力扣mysql刷题记录
mysql刷题记录
刷题链接https://leetcode.cn/tag/database/problemset/
230220开始更新-
mysql冲!
- mysql刷题记录
- 1699. 两人之间的通话次数
- 1251. 平均售价
- 1571. 仓库经理
- 1445. 苹果和桔子
- 1193. 每月交易 I
- 1633. 各赛事的用户注册率
- 1173. 即时食物配送 I
- 1211. 查询结果的质量和占比
- 175. 组合两个表
- ⭐176. 第二高的薪水(查询第N高的数据)
- ⭐178. 分数排名
- ⭐180. 连续出现的数字
- 181. 超过经理收入的员工
- ⭐182. 查找重复的名字
- ⭐183. 从不订购的客户
- ⭐184. 部门工资最高的员工
- 185. 部门工资前三高的所有员工
- 196. 删除重复的电子邮箱
- 197. 上升的温度
1699. 两人之间的通话次数
题
编写 SQL 语句,查询每一对用户 (person1, person2) 之间的通话次数和通话总时长,其中 person1 < person2 。
该表没有主键,可能存在重复项。
该表包含 from_id 与 to_id 间的一次电话的时长。
from_id != to_id
示例 :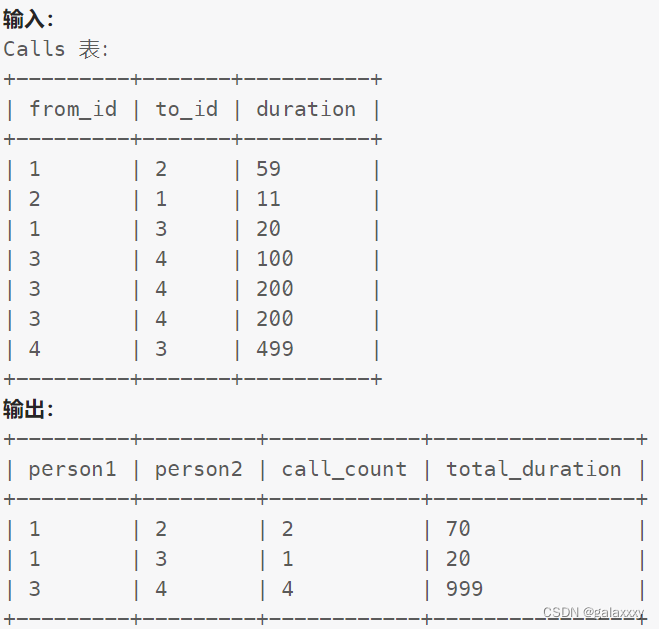
解释:
用户 1 和 2 打过 2 次电话,总时长为 70 (59 + 11)。
用户 1 和 3 打过 1 次电话,总时长为 20。
用户 3 和 4 打过 4 次电话,总时长为 999 (100 + 200 + 200 + 499)。
解
解法一
select
least(from_id, to_id) person1,
greatest(from_id, to_id) person2,
count(1) call_count,--count(1)≈count(*)统计列个数
sum(duration) total_duration
from
Calls
group by
least(from_id, to_id), greatest(from_id, to_id);
--根据最小,最大值相同点去判断
解法二
select
if(from_id<to_id,from_id,to_id) person1,
if(from_id<to_id,to_id,from_id) person2,
count(1) call_count,
sum(duration) total_duration
from
Calls
group by
person1,person2;
知识点:
-
least():一条记录中取几个字段的最小值
greates(): 一条记录中取几个字段的最大值
eg:
SELECT greatest(3,5,1,8,33,99,34,55,67,43) as max;
结果:99 -
if语句语法:
if(条件,如果是,如果不是) -
group by分组匹配,可以多条件
1251. 平均售价
题

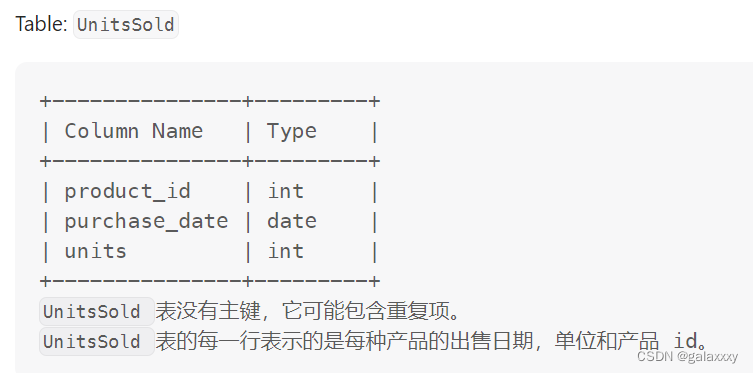
编写SQL查询以查找每种产品的平均售价。
average_price 应该四舍五入到小数点后两位。
units是卖出多少个
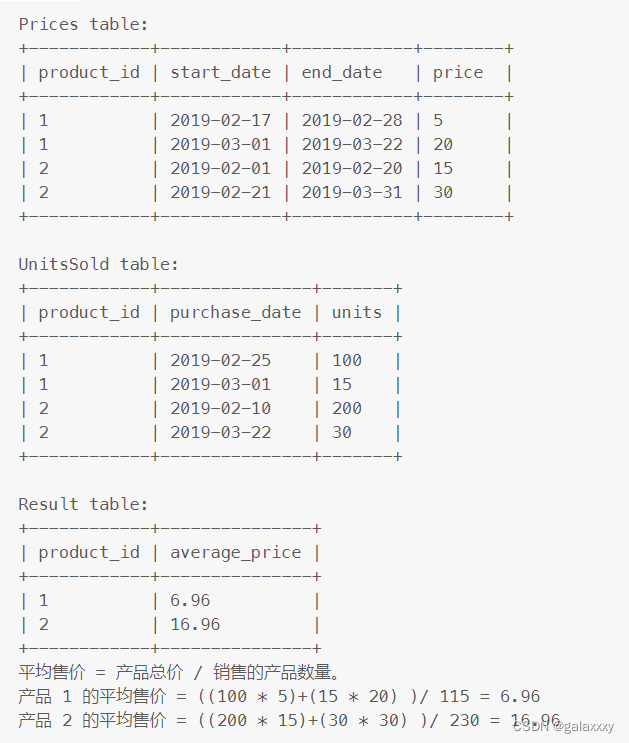
解
--每个价格的销售总额为 对应时间内的价格∗对应时间内的数量对应时间内的价格 * 对应时间内的数量对应时间内的价格∗对应时间内的数量。
--因为价格和时间在 Prices 表中,数量在 UnitsSold 表中,这两个表通过 product_id 关联
select
p.product_id,
round(sum(u.units * p.price)/sum(u.units),2) as average_price
from
Prices p inner join UnitsSold u
on
p.product_id=u.product_id
and u.purchase_date between p.start_date and p.end_date
group by p.product_id;-- 先按产品分类
知识点:
- inner join……on显式内连接
- round(~,小数位数):保留n位小数
1571. 仓库经理
题
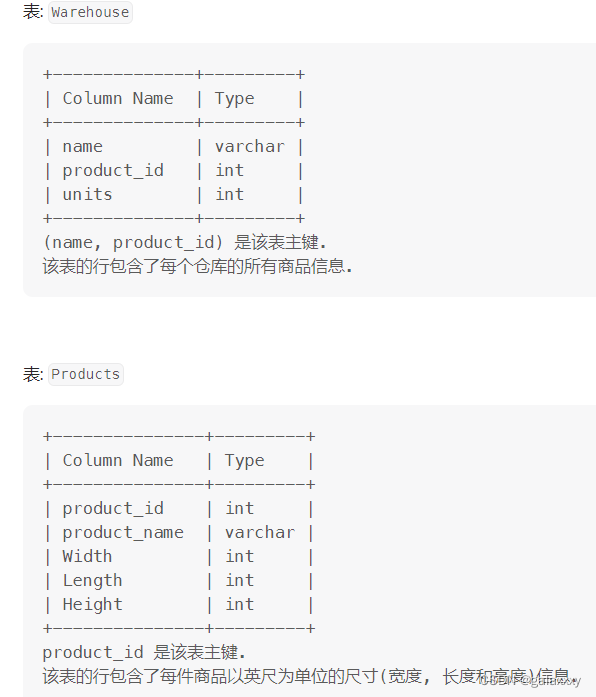
写一个 SQL 查询来报告, 每个仓库的存货量是多少立方英尺.
返回结果没有顺序要求.
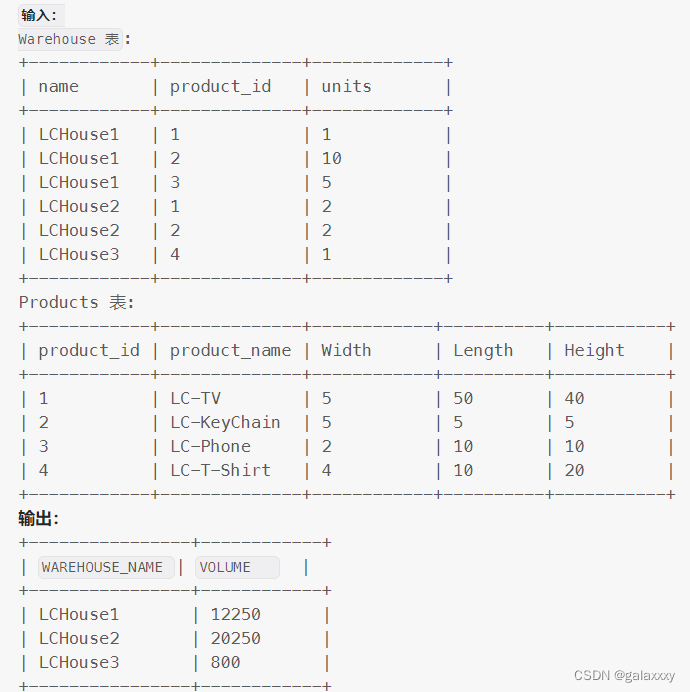
解释:
Id为1的商品(LC-TV)的存货量为 5x50x40 = 10000
Id为2的商品(LC-KeyChain)的存货量为 5x5x5 = 125
Id为3的商品(LC-Phone)的存货量为 2x10x10 = 200
Id为4的商品(LC-T-Shirt)的存货量为 4x10x20 = 800
仓库LCHouse1: 1个单位的LC-TV + 10个单位的LC-KeyChain + 5个单位的LC-Phone.
总存货量为: 110000 + 10125 + 5200 = 12250 立方英尺
仓库LCHouse2: 2个单位的LC-TV + 2个单位的LC-KeyChain.
总存货量为: 210000 + 2125 = 20250 立方英尺
仓库LCHouse3: 1个单位的LC-T-Shirt.
总存货量为: 1800 = 800 立方英尺.
解
-- 第一个自己写出来的sql题!
--先分组,再按分组计算体积*数量
select
w.name WAREHOUSE_NAME,
sum(p.Width*p.Length*p.Height*w.units) VOLUME
from
Warehouse w,
Products p
where
w.product_id = p.product_id
group by
WAREHOUSE_NAME;
1445. 苹果和桔子
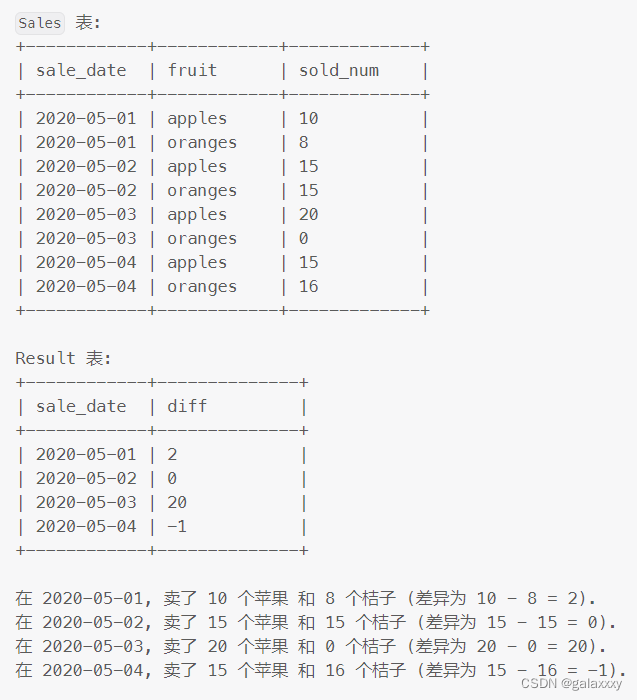
写一个 SQL 查询, 报告每一天 苹果 和 桔子 销售的数目的差异.
返回的结果表, 按照格式为 (‘YYYY-MM-DD’) 的 sale_date 排序.
解
select
s.sale_date,
s.sold_num-a.sold_num diff
from
Sales s,Sales a
where
s.sale_date=a.sale_date and
s.fruit='apples' and a.fruit='oranges'
group by s.sale_date
1193. 每月交易 I
题

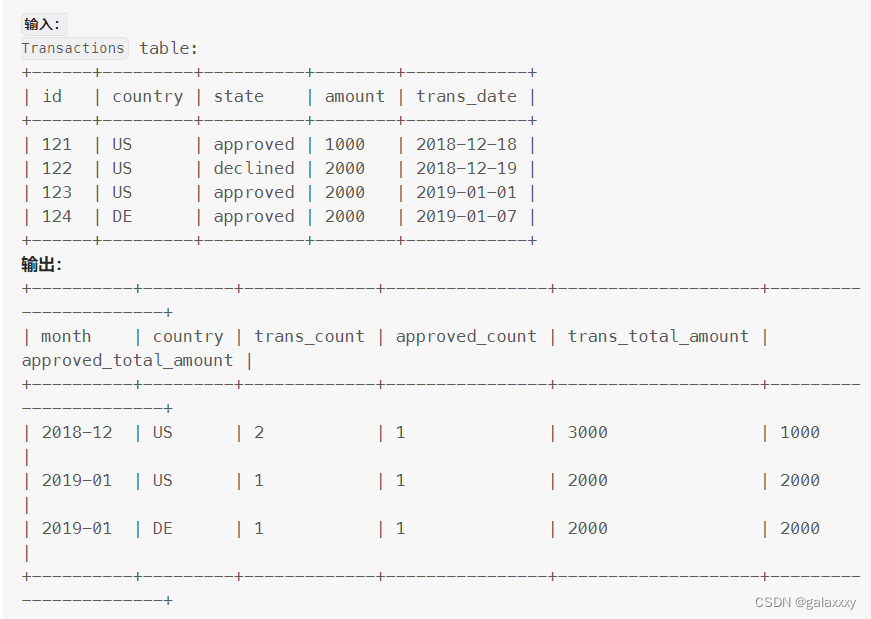
编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。
以 任意顺序 返回结果表。
解
select
DATE_FORMAT(t.trans_date, '%Y-%m') month ,
t.country country ,
count(1) trans_count ,
count(if(t.state='approved',1,NULL)) approved_count,
sum(t.amount) trans_total_amount,
sum(if(t.state='approved',amount,0)) approved_total_amount
from
Transactions t
group by
DATE_FORMAT(t.trans_date, '%Y-%m'),t.country;-- 按照国家,年月分类
知识点:
- DATE_FORMAT(t.trans_date, ‘%Y-%m’),数据表中的 trans_date 是精确到日,我们可以使用 DATE_FORMAT() 函数将日期按照年月 %Y-%m 输出。比如将 2019-01-02 转换成 2019-01
- if用法:if(t.state=‘approved’,1,NULL),如果(t.state=‘approved’)成立,就返回1,不成立就返回null
1633. 各赛事的用户注册率
题
写一条 SQL 语句,查询各赛事的用户注册百分率,保留两位小数。
返回的结果表按 percentage 的 降序 排序,若相同则按 contest_id 的 升序 排序。
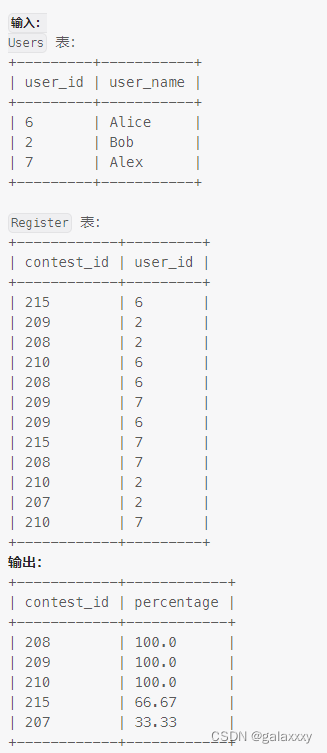
解释:
所有用户都注册了 208、209 和 210 赛事,因此这些赛事的注册率为 100% ,我们按 contest_id 的降序排序加入结果表中。
Alice 和 Alex 注册了 215 赛事,注册率为 ((2/3) * 100) = 66.67%
Bob 注册了 207 赛事,注册率为 ((1/3) * 100) = 33.33%
解
select
--先按id分组,round保留两位小数
r.contest_id contest_id,
round(100*count(1)/(select count(1) from users),2) percentage
from
Register r
group by
r.contest_id
order by
percentage desc,contest_id asc;
1173. 即时食物配送 I
题
如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。
写一条 SQL 查询语句获取即时订单所占的百分比, 保留两位小数。
查询结果如下所示。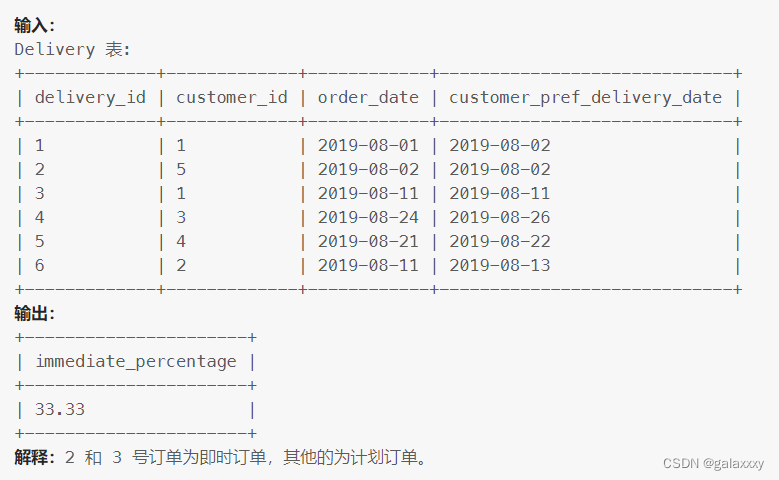
解
select
round(
sum(IF(order_date = customer_pref_delivery_date, 1, NULL))
/ COUNT(1)* 100,2)
as immediate_percentage
from
Delivery;
1211. 查询结果的质量和占比
题
“位置”(position)列的值为 1 到 500 。
“评分”(rating)列的值为 1 到 5 。评分小于 3 的查询被定义为质量很差的查询。
将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写一组 SQL 来查找每次查询的名称(query_name)、质量(quality) 和 劣质查询百分比(poor_query_percentage)。
质量(quality) 和劣质查询百分比(poor_query_percentage) 都应四舍五入到小数点后两位。
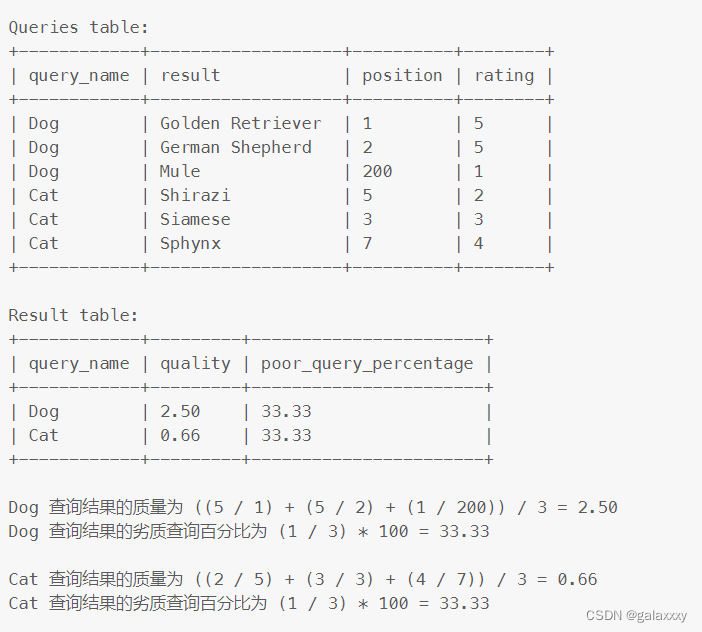
解
select
q.query_name query_name ,
round(avg(q.rating/q.position),2) quality,
round(sum(if(q.rating<3,1,0))/count(1)*100,2) poor_query_percentage
from
Queries q
group by
q.query_name;
175. 组合两个表
编写一个SQL查询来报告 Person 表中每个人的姓、名、城市和州。如果 personId 的地址不在 Address 表中,则报告为空 null 。
解
select
p.firstName firstName,
p.lastName lastName,
a.city city ,
a.state state
from
Person p
left join
Address a
on
p.personId=a.personId;
知识点:
总结:
内连接 inner join:A,B表值都存在情况
外连接 outer join:附表中值可能存在null的情况。
①A inner join B:取交集
②A left join B:取A全部,B没有对应的值,则为null
③A right join B:取B全部,A没有对应的值,则为null
④A full outer join B:取并集,彼此没有对应的值为null
上述4种的对应条件,在on后填写。
⭐176. 第二高的薪水(查询第N高的数据)
题
编写一个 SQL 查询,获取并返回 Employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null 。

解
select
ifnull(
(select distinct salary from Employee order by salary desc limit 1 offset 1) ,null)
SecondHighestSalary
知识点:
- 数据去重:SELECT DISTINCT
- limit y 分句表示: 读取 y 条数据
limit x, y 分句表示: 跳过 x 条数据,读取 y 条数据
limit y offset x 分句表示: 跳过 x 条数据,读取 y 条数据
eg:limit 1 offset 1跳过1条数据,读取1条数据 - IFNULL(value1, value2) :如果value1不为空,返回value1,否则返回value2
题
编写一个SQL查询来报告 Employee 表中第 n 高的工资。如果没有第 n 个最高工资,查询应该报告为 null

解
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare m int;
SET m = N-1;
RETURN (
select
ifnull(
(select distinct salary from Employee order by salary desc limit 1 offset m),null)
);
END
知识点:
- limit不支持运算,所以不能直接N-1,需要先声明一个int型变量m,并且set他的值为N-1
- 另外,这题不需要再为列起别名,因为在一个函数里,这个函数返回的是一个int值,那么后台在调用这个函数时,返回的列名就是——函数名(N)
⭐178. 分数排名
编写 SQL 查询对分数进行排序。排名按以下规则计算:
分数应按从高到低排列。
如果两个分数相等,那么两个分数的排名应该相同。
在排名相同的分数后,排名数应该是下一个连续的整数。换句话说,排名之间不应该有空缺的数字。
按 score 降序返回结果表。
select
score ,
dense_rank() over(order by Score desc) 'rank'
from
Scores;
知识点:
专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级
得到结果:
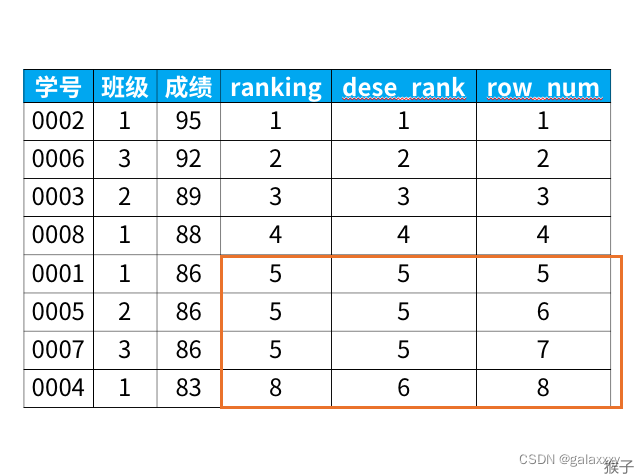
从上面的结果可以看出: 1)rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
2)dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
3)row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
⭐180. 连续出现的数字
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
返回的结果表中的数据可以按 任意顺序 排列。
select
distinct Num as ConsecutiveNums
from
(select Num,lead(Num,1) over(order by id) Num1,lead(Num,2) over (order by id) Num2 from Logs)
temp -- 此处创立一张新表,要有自己的姓名
where
Num=Num1 and Num1=Num2;
# 法二:ID连续,Num相等
SELECT DISTINCT
l1.Num AS ConsecutiveNums
FROM
Logs l1,
Logs l2,
Logs l3--自连接
WHERE
l1.Id = l2.Id - 1
AND l2.Id = l3.Id - 1
AND l1.Num = l2.Num
AND l2.Num = l3.Num
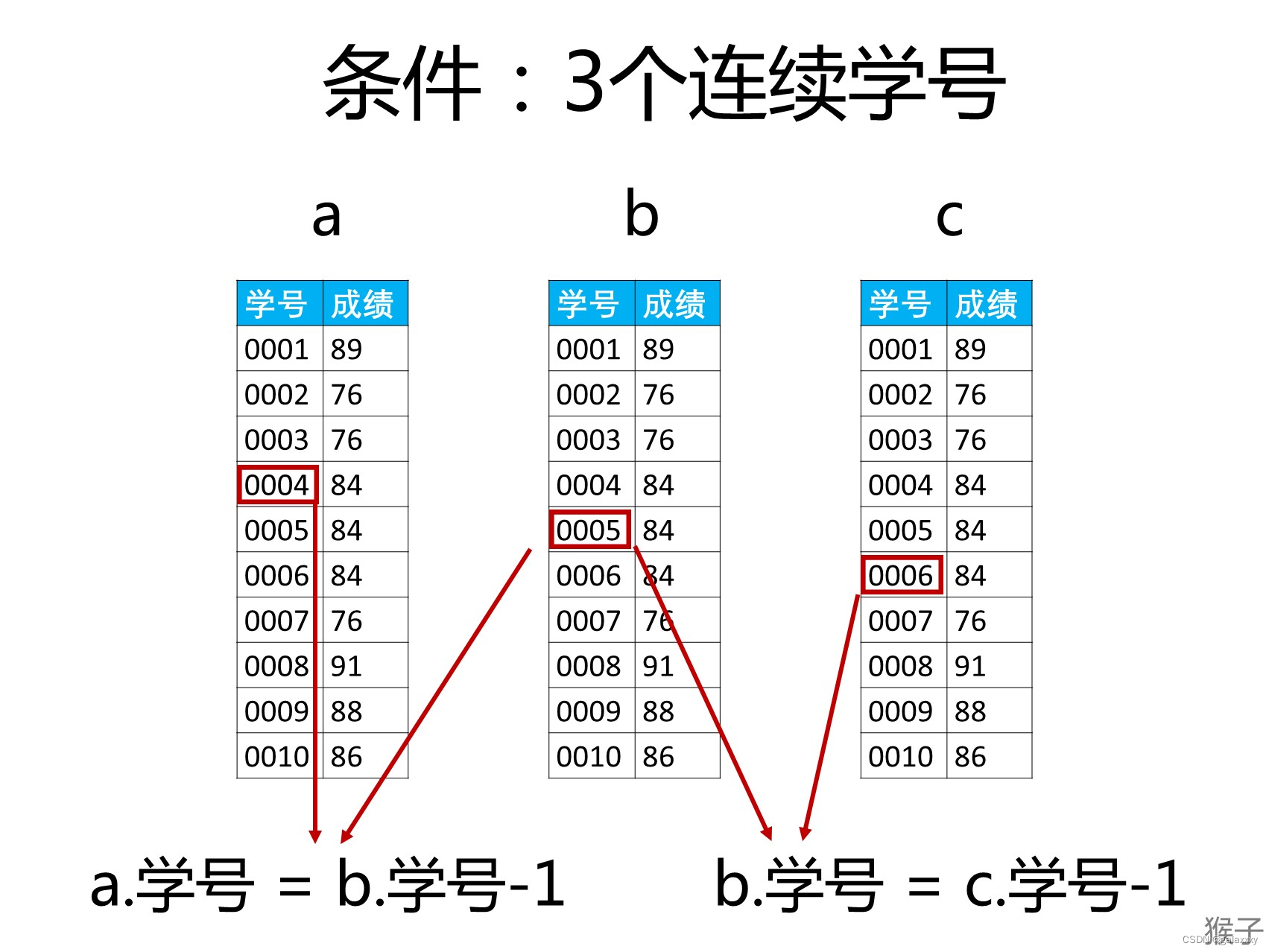
知识点:
1.
向上窗口函数lead:取出字段名所在的列,向上N行的数据,作为独立的列
向下窗口函数lag:取出字段名所在的列,向下N行的数据,作为独立的列
窗口函数语法如下:
lag(字段名,N,默认值) over(partion by …order by …)
lead(字段名,N,默认值) over(partion by …order by …)
例题:找出连续3次为球队得分的球员
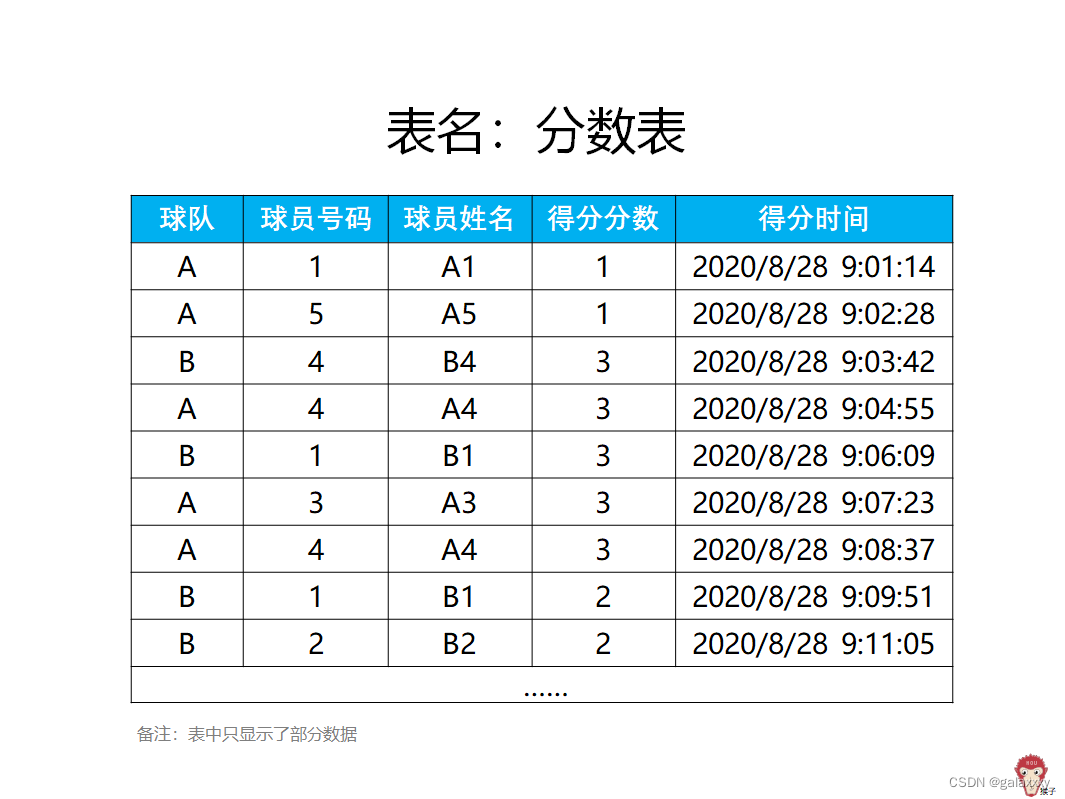
用向上窗口函数lead,得到球员姓名向上1行的列(第2列),因为A1向上1行超出了表行列的范围,所以这里对应的值就是默认值(不设置默认值就是null)

select 球员姓名,
lead(球员姓名,1) over(partition by 球队
order by 得分时间) as 下一项
from 分数表;
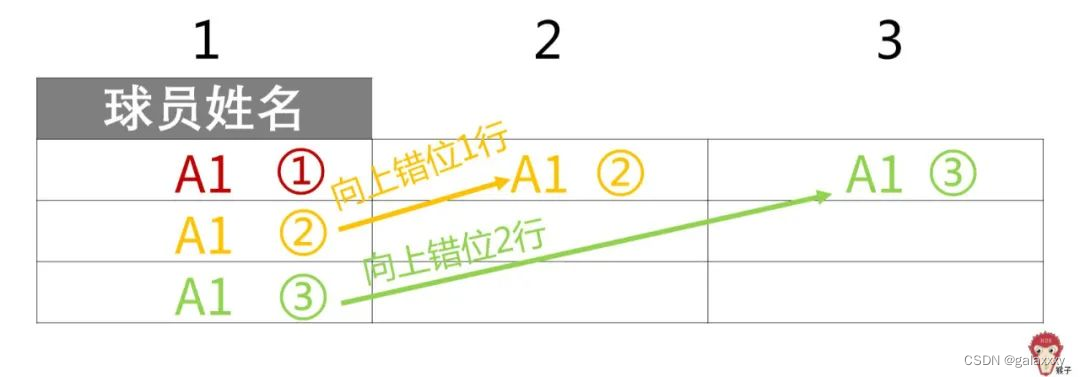
select 球员姓名,
lead(球员姓名,1) over(partition by 球队 order by 得分时间) as 姓名1,
lead(球员姓名,2) over(partition by 球队 order by 得分时间) as 姓名2
from 分数表;
结果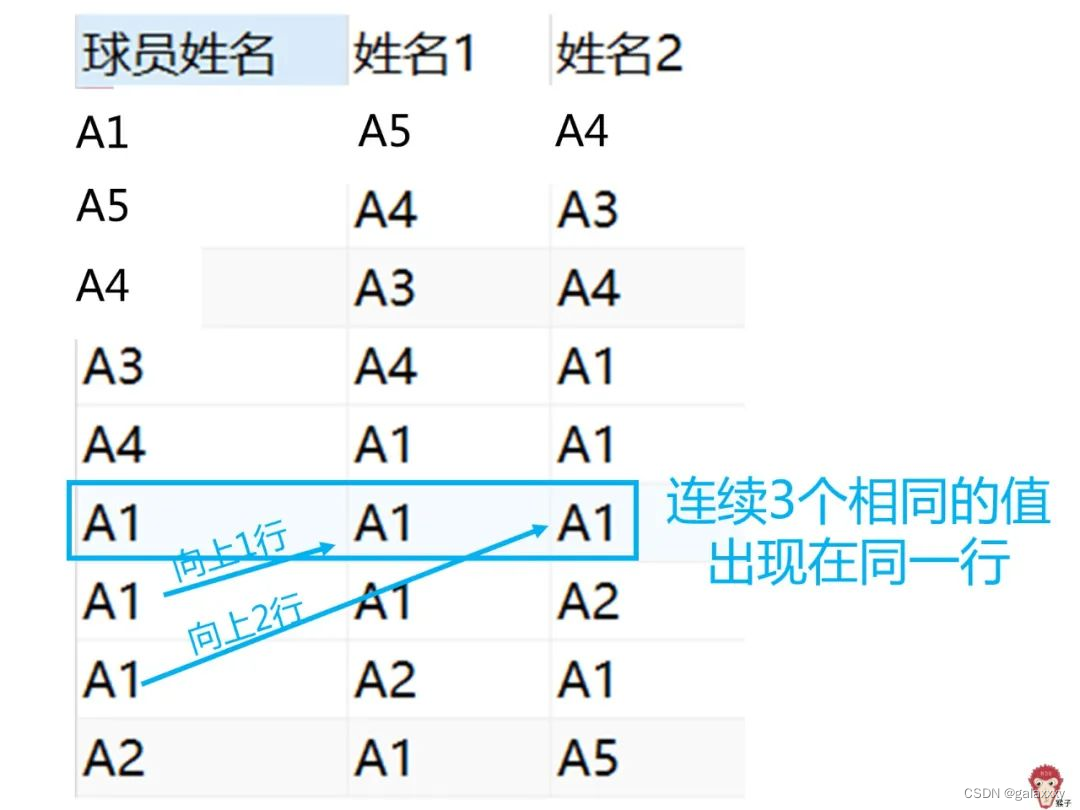
完成上面工作,现在就可以使用where子句筛选出出三个值都相同的行,也就是球员姓名 = 姓名1 and 球员姓名 = 姓名2。
select distinct 球员姓名
from(
select 球员姓名,
lead(球员姓名,1) over(partition by 球队 order by 得分时间) as 姓名1,
lead(球员姓名,2) over(partition by 球队 order by 得分时间) as 姓名2
from 分数表
) as a
where (a.球员姓名 = a.姓名1 and a.球员姓名 = a.姓名2);
解题步骤:
-
要用窗口函数,先根据球队分组,再按得分时间排序

-
找出连续出现3次的值,用lag,lead函数排出一张新表
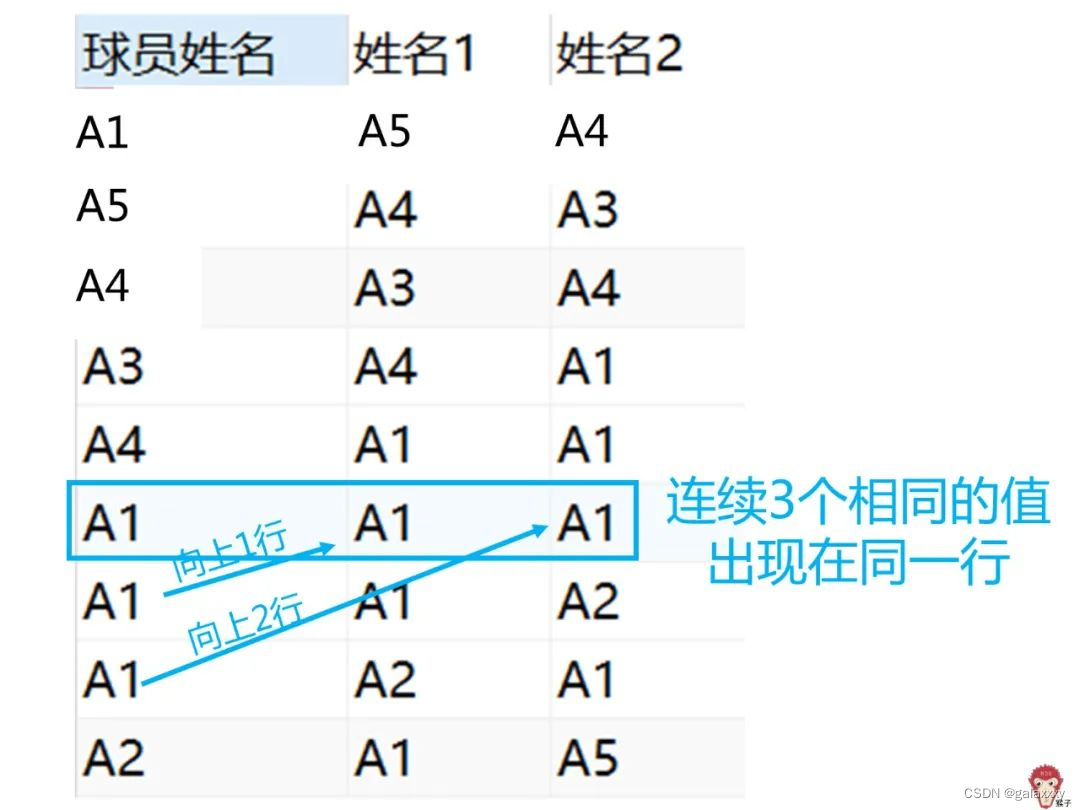
3.使用where子句筛选出出三个值都相同的行,也就是球员姓名 = 姓名1 and 球员姓名 = 姓名2。
181. 超过经理收入的员工
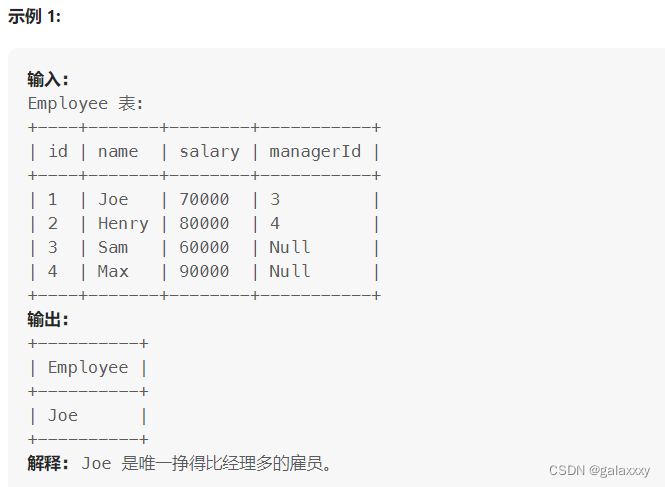
select
a.name Employee
from
Employee a,
Employee b
where
a.managerId=b.id and
a.salary>b.salary
⭐182. 查找重复的名字
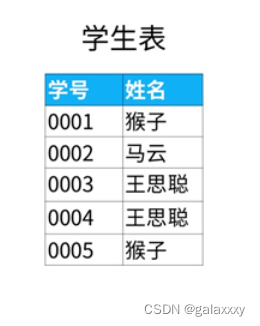
1.看到“找重复”的关键字眼,首先要用分组函数(group by),再用聚合函数中的计数函数count()给姓名列计数。
2.分组汇总后,生成了一个如下的表。从这个表里选出计数大于1的姓名,就是重复的姓名。
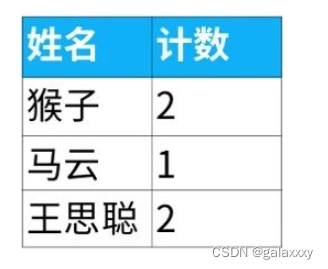
select 姓名, count(姓名) as 计数
from 学生表
group by 姓名;
select 姓名 from
(
select 姓名, count(姓名) as 计数
from 学生表
group by 姓名
) as 辅助表
where 计数 > 1;
法二:having
select 姓名
from 学生表
group by 姓名
having count(姓名) > 1;
【举一反三】
本题也可以拓展为:找出重复出现n次的数据。只需要改变having语句中的条件即可:
select 列名
from 表名
group by 列名
having count(列名) > n;
⭐183. 从不订购的客户
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。

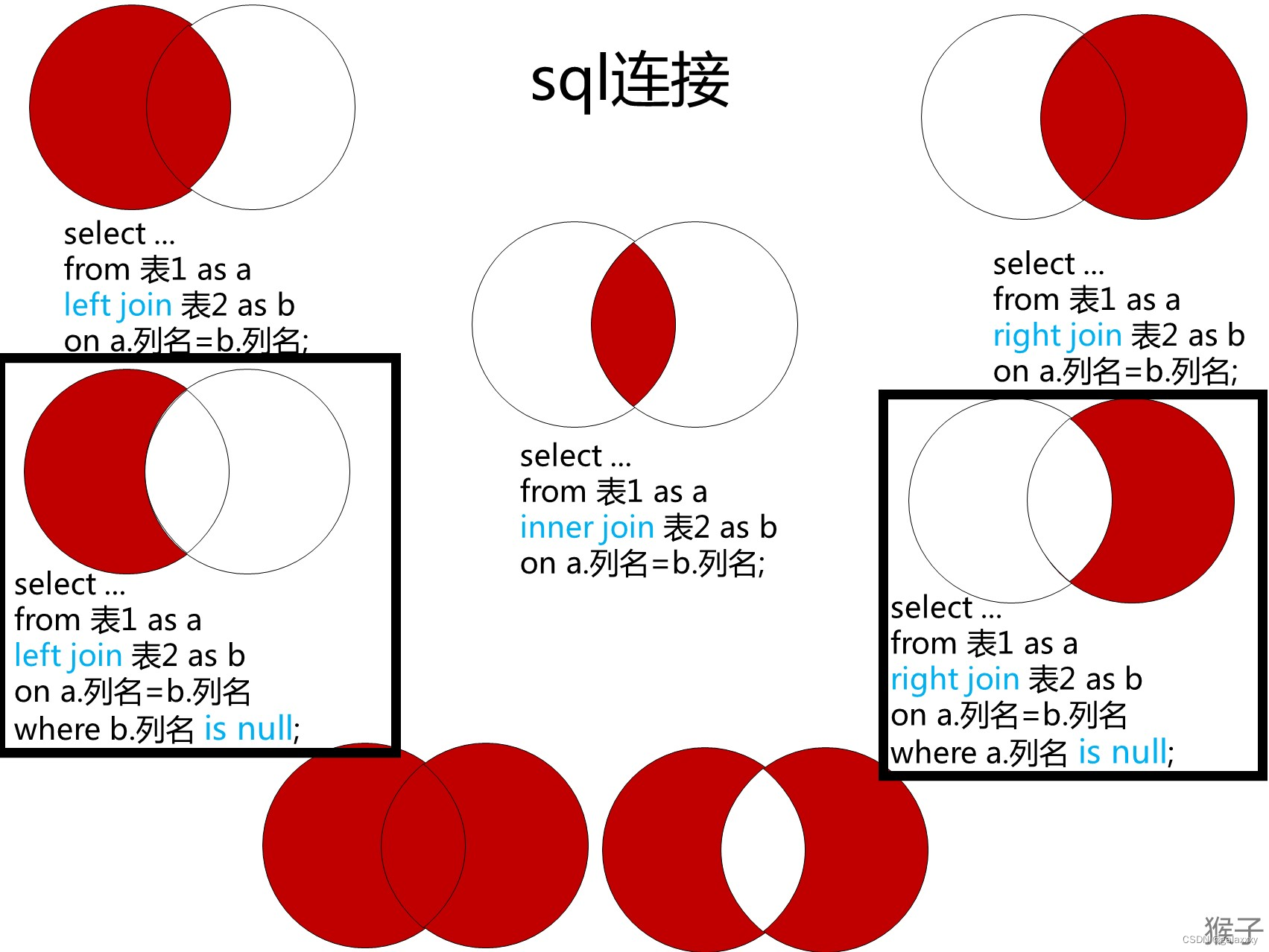
上图黑色框里的sql解决的问题是:不在表里的数据,也就是在表A里的数据,但是不在表B里的数据
select
c.Name Customers
from
Customers c
left join
Orders o
on
c.id=o.CustomerId
where
o.CustomerId is null;
请问不是近视眼的学生都有谁?
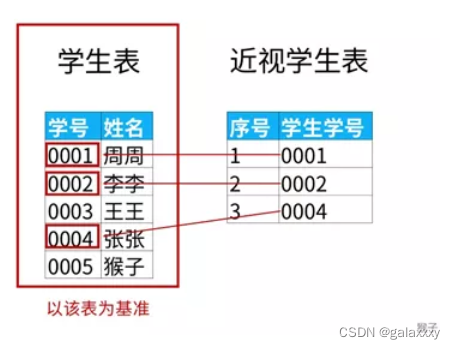
select a.姓名 as 不近视的学生名单
from 学生表 as a
left join 近视学生表 as b
on a.学号=b.学生学号
where b.序号 is null;
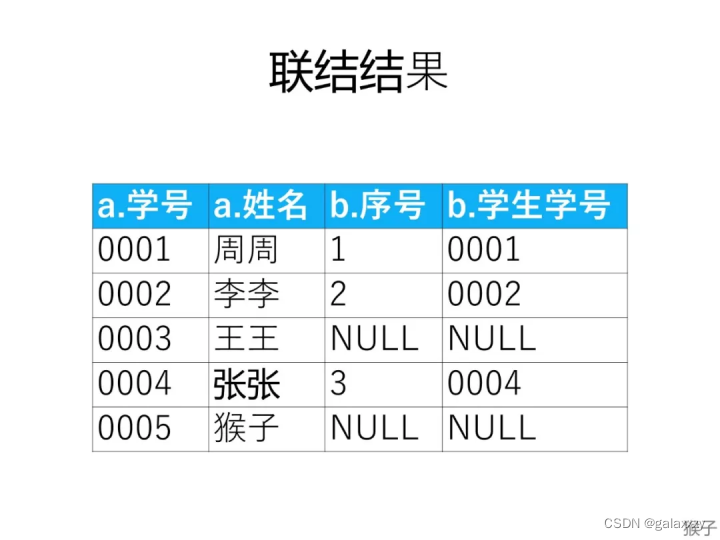
在不加where字句的情况下,两表联结得到下图的表
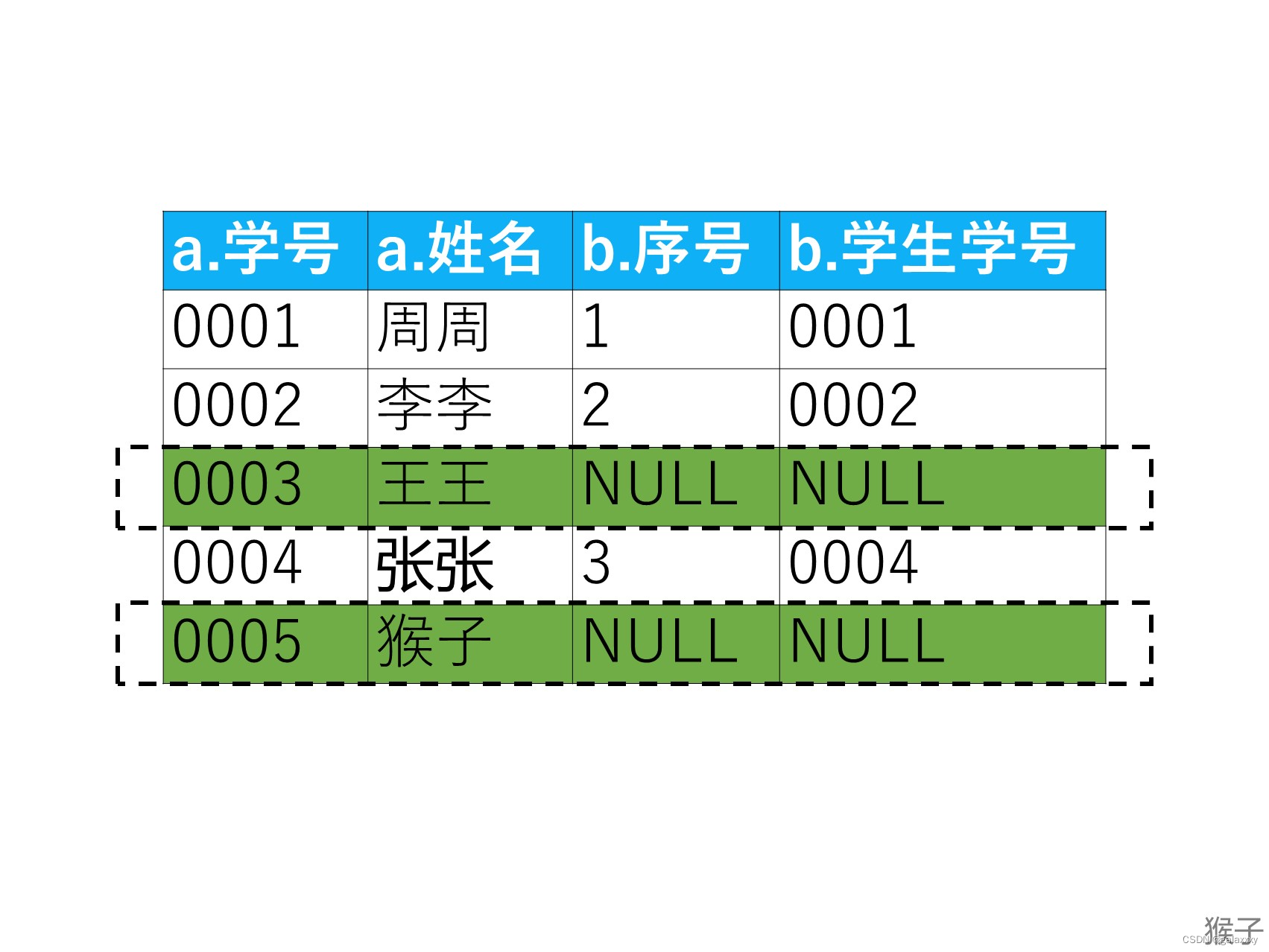
假设where字句(where b.序号 is null;)就会把b.序号这一列里为空值(NULL)的行选出来,就是题目要求的不近视的学生。(下图绿色框里的行)
⭐184. 部门工资最高的员工

法一:
select Department.name,Employee.name,Salary
from Employee
left join Department on Employee.DepartmentId = Department.Id
where (Employee.DepartmentId,Salary) in
(select DepartmentId,max(Salary)
from Employee
group by DepartmentId);
解题步骤:
- 两表连结
因为要查的是所有员工,所以是以员工表(表名Employee)进行左联结。
联结条件是什么?通过部门Id联结。
所以多表联结的sql如下:
from Employee
left join Department on Employee.DepartmentId = Department.Id
- 在合并表里查询,找出每个部门内最高的工资
where (Employee.DepartmentId,Salary) in
(select DepartmentId,max(Salary)
from Employee
group by DepartmentId)
/* 此语句可查出每个部门里的最高工资,
in里是包含多条数据的,在指定的集合范围内,多选一
eg:-- 查询销售部和市场部的所有员工信息
select * from employee
where dept in
(select id from dept where name = '销售部' or name = '市场部');*/
详细解题过程点此
法二:窗口函数
select Department, Employee, Salary
from
(
select
D.Name as Department,
E.Name as Employee,
E.Salary as Salary,
rank() over(partition by D.Name order by E.Salary desc) as rank_
from Employee E join Department D on E.DepartmentId = D.Id
) as tmp
where rank_ = 1
解题步骤:
1.rank() over(partition by D.Name order by E.Salary desc) as rank_
此句代码是先按照D.Name分区,再按照E.Salary 降序排序,每个分区里的rank排序都重新开始
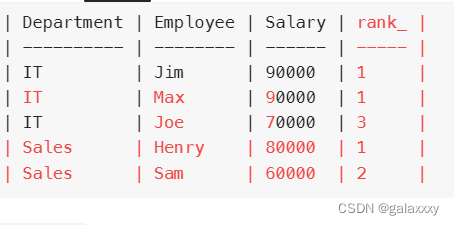
select
D.Name as Department,
E.Name as Employee,
E.Salary as Salary,
rank() over(partition by D.Name order by E.Salary desc) as rank_
from Employee E join Department D on E.DepartmentId = D.Id
此代码意思是在左连接表中打出排名,再在此表中查询每个rank_=1的行
185. 部门工资前三高的所有员工
topN问题:每组最大的N条记录。这类问题涉及到“既要分组,又要排序”的情况,要能想到用窗口函数来实现。

解释:
在IT部门:
- Max的工资最高
- 兰迪和乔都赚取第二高的独特的薪水
- 威尔的薪水是第三高的
在销售部:
- 亨利的工资最高
- 山姆的薪水第二高
- 没有第三高的工资,因为只有两名员工
-- 与上题一致,修改where即可
select
Department ,Employee , Salary
from
(
select
d.name Department ,
e.name Employee ,
e.salary Salary,
dense_rank() over(partition by e.departmentId order by salary desc)rank_
from
Employee e left join Department d
on e.departmentId=d.id
) temp
where rank_<=3;
196. 删除重复的电子邮箱
编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
以 任意顺序 返回结果表。 (注意: 仅需要写删除语句,将自动对剩余结果进行查询)

delete a
from person a inner join person b
where a.email = b.email and a.id > b.id
知识点
- delete语法如何作用于联结表
delete语法
最原始的delete语句delete from table1 where table1.id = 1;
如果需要关联其他表进行删除
delete table1
from table1 inner join table2 on table1.id = table2.id
where table2.type = 'something' and table1.id = 'idnums';
- inner join的原理
组成笛卡尔积
select * from person as a inner join person as b

筛选笛卡尔积中,email相同的记录
select * from person as a inner join person as b where a.email = b.email

选出email相同且a中id更大的记录,从而保留小的id
select * from person as a inner join person as b where a.email = b.email and a.id > b.id
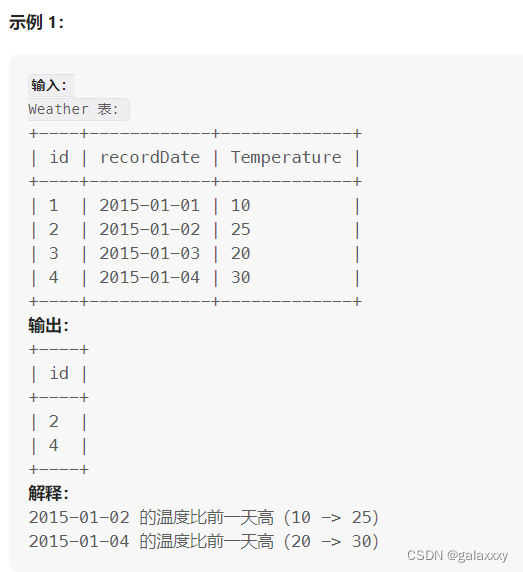
197. 上升的温度
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
select
b.id id
from
Weather a,Weather b
where
DATEDIFF(a.RecordDate,b.RecordDate) = -1 and a.Temperature<b.Temperature;
知识点:
- DATEDIFF(date1, date2) : 返回起始时间date1和结束时间date2之间的天数
where b.recordDate = ADDDATE( a.recordDate, INTERVAL 1 DAY ) and a.Temperature<b.Temperature;也可以(用adddate 函数给b加一天)
DATE_ADD(date, INTERVAL expr type) :返回一个日期/时间值加上一个时间间隔expr后的时间值