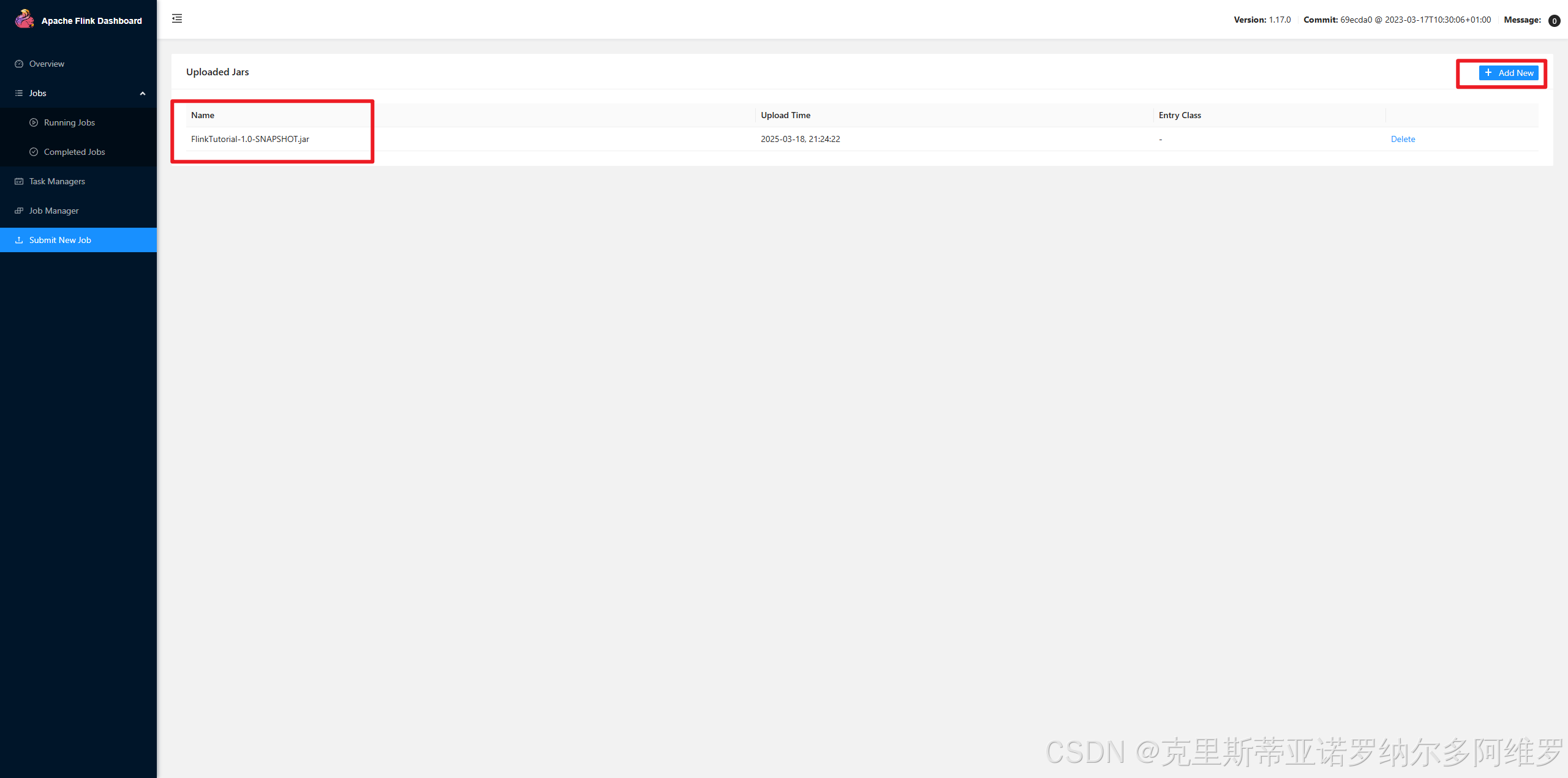
配置全类名后提交

在node1输入数据
[root@node1 ~]# nc -lk 7777
hello flink在WebUI查看结果
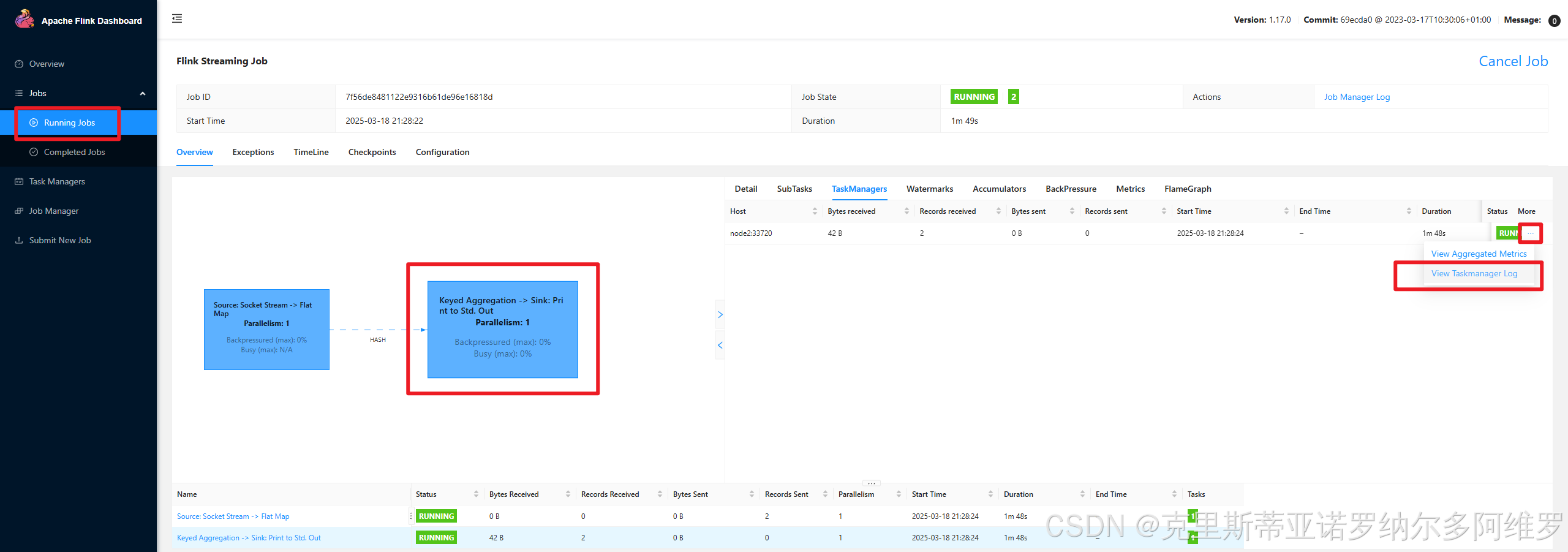

4. 命令行提交作业
- 将上面的jar包上传到/export/server/flink,执行命令提交作业
cd /export/server/flink
bin/flink run -m node1:8081 -c SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar然后用同样的方法在WebUI查看该作业
5. 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。
Flink为各种场景提供了不同的部署模式,主要有以下三种:
会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
5.1 会话模式
- 集群一直开着,可以跑多个作业。
- 资源大家一起用,谁提交作业谁用资源。
- 代码在客户端跑,提交作业到集群。
5.2 单作业模式
- 集群只跑一个作业,作业完就关。
- 资源只给这个作业用。
- 代码在客户端跑,提交作业后集群启动。
5.3 应用模式
- 集群跟着应用走,应用完就关。
- 资源只给应用用。
- 代码在集群里跑,直接在集群执行。
它们的区别主要在于:
集群的生命周期以及资源的分配方式;
以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
6. YARN运行模式部署
YARN上部署的过程是:
客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
请先部署好YARN,未部署可参考:
本地YARN集群部署![]() https://blog.csdn.net/m0_73641796/article/details/146051466?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_73641796/article/details/146051466?spm=1001.2014.3001.5501
6.1 配置环境变量
--在node1的环境变量中添加如下内容:
vim /etc/profile
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
source /etc/profile6.2 启动HDFS与YARN
su hadoop
start-dfs.sh
start-yarn.sh6.3 会话模式部署
su hadoop
bin/yarn-session.sh -nm test在node1:8088查看yarn任务
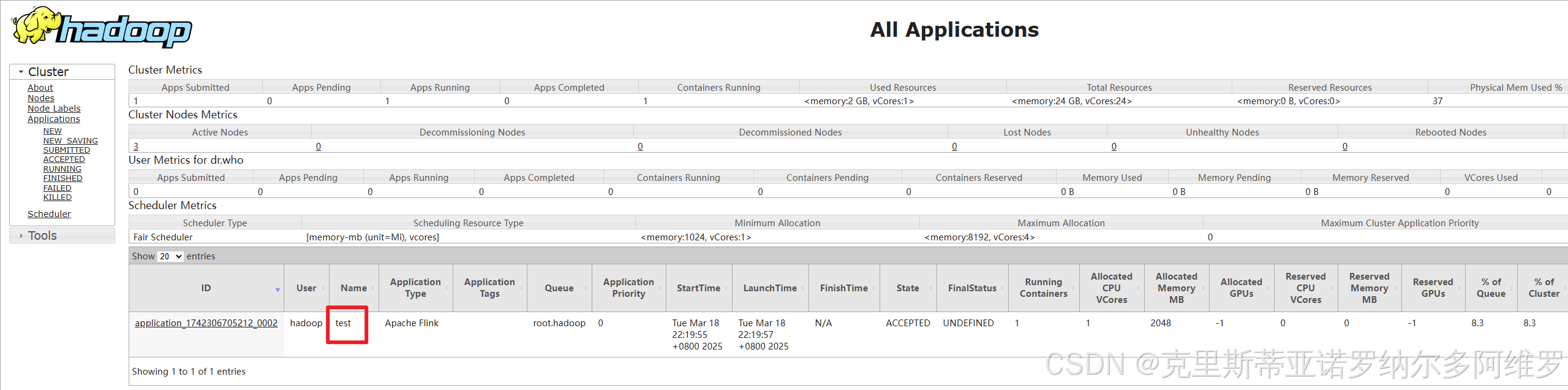
通过Applicationmaster代理跳转到Flink的WebUI

通过WebUI提交作业,具体流程可参考上面,提交后可见Yarn动态分配了1个Task Managers,将作业取消后又变为0个,被Yarn回收资源
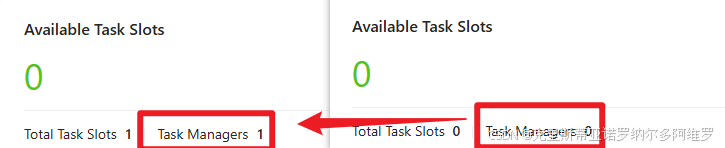
通过命令行提交作业,如果不指定-m参数,则自动提交到yarn上
6.4 单作业模式部署
bin/flink run -d -t yarn-per-job -c SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar注意:如果启动过程中报如下异常。
Exception in thread “Thread-5” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’
解决办法:在flink的/export/server/flink/conf/flink-conf.yaml配置文件中设置
classloader.check-leaked-classloader: false6.5 应用模式部署
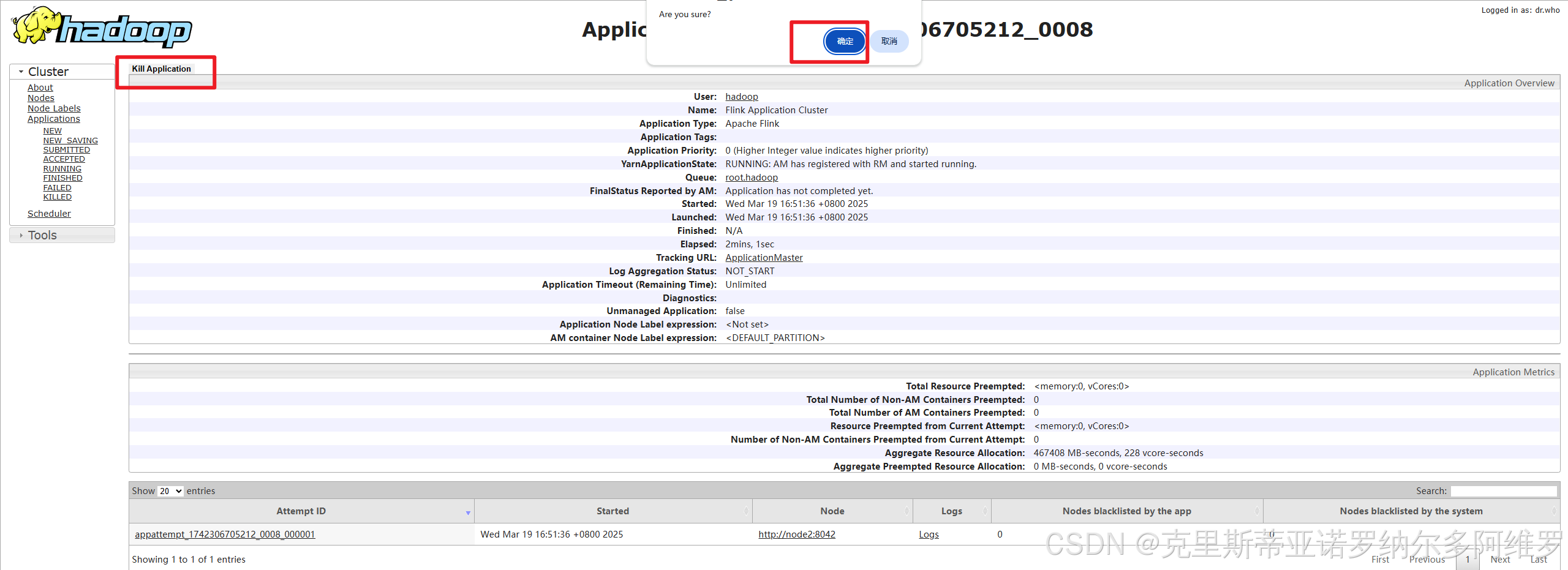
bin/flink run-application -t yarn-application -c SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar6.6 如何取消正在运行的作业
可直接在node1:8088,yarn的WebUI上直接取消
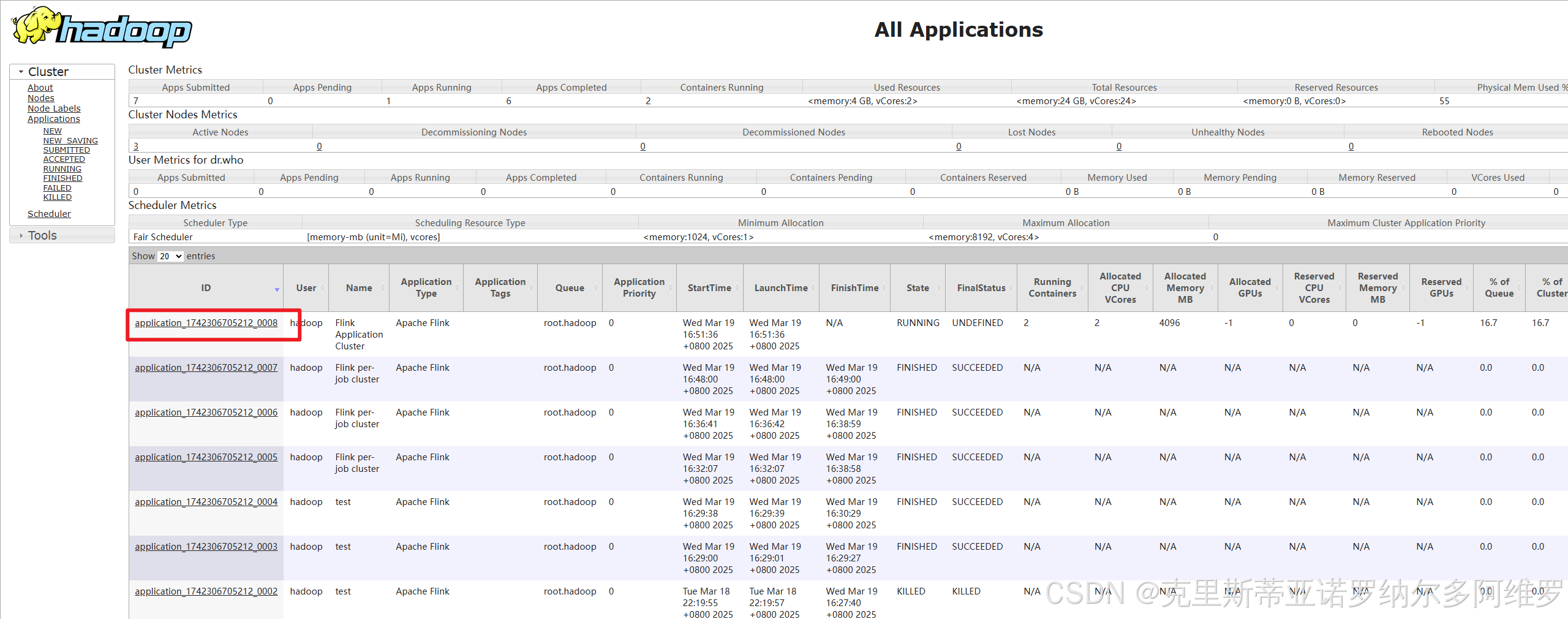
7. 历史服务器
hdfs dfs -mkdir -p /logs/flink-job
cd /export/server/flink/conf/flink-conf.yaml
vim flink-conf.yaml
--在 flink-config.yaml中添加如下配置
jobmanager.archive.fs.dir: hdfs://node1:8020/logs/flink-job
historyserver.web.address: node1
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://node1:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000
--启动历史服务器
bin/historyserver.sh start
--停止历史服务器
bin/historyserver.sh stop在浏览器地址栏输入:http://node1:8082 查看已经停止的 job 的统计信息