VLM理解(一)——视觉文本信息的标注与数据集制作过程
先来认识一下数据集结构及其制作过程。
https://github.com/PJLab-ADG/LeapAD/issues/3
https://github.com/OpenDriveLab/DriveLM
https://github.com/opendilab/LMDrive/issues/124
以上三篇中,DriveLM对于数据集的处理是最为清晰的,所以也按照它的格式来介绍视觉驾驶模型的标注。
特点
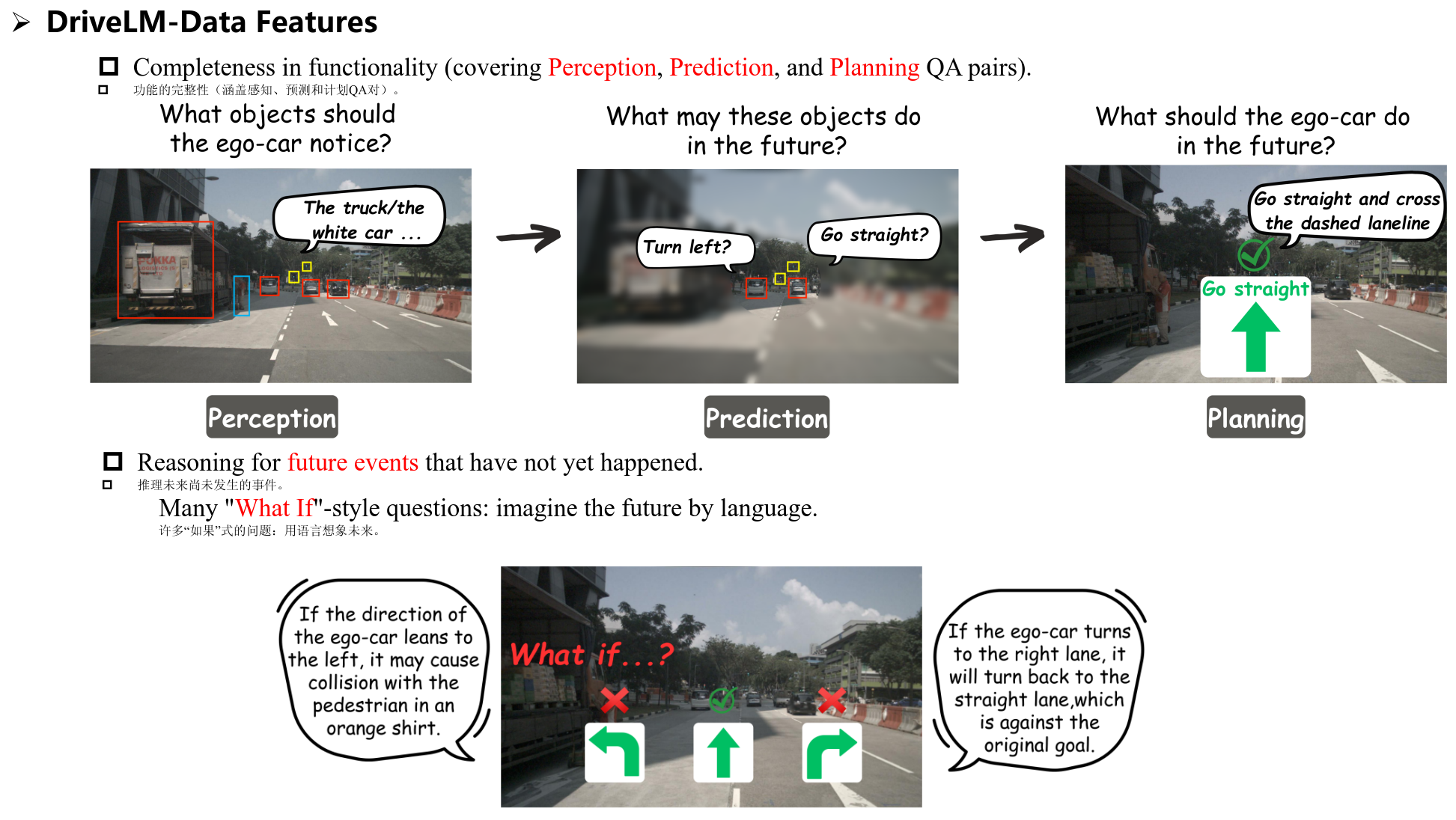
首先这个数据集涵盖了感知、预测和规划的三个部分,同时通过语言来推理未来可能发生的事件(用what if这样的语句)

最后一个特点是从场景级到帧级的QA对,一个场景包含了很多帧。
数据集制作
nuscenes数据集和carla的有所不同,对于nuscenes,主要包含三个步骤:

第一步,关键帧选择,选择的标准是对车辆运动状态的变化较大的作为关键帧。这里没有明说,但我觉得这个工作应该是人来完成的。
第二步,关键对象选择,从选择的关键帧中选出关键的目标,标准是要能够影响本车的动作的。
第三步,QA对设计。对于这些关键对象,自动生成一些关于感知预测和规划的问题。其格式:
v1_0_train_nus.json
├── scene_token:{
│ ├── "scene_description": "本车沿着当前道路行驶,准备在一系列连续右转后进入主路。",
│ ├── "key_frames":{
│ │ ├── "frame_token_1":{
│ │ │ ├── "key_object_infos":{"<c1,CAM_FRONT,258.3,442.5>": {"Category": "车辆", "Status": "行驶中", "Visual_description": "白色轿车", "2d_bbox": [x_min, y_min, x_max, y_max]}, ...},
│ │ │ ├── "QA":{
│ │ │ │ ├── "perception":[
│ │ │ │ │ ├── {"Q": "当前场景中有哪些重要物体?", "A": "重要物体包括 <c1,CAM_FRONT,258.3,442.5>, <c2,CAM_FRONT,1113.3,505.0>, ...", "C": None, "con_up": None, "con_down": None, "cluster": None, "layer": None},
│ │ │ │ │ ├── {"Q": "xxx", "A": "xxx", "C": None, "con_up": None, "con_down": None, "cluster": None, "layer": None}, ...
│ │ │ │ ├── ],
│ │ │ │ ├── "prediction":[
│ │ │ │ │ ├── {"Q": "<c1,CAM_FRONT,258.3,442.5> 的未来状态是什么?", "A": "轻微向左偏移以进行操控。", "C": None, "con_up": None, "con_down": None, "cluster": None, "layer": None}, ...
│ │ │ │ ├── ],
│ │ │ │ ├── "planning":[
│ │ │ │ │ ├── {"Q": "在这种情况下,本车可以采取哪些安全行动?", "A": "轻踩刹车停车,右转,左转。", "C": None, "con_up": None, "con_down": None, "cluster": None, "layer": None}, ...
│ │ │ │ ├── ],
│ │ │ │ ├── "behavior":[
│ │ │ │ │ ├── {"Q": "预测本车的行为。", "A": "本车正在直行。本车行驶速度较慢。", "C": None, "con_up": None, "con_down": None, "cluster": None, "layer": None}
│ │ │ │ ├── ]
│ │ │ ├── },
│ │ │ ├── "image_paths":{
│ │ │ │ ├── "CAM_FRONT": "xxx",
│ │ │ │ ├── "CAM_FRONT_LEFT": "xxx",
│ │ │ │ ├── "CAM_FRONT_RIGHT": "xxx",
│ │ │ │ ├── "CAM_BACK": "xxx",
│ │ │ │ ├── "CAM_BACK_LEFT": "xxx",
│ │ │ │ ├── "CAM_BACK_RIGHT": "xxx",
│ │ │ ├── }
│ │ ├── },
│ │ ├── "frame_token_2":{
│ │ │ ├── "key_object_infos":{"<c1,CAM_BACK,612.5,490.6>": {"Category": "交通元素", "Status": "无", "Visual_description": "停车标志", "2d_bbox": [x_min, y_min, x_max, y_max]}, ...},
│ │ │ ├── "QA":{
│ │ │ │ ├── "perception":[...],
│ │ │ │ ├── "prediction":[...],
│ │ │ │ ├── "planning":[...],
│ │ │ │ ├── "behavior":[...]
│ │ │ ├── },
│ │ │ ├── "image_paths":{...}
│ │ ├── }
│ ├── }
├── }
- scene_token与nuScenes数据集一致 scene_description是对约20秒视频片段中自车行为的总结
- key_frames下每个关键帧通过frame_token标识(对应nuScenes的token)
- key_object_infos映射c标签与物体信息,包含类别、状态、视觉描述和2D框
- QA按任务分类存储问答对,每个字典包含问题(Q)、答案(A)等字段,上下文相关键值当前为None
就应该比较明显了,关键帧,关键目标到QA问答,总体标注过程就比较清晰了。提供了数据集的下载链接,包含nuscenes的图片和DriveLM的json格式的文件。
| nuScenes subset images | DriveLM-nuScenes version-1.0 |
|---|---|
| Google Drive | Google Drive |
| Baidu Netdisk | Baidu Netdisk |
| HuggingFace | HuggingFace |
最后是carla中的数据集格式,

这个就是比较自动的标注方式了,不过有个限制,那就是要用他们的carla export来采集数据,然后在去处理关键帧并且自动嵌入QA对。切换到DriveLM的carla branch中:
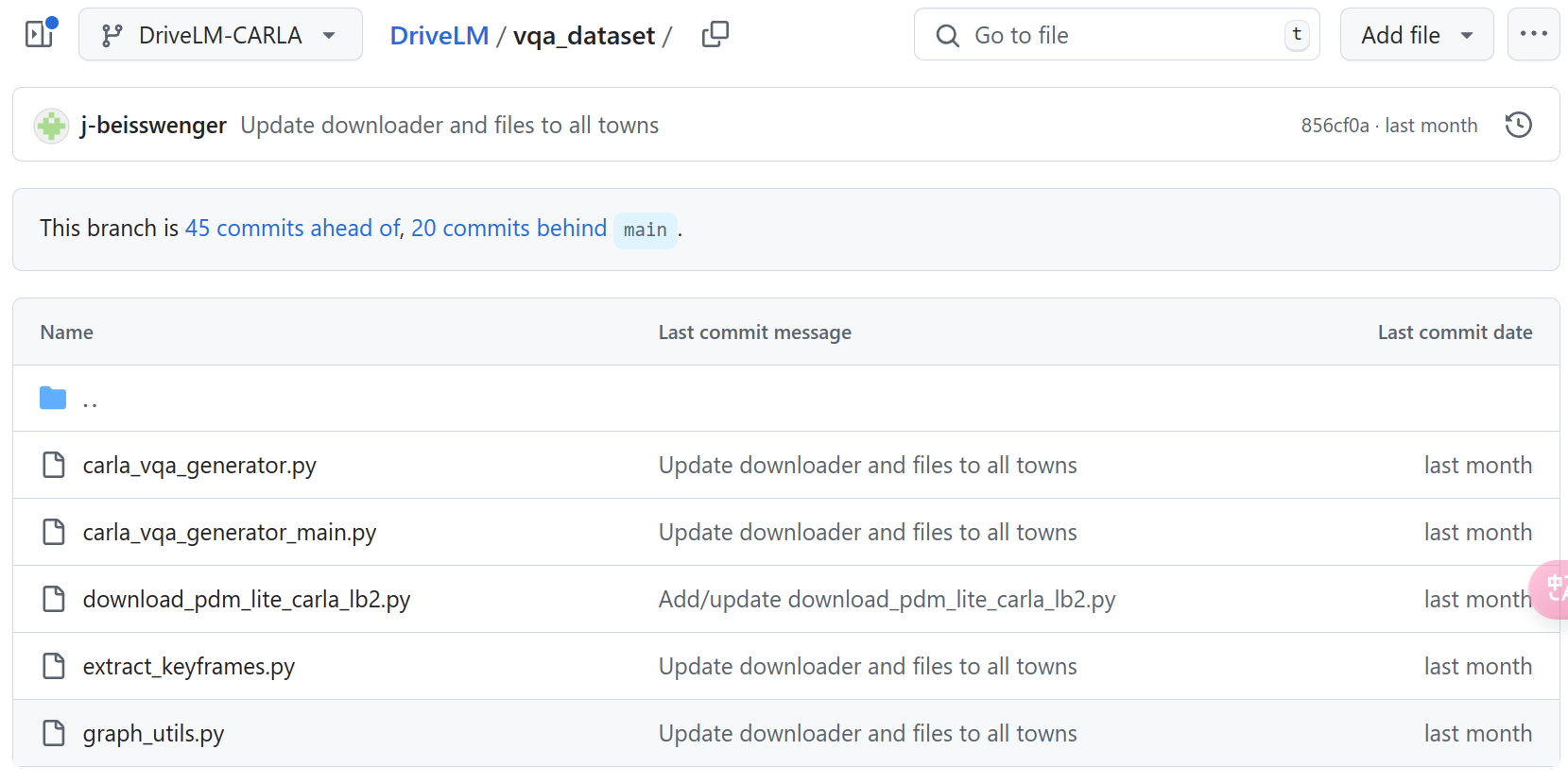
这里所涉及的py文件如上carla_vqa_generator.py和carla_vqa_generator_main.py是用来生成QA对的。然后download_pdm_lite_carla_lb2.py用来下载pdm_lite这个驾驶员。extract_keyframes.py解压关键帧,graph_utils.py是相关处理图像的工具。