GO语言入门
1. Go语言结构
Go 语言的基础组成有以下几个部分:
- 包声明
- 引入包
- 函数
- 变量
- 语句 & 表达式
- 注释
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
package main定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。import "fmt"告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。func main()是程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。fmt.Println(...)可以将字符串输出到控制台,并在最后自动增加换行字符 \n。
使用 fmt.Print(“hello, world\n”) 可以得到相同的结果。
Print 和 Println 这两个函数也支持使用变量,如:fmt.Println(arr)。如果没有特别指定,它们会以默认的打印格式将变量 arr 输出到控制台。- 当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 protected )。
2. Go语言基础语法
2.1. Go标记
Go 程序可以由多个标记组成,可以是关键字,标识符,常量,字符串,符号。如以下 GO 语句由 6 个标记组成:
fmt.Println("Hello, World!")
6 个标记是(每行一个):
1. fmt
2. .
3. Println
4. (
5. "Hello, World!"
6. )
2.2. 行分隔符
在 Go 程序中,一行代表一个语句结束。每个语句不需要像 C 家族中的其它语言一样以分号 ; 结尾,因为这些工作都将由 Go 编译器自动完成。
2.3. 注释
注释不会被编译,每一个包应该有相关注释。
单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾。如:
// 单行注释
/*
Author by 菜鸟教程
我是多行注释
*/
2.4. 标识符
标识符用来命名变量、类型等程序实体。一个标识符实际上就是一个或是多个字母(A~Z 和 a~z)数字(0-9)、下划线_组成的序列,但是第一个字符必须是字母或下划线而不能是数字。
以下是有效的标识符:
mahesh kumar abc move_name a_123
myname50 _temp j a23b9 retVal
以下是无效的标识符:
- 1ab(以数字开头)
- case(Go 语言的关键字)
- a+b(运算符是不允许的)
2.5. 关键字
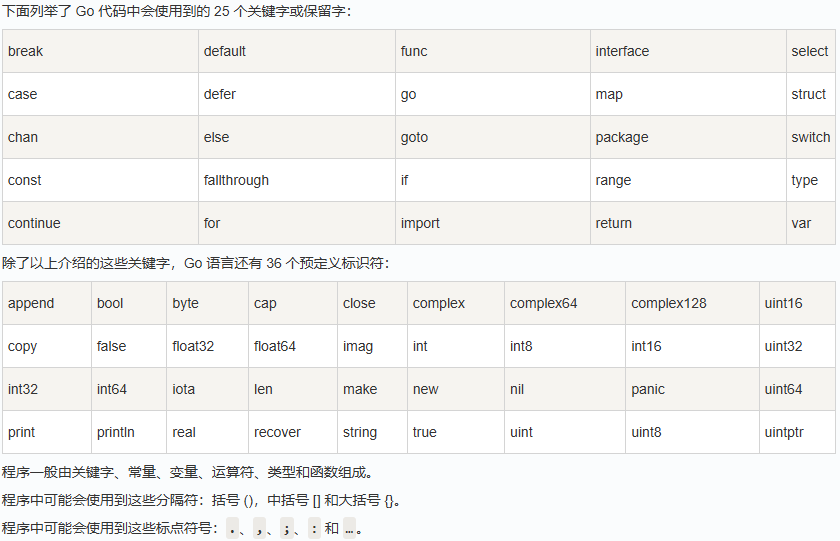
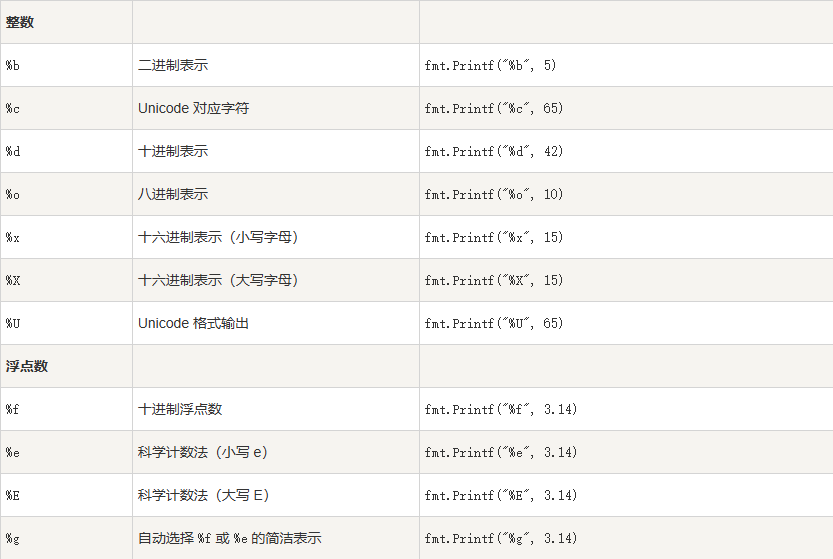
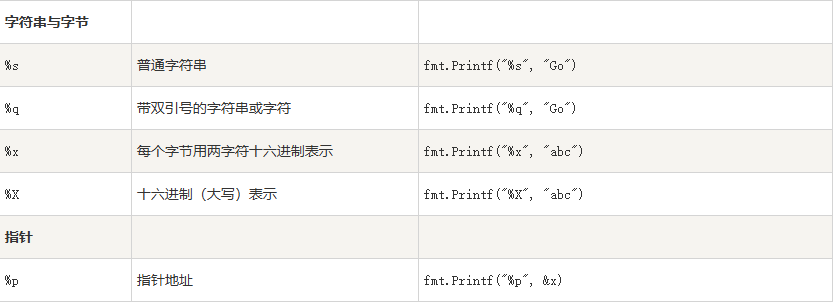
2.6. 格式化字符串
Go 语言中使用 fmt.Sprintf 或 fmt.Printf 格式化字符串并赋值给新串:
-
Sprintf 根据格式化参数生成格式化的字符串并返回该字符串。
fmt.Sprintf(格式化样式, 参数列表…)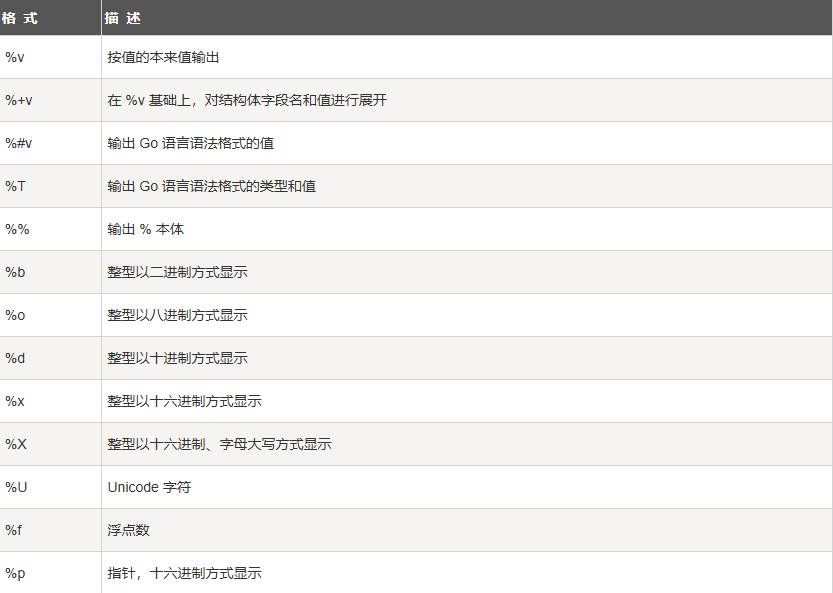

-
Printf 根据格式化参数生成格式化的字符串并写入标准输出
fmt.Printf(格式化样式, 参数列表…)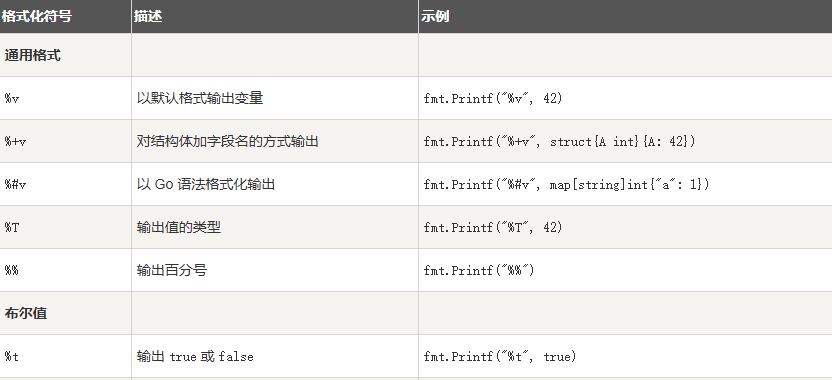
package main
import (
"fmt"
)
func main() {
// %d 表示整型数字,%s 表示字符串
var stockCode = 123
var endDate = "2025-04-13"
var url = "Code=%d&endDate=%s"
var targetUrl = fmt.Sprintf(url, stockCode, endDate)
fmt.Println(targetUrl) // Code=123&endDate=2025-04-13
}
package main
import (
"fmt"
)
func main() {
// %d 表示整型数字,%s 表示字符串
var stockCode = 123
var endDate = "2025-04-13"
var url = "Code=%d&endDate=%s"
fmt.Printf(url, stockCode, endDate) // Code=123&endDate=2025-04-13
}
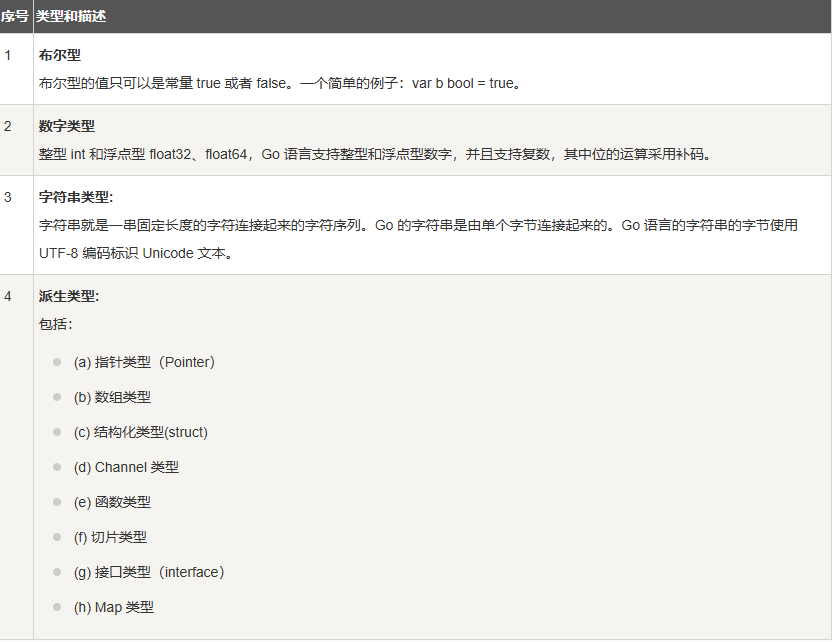
3. Go语言数据类型
在 Go 编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
3.1. 数字类型
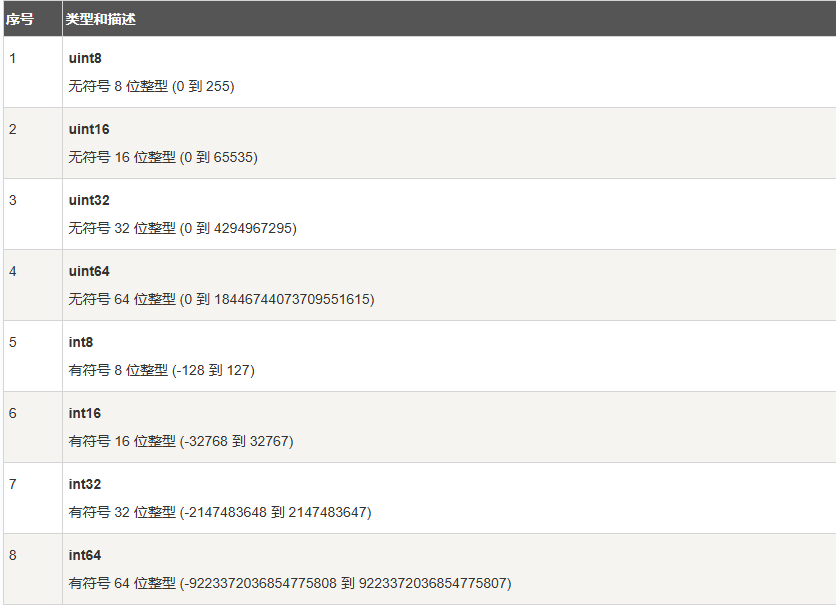
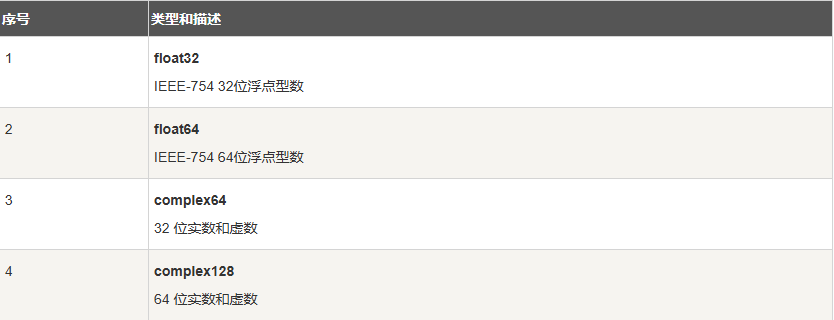
Go 也有基于架构的类型,例如:int、uint 和 uintptr。
3.2. 浮点型
3.3. 其他数字类型
4. GO语言变量
变量来源于数学,是计算机语言中能储存计算结果或能表示值抽象概念。
变量可以通过变量名访问。
Go 语言变量名由字母、数字、下划线组成,其中首个字符不能为数字。
声明变量的一般形式是使用 var 关键字:
var identifier type
可以一次声明多个变量:
var identifier1, identifier2 type
4.1. 变量声明
-
指定变量类型,如果没有初始化,则变量默认为零值,零值就是变量没有做初始化时系统默认设置的值
package main import "fmt" func main() { // 声明一个变量并初始化 var a = "RU NOOB" fmt.Println(a) // RU NOOB // 没有初始化就为零值 var b int fmt.Println(b) // 0 // bool 零值为false var c bool fmt.Println(c) // false // string 零值为空字符串 var s string fmt.Println(s) }以下几种类型为 nil:
var a *int var a []int var a map[string] int var a chan int var a func(string) int var a error // error 是接口 -
根据值自行判定变量类型
var v_name = value -
如果变量已经使用 var 声明过了,再使用 := 声明变量,就产生编译错误,格式:
v_name := value // 把右边 value 的值赋给左边的变量 v_name,并根据右侧的值自动推断类型例如:
var intVal int intVal :=1 // 这时候会产生编译错误,因为 intVal 已经声明,不需要重新声明直接使用下面的语句即可:
intVal := 1 // 此时不会产生编译错误,因为有声明新的变量,因为 := 是一个声明语句intVal := 1相等于:var intVal int intVal =1
4.2. 多变量声明
//类型相同多个变量, 非全局变量
var vname1, vname2, vname3 type
vname1, vname2, vname3 = v1, v2, v3
var vname1, vname2, vname3 = v1, v2, v3 // 和 python 很像,不需要显示声明类型,自动推断
vname1, vname2, vname3 := v1, v2, v3 // 出现在 := 左侧的变量不应该是已经被声明过的,否则会导致编译错误
// 这种因式分解关键字的写法一般用于声明全局变量
var (
vname1 v_type1
vname2 v_type2
)
package main
import (
"fmt"
)
var x, y int
var (
a int
b bool
)
var c, d int = 1, 2
var e, f = 123, "hello"
func main() {
//这种不带声明格式的只能在函数体中出现
g, h := 123, "hello"
fmt.Println(x, y, a, b, c, d, e, f, g, h) // 0 0 0 false 1 2 123 hello 123 hello
}
4.3. 值类型和引用类型
所有像 int、float、bool 和 string 这些基本类型都属于值类型,使用这些类型的变量直接指向存在内存中的值:

当使用等号 = 将一个变量的值赋值给另一个变量时,如:j = i,实际上是在内存中将 i 的值进行了拷贝:

你可以通过 &i 来获取变量 i 的内存地址,例如:0xf840000040(每次的地址都可能不一样)。
值类型变量通常存储在栈中,尤其是当它们是局部变量时。当值类型变量的值需要在函数作用域之外使用时,Go 会将其分配到堆内存中。
内存地址会根据机器的不同而有所不同,甚至相同的程序在不同的机器上执行后也会有不同的内存地址。因为每台机器可能有不同的存储器布局,并且位置分配也可能不同。
更复杂的数据通常会需要使用多个字,这些数据一般使用引用类型保存。
一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址(数字),或内存地址中第一个字所在的位置。

这个内存地址称之为指针,这个指针实际上也被存在另外的某一个值中。
同一个引用类型的指针指向的多个字可以是在连续的内存地址中(内存布局是连续的),这也是计算效率最高的一种存储形式;也可以将这些字分散存放在内存中,每个字都指示了下一个字所在的内存地址。
当使用赋值语句 r2 = r1 时,只有引用(地址)被复制。
如果 r1 的值被改变了,那么这个值的所有引用都会指向被修改后的内容,在这个例子中,r2 也会受到影响。
5. Go语言常量
5.1. 定义
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
常量的定义格式:
const identifier [type] = value
你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
- 显式类型定义:
const b string = "abc" - 隐式类型定义:
const b = "abc"
多个相同类型的声明可以简写为:
const c_name1, c_name2 = value1, value2
多重赋值:
const a, b, c = 1, false, "str"
常量还可以用作枚举:
const (
Unknown = 0 // 未知
Female = 1 // 女性
Male = 2 // 男性
)
常量可以用len(), cap(), unsafe.Sizeof()函数计算表达式的值。常量表达式中,函数必须是内置函数,否则编译不过:
package main
import "unsafe"
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(a)
)
func main() {
println(a, b, c) // abc 3 16
}
5.2. iota
iota,特殊常量,可以认为是一个可以被编译器修改的常量。
iota 在 const关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。
iota 可以被用作枚举值:
const (
a = iota
b = iota
c = iota
)
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const (
a = iota
b
c
)
用法:
package main
import (
"fmt"
)
func main() {
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
fmt.Println(a, b, c, d, e, f, g, h, i) // 0 1 2 ha ha 100 100 7 8
}
6. GO语言运算符
6.1. 算术运算符
假定 A 值为 10,B 值为 20

6.2. 关系运算符
假定 A 值为 10,B 值为 20
6.3. 逻辑运算符
假定 A 值为 True,B 值为 False

6.4. 位运算符
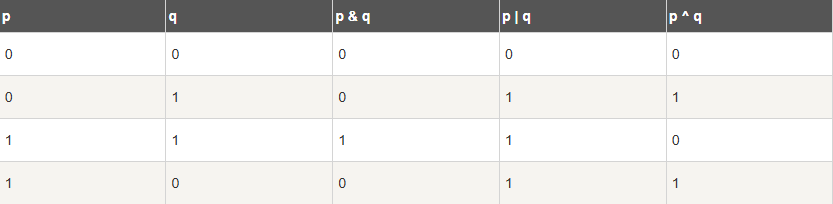
位运算符对整数在内存中的二进制位进行操作。
下表列出了位运算符 &(与), |(或), 和 ^(异或)的计算:
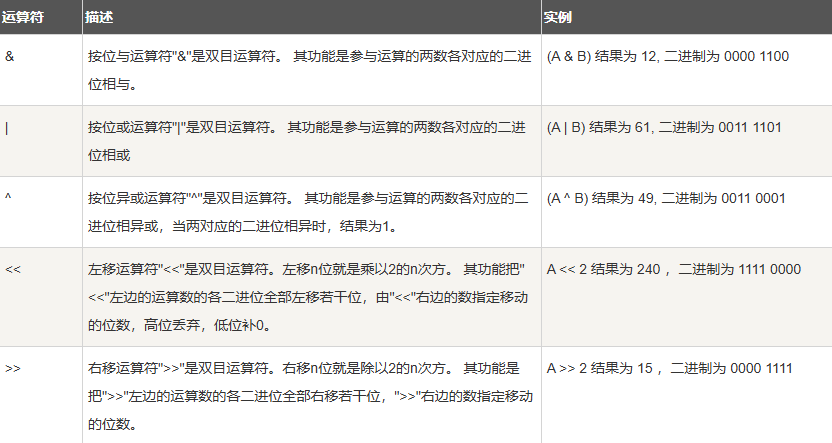
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
6.5. 赋值运算符
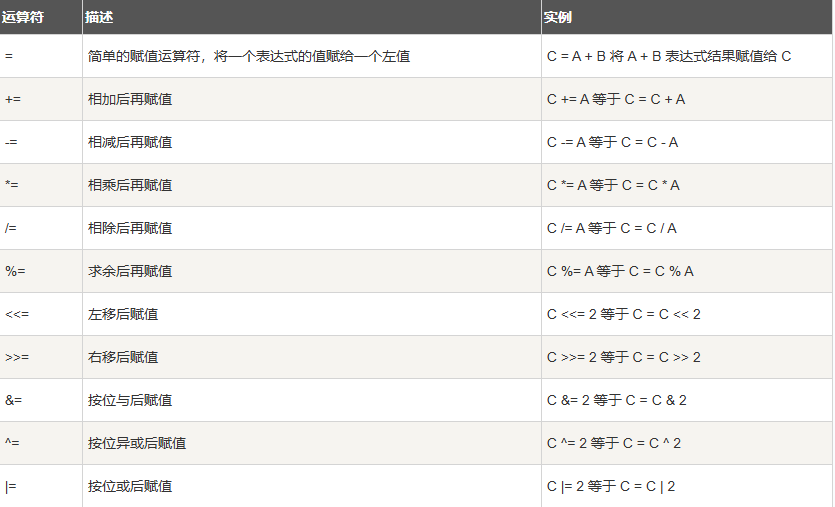
6.6. 其他运算符

package main
import "fmt"
func main() {
var a int = 4
var b int32
var c float32
var ptr *int
fmt.Printf("第 1 行 - a 变量类型为 = %T\n", a)
fmt.Printf("第 2 行 - b 变量类型为 = %T\n", b)
fmt.Printf("第 3 行 - c 变量类型为 = %T\n", c)
ptr = &a /* 'ptr' 包含了 'a' 变量的地址 */
fmt.Printf("a 的值为 %d\n", a) // 4
fmt.Printf("*ptr 为 %d\n", *ptr) // 4
}
6.7. 运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
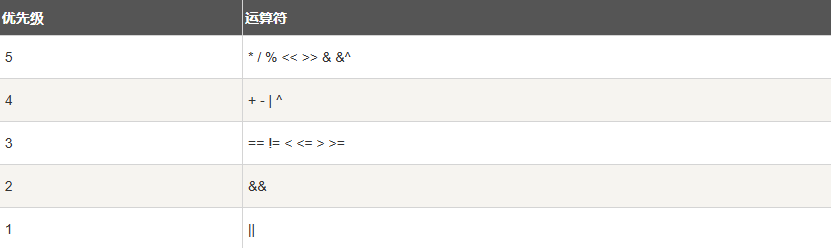
7. Go语言语句
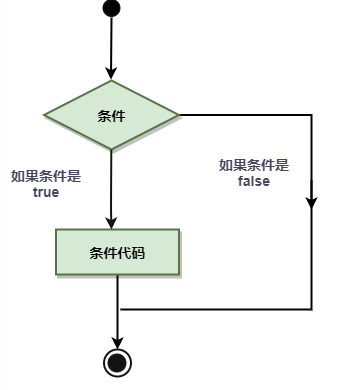
7.1. 条件语句
条件语句需要开发者通过指定一个或多个条件,并通过测试条件是否为 true 来决定是否执行指定语句,并在条件为 false 的情况在执行另外的语句。
注意:Go没有三目运算符!!!
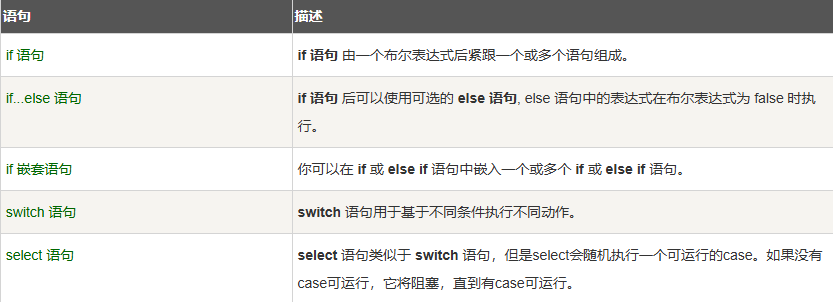
7.1.1. if语句
和其他语言没区别
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} else {
/* 在布尔表达式为 false 时执行 */
}
7.1.2. Switch语句
Go 编程语言中 switch 语句的语法如下:
switch var1 {
case val1:
...
case val2:
...
default:
...
}
变量 var1 可以是任何类型,而 val1 和 val2 则可以是同类型的任意值。类型不被局限于常量或整数,但必须是相同的类型;或者最终结果为相同类型的表达式。
使用 fallthrough 会强制执行后面的 case 语句,fallthrough 不会判断下一条 case 的表达式结果是否为 true。
7.1.3. Select语句
Go 编程语言中 select 语句的语法如下:
专门用于 通道(channel)通信的多路复用。它的作用有点像 switch,但每个 case 都是一个通道的操作(如接收、发送),只会执行其中一个可运行的分支。
select {
case msg1 := <-ch1:
fmt.Println("Received", msg1)
case msg2 := <-ch2:
fmt.Println("Received", msg2)
case ch3 <- 42:
fmt.Println("Sent 42 to ch3")
default:
fmt.Println("No channel is ready")
}
接收数据:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
go func() {
time.Sleep(1 * time.Second)
ch1 <- "from ch1"
}()
go func() {
time.Sleep(2 * time.Second)
ch2 <- "from ch2"
}()
select {
case msg := <-ch1:
fmt.Println(msg)
case msg := <-ch2:
fmt.Println(msg)
}
}
输出:一秒后会打印 from ch1,因为 ch1 更早 ready。
带default(非阻塞):
select {
case msg := <-ch1:
fmt.Println("Received:", msg)
default:
fmt.Println("Nothing ready")
}
如果 ch1 没准备好,直接走 default,不会阻塞。
超时控制:
select {
case msg := <-ch:
fmt.Println("Received:", msg)
case <-time.After(2 * time.Second):
fmt.Println("Timeout!")
}
如果 2 秒内没有消息,就打印超时。
7.2. 循环语句
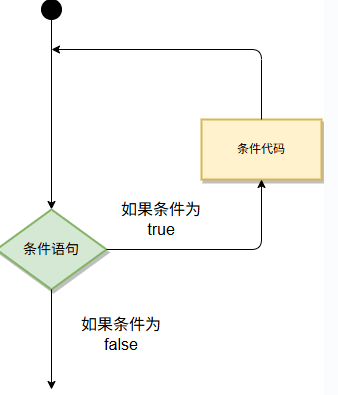

7.2.1. for循环
Go 语言的 For 循环有 3 种形式,只有其中的一种使用分号。
for init; condition; post { }
for condition { }
for { } // 无限循环
- init: 一般为赋值表达式,给控制变量赋初值;
- condition: 关系表达式或逻辑表达式,循环控制条件;
- post: 一般为赋值表达式,给控制变量增量或减量。
package main
import "fmt"
func main() {
for sum := 1; sum <= 10; {
sum += sum
}
fmt.Println(sum)
// 这样写也可以,更像 While 语句形式
for sum <= 10 {
sum += sum
}
fmt.Println(sum)
}
7.2.2. for … range循环
for … range 循环用于遍历数组、切片、字符串、map、channel。
for key, value := range collection {
// 使用 key 和 value
}
遍历数组/切片:
nums := []int{10, 20, 30}
for i, v := range nums {
fmt.Printf("下标: %d, 值: %d\n", i, v)
}
如果不需要索引,可以用 _ 忽略索引
遍历字符串(以 rune 为单位):
str := "你A好"
for i, ch := range str {
fmt.Printf("索引: %d, 字符: %c\n", i, ch)
}
注意:中文字符占 3 个字节,所以索引不是连续的。


| 单位 | 代表啥 | 用在哪 |
|---|---|---|
| byte | UTF-8编码的最小单位 | 用[]byte、len(str) 看字节长度 |
| rune | 表示一个Unicode字符 | 用for range遍历字符更准确 |
遍历map:
m := map[string]int{"apple": 5, "banana": 10, "cherry": 15}
for k, v := range m {
fmt.Printf("%s: %d\n", k, v)
}
遍历channel:
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
close(ch)
for v := range ch {
fmt.Println("收到:", v)
}
循环控制语句:可以控制循环体内语句的执行过程

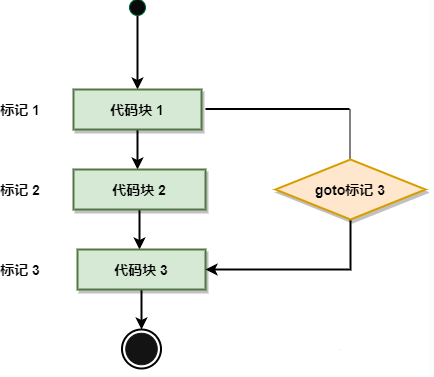
7.2.3. goto语句
Go 语言的 goto 语句可以无条件地转移到过程中指定的行。
goto 语句通常与条件语句配合使用。可用来实现条件转移, 构成循环,跳出循环体等功能。
但是,在结构化程序设计中一般不主张使用 goto 语句, 以免造成程序流程的混乱,使理解和调试程序都产生困难。
goto label;
..
.
label: statement;
package main
import "fmt"
func main() {
var a int = 10
LOOP:
for a < 12 {
if a == 11 {
a = a + 1
goto LOOP
}
fmt.Printf("value of a: %d\n", a) // value of a: 10
a++
}
}
8. Go语言函数
函数是基本的代码块,用于执行一个任务。
Go 语言最少有个 main() 函数。
你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。
函数声明告诉了编译器函数的名称,返回类型,和参数。
Go 语言标准库提供了多种可动用的内置的函数。例如,len() 函数可以接受不同类型参数并返回该类型的长度。如果我们传入的是字符串则返回字符串的长度,如果传入的是数组,则返回数组中包含的元素个数。
8.1. 函数定义
格式:
func function_name( [parameter list] ) [return_types] {
函数体
}
- func:函数由 func 开始声明
- function_name:函数名称,参数列表和返回值类型构成了函数签名。
- parameter list:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为实际参数。参数列表指定的是参数类型、顺序、及参数个数。参数是可选的,也就是说函数也可以不包含参数。
- return_types:返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值,这种情况下 return_types 不是必须的。
- 函数体:函数定义的代码集合。
8.2. 函数调用
当创建函数时,你定义了函数需要做什么,通过调用该函数来执行指定任务。
调用函数,向函数传递参数,并返回值,例如:
package main
import "fmt"
func main() {
var a int = 100
var b int = 200
var ret int
ret = max(a, b)
fmt.Println("Max value is ", ret) // 200
}
/* 返回两个数的最大值 */
func max(num1, num2 int) int {
var result int
if num1 > num2 {
result = num1
} else {
result = num2
}
return result
}
8.3. 函数参数
函数如果使用参数,该变量可称为函数的形参。
形参就像定义在函数体内的局部变量。
调用函数,可以通过两种方式来传递参数:

8.3.1. 值传递
传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
/* 定义相互交换值的函数 */
func swap(x, y int) int {
var temp int
temp = x /* 保存 x 的值 */
x = y /* 将 y 值赋给 x */
y = temp /* 将 temp 值赋给 y*/
return temp;
}
8.3.2. 引用传递
引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
/* 定义交换值函数*/
func swap(x *int, y *int) {
var temp int
temp = *x /* 保持 x 地址上的值 */
*x = *y /* 将 y 值赋给 x */
*y = temp /* 将 temp 值赋给 y */
}
// 指针作为函数参数
package main
import "fmt"
func main() {
var a int = 100
var b int = 200
fmt.Printf("交换前,a的值:%d\n", a) // 100
fmt.Printf("交换前,b的值:%d\n", b) // 200
swap(&a, &b)
fmt.Printf("交换后,a的值:%d\n", a) // 200
fmt.Printf("交换后,b的值:%d\n", b) // 100
}
func swap(x *int, y *int) {
var temp int
temp = *x
*x = *y
*y = temp
}
8.4. 函数用法

8.4.1. 函数作为实参
Go 语言可以很灵活的创建函数,并作为另外一个函数的实参。以下实例中我们在定义的函数中初始化一个变量,该函数仅仅是为了使用内置函数 math.sqrt(),实例为:
package main
import (
"fmt"
"math"
)
func main() {
getSquareRoot := func(x float64) float64 {
return math.Sqrt(x)
}
fmt.Println(getSquareRoot(9)) // 3
}
8.4.2. 匿名函数
匿名函数只能在函数内部存在,匿名函数可以简单理解为没有名称的函数,例如:
func main() {
func(a, b int) int {
return a + b
}(1, 2)
}
或者当函数参数是一个函数类型时,这时名称不再重要,可以直接传递一个匿名函数
func main() {
DoSum(1, 2, func(a int, b int) int {
return a + b
})
}
func DoSum(a, b int, f func(int, int) int) int {
return f(a, b)
}
8.4.3. 闭包
Go 语言支持匿名函数,可作为闭包。匿名函数是一个"内联"语句或表达式。匿名函数的优越性在于可以直接使用函数内的变量,不必申明。
匿名函数是一种没有函数名的函数,通常用于在函数内部定义函数,或者作为函数参数进行传递。
闭包 = 函数 + 外部变量的引用
以下实例中,我们创建了函数 getSequence() ,返回另外一个函数。该函数的目的是在闭包中递增 i 变量,独立的闭包,互不干扰,每个都有自己的 i 值,代码如下:
package main
import "fmt"
func main() {
nextNumber := getSequence()
fmt.Println(nextNumber()) // 1
fmt.Println(nextNumber()) // 2
fmt.Println(nextNumber()) // 3
nextNumber2 := getSequence()
fmt.Println(nextNumber2()) // 1
fmt.Println(nextNumber2()) // 2
}
func getSequence() func() int {
i := 0
return func() int {
i += 1
return i
}
}
8.4.4. defer延迟调用
- 关键字 defer 用于注册延迟调用
- 这些调用直到 return 前才被执。因此,可以用来做资源清理
- 多个defer语句,按先进后出的方式执行
- defer语句中的变量,在defer声明时就决定了
defer是后进先出:
func main() {
var whatever [5]struct{}
for i := range whatever {
defer fmt.Println(i) // 4 3 2 1 0
}
}
defer碰上闭包:
func main() {
var whatever [5]struct{}
for i := range whatever {
defer func() {
fmt.Println(i) // 4 3 2 1 0
}()
}
}
8.4.5. 方法
Go 语言中同时有函数和方法。一个方法就是一个包含了接受者的函数,接受者可以是命名类型或者结构体类型的一个值或者是一个指针。所有给定类型的方法属于该类型的方法集。语法格式如下:
func (variable_name variable_data_type) function_name() [return_type]{
/* 函数体*/
}
-
receiver_name:接收者变量名(你可以随便命名,一般是缩写,比如 u、p 等)
-
receiver_type:接收者的类型(可以是结构体,也可以是其他自定义类型)
-
method_name():方法名
-
[return_type]:返回值类型(可选)
package main
import "fmt"
type Circle struct {
radius float64
}
func main() {
var c1 Circle
c1.radius = 10.00
fmt.Println("Circle Area:", c1.getArea()) // Circle Area: 314
}
// 该 method 属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
return 3.14 * c.radius * c.radius
}
9. Go语言变量作用域
作用域为已声明标识符所表示的常量、类型、变量、函数或包在源代码中的作用范围。
Go 语言中变量可以在三个地方声明:
- 函数内定义的变量称为局部变量
- 函数外定义的变量称为全局变量
- 函数定义中的变量称为形式参数
接下来让我们具体了解局部变量、全局变量和形式参数。
9.1. 局部变量
在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,参数和返回值变量也是局部变量。
以下实例中 main() 函数使用了局部变量 a, b, c:
func main() {
/* 声明局部变量 */
var a, b, c int
}
9.2. 全局变量
在函数体外声明的变量称之为全局变量,全局变量可以在整个包甚至外部包(被导出后)使用。
全局变量可以在任何函数中使用,以下实例演示了如何使用全局变量:
/* 声明全局变量 */
var g int
func main() {
/* 声明局部变量 */
var a, b int
}
Go 语言程序中全局变量与局部变量名称可以相同,但是函数内的局部变量会被优先考虑。
9.3. 形式参数
形式参数会作为函数的局部变量来使用
package main
import "fmt"
/* 声明全局变量 */
var a int = 20;
func main() {
/* main 函数中声明局部变量 */
var a int = 10
var b int = 20
var c int = 0
fmt.Printf("main()函数中 a = %d\n", a); // 10
c = sum(a, b);
fmt.Printf("main()函数中 c = %d\n", c); // 30
}
/* 函数定义-两数相加 */
func sum(a, b int) int {
fmt.Printf("sum() 函数中 a = %d\n", a); // 10
fmt.Printf("sum() 函数中 b = %d\n", b); // 20
return a + b;
}
9.4. 初始化局部和全局变量
不同类型的局部和全局变量默认值为:

10. Go语言数组
Go 语言提供了数组类型的数据结构。
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
相对于去声明 number0, number1, …, number99 的变量,使用数组形式 numbers[0], numbers[1] …, numbers[99] 更加方便且易于扩展。
数组元素可以通过索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推。

10.1. 声明数组
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var arrayName [size]dataType
其中,arrayName 是数组的名称,size 是数组的大小,dataType 是数组中元素的数据类型。
以下定义了数组 balance 长度为 10 类型为 float32:
var balance [10]float32
10.2. 初始化数组
以下实例声明一个名为 numbers 的整数数组,其大小为 5,在声明时,数组中的每个元素都会根据其数据类型进行默认初始化,对于整数类型,初始值为 0。
var numbers [5]int
还可以使用初始化列表来初始化数组的元素:
var numbers = [5]int{1, 2, 3, 4, 5}
以上代码声明一个大小为 5 的整数数组,并将其中的元素分别初始化为 1、2、3、4 和 5。
另外,还可以使用 := 简短声明语法来声明和初始化数组:
numbers := [5]int{1, 2, 3, 4, 5}
以上代码创建一个名为 numbers 的整数数组,并将其大小设置为 5,并初始化元素的值。
注意:在 Go 语言中,数组的大小是类型的一部分,因此不同大小的数组是不兼容的,也就是说 [5]int 和 [10]int 是不同的类型。
以下定义了数组 balance 长度为 5 类型为 float32,并初始化数组的元素:
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
也可以通过字面量在声明数组的同时快速初始化数组:
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果数组长度不确定,可以使用 … 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
或
balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 1 和 3 的元素初始化
balance := [5]float32{1:2.0, 3:7.0}
初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
balance[4] = 50.0
以上实例读取了第五个元素。数组元素可以通过索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推。

10.3. 访问数组元素
数组元素可以通过索引(位置)来读取。格式为数组名后加中括号,中括号中为索引的值。例如:
// 读取了数组 balance 第 10 个元素的值
var salary float32 = balance[9]
package main
import "fmt"
func main() {
var n [10]int
var i, j int
for i = 0; i < 10; i++ {
n[i] = i + 100
}
for j = 0; j < 10; j++ {
fmt.Printf("Element[%d] = %d\n", j, n[j])
}
}
10.4. 多维数组
Go 语言支持多维数组,以下为常用的多维数组声明方式:
var variable_name [SIZE1][SIZE2]...[SIZEN] variable_type
10.5. 二维数组
定义方式如下:
var arrayName [x][y] variable_type
variable_type 为 Go 语言的数据类型,arrayName 为数组名,二维数组可认为是一个表格,x 为行,y 为列,下图演示了一个二维数组 a 为三行四列:

package main
import "fmt"
func main() {
// Step 1: 创建数组
values := [][]int{}
// Step 2: 使用 append() 函数向空的二维数组添加两行一维数组
row1 := []int{1, 2, 3}
row2 := []int{4, 5, 6}
values = append(values, row1)
values = append(values, row2)
// Step 3: 显示两行数据
fmt.Println("Row 1")
fmt.Println(values[0])
fmt.Println("Row 2")
fmt.Println(values[1])
// Step 4: 访问第一个元素
fmt.Println("第一个元素为:")
fmt.Println(values[0][0])
}
初始化二维数组: 多维数组可通过大括号来初始值
package main
import "fmt"
func main() {
a := [2][2]int{
{1, 2},
{3, 4},
}
fmt.Println(a) // [[1 2] [3 4]]
sites := [2][2]string{}
sites[0][0] = "Google"
sites[0][1] = "Runoob"
sites[1][0] = "Taobao"
sites[1][1] = "Weibo"
fmt.Println(sites) // [[Google Runoob] [Taobao Weibo]]
}
访问二维数组: 二维数组通过指定坐标来访问。如数组中的行索引与列索引,例如:
val := a[2][3]
或
var value int = a[2][3]
10.6. 向函数传递数组
Go 语言中的数组是值类型,因此在将数组传递给函数时,实际上是传递数组的副本。
如果你想向函数传递数组参数,你需要在函数定义时,声明形参为数组,我们可以通过以下两种方式来声明:
- 形参设定数组大小:
func myFunction(param [10]int) { .... } - 形参未设定数组大小:
func myFunction(param []int) { .... }
如果你想要在函数内修改原始数组,可以通过传递数组的指针来实现。
package main
import "fmt"
func main() {
a := [3]int{1, 2, 3}
modifyArray(&a)
fmt.Println(a) // [100 2 3]
}
func modifyArray(arr *[3]int) {
(*arr)[0] = 100
}
11. Go语言指针
变量是一种使用方便的占位符,用于引用计算机内存地址。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
以下实例演示了变量在内存中地址:
var a int = 10
fmt.Printf("%x\n", &a) // c00000a108
11.1. 什么是指针
一个指针变量指向了一个值的内存地址。
类似于变量和常量,在使用指针前你需要声明指针。指针声明格式如下:
var var_name *var-type
var-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。
11.2. 如何使用指针
指针使用流程:
- 定义指针变量。
- 为指针变量赋值。
- 访问指针变量中指向地址的值。
在指针类型前面加上 * 号(前缀)来获取指针所指向的内容。
package main
import "fmt"
func main() {
var a int = 20
var ip *int
ip = &a
fmt.Printf("a 变量的地址是:%x\n", &a) // c00000a108
/* 指针变量的存储地址 */
fmt.Printf("ip 变量储存的指针地址:%x\n", ip) // c00000a108
/* 使用指针访问值 */
fmt.Printf("*ip 变量的值是:%d\n", *ip) // 20
}
11.3. 空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
nil 指针也称为空指针。
nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
一个指针变量通常缩写为 ptr。
var ptr *int
fmt.Println("ptr is", ptr) // ptr is <nil>
11.4. 指针数组
声明整型指针数组:
var ptr [MAX]*int
ptr 为整型指针数组。因此每个元素都指向了一个值。以下实例的三个整数将存储在指针数组中:
package main
import "fmt"
const MAX int = 3
func main() {
a := []int{10, 100, 200}
var i int
var ptr [MAX]*int
for i = 0; i < MAX; i++ {
ptr[i] = &a[i] // 整数地址赋值给指针数组
}
for i = 0; i < MAX; i++ {
fmt.Printf("a[%d] = %d\n", i, *ptr[i])
}
}
11.5. 指向指针的指针
如果一个指针变量存放的又是另一个指针变量的地址,则称这个指针变量为指向指针的指针变量。
当定义一个指向指针的指针变量时,第一个指针存放第二个指针的地址,第二个指针存放变量的地址:

格式:
var ptr **int
package main
import "fmt"
func main() {
a := 300
var ptr *int
var pptr **int
// 指针ptr指向a
ptr = &a
// 指向指针pptr指向ptr
pptr = &ptr
fmt.Printf("变量a = %d\n", a) // 300
fmt.Printf("指针变量 *ptr = %d\n", *ptr) // 300
fmt.Printf("指向指针的指针变量 **pptr = %d\n", **pptr) // 300
}
12. Go语言结构体
Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型。
结构体是由一系列具有相同类型或不同类型的数据构成的数据集合。
结构体表示一项记录,比如保存图书馆的书籍记录,每本书有以下属性:
- Title :标题
- Author : 作者
- Subject:学科
- ID:书籍ID
12.1. 定义结构体
结构体定义需要使用 type 和 struct 语句。struct 语句定义一个新的数据类型,结构体中有一个或多个成员。type 语句设定了结构体的名称。结构体的格式如下:
type struct_variable_type struct {
member definition
member definition
...
member definition
}
一旦定义了结构体类型,它就能用于变量的声明,语法格式如下:
variable_name := structure_variable_type {value1, value2...valuen}
或
variable_name := structure_variable_type { key1: value1, key2: value2..., keyn: valuen}
package main
import "fmt"
type Books struct {
bookId int
title string
author string
subject string
}
func main() {
// 创建一个结构体
fmt.Println(Books{1, "Go语言", "www.runoob.com", "Go语言教程"})
// 创建一个结构体(key => value 格式)
fmt.Println(Books{bookId: 1, title: "Go语言", author: "www.runoob.com", subject: "Go语言教程"})
// 忽略的字段为 0 或 空
fmt.Println(Books{bookId: 1, title: "Go语言"})
}
12.2. 访问结构体成员
如果要访问结构体成员,需要使用点号 . 操作符,格式为:
结构体.成员名
结构体类型变量使用 struct 关键字定义,实例如下:
func main() {
var Book Books
Book.bookId = 123
Book.title = "Go Programming"
Book.author = "Mahesh Kumar"
Book.subject = "Go Programming Tutorial"
fmt.Printf("Book Id : %d\n", Book.bookId) // Book Id : 123
}
12.3. 结构体作为函数参数
func main() {
var Book Books
Book.bookId = 123
Book.title = "Go Programming"
Book.author = "Mahesh Kumar"
Book.subject = "Go Programming Tutorial"
printBook(Book)
}
func printBook(book Books) {
fmt.Printf("Book Id : %d\n", book.bookId) // Book Id : 123
fmt.Printf("Book title : %s\n", book.title) // Book title : Go Programming
fmt.Printf("Book author : %s\n", book.author) // Book author : Mahesh Kumar
fmt.Printf("Book subject : %s\n", book.subject) // Book subject : Go Programming Tutorial
}
12.4. 结构体指针
可以定义指向结构体的指针类似于其他指针变量,格式如下:
var struct_pointer *Books
以上定义的指针变量可以存储结构体变量的地址。查看结构体变量地址,可以将 & 符号放置于结构体变量前:
struct_pointer = &Book
使用结构体指针访问结构体成员,使用 “.” 操作符:
struct_pointer.title
13. Go语言切片
Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
13.1. 定义切片
可以声明一个未指定大小的数组来定义切片:
var identifier []type
切片不需要说明长度。
或使用 make() 函数来创建切片:
var slice1 []type = make([]type, len)
// 简写
slice1 := make([]type, len)
也可以指定容量,其中 capacity 为可选参数
make([]T, length, capacity)
这里 len 是数组的长度并且也是切片的初始长度。
13.2. 切片初始化
直接初始化切片,[] 表示是切片类型,{1,2,3} 初始化值依次是 1,2,3,其 cap=len=3
s :=[] int {1,2,3 }
初始化切片 s,是数组 arr 的引用
s := arr[:]
将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片
s := arr[startIndex:endIndex]
默认 endIndex 时将表示一直到arr的最后一个元素
s := arr[startIndex:]
默认 startIndex 时将表示从 arr 的第一个元素开始
s := arr[:endIndex]
通过切片 s 初始化切片 s1
s1 := s[startIndex:endIndex]
通过内置函数 make() 初始化切片s,[]int 标识为其元素类型为 int 的切片
s :=make([]int, len, cap)
13.3. len() 和 cap()函数
切片是可索引的,并且可以由 len() 方法获取长度。
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少。
以下为具体实例:
package main
import "fmt"
func main() {
var numbers = make([]int, 3, 5)
printSlice(numbers)
}
func printSlice(x []int) {
fmt.Printf("len=%d cap=%d slice=%v\n", len(x), cap(x), x) // len=3 cap=5 slice=[0 0 0]
}
13.4. 空切片
一个切片在未初始化之前默认为 nil,长度为 0,实例如下:
func main() {
var numbers []int
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x) // len=0 cap=0 slice=[]
}
13.5. 切片截取
可以通过设置下限及上限来设置截取切片 [lower-bound:upper-bound],实例如下:
package main
import "fmt"
func main() {
numbers := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
printSlice(numbers)
// 打印从索引1(包含)到索引4(不包含)
fmt.Println(numbers[1:4]) // [1 2 3]
// 默认下限为 0
fmt.Println(numbers[:3]) // [0 1 2]
// 默认上限为 len(s)
fmt.Println(numbers[4:]) // [4 5 6 7 8 9]
}
func printSlice(x []int) {
fmt.Printf("len=%d cap=%d slice=%v\n", len(x), cap(x), x) // len=0 cap=0 slice=[]
}
13.6. append() 和 copy()函数
如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来。
下面的代码描述了从拷贝切片的 copy 方法和向切片追加新元素的 append 方法。
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers) // len=0 cap=0 slice=[]
// 允许追加空切片
numbers = append(numbers, 0)
printSlice(numbers) // len=1 cap=1 slice=[0]
// 追加多个元素
numbers = append(numbers, 1, 2, 3, 4)
printSlice(numbers) // len=5 cap=6 slice=[0 1 2 3 4]
// 创建切片 numbers2 是之前切片的两倍容量
numbers2 := make([]int, len(numbers), (cap(numbers))*2)
// 拷贝 numbers 的内容到 numbers2
copy(numbers2, numbers)
printSlice(numbers2) // len=5 cap=12 slice=[0 1 2 3 4]
}
func printSlice(x []int) {
fmt.Printf("len=%d cap=%d slice=%v\n", len(x), cap(x), x)
}
14. Go语言范围(range)
Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
for key, value := range oldMap {
newMap[key] = value
}
以上代码中的 key 和 value 是可以省略。
如果只想读取其中一个,格式如下:
// 只读取key
for key := range oldMap
// 或者
for key, _ := range oldMap
// 只读取value
for _, value := range oldMap
14.1. 数组和切片
遍历简单的切片,2**%d 的结果为 2 对应的次方数:
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
14.2. 字符串
range 迭代字符串时,返回每个字符的索引和 Unicode 代码点(rune)。
func main() {
for i, c := range "hello" {
fmt.Printf("index: %d, char: %c\n", i, c)
}
}
14.3. 映射(Map)
for 循环的 range 格式可以省略 key 和 value,如下实例:
func main() {
map1 := make(map[int]float32)
map1[1] = 1.0
map1[2] = 2.0
map1[3] = 3.0
map1[4] = 4.0
for key, value := range map1 {
fmt.Printf("Key: %d, Value: %f\n", key, value)
}
}
14.4. 通道(Channel)
range 遍历从通道接收的值,直到通道关闭。
func main() {
ch := make(chan int, 2)
ch <- 1
ch <- 2
close(ch)
for v := range ch {
fmt.Println(v)
}
}
14.5. 忽略值
在遍历时可以使用 _ 来忽略索引或值。
func main() {
nums := []int{2, 3, 4}
// 忽略索引
for _, num := range nums {
fmt.Println("value:", num)
}
// 忽略值
for i := range nums {
fmt.Println("index:", i)
}
}
15. Go语言Map(集合)
Map 是一种无序的键值对的集合。
Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,遍历 Map 时返回的键值对的顺序是不确定的。
在获取 Map 的值时,如果键不存在,返回该类型的零值,例如 int 类型的零值是 0,string 类型的零值是 “”。
Map 是引用类型,如果将一个 Map 传递给一个函数或赋值给另一个变量,它们都指向同一个底层数据结构,因此对 Map 的修改会影响到所有引用它的变量。
定义map:
可以使用内建函数 make 或使用 map 关键字来定义 Map:
/* 使用 make 函数 */
map_variable := make(map[KeyType]ValueType, initialCapacity)
- KeyType 是键的类型
- ValueType 是值的类型
- initialCapacity 是可选的参数,用于指定 Map 的初始容量
Map 的容量是指 Map 中可以保存的键值对的数量,当 Map 中的键值对数量达到容量时,Map 会自动扩容。如果不指定 initialCapacity,Go 语言会根据实际情况选择一个合适的值。
// 创建一个空的 Map
m := make(map[string]int)
// 创建一个初始容量为 10 的 Map
m := make(map[string]int, 10)
也可以使用字面量创建 Map:
m := map[string]int{
"apple": 1,
"banana": 2,
"orange": 3,
}
获取元素:
// 获取键值对
v1 := m["apple"]
v2, ok := m["pear"] // 如果键不存在,ok 的值为 false,v2 的值为该类型的零值
修改元素:
// 修改键值对
m["apple"] = 5
获取 Map 的长度:
// 获取 Map 的长度
len := len(m)
遍历 Map:
// 遍历 Map
for k, v := range m {
fmt.Printf("key=%s, value=%d\n", k, v)
}
删除元素:
// 删除键值对
delete(m, "banana")
func main() {
siteMap := make(map[string]string)
siteMap["Google"] = "谷歌"
siteMap["Baidu"] = "百度"
siteMap["Yahoo"] = "雅虎"
for site := range siteMap {
fmt.Println(site, siteMap[site])
}
// 查看集合是否存在该元素
name, ok := siteMap["Facebook"]
if ok {
fmt.Println(name)
} else {
fmt.Println("Facebook not found")
}
}
16. Go语言递归函数
递归,就是在运行的过程中调用自己。
语法格式如下:
func recursion() {
recursion() /* 函数调用自身 */
}
func main() {
recursion()
}
Go 语言支持递归。但我们在使用递归时,开发者需要设置退出条件,否则递归将陷入无限循环中。
递归函数对于解决数学上的问题是非常有用的,就像计算阶乘,生成斐波那契数列等。
通过 Go 语言的递归函数实例阶乘:
package main
import "fmt"
func main() {
i := 3
fmt.Println(Factorial(uint64(i))) // 6
}
func Factorial(n uint64) (result uint64) {
if n > 0 {
result = n * Factorial(n-1)
return result
}
return 1
}
17. Go语言类型转换
类型转换用于将一种数据类型的变量转换为另外一种类型的变量。
Go 语言类型转换基本格式如下:
type_name(expression)
- type_name 为类型
- expression 为表达式
17.1. 数值类型转换
将整型转换为浮点型:
var a int = 10
var b float64 = float64(a)
以下实例中将整型转化为浮点型,并计算结果,将结果赋值给浮点型变量:
func main() {
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum) / float32(count)
fmt.Printf("mean 的值为: %f\n", mean) // 3.400000
}
17.2. 字符串类型转换
字符串转为整数:
func main() {
// 字符串转换为整数
str := "123"
num, err := strconv.Atoi(str)
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("字符串 '%s' 转换为整数为:%d\n", str, num) // 字符串 '123' 转换为整数为:123
}
}
注意,strconv.Atoi 函数返回两个值,第一个是转换后的整型值,第二个是可能发生的错误,我们可以使用空白标识符 _ 来忽略这个错误
整数转为字符串:
func main() {
num := 123
str := strconv.Itoa(num)
fmt.Printf("整数 %d 转换为字符串为:'%s'\n", num, str) // 整数 123 转换为字符串为:'123'
}
字符串转为浮点数:
func main() {
str := "3.14"
num, err := strconv.ParseFloat(str, 64)
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("字符串 '%s' 转为浮点型为:%f\n", str, num) // 字符串 '3.14' 转为浮点型为:3.140000
}
}
浮点数转为字符串:
func main() {
num := 3.14
str := strconv.FormatFloat(num, 'f', 2, 64)
fmt.Printf("浮点数 %f 转为字符串为:'%s'\n", num, str) // 浮点数 3.140000 转为字符串为:'3.14'
}
17.3. 接口类型转换
接口类型转换有两种情况:类型断言和类型转换。
17.3.1. 类型断言
类型断言用于将接口类型转换为指定类型,其语法为:
value.(type)
// 或者
value.(T)
其中 value 是接口类型的变量,type 或 T 是要转换成的类型。
如果类型断言成功,它将返回转换后的值和一个布尔值,表示转换是否成功。
func main() {
var i interface{} = "hello, world"
str, ok := i.(string)
if ok {
fmt.Println(str) // "hello, world"
} else {
fmt.Println("i is not a string")
}
}
以上实例中,我们定义了一个接口类型变量 i,并将它赋值为字符串 “Hello, World”。然后,我们使用类型断言将 i 转换为字符串类型,并将转换后的值赋值给变量 str。最后,我们使用 ok 变量检查类型转换是否成功,如果成功,我们打印转换后的字符串;否则,我们打印转换失败的消息。
17.3.2. 类型转换
类型转换用于将一个接口类型的值转换为另一个接口类型,其语法为:
T(value)
T 是目标接口类型,value 是要转换的值。
在类型转换中,我们必须保证要转换的值和目标接口类型之间是兼容的,否则编译器会报错。
package main
import "fmt"
// 定义一个接口 Writer,在接口里定义Write方法
type Writer interface {
Write([]byte) (int, error)
}
// 实现 Writer接口的结构体 StringWriter
type StringWriter struct {
str string
}
// 实现 Write 方法
func (sw *StringWriter) Write(data []byte) (int, error) {
sw.str += string(data)
return len(data), nil
}
func main() {
// 创建一个 StringWriter 实例并赋值给 Writer 接口变量
var w Writer = &StringWriter{}
// 将 Writer 接口类型转换为 StringWriter 类型
sw := w.(*StringWriter)
// 修改 StringWriter 实例的 str 字段
sw.str = "Hello, World!"
// 输出修改后的 str 字段
fmt.Println(sw.str) // Hello, World!
}
17.3.3. 空接口类型
空接口 interface{} 可以持有任何类型的值。在实际应用中,空接口经常被用来处理多种类型的值。
func printValue(v interface{}) {
switch v := v.(type) {
case int:
fmt.Println("Integer:", v)
case string:
fmt.Println("String:", v)
default:
fmt.Println("Unknown type")
}
}
func main() {
printValue(42) // Integer: 42
printValue("hello") // String: hello
printValue(3.14) // Unknown type
}
在这个例子中,printValue 函数接受一个空接口类型的参数,并使用类型断言和类型选择来处理不同的类型。
18. Go语言接口
接口(interface)是 Go 语言中的一种类型,用于定义行为的集合,它通过描述类型必须实现的方法,规定了类型的行为契约。
Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。
Go 的接口设计简单却功能强大,是实现多态和解耦的重要工具。
接口可以让我们将不同的类型绑定到一组公共的方法上,从而实现多态和灵活的设计。
18.1. 特点
隐式实现:
- Go 中没有关键字显式声明某个类型实现了某个接口。
- 只要一个类型实现了接口要求的所有方法,该类型就自动被认为实现了该接口。
接口类型变量:
- 接口变量可以存储实现该接口的任意值。
- 接口变量实际上包含了两个部分:
- 动态类型:存储实际的值类型。
- 动态值:存储具体的值。
零值接口:
- 接口的零值是 nil。
- 一个未初始化的接口变量其值为 nil,且不包含任何动态类型或值。
空接口:
定义为 interface{},可以表示任何类型。
常见用法:
多态:不同类型实现同一接口,实现多态行为。
解耦:通过接口定义依赖关系,降低模块之间的耦合。
泛化:使用空接口 interface{} 表示任意类型。
18.2. 定义和实现
接口定义使用关键字 interface,其中包含方法声明。
/* 定义接口 */
type interface_name interface {
method_name1 [return_type]
method_name2 [return_type]
method_name3 [return_type]
...
method_namen [return_type]
}
/* 定义结构体 */
type struct_name struct {
/* variables */
}
/* 实现接口方法 */
func (struct_name_variable struct_name) method_name1() [return_type] {
/* 方法实现 */
}
...
func (struct_name_variable struct_name) method_namen() [return_type] {
/* 方法实现*/
}
package main
import (
"fmt"
"math"
)
// Shape 定义接口
type Shape interface {
Area() float64
Perimeter() float64
}
// Circle 定义结构体
type Circle struct {
Radius float64
}
// Circle 实现 Shape接口
func (c Circle) Area() float64 {
return math.Pi * c.Radius * c.Radius
}
func (c Circle) Perimeter() float64 {
return 2 * math.Pi * c.Radius
}
func main() {
c := Circle{Radius: 5}
var s Shape = c // 接口变量可以接收任何实现了接口的实例
fmt.Println("Area", s.Area())
fmt.Println("Perimeter", s.Perimeter())
}
18.3. 空接口
空接口 interface{} 是 Go 的特殊接口,表示所有类型的超集。
- 任意类型都实现了空接口。
- 常用于需要存储任意类型数据的场景,如泛型容器、通用参数等。
var a interface{}
a = 10 // int
a = "hello" // string
a = true // bool
a = []int{1,2} // slice
18.4. 类型断言
类型断言用于从接口类型中提取其底层值。
基本语法:
value := iface.(Type)
- iface 是接口变量。
- Type 是要断言的具体类型。
- 如果类型不匹配,会触发 panic。
var i interface{} = "hello"
str := i.(string) // 如果不是string类型,就报错
fmt.Println(str)
带检查的类型断言:
为了避免 panic,可以使用带检查的类型断言:
value, ok := iface.(Type)
- ok 是一个布尔值,表示断言是否成功。
- 如果断言失败,value 为零值,ok 为 false。
var i interface{} = 42
// if 初始化语句; 条件判断
if str, ok := i.(string); ok {
fmt.Println("String", str)
} else {
fmt.Println("Not a string")
}
18.5. 接口组合
接口可以通过嵌套组合,实现更复杂的行为描述。
package main
import "fmt"
type Reader interface {
Read() string
}
type Writer interface {
Write(string)
}
type ReadWriter interface {
Reader
Writer
}
type File struct{}
func (f File) Read() string {
return "Reading data"
}
func (f File) Write(data string) {
fmt.Println("Writing data:", data)
}
func main() {
var rw ReadWriter = File{}
fmt.Println(rw.Read()) // Reading data
rw.Write("Hello, World!") // Writing data: Hello, World!
}
18.6. 动态值和动态类型
接口变量实际上包含了两部分:
- 动态类型:接口变量存储的具体类型。
- 动态值:具体类型的值。
动态值和动态类型示例:
var i interface{} = 42
fmt.Printf("Dynamic type: %T, Dynamic value: %v\n", i, i) // int 42
18.7. 接口的零值
接口的零值是 nil。
当接口变量的动态类型和动态值都为 nil 时,接口变量为 nil。
接口零值示例:
var i interface{}
fmt.Println(i == nil) // 输出:true
19. Go泛型
19.1. 类型参数声明
在函数、结构体或方法中使用 [T 约束] 声明泛型类型参数:
- 函数泛型:
func 函数名[T 约束](参数 T) 返回值 T { // 逻辑 } - 结构体泛型:
type 结构体名[T 约束] struct { 字段 T } - 接口约束:
type 约束接口 interface { int | string | float64 // 允许的类型集合 }
19.2. 类型约束
通过接口定义类型参数允许的类型:
- 简单类型集合:
type Numeric interface { int | float64 | uint } - 支持方法的约束(约束可以包含方法):
type Stringer interface { String() string }
19.3. 泛型函数
package main
import "fmt"
type Number interface {
int | float64
}
func Sum[T Number](slice []T) T {
var sum T
for _, v := range slice {
sum += v
}
return sum
}
func main() {
nums := []int{1, 2, 3, 4, 5}
fmt.Println(Sum(nums)) // 15
}
19.4. 泛型结构体
通用栈:
package main
import "fmt"
type Stack[T any] struct {
elements []T
}
// 入栈
func (s *Stack[T]) Push(v T) {
s.elements = append(s.elements, v)
}
// 出栈
func (s *Stack[T]) Pop() T {
if len(s.elements) == 0 {
panic("Stack is empty")
}
v := s.elements[len(s.elements)-1]
s.elements = s.elements[:len(s.elements)-1]
return v
}
func main() {
s := Stack[string]{}
s.Push("Go")
s.Push("Generics")
fmt.Println(s.Pop()) // Generics
}
19.5. 泛型方法
Go 中方法的接收者可以带泛型,但方法自身不能声明泛型参数:
package main
import "fmt"
type Box[T any] struct {
Content T
}
// 接收者带泛型的方法
func (b *Box[T]) Replace(newValue T) {
b.Content = newValue
}
func main() {
b := Box[int]{Content: 42}
b.Replace(100)
fmt.Println(b.Content) // 100
}
19.6. 多类型参数
泛型支持多个类型参数:
// 交换两个值
func Swap[T1, T2 any](a T1, b T2) (T2, T1) {
return b, a
}
func main() {
x, y := Swap(10, "hello")
fmt.Println(x, y) // 输出 "hello 10"
}
19.7. 联合类型约束
允许类型参数是多个类型的其中之一:
type NumericOrString interface {
int | float64 | string
}
func PrintValue[T NumericOrString](v T) {
fmt.Println(v)
}
func main() {
PrintValue(123) // 输出 123
PrintValue("hello") // 输出 hello
}
19.8. 约束中的方法
约束可以要求类型必须实现某些方法:
type Cloner[T any] interface {
Clone() T
}
func Duplicate[T Cloner[T]](original T) T {
return original.Clone()
}
// 实现 Clone 方法的类型
type MyStruct struct {
Data string
}
func (m MyStruct) Clone() MyStruct {
return MyStruct{Data: m.Data}
}
func main() {
original := MyStruct{Data: "test"}
copy := Duplicate(original)
fmt.Println(copy.Data) // "test"
}
20. Go错误处理
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
Go 语言的错误处理采用显式返回错误的方式,而非传统的异常处理机制。这种设计使代码逻辑更清晰,便于开发者在编译时或运行时明确处理错误。
Go 的错误处理主要围绕以下机制展开:
- error 接口:标准的错误表示。
- 显式返回值:通过函数的返回值返回错误。
- 自定义错误:可以通过标准库或自定义的方式创建错误。
- panic 和 recover:处理不可恢复的严重错误。
20.1. error接口
Go 标准库定义了一个 error 接口,表示一个错误的抽象。
error 类型是一个接口类型,这是它的定义:
type error interface {
Error() string
}
- 实现 error 接口:任何实现了 Error() 方法的类型都可以作为错误。
- Error() 方法返回一个描述错误的字符串。
20.2. 使用errors包创建错误
我们可以在编码中通过实现 error 接口类型来生成错误信息。
创建一个简单错误:
err := errors.New("this is an error")
fmt.Println(err) // 输出:this is an error
函数通常在最后的返回值中返回错误信息,使用 errors.New 可返回一个错误信息:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
在下面的例子中,我们在调用 Sqrt 的时候传递的一个负数,然后就得到了 non-nil 的 error 对象,将此对象与 nil 比较,结果为 true,所以 fmt.Println(fmt 包在处理 error 时会调用 Error 方法)被调用,以输出错误,请看下面调用的示例代码:
result, err:= Sqrt(-1)
if err != nil {
fmt.Println(err)
}
20.3. 显式返回错误
Go 中,错误通常作为函数的返回值返回,开发者需要显式检查并处理。
显式返回错误:
package main
import (
"errors"
"fmt"
)
func divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("division by zero")
}
return a / b, nil
}
func main() {
result, err := divide(10, 0)
if err != nil {
fmt.Println("Error:", err) // Error: division by zero
} else {
fmt.Println("Result:", result)
}
}
20.4. 自定义错误
通过定义自定义类型,可以扩展 error 接口。
自定义错误类型:
package main
import (
"fmt"
)
type DivideError struct {
Dividend int
Divisor int
}
func (e *DivideError) Error() string {
return fmt.Sprintf("cannot divide %d by %d", e.Dividend, e.Divisor)
}
func divide(a, b int) (int, error) {
if b == 0 {
return 0, &DivideError{Dividend: a, Divisor: b}
}
return a / b, nil
}
func main() {
_, err := divide(10, 0)
if err != nil {
fmt.Println("Error:", err) // Error: cannot divide 10 by 0
}
}
20.5. fmt包与错误格式化
fmt 包提供了对错误的格式化输出支持:
- %v:默认格式。
- %+v:如果支持,显示详细的错误信息。
- %s:作为字符串输出。
package main
import (
"fmt"
)
// 定义一个 DivideError 结构
type DivideError struct {
dividee int
divider int
}
// 实现 `error` 接口
func (de *DivideError) Error() string {
strFormat := `
Cannot proceed, the divider is zero.
dividee: %d
divider: 0
`
return fmt.Sprintf(strFormat, de.dividee)
}
// 定义 `int` 类型除法运算的函数
func Divide(varDividee int, varDivider int) (result int, errorMsg string) {
if varDivider == 0 {
dData := DivideError{
dividee: varDividee,
divider: varDivider,
}
errorMsg = dData.Error()
return
} else {
return varDividee / varDivider, ""
}
}
func main() {
// 正常情况
if result, errorMsg := Divide(100, 10); errorMsg == "" {
fmt.Println("100/10 = ", result) // 100/10 = 10
}
// 当除数为零的时候会返回错误信息
if _, errorMsg := Divide(100, 0); errorMsg != "" {
fmt.Println("errorMsg is: ", errorMsg)
/**
errorMsg is:
Cannot proceed, the divider is zero.
dividee: 100
divider: 0
*/
}
}
20.6. 使用 errors.Is 和 errors.As
从 Go 1.13 开始,errors 包引入了 errors.Is 和 errors.As 用于处理错误链:
errors.Is: 检查某个错误是否是特定错误或由该错误包装而成。
var ErrNotFound = errors.New("not found")
func findItem(id int) error {
return fmt.Errorf("database error: %w", ErrNotFound)
}
func main() {
err := findItem(1)
if errors.Is(err, ErrNotFound) {
fmt.Println("Item not found")
} else {
fmt.Println("Other error:", err)
}
}
errors.AS: 将错误转换为特定类型以便进一步处理。
package main
import (
"errors"
"fmt"
)
type MyError struct {
Code int
Msg string
}
func (e *MyError) Error() string {
return fmt.Sprintf("Code: %d, Msg: %s", e.Code, e.Msg)
}
func getError() error {
return &MyError{Code: 404, Msg: "Not Found"}
}
func main() {
err := getError()
var myErr *MyError
if errors.As(err, &myErr) {
fmt.Printf("Custom error - Code: %d, Msg: %s\n", myErr.Code, myErr.Msg) // Custom error - Code: 404, Msg: Not Found
}
}
20.7. panic 和 recover
Go 的 panic 用于处理不可恢复的错误,recover 用于从 panic 中恢复。
panic:
- 导致程序崩溃并输出堆栈信息。
- 常用于程序无法继续运行的情况。
recover:
- 捕获 panic,避免程序崩溃。
func safeFunction() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered from panic:", r)
}
}()
panic("something went wrong")
}
func main() {
fmt.Println("Starting program...")
safeFunction()
fmt.Println("Program continued after panic")
}
在 safeFunction 函数中,panic("something went wrong") 引发了一个 panic,随后 defer 的 recover() 语句被调用,捕获到这个 panic,从而阻止了程序崩溃,并打印出 "Recovered from panic: something went wrong"。
21. Go并发
并发是指程序同时执行多个任务的能力。
Go 语言支持并发,通过 goroutines 和 channels 提供了一种简洁且高效的方式来实现并发。
Goroutines:
- Go 中的并发执行单位,类似于轻量级的线程。
- Goroutine 的调度由 Go 运行时管理,用户无需手动分配线程。
- 使用 go 关键字启动 Goroutine。
- Goroutine 是非阻塞的,可以高效地运行成千上万个 Goroutine。
Channel:
- Go 中用于在 Goroutine 之间通信的机制。
- 支持同步和数据共享,避免了显式的锁机制。
- 使用 chan 关键字创建,通过
<-操作符发送和接收数据。
Scheduler(调度器):
Go 的调度器基于 GMP 模型,调度器会将 Goroutine 分配到系统线程中执行,并通过 M 和 P 的配合高效管理并发。
- G:Goroutine。
- M:系统线程(Machine)。
- P:逻辑处理器(Processor)。
21.1. Goroutine
goroutine 是轻量级线程,goroutine 的调度是由 Golang 运行时进行管理的。
goroutine 语法格式:
go 函数名( 参数列表 )
例如:
go f(x, y, z)
开启一个新的 goroutine:
f(x, y, z)
Go 允许使用 go 语句开启一个新的运行期线程, 即 goroutine,以一个不同的、新创建的 goroutine 来执行一个函数。 同一个程序中的所有 goroutine 共享同一个地址空间。
package main
import (
"fmt"
"time"
)
func sayHello() {
for i := 0; i < 5; i++ {
fmt.Println("Hello World")
time.Sleep(100 * time.Millisecond)
}
}
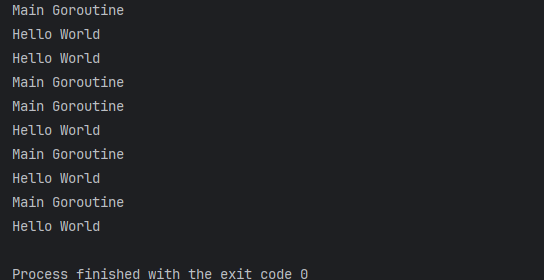
func main() {
go sayHello() // 启动Goroutine
for i := 0; i < 5; i++ {
fmt.Println("Main Goroutine")
time.Sleep(100 * time.Millisecond)
}
}
执行以上代码,你会看到输出的 Main 和 Hello。输出是没有固定先后顺序,因为它们是两个 goroutine 在执行:
21.2. 通道(Channel)
通道(Channel)是用于 Goroutine 之间的数据传递。
通道可用于两个 goroutine 之间通过传递一个指定类型的值来同步运行和通讯。
使用 make 函数创建一个 channel,使用 <- 操作符发送和接收数据。如果未指定方向,则为双向通道。
ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据,并把值赋给 v
声明一个通道很简单,我们使用chan关键字即可,通道在使用前必须先创建:
ch := make(chan int)
注意:默认情况下,通道是不带缓冲区的。发送端发送数据,同时必须有接收端相应的接收数据。
以下实例通过两个 goroutine 来计算数字之和,在 goroutine 完成计算后,它会计算两个结果的和:
package main
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // 将和发送到通道c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c) // 17
go sum(s[len(s)/2:], c) // -5
x, y := <-c, <-c // 从通道c中接收
fmt.Println(x, y, x+y) // 17 -5 12
}
21.3. 通道缓冲区
通道可以设置缓冲区,通过make的第二个参数指定缓冲区大小:
ch := make(chan int, 100)
带缓冲区的通道允许发送端的数据发送和接收端的数据获取处于异步状态,就是说发送端发送的数据可以放在缓冲区里面,可以等待接收端去获取数据,而不是立刻需要接收端去获取数据。
不过由于缓冲区的大小是有限的,所以还是必须有接收端来接收数据的,否则缓冲区一满,数据发送端就无法再发送数据了。
注意:如果通道不带缓冲,发送方会阻塞直到接收方从通道中接收了值。如果通道带缓冲,发送方则会阻塞直到发送的值被拷贝到缓冲区内;如果缓冲区已满,则意味着需要等待直到某个接收方获取到一个值。接收方在有值可以接收之前会一直阻塞。
21.4. 遍历通道与关闭通道
Go 通过 range 关键字来实现遍历读取到的数据,类似于与数组或切片。格式如下:
v, ok := <-ch
如果通道接收不到数据后 ok 就为 false,这时通道就可以使用 close() 函数来关闭。
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
// range 函数遍历每个从通道接收到的数据,因为 c 在发送完 10 个
// 数据之后就关闭了通道,所以这里我们 range 函数在接收到 10 个数据
// 之后就结束了。如果上面的 c 通道不关闭,那么 range 函数就不
// 会结束,从而在接收第 11 个数据的时候就阻塞了。
for i := range c {
fmt.Println(i)
}
}
21.5. Select语句
select 语句使得一个 goroutine 可以等待多个通信操作。select 会阻塞,直到其中的某个 case 可以继续执行:
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
以上代码中,fibonacci goroutine 在 channel c 上发送斐波那契数列,当接收到 quit channel 的信号时退出。
21.6. 使用WaitGroup
sync.WaitGroup用于等待多个Goroutine完成
同步多个 Goroutine:
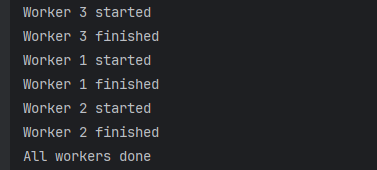
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // Goroutine 完成时调用 Done()
fmt.Printf("Worker %d started\n", id)
fmt.Printf("Worker %d finished\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 3; i++ {
wg.Add(1) // 增加计数器
go worker(i, &wg)
}
wg.Wait() // 等待所有 Goroutine 完成
fmt.Println("All workers done")
}
21.7. 高级特性
21.7.1. Buffered Channel
创建有缓冲的 Channel
ch := make(chan int, 2)
21.7.2. Context
用于控制 Goroutine 的生命周期
context.WithCancel、context.WithTimeout
21.7.3. Mutex 和 RWMutex
sync.Mutex 提供互斥锁,用于保护共享资源
var mu sync.Mutex
mu.Lock()
// critical section
mu.Unlock()