案例-索引对于并发Insert性能优化测试
前言
最近因业务并发量上升,开发反馈对订单表Insert性能降低。应开发要求对涉及Insert的表进行分析并提供优化方案。
一般对Insert 影响基本都在索引,涉及表已按创建日期做了分区表,索引全部为普通索引未做分区索引。
优化建议:
- 1、将UNIQUE改为HASH(64) GLOBAL INDEX,NORMAL改为Local INDEX。
优化思路:分散IO及减少维护成本,Oracle在索引分裂是当索引块空间不足时,通过分裂为新块以容纳新数据的操作,会引发性能问题。普通索引和分区索引(尤其是本地分区索引)在索引分裂时的行为存在显著差异。
- 2、RAC环境使用TAF(Transparent Application Failover)即透明应用程序故障转移技术,通过应用细化连接,减少RAC集群的内网交互,从而减少RAC集群的负载。
优化方案压力测试
表1:
- 数据量:1.5亿,需要调整的索引:唯一索引:3,普通索引:3

- 优化后:
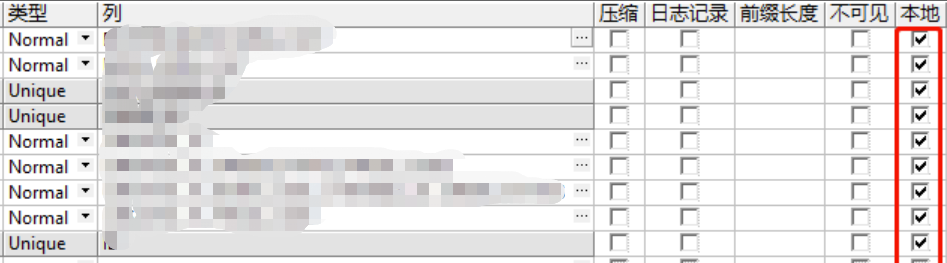
表2:
- 数据量:1.4亿,需要调整的索引:唯一索引:1,普通索引:4
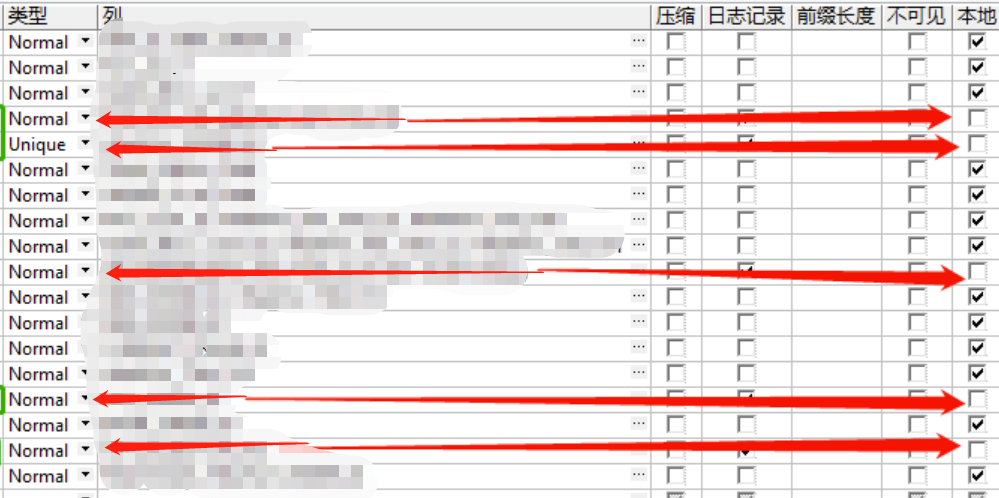
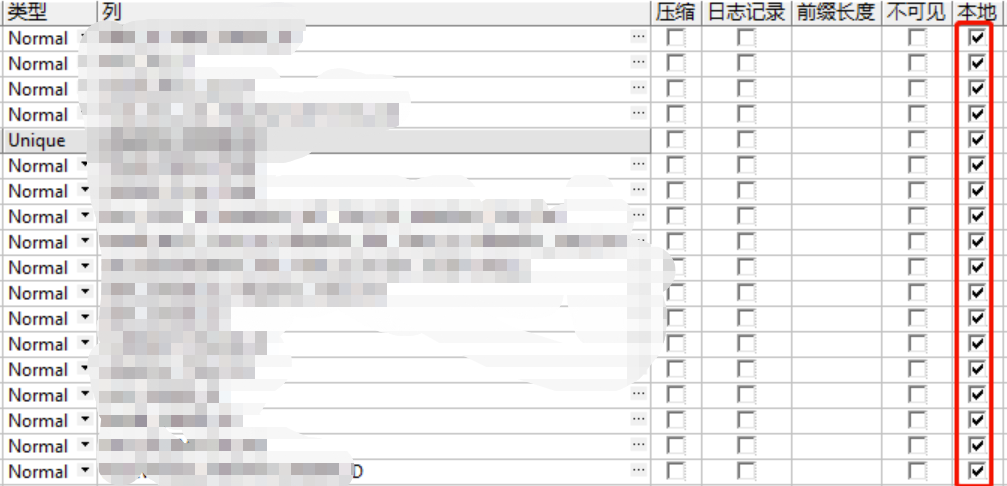
- 优化后:
RAC的TAF技术测试
- 连接SCAN_IP 测试双节点插入
- 连接单节点VIP 测试单节点插入
并发测试脚本:《Oracle&Python并发Insert测试脚本.pdf》
压力测试结果:
- 并发:100,插入数据:80w
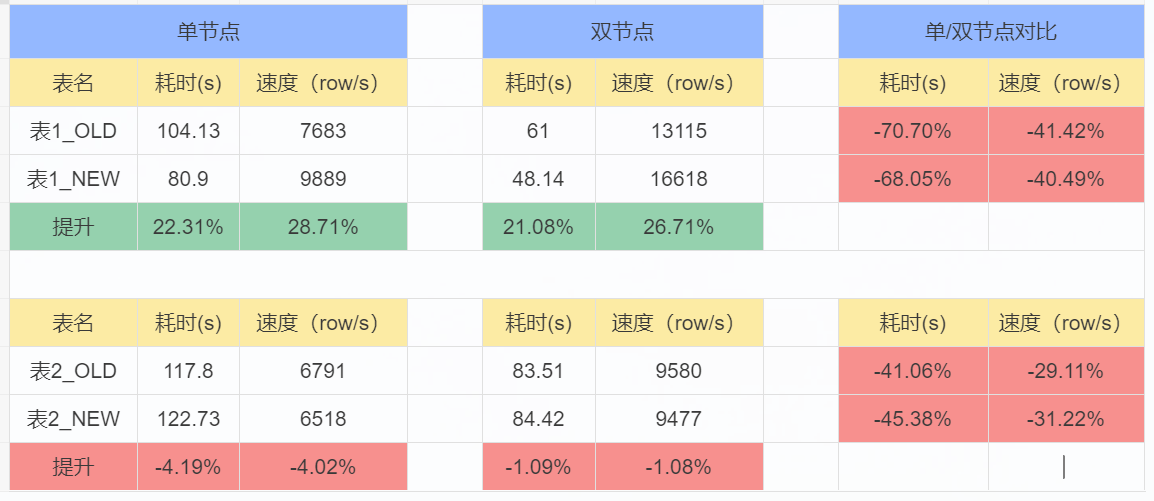
- 小结分析:
1、表1的优化效果提升20%以上,表2的优化效果差强人意(-1%至-4%之间)。
原因分析:Insert 语句导致:直接复制表中的单条记录,然后对唯一索引字段修改为UUID值,日期字段为:sysdate,其它字段为固定值。
表1:索引字段都有插入数据且值为UUID或其它索引字段均有日期字段。
表2:索引字段有3个索引值为Null(索引无操作),另一个索引插入的值为固定值(无法做到IO分散),仅唯一索引的值为UUID(有效果)。。
2、单节点比双节点插入效率-50%左右,原因为双节点分摊了并发压力,相关于单节点的:并发50,40w的数据插入,因此双节点要比单节点同样的压力要更优。
3、最终确认方案仅对表1进行索引优化,其它保持不变。
4、声明:此方案提升效果仅适用于此压测数据,而生产环境很难达到并发:100 数据量:80w 耗时:100s插入完成,并且为单条Insert语句。当并发压力未传到数据库的情况下,优化效果可能并不明显。因此生产的性能问题还需要与开发一起综合设计优化方案为最佳。
验证测试:
- 表说明:优化前:A_OLD、优化后:A_NEW,数据量:1.5亿
- 测试方向:对唯一索引、普通索引优化为:全局HASH分区索引(64)、本地索引提升效果。
查询索引
SELECT
i.TABLE_NAME,
i.index_type,
p.locality ,
i.UNIQUENESS,
LISTAGG(ic.COLUMN_NAME, ',') WITHIN GROUP (ORDER BY ic.COLUMN_POSITION) AS INDEX_COLUMNS,
i.INDEX_NAME
FROM
ALL_INDEXES i
JOIN
ALL_IND_COLUMNS ic ON i.INDEX_NAME = ic.INDEX_NAME
left join user_part_indexes p on i.INDEX_NAME = p.INDEX_NAME
WHERE
i.TABLE_NAME in ('A_NEW','A_OLD')
GROUP BY
i.TABLE_NAME,i.INDEX_NAME,i.UNIQUENESS,p.locality ,i.index_type, i.UNIQUENESS
order by 3,1;
TABLE_NAME INDEX_TYPE LOCALI UNIQUENES INDEX_COLUMNS INDEX_NAME
----------- ----------- ------ --------- --------------- ------------------
A_NEW NORMAL GLOBAL UNIQUE ID IDX_UN_ID_A_NEW
A_OLD NORMAL UNIQUE ID IDX_UN_ID_A_OLD
A_NEW NORMAL LOCAL NONUNIQUE BANK_NO IDX_BANK_NO_A_NEW
A_OLD NORMAL NONUNIQUE BANK_NO IDX_BANK_NO_A_OLD
并发测试脚本:<Oracle与Python并发Insert测试>
脚本输出
略......
2025-04-09 18:52:22,494 - INFO - INS:twodb1|SID:1006: A_OLD:8000: 530行/秒
2025-04-09 18:52:22,517 - INFO - INS:twodb1|SID:1923: A_OLD:8000: 523行/秒
2025-04-09 18:52:22,707 - INFO - INS:twodb1|SID:1858: A_OLD:8000: 529行/秒
2025-04-09 18:52:22,781 - INFO - INS:twodb1|SID:1925: A_OLD:8000: 527行/秒
2025-04-09 18:52:22,798 - INFO - 表 名:A_OLD
2025-04-09 18:52:22,798 - INFO - 开始时间: 2025-04-09 18:52:07
2025-04-09 18:52:22,798 - INFO - 结束时间: 2025-04-09 18:52:22
2025-04-09 18:52:22,799 - INFO - 耗 时: 15.61 seconds
2025-04-09 18:52:22,799 - INFO - 并 行: 100
2025-04-09 18:52:22,799 - INFO - 数 据 量: 800000
2025-04-09 18:52:22,799 - INFO - 速 度: 51260 行/秒
2025-04-09 18:52:22,799 - INFO - -----------------------wait 10 min------------------------------------
略......
2025-04-09 19:02:40,629 - INFO - INS:twodb1|SID:1709: A_NEW:8000: 557行/秒
2025-04-09 19:02:40,655 - INFO - INS:twodb1|SID:150: A_NEW:8000: 556行/秒
2025-04-09 19:02:40,658 - INFO - INS:twodb1|SID:1217: A_NEW:8000: 555行/秒
2025-04-09 19:02:40,660 - INFO - INS:twodb1|SID:716: A_NEW:8000: 553行/秒
2025-04-09 19:02:40,677 - INFO - 表 名:A_NEW
2025-04-09 19:02:40,678 - INFO - 开始时间: 2025-04-09 19:02:26
2025-04-09 19:02:40,678 - INFO - 结束时间: 2025-04-09 19:02:40
2025-04-09 19:02:40,678 - INFO - 耗 时: 14.63 seconds
2025-04-09 19:02:40,678 - INFO - 并 行: 100
2025-04-09 19:02:40,678 - INFO - 数 据 量: 800000
2025-04-09 19:02:40,678 - INFO - 速 度: 54695 行/秒
2025-04-09 19:02:40,681 - INFO - --------------程序执行结束-----------------------------------
测试结果:
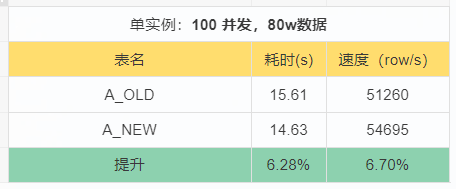
测试小结
- 从上面的测试结果来看,普通索引(UNIQU、NORMAL)优化为(HASH(64)INDEX、Local INDEX)效果提升6%以上。
分析:普通索引、本地分区索引、全局分区索引
- 1、 普通索引
结构影响:普通索引基于整个表构建,索引分裂会影响整个索引树结构。例如,频繁插入可能导致叶子块分裂(如50-50分裂或99-分裂),甚至触发分支节点分裂,增加I/O和锁争用。
维护开销:每次分裂需更新整个索引结构,高并发写入时可能成为性能瓶颈。
热点问题:所有插入操作集中在同一索引结构,可能导致块竞争(如索引块争用)。 - 2、 本地分区索引(Local Partitioned Index)
分区独立性:每个分区的索引独立维护,索引分裂仅发生在操作对应的分区内,不影响其他分区。
维护效率:分区操作(如TRUNCATE或DROP)仅影响本地索引的对应分区,维护更快且无需重建整个索引。
并发优化:不同分区的插入操作分散到各自的索引分区,减少锁争用和热点问题。
适用场景:适合数据有明显分区键(如时间范围),且频繁写入的场景。 - 3、 全局分区索引(Global Partitioned Index)
跨分区结构:索引的分区方式与表分区无关,索引分裂可能影响整个全局索引的结构,类似普通索引,优化是分散IO。
维护开销:对表分区的维护操作(如删除分区)可能导致全局索引失效,需重建或命令加:update indexes来维护索引。
灵活性:分区键可独立于表,但牺牲了本地索引的维护优势。 - 4. 索引分裂优化策略
普通索引:使用REVERSE KEY索引或调整PCTFREE减少分裂频率。
本地分区索引:合理设计分区键,确保写入均匀分布到不同分区。
全局索引:慎用,仅在查询模式需要时使用,并定期维护。 - 5、索引相关案例:数据裁剪偶遇【enq: TX - index contention】
总结
- 本地分区索引在分裂和维护效率上显著优于普通索引和全局索引,尤其适合分区表的高并发场景。
- 普通索引简单但易成瓶颈;全局索引灵活性高但维护成本大。设计时应根据数据分布和查询需求权衡选择。
- 全局分区索引也有某些局限,那就是如果查询条件跨多个索引分区,则效率就下降了,因此全局分区索引对范围查询(Between…and…、>、<、<>等)操作通常性能不好。总之,全局分区索引将索引高度降低了,能提升性能,但如果横向扩展访问多个分区索引树,性能又会下降。
- 周期性的开启Oracle 的“索引监控功能”,对不需要的索引及时清理。