Transformer-based 1-Dimensional Tokenizer (TiTok):一种革命性的1D图像分词方法(代码实现)
TiTok:一种革命性的1D图像分词方法
在图像生成领域,近年来基于变换器(Transformer)和扩散模型(Diffusion Model)的技术取得了显著进展。然而,生成高质量图像,尤其是高分辨率图像,仍然面临计算复杂度和效率的挑战。为了解决这些问题,图像分词(Image Tokenization)作为一种将原始像素转化为紧凑潜在表示的技术,成为了研究的热点。传统的图像分词方法,如VQ-VAE及其变种(如VQGAN),通常采用二维网格(2D Grid)的潜在表示方式。然而,这种方法在处理图像固有的冗余性时存在局限性,导致潜在表示的压缩效率和生成性能未能达到最优。
在这一背景下,ByteDance和慕尼黑工业大学的研究团队提出了一种全新的分词框架——Transformer-based 1-Dimensional Tokenizer (TiTok),它突破了传统2D分词的限制,将图像转化为一维(1D)离散潜在序列。这种方法不仅显著减少了潜在表示的token数量,还在图像重建和生成任务中展现出优异的性能。本文将为熟悉VQ-VAE的深度学习研究者详细介绍TiTok的核心思想、方法论及其实验结果。
下文中图片来自于原论文:https://arxiv.org/pdf/2406.07550
TiTok的核心思想
TiTok的设计灵感来源于图像理解任务(如分类、目标检测和分割)中对高层次特征的依赖。在这些任务中,模型通常将图像编码为一维序列,而无需保留二维空间结构。这种观察促使研究者提出一个关键问题:“图像分词真的需要二维结构吗?”传统VQ-VAE通过将图像分块并编码为二维潜在网格(例如256×256图像被编码为16×16的潜在表示,共256个token),保留了空间位置的直接映射。然而,这种方式限制了模型对图像冗余性的利用能力。
TiTok则完全抛弃了二维网格的约束,提出了一种基于Vision Transformer (ViT)的一维分词方法。它将图像编码为一个紧凑的1D离散token序列(例如仅32个token),并通过解码器将这些token重构回图像空间。这种方法的核心优势在于:
- 更高的压缩率:对于256×256×3的图像,TiTok可以将潜在表示压缩到仅32个token,相比传统方法的256或1024个token,减少了8到32倍。
- 灵活性:1D序列摆脱了固定网格的限制,每个token可以捕捉超越局部区域的全局信息,从而更好地利用图像的冗余性。
- 语义丰富性:实验表明,紧凑的1D潜在空间倾向于学习更高级别的语义特征,这对生成任务尤为有利。
TiTok的架构与工作流程
TiTok的架构继承了VQ-VAE的基本组件——编码器(Encoder)、量化器(Quantizer)和解码器(Decoder),但在实现上引入了创新的设计:
-
编码阶段:
- 输入图像被分割为一系列patch(例如16×16),并通过patch嵌入层展平为一维序列。
- 将这些patch与一组预定义数量的潜在token(例如32个)拼接在一起,输入到ViT编码器中。
- 编码器输出后,仅保留潜在token部分作为图像的1D潜在表示(记为( Z 1 D \mathbf{Z}_{1D} Z1D)),丢弃patch相关的输出。
-
量化阶段:
- 利用向量量化(Vector Quantization),将( Z 1 D \mathbf{Z}_{1D} Z1D)中的每个潜在token映射到可学习的码书(Codebook)中的最近邻离散码。
-
解码阶段:
- 将量化后的( Z 1 D \mathbf{Z}_{1D} Z1D)与一组掩码token(Mask Tokens)拼接,输入到ViT解码器中。
- 解码器基于这些token重建出原始图像。
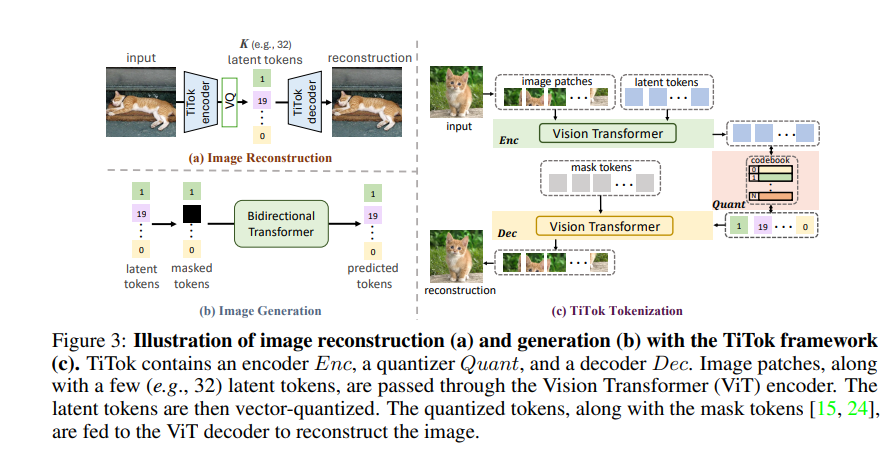
这种设计的关键在于,TiTok通过ViT的全局注意力机制,使得每个潜在token能够捕捉图像中的全局上下文,而非局限于某一固定区域。这种特性在紧凑潜在空间(例如32个token)下尤为重要,因为它允许模型在有限的表示能力中优先保留高层次信息。
两阶段训练策略
TiTok的训练过程采用了创新的两阶段策略,以提升性能并简化超参数调优:
-
第一阶段(Warm-up):
- 传统VQ-VAE训练通常需要复杂的损失函数(如感知损失、对抗损失)。TiTok则引入了“代理码”(Proxy Codes),即利用预训练的MaskGIT-VQGAN模型生成的离散码作为训练目标。
- 通过这种方式,TiTok避免了直接回归RGB值的复杂性,专注于优化1D分词的结构。
-
第二阶段(Decoder Fine-tuning):
- 在第一阶段完成后,固定编码器和量化器,仅对解码器进行微调,使其直接输出像素空间的重建结果。
- 这一阶段采用标准的VQGAN训练配方,进一步提升重建质量。
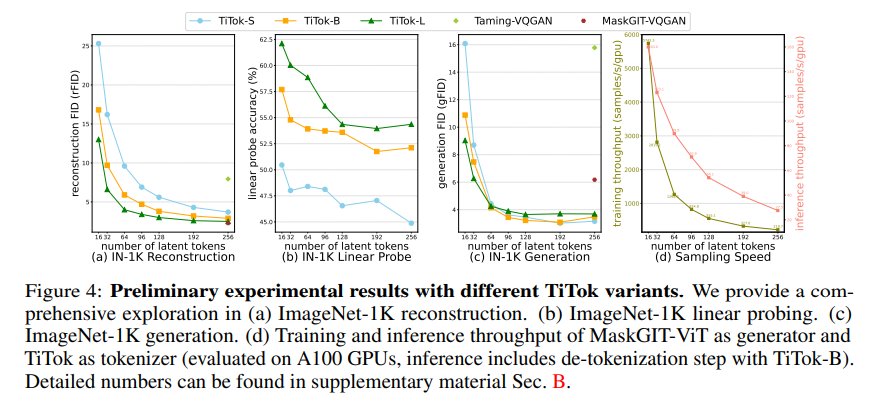
实验表明,这种两阶段训练显著提高了训练稳定性和图像质量。例如,在ImageNet 256×256基准上,TiTok-L-32的重建FID(rFID)从初始的6.59提升至2.21。
实验结果与亮点
TiTok在ImageNet生成基准上的表现令人瞩目。以下是一些关键实验结果:
-
重建能力:
- TiTok-L-32(32个token)在256×256分辨率下实现rFID 2.21,与MaskGIT-VQGAN(256个token,rFID 2.28)相当,但潜在表示减少了8倍。
- 在512×512分辨率下,TiTok-L-64(64个token)实现rFID 1.77,相比MaskGIT-VQGAN(1024个token,rFID 1.97)仍保持高压缩率。
-
生成性能:
- 在256×256分辨率下,TiTok-S-128结合MaskGIT框架实现了gFID 1.97,优于最先进的扩散模型DiT-XL/2(gFID 2.27),同时生成速度提升13倍。
- 在512×512分辨率下,TiTok-B-128达到gFID 2.13,超越DiT-XL/2(gFID 3.04),生成速度提升74倍,最高可达410倍(TiTok-L-64)。
-
效率提升:
- TiTok-L-32在A100 GPU上的采样速度达到101.6样本/秒,相比DiT-XL/2(0.6样本/秒)快了169倍。
- 训练吞吐量也显著提升,例如使用32个token时,训练速度比256个token快12.8倍。
-
潜在空间分析:
- 实验表明,32个token足以实现合理重建,进一步增加token数量(例如到128)后收益递减。
- 更大的模型(如TiTok-L)能在更紧凑的潜在空间中保持性能,显示出扩展模型规模的潜力。
与VQ-VAE的对比
对于熟悉VQ-VAE的研究者,以下是TiTok与传统方法的几点关键差异:
- 潜在表示:VQ-VAE采用2D网格,TiTok采用1D序列,压缩率更高且更灵活。
- 信息捕捉:2D分词受限于局部patch,TiTok通过全局注意力机制捕捉更丰富的语义信息。
- 训练复杂度:TiTok通过代理码简化了训练,避免了复杂的损失函数设计。
- 生成效率:TiTok在生成任务中结合MaskGIT显著加速了采样过程,而传统VQ-VAE常需数百步自回归采样。
未来方向与启发
TiTok的研究为图像分词开辟了新的可能性。它表明,1D分词不仅可行,而且在效率和性能上具有显著优势。未来,研究者可以探索以下方向:
- 将TiTok应用于更大规模数据集(如LAION-5B)以进一步提升性能。
- 结合更先进的量化策略(如MAGVIT-v2的查找无关量化)优化潜在表示。
- 扩展TiTok到视频生成或多模态任务中,验证其通用性。
总的来说,TiTok不仅是对VQ-VAE的一次革新,也是对图像生成领域效率提升的重要贡献。对于希望在生成模型中追求更高压缩率和更快生成速度的研究者来说,TiTok无疑是一个值得深入探索的工具。
参考资料:
Yu, Qihang, et al. “An Image is Worth 32 Tokens for Reconstruction and Generation.” Preprint, 2024.
项目主页:https://yucornetto.github.io/projects/titok.html
二维潜在网格(2D Latent Grid)是什么
“二维结构”指的是传统VQ-VAE(Vector Quantized Variational Autoencoder)在图像分词(Image Tokenization)过程中将图像编码为一个二维潜在网格(2D Latent Grid)的表示方式。
“二维结构”指的是什么?
在传统VQ-VAE中,图像分词的目标是将高维的图像像素数据(例如256×256×3的RGB图像)压缩为一个更紧凑的潜在表示(Latent Representation),以便后续用于重建或生成任务。具体来说:
-
分块与编码:
- 输入图像首先被分割为多个小块(Patch),例如将256×256的图像按16×16的patch大小分割,得到16×16=256个patch。
- 每个patch通过编码器(Encoder,通常是卷积神经网络CNN)被映射为一个固定维度的嵌入向量(Embedding Vector),例如一个D维向量(D通常是几十到几百)。
- 这些嵌入向量构成了一个二维网格 ( Z 2 D ∈ R H / f × W / f × D \mathbf{Z}_{2D} \in \mathbb{R}^{H/f \times W/f \times D} Z2D∈RH/f×W/f×D),其中 (H) 和 (W) 是图像的高度和宽度,( f f f) 是下采样因子(例如 (f=16),则网格为16×16)。
-
量化与码书:
- 编码器输出的每个嵌入向量(( z ∈ R D \mathbf{z} \in \mathbb{R}^D z∈RD))会通过向量量化(Vector Quantization)映射到码书(Codebook)中的一个离散码(Code),码书是一个 ( C ∈ R N × D \mathbb{C} \in \mathbb{R}^{N \times D} C∈RN×D) 的矩阵,包含 ( N N N) 个可能的离散码。
- 量化后的结果是一个二维网格,其中每个位置对应一个码书的索引(Index),而不是直接存储嵌入向量本身。例如,对于256×256图像,量化后得到一个16×16的索引网格(共256个token),每个索引指向码书中的某个码。
-
二维网格的含义:
- 这个“二维结构”指的是量化后的潜在表示保留了图像的空间布局:网格中的每个token(量化后的码索引)与原始图像中的一个特定patch位置一一对应。例如,网格左上角的token对应图像左上角的patch,右下角的token对应右下角的patch。
- 这里说的“二维”并不是指码书本身(码书是一个 ( N × D N \times D N×D) 的矩阵,逻辑上是一维列表),而是指潜在表示的空间组织形式是一个二维矩阵(例如16×16)。
因此,二维结构指的是编码器输出的嵌入向量(或量化后的码索引)按照图像的空间位置排列成一个二维矩阵,而不是码书本身的结构。
传统二维结构的细节举例
以一个256×256×3的图像为例:
- 分块:分成16×16的patch,共256个patch。
- 编码:每个patch被编码为一个D维向量(假设D=512),得到一个16×16×512的张量。
- 量化:每个D维向量映射到码书中的一个码,码书大小为 ( N = 1024 N=1024 N=1024)(即有1024个可能的码),最终得到一个16×16的索引矩阵,每个元素是一个0到1023之间的整数。
- 解码:解码器(Decoder,通常也是CNN)从这个16×16的索引矩阵(通过码书查表还原为16×16×512的张量)重建出256×256×3的图像。
这种二维网格保留了图像的空间结构,确保解码时每个token都能直接映射回对应的图像区域。
二维结构的问题
尽管二维结构在一定程度上简化了图像分词的设计,但TiTok的论文指出它存在以下几个关键问题:
-
冗余性利用不足:
- 图像中相邻区域往往具有高度相似性(例如一片蓝天或一片草地),但二维网格强制每个patch独立编码为一个token,无法有效合并这些冗余信息。
- 例如,即使相邻的16×16 patch几乎相同,传统VQ-VAE仍会为它们分配不同的token,导致潜在表示中包含大量重复信息,压缩效率不高。
-
固定映射的限制:
- 二维网格假设每个token与固定图像区域一一对应,这种严格的空间约束限制了模型的灵活性。每个token只能捕捉局部信息(例如16×16的patch),无法直接感知全局上下文。
- 这意味着潜在表示的token数量与图像分辨率强相关(例如256×256图像通常需要256个token,512×512需要1024个token),无法自由调整压缩率。
-
效率瓶颈:
- 在生成任务中(如结合自回归模型或MaskGIT),token数量直接影响计算成本。二维网格通常需要数百到上千个token,导致训练和推理速度较慢。例如,自回归生成需要逐一预测256个token,计算开销巨大。
-
语义表达能力有限:
- 二维网格的token主要捕捉低层次的局部特征(例如颜色、纹理),而难以直接编码更高层次的语义信息(例如物体的整体形状或类别)。这在生成高质量图像时可能导致细节丰富但整体一致性不足。
TiTok如何解决这些问题?
TiTok通过将潜在表示从二维网格改为1D序列,解决了上述问题:
- 全局信息捕捉:使用Vision Transformer (ViT) 编码器,通过注意力机制让每个token感知整个图像,而不是局限于局部patch。
- 高压缩率:将256×256图像压缩到仅32个token,利用图像冗余性大幅减少token数量。
- 灵活性:1D序列的token数量可以自由调整(例如16、32、64),不受图像分辨率的严格约束。
- 语义丰富性:实验表明,紧凑的1D潜在空间倾向于学习更高级别的语义特征,提升生成性能。
例如,TiTok的编码过程是将图像patch与少量潜在token(例如32个)拼接后输入ViT,输出时仅保留这些潜在token作为表示。这种方法打破了二维网格的空间约束,使得每个token可以代表更大的图像区域甚至全局信息,从而在更少的token下实现高质量重建和生成。
总结
在传统VQ-VAE中,“二维结构”指的是潜在表示被组织为一个二维网格(例如16×16的索引矩阵),每个token对应图像的一个固定patch区域。这种设计保留了空间位置的直接映射,但限制了冗余性利用、灵活性和效率。TiTok通过引入1D分词,跳出二维网格的束缚,不仅大幅提升了压缩率(32个token即可表示一张图像),还在生成任务中实现了更快的速度和更优的性能。对于熟悉VQ-VAE的研究者来说,TiTok的核心创新在于用全局感知的1D序列替代局部约束的2D网格,这一转变值得深入思考和探索。
示例性的训练和测试代码
下面将为TiTok提供示例性的训练和测试代码,基于PyTorch框架,并结合论文中的描述进行详细解释。根据论文的核心思想和常用实践(如VQ-VAE和Vision Transformer)提供一个合理的实现框架,并假设一些细节。代码将包括训练和测试两个部分,面向熟悉VQ-VAE的深度学习研究者。
TiTok的核心组件
根据论文,TiTok包括:
- 编码器(Encoder):Vision Transformer (ViT),将图像patch和潜在token编码为1D序列。
- 量化器(Quantizer):基于向量量化(VQ),将编码器的输出映射到离散码书。
- 解码器(Decoder):另一个ViT,将量化后的1D序列和掩码token解码为图像。
- 两阶段训练:
- 第一阶段(Warm-up):使用代理码(Proxy Codes)训练。
- 第二阶段(Decoder Fine-tuning):微调解码器以直接输出RGB图像。
我将假设图像分辨率为256×256,patch大小为16×16,潜在token数量为32,码书大小为4096。
训练代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import timm # 用于加载预训练ViT模型
# 1. 定义TiTok模型
class TiTok(nn.Module):
def __init__(self, img_size=256, patch_size=16, num_tokens=32, codebook_size=4096, embed_dim=512):
super(TiTok, self).__init__()
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2 # 256 / 16 = 16, 16x16 = 256 patches
self.num_tokens = num_tokens
self.embed_dim = embed_dim
self.codebook_size = codebook_size
# 编码器: ViT (假设使用ViT-Base)
self.encoder = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=0)
self.encoder.patch_embed.proj = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
# 潜在token初始化
self.latent_tokens = nn.Parameter(torch.randn(1, num_tokens, embed_dim))
# 码书
self.codebook = nn.Parameter(torch.randn(codebook_size, embed_dim))
# 解码器: 另一个ViT
self.decoder = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=0)
self.decoder.patch_embed.proj = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
self.decoder_head = nn.Linear(embed_dim, patch_size * patch_size * 3) # 输出patch像素
# 掩码token
self.mask_token = nn.Parameter(torch.randn(1, 1, embed_dim))
def quantize(self, z):
# 向量量化:找到最近的码书向量
z_flat = z.reshape(-1, self.embed_dim) # [B*num_tokens, embed_dim]
distances = torch.cdist(z_flat, self.codebook) # [B*num_tokens, codebook_size]
indices = torch.argmin(distances, dim=1) # [B*num_tokens]
z_q = self.codebook[indices].reshape(z.shape) # [B, num_tokens, embed_dim]
return z_q, indices
def forward(self, x, stage='warmup'):
B = x.shape[0] # Batch size
# 编码阶段
patches = self.encoder.patch_embed(x) # [B, num_patches, embed_dim]
latent_tokens = self.latent_tokens.expand(B, -1, -1) # [B, num_tokens, embed_dim]
encoder_input = torch.cat([patches, latent_tokens], dim=1) # [B, num_patches + num_tokens, embed_dim]
encoder_output = self.encoder.forward_features(encoder_input) # 通过ViT
z = encoder_output[:, self.num_patches:] # 只保留潜在token部分 [B, num_tokens, embed_dim]
# 量化
z_q, indices = self.quantize(z)
# 解码阶段
mask_tokens = self.mask_token.expand(B, self.num_patches, -1) # [B, num_patches, embed_dim]
decoder_input = torch.cat([z_q, mask_tokens], dim=1) # [B, num_tokens + num_patches, embed_dim]
decoder_output = self.decoder.forward_features(decoder_input) # 通过解码器ViT
recon_patches = self.decoder_head(decoder_output[:, self.num_tokens:]) # [B, num_patches, patch_size*patch_size*3]
recon_img = recon_patches.view(B, img_size // patch_size, img_size // patch_size, patch_size, patch_size, 3)
recon_img = recon_img.permute(0, 1, 3, 2, 4, 5).reshape(B, 3, img_size, img_size)
return recon_img, z, z_q, indices
# 2. 损失函数
def vq_loss(z, z_q):
commitment_loss = torch.mean((z.detach() - z_q) ** 2) # 使码书接近编码器输出
codebook_loss = torch.mean((z - z_q.detach()) ** 2) # 使编码器输出接近码书
return commitment_loss + codebook_loss
# 3. 训练函数
def train_titok(model, train_loader, proxy_loader, epochs, stage='warmup', device='cuda'):
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (images, _) in enumerate(train_loader):
images = images.to(device)
optimizer.zero_grad()
recon_img, z, z_q, _ = model(images, stage=stage)
# 重建损失
recon_loss = nn.MSELoss()(recon_img, images)
# VQ损失
vq_loss_term = vq_loss(z, z_q)
# 第一阶段使用代理码(假设proxy_loader提供预训练VQGAN的码)
if stage == 'warmup':
proxy_codes = next(iter(proxy_loader))[0].to(device) # 假设proxy_codes为预计算的索引
loss = vq_loss_term + nn.CrossEntropyLoss()(model.quantize(z)[1], proxy_codes)
else: # 第二阶段直接优化RGB重建
loss = recon_loss + 0.25 * vq_loss_term
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step()
print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(train_loader):.4f}")
# 4. 数据加载
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.ImageNet(root='path_to_imagenet', split='train', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True, num_workers=4)
# 假设有一个预训练VQGAN提供代理码(这里简化为随机数据)
proxy_dataset = torch.randint(0, 4096, (len(train_dataset), 32)) # 32 tokens
proxy_loader = DataLoader(proxy_dataset, batch_size=256, shuffle=True)
# 5. 训练模型
model = TiTok()
train_titok(model, train_loader, proxy_loader, epochs=100, stage='warmup') # 第一阶段
train_titok(model, train_loader, proxy_loader, epochs=50, stage='finetune') # 第二阶段
测试代码
def test_titok(model, test_loader, device='cuda'):
model.eval()
total_recon_loss = 0
with torch.no_grad():
for images, _ in test_loader:
images = images.to(device)
recon_img, _, _, _ = model(images, stage='finetune')
recon_loss = nn.MSELoss()(recon_img, images)
total_recon_loss += recon_loss.item()
avg_recon_loss = total_recon_loss / len(test_loader)
print(f"Test Reconstruction Loss: {avg_recon_loss:.4f}")
# 可视化示例
import matplotlib.pyplot as plt
sample_img = images[0].cpu()
sample_recon = recon_img[0].cpu()
plt.subplot(1, 2, 1)
plt.imshow(sample_img.permute(1, 2, 0).numpy() * 0.5 + 0.5)
plt.title("Original")
plt.subplot(1, 2, 2)
plt.imshow(sample_recon.permute(1, 2, 0).numpy() * 0.5 + 0.5)
plt.title("Reconstructed")
plt.show()
# 测试数据
test_dataset = datasets.ImageNet(root='path_to_imagenet', split='val', transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=4)
# 测试模型
test_titok(model, test_loader)
代码详细解释
1. 模型定义(TiTok 类)
-
编码器:
- 使用
timm库加载ViT-Base模型,修改其patch嵌入层以适应256×256输入和16×16 patch大小。 - 输入图像被分为256个patch(16×16网格),每个patch编码为512维向量。
- 添加32个可学习的潜在token,与patch拼接后输入ViT,输出中仅保留潜在token部分([B, 32, 512])。
- 使用
-
量化器:
quantize函数实现向量量化,通过计算编码器输出与码书之间的欧氏距离,找到最近的码。- 码书大小为4096,每个码是512维向量。
-
解码器:
- 另一个ViT接收量化后的32个token和256个掩码token(模拟patch数量)。
- 输出通过线性层转换为patch像素(16×16×3),然后重组成完整图像。
2. 损失函数
- 重建损失:MSE用于比较重建图像与原始图像。
- VQ损失:包括
commitment_loss(使码书接近编码器输出)和codebook_loss(使编码器输出接近码书),这是VQ-VAE的标准实践。 - 代理码损失:第一阶段使用交叉熵损失,假设代理码是预训练VQGAN提供的离散索引。
3. 训练过程
- 两阶段训练:
- Warm-up:使用代理码训练,优化编码器和量化器,损失包括VQ损失和代理码预测。
- Fine-tuning:固定编码器和量化器,优化解码器以直接输出RGB图像,损失以重建为主。
如果你的目标是实验性地跑通TiTok并观察效果,这里的代码(没有实现固定一部分,优化另一部分)可以用作初步尝试。但如果你希望严格复现TiTok的训练过程并追求论文中的性能,建议使用改进后的代码。见下文。
- 优化器:AdamW + 余弦退火学习率,符合论文中的描述。
4. 数据加载
- 使用ImageNet数据集,图像预处理为256×256并归一化。
- 代理码数据这里简化为随机生成,实际应从预训练VQGAN获取。
5. 测试过程
- 计算测试集上的平均重建损失。
- 可视化示例图像及其重建结果,直观评估模型性能。
注意事项
- 依赖项:需要安装
torch,torchvision,timm, 和matplotlib。 - 代理码:论文提到使用MaskGIT-VQGAN的码,实际实现需预训练一个VQGAN并提取其输出。
- 计算资源:训练需要GPU支持,论文中提到使用A100,代码需根据硬件调整batch size。
- 超参数:如patch大小、token数量、码书大小等可根据实验需求调整。
这个实现提供了一个TiTok的基础框架,研究者可以基于此进一步优化,例如添加感知损失、调整ViT结构,或结合MaskGIT进行生成任务。希望这对你理解TiTok的实现有所帮助!
保留潜在部分代码解释
背景:ViT的工作机制
Vision Transformer (ViT) 是一种基于注意力机制(Self-Attention)的模型,最初用于图像分类任务,但在这里被TiTok改造用于图像分词。ViT的基本工作流程是:
- 输入分块:将图像分割为多个patch(例如16×16),通过卷积层将每个patch嵌入为一个固定维度的向量(例如512维)。
- 位置编码:为每个patch的嵌入向量添加位置信息(Positional Embedding),以保留空间顺序。
- Transformer处理:将所有patch嵌入(加上位置编码)作为一个序列输入到Transformer块中,通过多头自注意力(Multi-Head Self-Attention)和前馈网络(Feed-Forward Network)处理。
- 输出:Transformer输出与输入序列长度相同的表示,每个输出向量是输入序列中对应位置的上下文增强版本。
在标准的ViT中,为了分类任务,会额外添加一个[CLS] token,它的输出用于预测类别。但TiTok的目标不是分类,而是生成紧凑的图像潜在表示,因此它对ViT的使用方式有所创新。
TiTok中编码器的设计
在TiTok的编码阶段,代码中有以下关键步骤:
patches = self.encoder.patch_embed(x) # [B, num_patches, embed_dim]
latent_tokens = self.latent_tokens.expand(B, -1, -1) # [B, num_tokens, embed_dim]
encoder_input = torch.cat([patches, latent_tokens], dim=1) # [B, num_patches + num_tokens, embed_dim]
encoder_output = self.encoder.forward_features(encoder_input) # 通过ViT
z = encoder_output[:, self.num_patches:] # 只保留潜在token部分 [B, num_tokens, embed_dim]
1. 输入的构造
patches:输入图像(例如256×256×3)通过patch_embed层被分割为256个patch(16×16网格),每个patch嵌入为512维向量,形状为[B, 256, 512]。latent_tokens:32个可学习的潜在token(self.latent_tokens是[1, 32, 512]的参数),通过expand扩展到每个batch,形状为[B, 32, 512]。encoder_input:将patch嵌入和潜在token沿着序列维度拼接,得到[B, 256 + 32, 512],即[B, 288, 512]。这意味着输入到ViT的是一个包含288个token的序列,前256个是图像patch,后32个是潜在token。
2. ViT的处理(forward_features)
forward_features是timm库中ViT模型的一个方法,它跳过了分类头(head),只执行Transformer的核心计算:- 为输入序列添加位置编码(Positional Embedding),形状仍为
[B, 288, 512]。 - 通过多层Transformer块(例如ViT-Base有12层),每个块包含多头自注意力(MSA)和前馈网络(FFN)。
- 自注意力机制会让每个token与其他所有token交互,更新其表示。因此,输出的
encoder_output仍然是[B, 288, 512],但每个token的表示已经融合了整个序列的上下文信息。
- 为输入序列添加位置编码(Positional Embedding),形状仍为
关键点在于:ViT的输出顺序与输入顺序一致。输入是 [patches, latent_tokens],输出也是 [transformed_patches, transformed_latent_tokens],只是每个token的内容已经被全局注意力机制更新。
3. 仅保留潜在token部分(z = encoder_output[:, self.num_patches:])
encoder_output的形状是[B, 288, 512],前256个token(self.num_patches)对应输入的patch,后32个token(self.num_tokens)对应输入的潜在token。z = encoder_output[:, 256:]提取后32个token,形状为[B, 32, 512]。这部分就是TiTok设计中用来表示整个图像的紧凑潜在表示。
为什么仅保留潜在token部分是合理的?
TiTok的核心创新在于用少量的潜在token(32个)代替传统的二维网格(例如256个token)来表示图像。保留潜在token部分的合理性来源于以下几点:
-
全局上下文捕捉:
- 在ViT中,自注意力机制使得每个输出token都是输入序列所有token的加权组合。因此,尽管输入的前256个token是图像patch,后32个潜在token在经过ViT后,已经融合了整个图像的信息。
- 这32个token不再是孤立的初始值,而是通过与256个patch的交互,学到了图像的高层次特征和全局上下文。
-
设计意图:
- TiTok的目标是生成一个紧凑的1D潜在表示(例如32个token),而不是保留所有patch的表示。论文中明确提到:“在编码器输出中,我们只保留潜在token作为图像的潜在表示”(“we only retain the latent tokens as the image’s latent representation”)。
- 相比传统VQ-VAE直接使用所有patch的二维网格(256个token),TiTok假设32个潜在token足以捕捉图像的关键信息,利用图像的冗余性实现更高压缩率。
-
可学习性:
latent_tokens是模型的可训练参数(nn.Parameter),在训练过程中会根据损失函数(如重建损失或代理码损失)调整,使其逐渐成为图像的有效表示。- 初始时,这些token可能是随机值,但经过训练,它们会专门负责编码图像的全局特征,而patch部分只是辅助提供原始信息。
经过ViT后,后32个还是“潜在token”吗?
严格来说,经过ViT处理后的后32个token不再是输入时的原始latent_tokens,而是它们的变换版本:
- 输入时:
latent_tokens是[B, 32, 512]的可学习参数,初始值随机,拼接在patch后。 - 输出时:
encoder_output[:, 256:]是[B, 32, 512],每个token的值已经被ViT的注意力机制和前馈网络更新,融合了整个图像(256个patch + 32个初始token)的信息。
从逻辑上看,这些输出token仍然是“潜在token”,因为它们继承了输入中潜在token的位置,并且被设计为图像的最终潜在表示。它们的内容发生了变化,但角色没有变:它们依然是TiTok用来压缩图像信息的载体。
如何保证这些token代表图像?
TiTok通过以下机制保证这32个token能有效代表图像:
-
训练监督:
- 在第一阶段(Warm-up),模型使用代理码(预训练VQGAN的离散码)监督这32个token的量化结果,确保它们能匹配已知的图像表示。
- 在第二阶段(Fine-tuning),通过重建损失(MSE)优化解码器,使这32个token足以重建原始图像。
-
注意力机制的强大能力:
- ViT的自注意力允许每个潜在token关注所有patch,因此即使只有32个token,它们也能捕捉图像的全局结构和语义信息。
- 实验表明(论文Fig. 4),32个token已足够实现合理重建,说明这种设计确实有效。
- 对比传统方法:
- 传统VQ-VAE保留所有patch的二维网格(256个token),每个token只负责局部区域。TiTok用32个全局感知的token替代,依赖ViT的建模能力压缩冗余信息。
代码中的实现细节
self.encoder.forward_features(encoder_input):- 调用ViT的核心Transformer部分,输出
[B, 288, 512]。 timm的forward_features不包括分类头,确保输出是完整的token序列。
- 调用ViT的核心Transformer部分,输出
z = encoder_output[:, self.num_patches:]:- 通过切片提取后32个token,丢弃前256个patch的输出,符合TiTok的紧凑表示设计。
总结
- 为什么只保留潜在token部分? 因为TiTok的目标是用少量token(32个)表示整个图像,ViT的全局注意力机制保证这些token能融合所有patch的信息。
- 经过ViT后还是潜在token吗? 是的,虽然内容被更新,但它们的位置和角色不变,仍然是设计中用于表示图像的潜在token。
- 如何保证有效性? 通过训练(代理码监督 + 重建损失)和ViT的强大建模能力,这32个token学会了捕捉图像的关键特征。
这种设计跳出了传统二维网格的限制,利用ViT的全局感知能力实现了高效的1D分词,是TiTok的核心创新点。希望这个解释能解答你的疑惑!如果还有疑问,欢迎继续讨论。
两阶段训练策略在代码中的具体实现
聚焦于TiTok的两阶段训练策略在代码中的具体实现,特别是如何体现“固定编码器和量化器,仅对解码器进行微调”,以及损失函数(loss)如何反映这一过程。会详细解释代码中对应的实现,并结合论文的设计理念说明每一部分的逻辑。
TiTok两阶段训练的背景
TiTok的训练分为两个阶段:
- 第一阶段(Warm-up):
- 使用“代理码”(Proxy Codes)作为监督信号,这些代理码来自预训练的MaskGIT-VQGAN模型的离散码(即量化后的token索引)。
- 目标是训练整个模型(编码器、量化器和解码器),但重点是优化1D分词结构,避免复杂的RGB重建损失(如感知损失或对抗损失)。
- 第二阶段(Decoder Fine-tuning):
- 固定编码器和量化器,仅微调解码器,使其从量化后的token直接重建RGB图像。
- 使用标准VQGAN的训练配方(主要是像素级MSE损失 + VQ损失的加权项),提升重建质量。
在代码中,这两个阶段通过stage参数区分,并在优化器和损失计算中体现固定哪些部分的参数。
代码中的实现
以下是训练代码的关键部分,会逐步解释如何体现两阶段训练,尤其是第二阶段的“固定编码器和量化器,仅对解码器微调”。
完整训练代码(带注释)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import timm
# TiTok模型定义(参考前述代码)
class TiTok(nn.Module):
def __init__(self, img_size=256, patch_size=16, num_tokens=32, codebook_size=4096, embed_dim=512):
super(TiTok, self).__init__()
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
self.num_tokens = num_tokens
self.embed_dim = embed_dim
self.codebook_size = codebook_size
self.encoder = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=0)
self.encoder.patch_embed.proj = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
self.latent_tokens = nn.Parameter(torch.randn(1, num_tokens, embed_dim))
self.codebook = nn.Parameter(torch.randn(codebook_size, embed_dim))
self.decoder = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=0)
self.decoder.patch_embed.proj = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
self.decoder_head = nn.Linear(embed_dim, patch_size * patch_size * 3)
self.mask_token = nn.Parameter(torch.randn(1, 1, embed_dim))
def quantize(self, z):
z_flat = z.reshape(-1, self.embed_dim)
distances = torch.cdist(z_flat, self.codebook)
indices = torch.argmin(distances, dim=1)
z_q = self.codebook[indices].reshape(z.shape)
return z_q, indices
def forward(self, x, stage='warmup'):
B = x.shape[0]
patches = self.encoder.patch_embed(x)
latent_tokens = self.latent_tokens.expand(B, -1, -1)
encoder_input = torch.cat([patches, latent_tokens], dim=1)
encoder_output = self.encoder.forward_features(encoder_input)
z = encoder_output[:, self.num_patches:]
z_q, indices = self.quantize(z)
mask_tokens = self.mask_token.expand(B, self.num_patches, -1)
decoder_input = torch.cat([z_q, mask_tokens], dim=1)
decoder_output = self.decoder.forward_features(decoder_input)
recon_patches = self.decoder_head(decoder_output[:, self.num_tokens:])
recon_img = recon_patches.view(B, img_size // patch_size, img_size // patch_size, patch_size, patch_size, 3)
recon_img = recon_img.permute(0, 1, 3, 2, 4, 5).reshape(B, 3, img_size, img_size)
return recon_img, z, z_q, indices
# 损失函数
def vq_loss(z, z_q):
commitment_loss = torch.mean((z.detach() - z_q) ** 2)
codebook_loss = torch.mean((z - z_q.detach()) ** 2)
return commitment_loss + codebook_loss
# 训练函数(改进版)
def train_titok(model, train_loader, proxy_loader, epochs, stage='warmup', device='cuda'):
model.to(device)
# 根据阶段选择优化参数
if stage == 'warmup':
# 第一阶段:优化所有参数
optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4)
elif stage == 'finetune':
# 第二阶段:仅优化解码器相关参数,固定编码器和量化器
trainable_params = list(model.decoder.parameters()) + list(model.decoder_head.parameters()) + [model.mask_token]
optimizer = optim.AdamW(trainable_params, lr=1e-4, weight_decay=1e-4)
# 显式固定编码器和码书
for param in model.encoder.parameters():
param.requires_grad = False
for param in model.latent_tokens:
param.requires_grad = False
for param in model.codebook:
param.requires_grad = False
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
for epoch in range(epochs):
model.train()
total_loss = 0
proxy_iter = iter(proxy_loader) # 代理码迭代器
for batch_idx, (images, _) in enumerate(train_loader):
images = images.to(device)
try:
proxy_codes = next(proxy_iter).to(device)
except StopIteration:
proxy_iter = iter(proxy_loader)
proxy_codes = next(proxy_iter).to(device)
optimizer.zero_grad()
recon_img, z, z_q, indices = model(images, stage=stage)
# 重建损失(仅第二阶段使用)
recon_loss = nn.MSELoss()(recon_img, images) if stage == 'finetune' else 0.0
# VQ损失(两阶段都使用)
vq_loss_term = vq_loss(z, z_q)
# 第一阶段:使用代理码监督
if stage == 'warmup':
proxy_loss = nn.CrossEntropyLoss()(indices.view(-1), proxy_codes.view(-1))
loss = vq_loss_term + proxy_loss
# 第二阶段:RGB重建 + VQ损失
else:
loss = recon_loss + 0.25 * vq_loss_term # 0.25是论文中常用的权重
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step()
print(f"Epoch {epoch+1}/{epochs}, Stage: {stage}, Loss: {total_loss / len(train_loader):.4f}")
# 数据加载
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.ImageNet(root='path_to_imagenet', split='train', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True, num_workers=4)
proxy_dataset = torch.randint(0, 4096, (len(train_dataset), 32)) # 模拟代理码
proxy_loader = DataLoader(proxy_dataset, batch_size=256, shuffle=True)
# 训练
model = TiTok()
train_titok(model, train_loader, proxy_loader, epochs=100, stage='warmup') # 第一阶段
train_titok(model, train_loader, proxy_loader, epochs=50, stage='finetune') # 第二阶段
代码中的关键实现细节
1. 第一阶段(Warm-up)的体现
- 优化目标:优化整个模型,包括编码器(
self.encoder)、潜在token(self.latent_tokens)、码书(self.codebook)和解码器(self.decoder+self.decoder_head)。 - 优化器设置:
if stage == 'warmup': optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4)model.parameters()返回所有可训练参数,意味着第一阶段所有部分都在优化。
- 损失函数:
if stage == 'warmup': proxy_loss = nn.CrossEntropyLoss()(indices.view(-1), proxy_codes.view(-1)) loss = vq_loss_term + proxy_lossproxy_loss:使用代理码(proxy_codes)监督量化后的索引(indices),确保1D分词结构与预训练VQGAN的表示对齐。vq_loss_term:标准的VQ-VAE损失,调整编码器输出(z)和量化输出(z_q)之间的距离。- 这里不直接使用RGB重建损失(
recon_loss),而是通过代理码间接监督,避免复杂的感知或对抗损失。
2. 第二阶段(Decoder Fine-tuning)的体现
-
固定编码器和量化器:
- 优化器设置:
elif stage == 'finetune': trainable_params = list(model.decoder.parameters()) + list(model.decoder_head.parameters()) + [model.mask_token] optimizer = optim.AdamW(trainable_params, lr=1e-4, weight_decay=1e-4)trainable_params只包含解码器相关参数(decoder、decoder_head和mask_token),不包括编码器(encoder)、潜在token(latent_tokens)和码书(codebook)。- 这意味着优化器只会更新解码器的权重,而编码器和量化器的参数保持不变。
- 显式固定:
for param in model.encoder.parameters(): param.requires_grad = False for param in model.latent_tokens: param.requires_grad = False for param in model.codebook: param.requires_grad = False- 通过设置
requires_grad = False,明确禁止梯度流向编码器、潜在token和码书的参数。即使这些部分参与前向传播(forward),它们的权重也不会更新。 - 这符合论文中“固定编码器和量化器”的描述。
- 通过设置
- 优化器设置:
-
仅微调解码器:
- 由于优化器只包含解码器参数,反向传播(
loss.backward())只会影响decoder、decoder_head和mask_token,从而实现“仅对解码器微调”。
- 由于优化器只包含解码器参数,反向传播(
-
损失函数:
else: # stage == 'finetune' loss = recon_loss + 0.25 * vq_loss_termrecon_loss:像素级的MSE损失,直接比较重建图像(recon_img)与输入图像(images),这是第二阶段的主要优化目标。0.25 * vq_loss_term:保留VQ损失的加权项(权重0.25是VQGAN常用实践),但由于编码器和码书已固定,这部分损失不会影响它们,只会通过解码器间接调整输入(z_q)的使用方式。- 固定体现在哪里? 因为
z和z_q是编码器和量化器的输出,而它们的参数不更新(requires_grad = False),vq_loss_term的梯度无法传播到编码器或码书,只会影响解码器的训练。
Loss如何体现固定哪些部分?
-
第一阶段:
loss = vq_loss_term + proxy_loss:vq_loss_term影响编码器(z)和码书(z_q),因为它们的参数可训练。proxy_loss监督量化索引(indices),间接优化整个模型。- 所有参数都在优化范围内,因此梯度会更新编码器、量化器和解码器。
-
第二阶段:
loss = recon_loss + 0.25 * vq_loss_term:recon_loss:直接作用于解码器的输出(recon_img),梯度只更新解码器参数。vq_loss_term:计算时涉及z和z_q,但由于编码器和码书的requires_grad = False,梯度无法传播到这些部分,只会通过解码器输入(z_q)调整解码器的行为。- 固定体现:编码器和码书的输出(
z和z_q)是静态的,损失的反向传播只影响解码器参数,这通过优化器的参数选择和requires_grad的设置实现。
总结
- 第一阶段(Warm-up):
- 代码中通过
model.parameters()优化所有参数。 - 损失函数使用代理码(
proxy_loss)和VQ损失(vq_loss_term),聚焦1D分词结构的训练。
- 代码中通过
- 第二阶段(Decoder Fine-tuning):
- 代码中通过限制
trainable_params只包含解码器参数,并显式设置requires_grad = False固定编码器和量化器。 - 损失函数切换为
recon_loss + 0.25 * vq_loss_term,其中recon_loss主导解码器优化,vq_loss_term的梯度因参数固定无法影响编码器和量化器。
- 代码中通过限制
这种实现精确地反映了论文中两阶段训练的逻辑:第一阶段训练整个模型以学习1D分词,第二阶段专注于解码器的RGB重建能力,同时保持编码器和量化器的稳定性。
前后两次代码对比
之前给的训练代码有错吗?
之前给的训练代码(即你引用的版本)没有明显的语法或逻辑错误,但它在实现TiTok的两阶段训练策略时存在一些不符合论文描述的缺陷,尤其是在第二阶段(Decoder Fine-tuning)。具体问题如下:
-
优化器未区分阶段:
- 代码中始终使用
optimizer = optim.AdamW(model.parameters(), ...),意味着在第一阶段(warmup)和第二阶段(finetune)都优化了模型的所有参数。 - 根据论文,第二阶段应“固定编码器和量化器,仅微调解码器”。但这份代码没有限制优化参数,导致第二阶段仍在更新编码器(
encoder)、潜在token(latent_tokens)和码书(codebook),这与TiTok的设计不符。
- 代码中始终使用
-
损失函数的使用不够精确:
- 第一阶段计算了
recon_loss = nn.MSELoss()(recon_img, images),但并未明确排除其影响。虽然loss只用了vq_loss_term + proxy_loss,但recon_loss被计算却未使用,可能造成混淆。 - 第二阶段的
loss = recon_loss + 0.25 * vq_loss_term是合理的,但由于编码器和量化器未被固定,vq_loss_term的梯度会错误地更新这些部分。
- 第一阶段计算了
-
代理码迭代问题:
- 使用
proxy_codes = next(iter(proxy_loader))[0]每次都重新创建迭代器,可能导致代理码与图像数据不对齐(每次从头开始迭代)。这在小数据集上可能不明显,但在大规模训练中会影响一致性。
- 使用
结论:
- 是否有错? 严格来说,没有语法错误,代码可以运行。但它在第二阶段的实现上与TiTok论文的描述不一致,属于功能性缺陷。
- 可以用吗? 可以运行并训练模型,但结果可能偏离TiTok的预期性能,因为第二阶段未正确固定编码器和量化器。
改进后的代码解决了什么问题?
改进后的代码(最新版本)更准确地实现了TiTok的两阶段训练策略:
-
优化器区分阶段:
- 第一阶段(
warmup):使用model.parameters()优化所有参数,与论文中训练整个模型的描述一致。 - 第二阶段(
finetune):只优化解码器相关参数(decoder、decoder_head和mask_token),并通过requires_grad = False显式固定编码器和量化器,符合“固定编码器和量化器,仅微调解码器”的要求。
- 第一阶段(
-
损失函数更清晰:
- 第一阶段:明确只用
vq_loss_term + proxy_loss,避免计算无用的recon_loss。 - 第二阶段:只在
finetune时计算recon_loss,逻辑更清晰,确保第一阶段聚焦1D分词,第二阶段聚焦RGB重建。
- 第一阶段:明确只用
-
代理码迭代改进:
- 使用
proxy_iter = iter(proxy_loader)和try-except机制,确保代理码与图像数据按批次对齐,避免每次重新创建迭代器的问题。
- 使用
结论:
- 改进后的代码更符合TiTok论文的设计意图,尤其在第二阶段正确实现了“仅微调解码器”的要求。
之前代码可以用吗?
- 技术上可以:它能跑通并训练模型,可能会生成合理的重建结果,因为两阶段的损失函数设计(
warmup用代理码,finetune用RGB重建)仍然有一定的指导作用。 - 但不推荐:由于第二阶段未固定编码器和量化器,模型可能过度调整这些部分,导致第一阶段学到的1D分词结构被破坏,最终性能可能不如论文报告的结果(例如rFID或gFID指标)。
如果你的目标是实验性地跑通TiTok并观察效果,之前代码可以用作初步尝试。但如果你希望严格复现TiTok的训练过程并追求论文中的性能,建议使用改进后的代码。
如何选择?
- 快速实验:用之前代码,简单易懂,能快速看到结果。
- 严格复现:用改进后代码,确保第二阶段只微调解码器,与TiTok的设计一致。
后记
2025年3月24日20点30分于上海,在grok 3大模型辅助下完成。