IJCV-2025 | 深圳大学记忆增强的具身导航!ESceme:基于情景记忆的视觉语言导航

- 作者:Qi Zheng 1 , 2 ^{1,2} 1,2, Daqing Liu 3 ^{3} 3, Chaoyue Wang 3 ^{3} 3, Jing Zhang 2 ^{2} 2, Dadong Wang 4 ^{4} 4, Dacheng Tao 2 ^{2} 2
- 单位: 1 ^{1} 1深圳大学电子与信息工程学院, 2 ^{2} 2悉尼大学计算机科学学院, 3 ^{3} 3京东探索研究院, 4 ^{4} 4CSIRO,DATA61
- 论文标题:ESceme: Vision-and-Language Navigation with Episodic Scene Memory
- 论文链接:https://link.springer.com/article/10.1007/s11263-024-02159-8
- 代码链接:https://github.com/qizhust/esceme
主要贡献
-
论文首次提出Episodic Scene Memory(ESceme)场景记忆机制,通过记忆过去的访问场景来平衡泛化能力和效率。
-
通过Candidate Enhancing方法,论文提供了一个简单而有效的ESceme实现,通过在每个位置增强可访问的视图,并在导航过程中逐步完成记忆来实现。
-
在短视距(R2R)、长视距(R4R)和视觉-对话(CVDN)导航任务上验证了ESceme的优越性。实验结果表明,ESceme在这些任务中表现优异。
-
ESceme在CVDN排行榜上取得了第一名,展示了其在复杂导航任务中的强大能力。
研究背景
研究问题
- 论文主要解决的问题是如何在视觉语言导航(VLN)中平衡泛化能力和效率。
- 现有的方法在导航新环境方面取得了巨大进展,但在多步决策过程中,由于领域偏移和观察变化,VLN智能体的性能会受到显著影响。
研究难点
该问题的研究难点包括:
- 如何在多步决策中有效地利用历史信息,
- 如何在未见环境中进行有效的导航,
- 以及如何在保证效率的同时提高导航的准确性。
相关工作
-
视觉语言导航方法:
- 基础方法:自Anderson等人(2018b)定义VLN任务并提供基于LSTM的序列到序列(Seq2Seq)基线以来,许多方法被开发出来以提高导航性能。这些方法包括数据增强、特征表示和架构的改进等。
- 数据增强:一些方法通过数据增强来提高导航能力,例如SF(Fried et al., 2018)、EnvDrop(Tan et al., 2019)和EnvEdit(Li et al., 2022a)。
- 环境建模:Wang等人(2018)通过建模环境来提供导航计划信息。RCM(Wang et al., 2019)通过指令-轨迹匹配批评家提供内在奖励进行强化学习。
- 多模态特征:许多方法探索了更有效的特征表示和架构,如PTA(Cornia & Cucchiara, 2019)、OAAM(Qi et al., 2020a)、NvEM(An et al., 2021)等。
- 图构建与推理:一些方法在导航过程中构建和推理导航图,如NTS(Chaplot et al., 2020)和RECON(Shah et al., 2022)。
-
探索策略:
- 预探索:为了提高在新环境中导航的能力,一些方法采用预探索策略,允许智能体在导航前预先探索未知环境。这些方法包括Wang等人(2019)的预探索和Ma等人(2019a, 2019b)的后悔模块。
- 全局动作空间:Deng等人(2020)首次定义了全局动作空间,并构建了环境的图形表示以优雅地进行探索和回溯。
- 结构化场景记忆:Wang等人(2021)扩展了EnvDrop(Tan et al., 2019)以使用外部结构化场景记忆(SSM)来促进全局动作空间中的探索。
-
与其他方法的比较:
- 场景记忆与路径记忆:论文指出,ESceme与其他图构建或地图构建方法的主要区别在于,ESceme维护的是场景级别的记忆,而不是路径级别的记忆。ESceme通过增加每个节点的信息来改善导航,而不是通过扩展智能体的动作空间。
ESceme
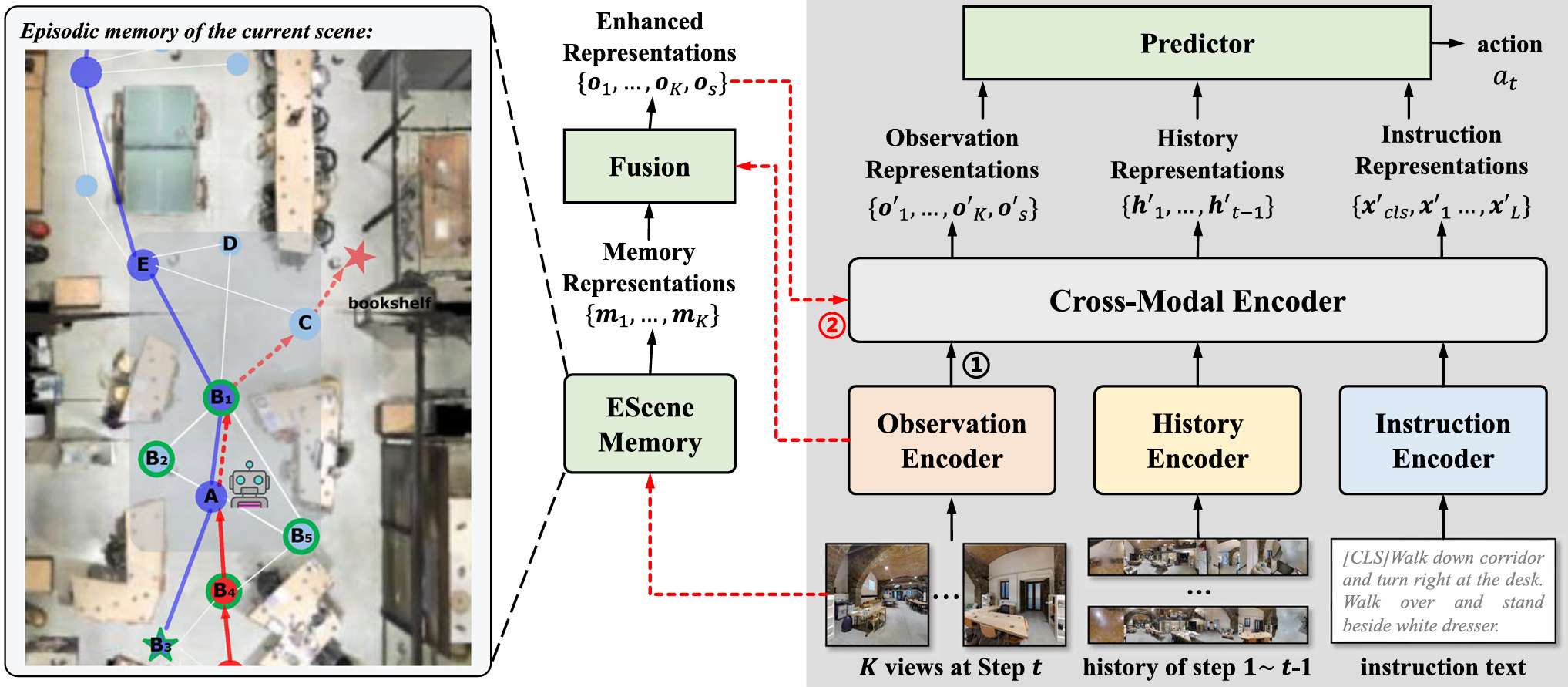
问题表述
- ESceme的目标是解决视觉-语言导航(VLN)中的问题,其中智能体需要根据自然语言指令在环境中导航。
- 给定一个指令和一个初始位置,智能体需要观察环境并选择合适的行动以达到目标。
- ESceme通过引入场景记忆来增强智能体的导航能力。
场景记忆构建
-
初始化:场景记忆以空图的形式初始化,表示智能体从未访问过该场景。当智能体首次进入一个场景时,它会开始导航并逐步更新记忆。
G Y ( 0 ) = ( V Y ( 0 ) = ∅ , E Y ( 0 ) = ∅ ) \mathcal{G}_{Y}^{(0)} = (\mathcal{V}_{Y}^{(0)} = \emptyset, \mathcal{E}_{Y}^{(0)} = \emptyset) GY(0)=(VY(0)=∅,EY(0)=∅)
其中 V Y ( 0 ) \mathcal{V}_{Y}^{(0)} VY(0) 和 E Y ( 0 ) \mathcal{E}_{Y}^{(0)} EY(0) 分别表示场景 Y Y Y 的节点集合和边集合。 -
更新机制:在每个时间步,智能体会更新其场景记忆。如果智能体到达一个新的位置,它会在记忆图中添加这个位置及其邻居。节点特征是其邻居特征的池化结果,池化函数可以是最大池化或平均池化。
m V 1 = pooling ( f V 1 , i ) m_{V_{1}} = \text{pooling}(f_{V_{1, i}}) mV1=pooling(fV1,i)
其中 f V 1 , i f_{V_{1, i}} fV1,i 是第 i i i 个邻居视点的特征, m V 1 m_{V_{1}} mV1 是节点 V 1 V_{1} V1 的特征。
场景记忆导航
-
候选增强(Candidate Enhancing, CE):在每个决策步骤中,智能体会检索其当前位置的记忆表示,并将其与原始观察特征结合,以增强候选视点的表示。
m k = { m V j if the k -th view is V j ∈ V ( t − 1 ) 0 otherwise. m_{k} = \left\{\begin{array}{ll}m_{V_{j}} & \text{if the } k\text{-th view is } V_{j}\in\mathcal{V}^{(t-1)}\\ 0 & \text{otherwise.}\end{array}\right. mk={mVj0if the k-th view is Vj∈V(t−1)otherwise.
这里的 m k m_{k} mk 是从记忆中检索的表示, f k f_{k} fk 是原始观察特征。通过拼接和多层感知机(MLP)投影,生成增强的候选视点表示。
o k = MLP ( [ [ m k ; f k ] ] ) o_{k} = \text{MLP}([\text{[}m_{k}; f_{k}\text{]}]) ok=MLP([[mk;fk]])
其中 [ ⋅ ; ⋅ ] [\cdot;\cdot] [⋅;⋅] 表示特征维度的拼接。 -
输入到导航网络:增强的候选视点表示与历史特征和指令文本一起输入到交叉模态编码器中,以预测下一步的行动。智能体预测行动的概率分布如下:
P ( a t = k ∈ { 1 , … , K , s } ) = e M L P ( o k ′ ⊙ x c l s ′ ) ∑ j ∈ { 1 , … , K , s } e M L P ( o j ′ ⊙ x c l s ′ ) , P\left(a_{t}=k\in\{1,\ldots, K, s\}\right)=\frac{e^{MLP\left(o_{k}^{\prime}\odot x_{cl s}^{\prime}\right)}}{\sum_{j\in\{1,\ldots, K, s\}} e^{MLP\left(o_{j}^{\prime}\odot x_{cl s}^{\prime}\right)}}, P(at=k∈{1,…,K,s})=∑j∈{1,…,K,s}eMLP(oj′⊙xcls′)eMLP(ok′⊙xcls′),
其中 ⊙ \odot ⊙ 表示向量逐元素乘法, o k ′ o_{k}^{\prime} ok′ 和 x c l s ′ x_{cls}^{\prime} xcls′ 是编码后的特征。
训练目标
ESceme通过模仿学习和强化学习的混合目标进行端到端训练。目标是最大化模仿学习的目标概率和最小化强化学习的回报与状态值的差异。
L = − α ∑ t = 1 T ∗ log P ( a t = a t ∗ ) − ∑ t = 1 T log P ( a ~ t ) ( r t − v t ) , \mathcal{L}=-\alpha\sum_{t=1}^{T^{*}}\log P\left(a_{t}=a_{t}^{*}\right)-\sum_{t=1}^{T}\log P\left(\tilde{a}_{t}\right)\left(r_{t}-v_{t}\right), L=−αt=1∑T∗logP(at=at∗)−t=1∑TlogP(a~t)(rt−vt),
其中 T ∗ T^{*} T∗ 是标注路径的长度, T T T 是预测路径的长度, a ~ t \tilde{a}_{t} a~t 是采样的动作, r t r_{t} rt 是折扣奖励, v t v_{t} vt 是状态值。
实验
实验设置
数据集和指标
- R2R数据集:用于评估短视距导航任务,包含7,189条直接到目标的轨迹。评估指标包括轨迹长度(TL)、导航误差(NE)、成功率(SR)和路径长度加权成功率(SPL)。
- R4R数据集:用于评估长视距导航任务,通过连接R2R中的轨迹生成。评估指标包括NE、SR、SPL、覆盖率加权得分(CLS)、归一化动态时间规整(nDTW)和SDTW。
- CVDN数据集:用于评估视觉-对话导航任务,要求智能体根据目标物体和对话历史进行导航。主要评估指标是目标进度(GP)。
实现细节
- 模型架构:默认采用Chen等人(2021b)的编码器。单视图特征使用Chen等人(2021b)发布的微调ViT-B/16提取。
- 训练参数:设置特征维度 d = 768 d=768 d=768,模仿学习损失比例 α = 0.2 \alpha=0.2 α=0.2,训练迭代次数为100,000次,批量大小为8,学习率为1e-5。
- 硬件:所有实验在单个NVIDIA V100 GPU上进行。
公平比较
- 公平性:确保在未见环境中部署智能体时,智能体从未见过环境。ESceme在初始化时为空,后续场景中逐步更新记忆。
与最新方法的比较
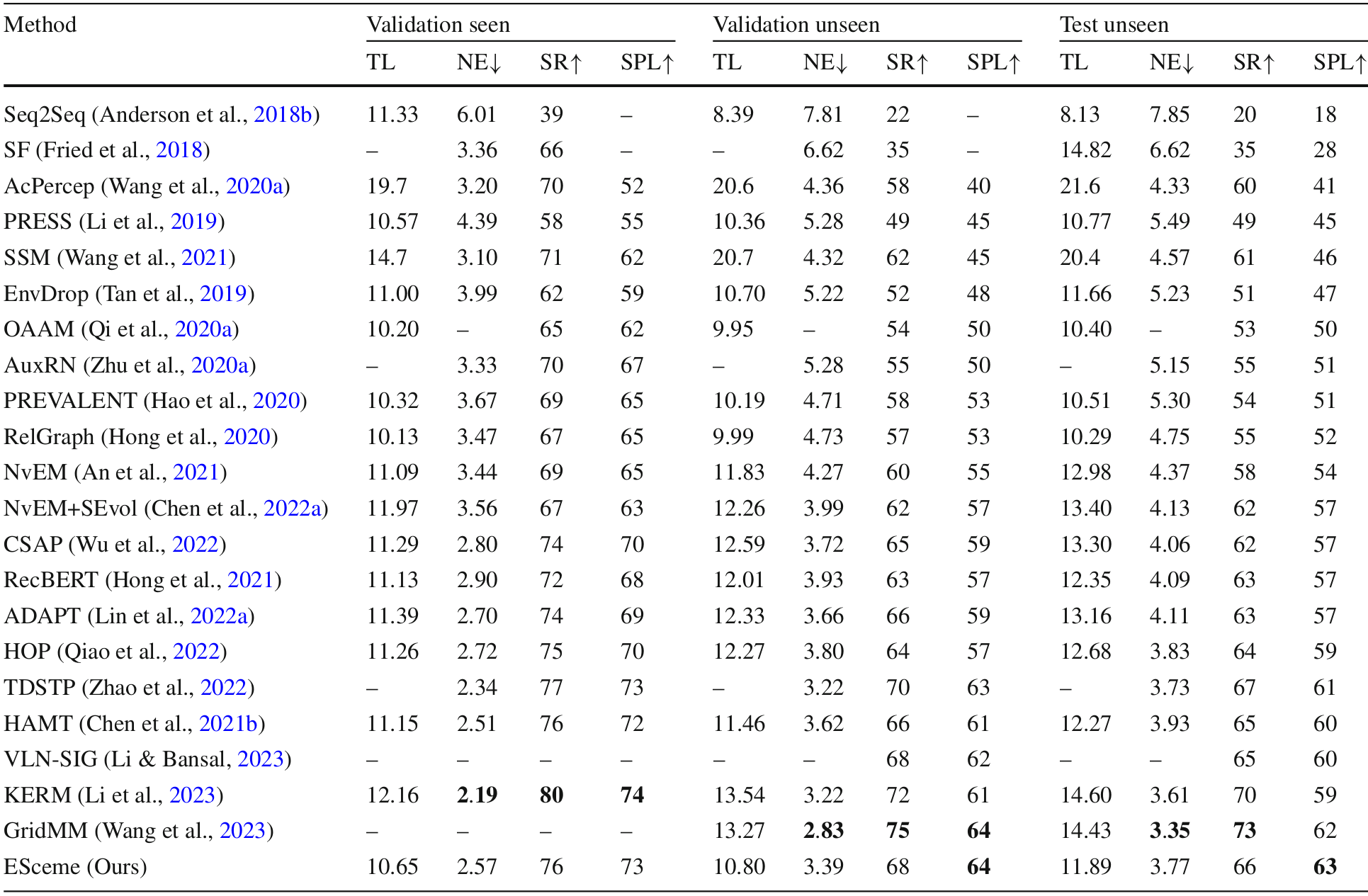
R2R数据集结果
- ESceme在未见分割上实现了最高的SPL,超越了基线模型HAMT和其他最新方法。
- 在验证和测试未见环境中,ESceme分别比HAMT高出约5%的SPL。
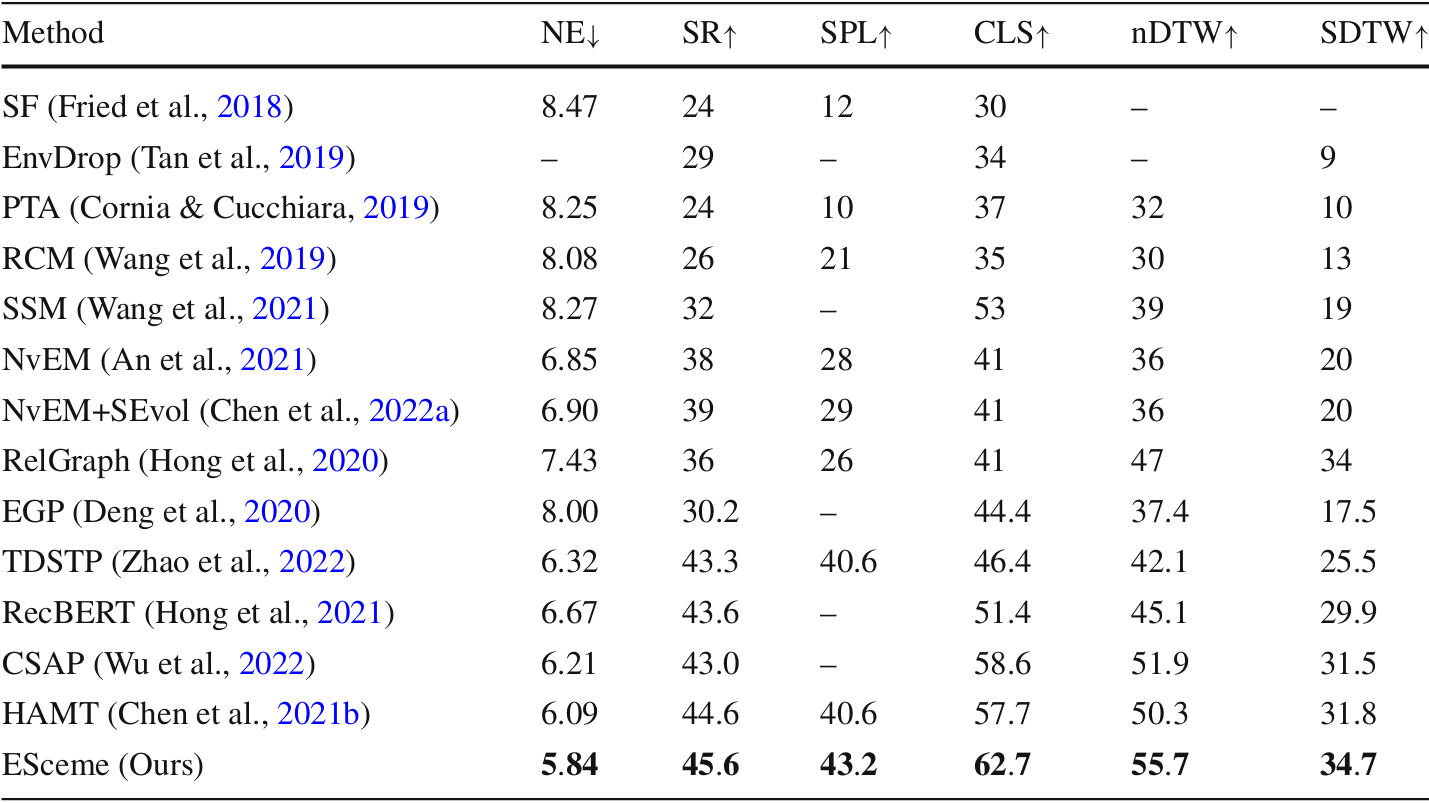
R4R数据集结果
- ESceme在多个指标上大幅超越现有最先进方法,包括SPL、CLS、nDTW和SDTW。
- 这表明ESceme不仅提高了导航成功率,还改善了路径保真度。
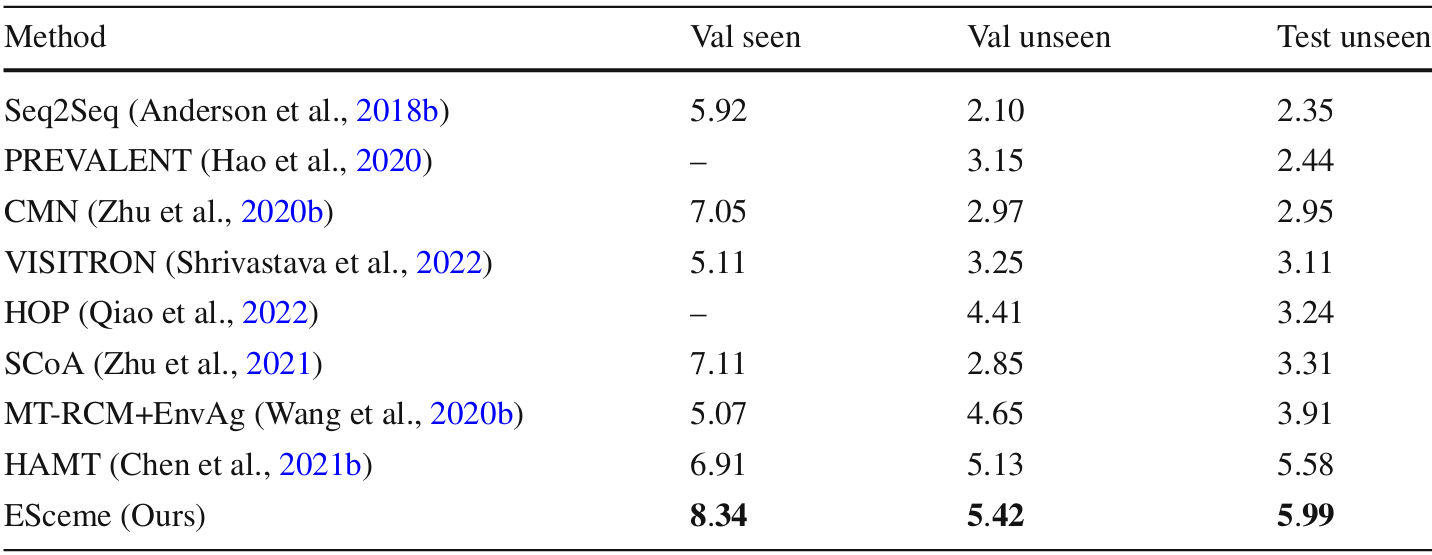
CVDN数据集结果
- ESceme在目标进度(GP)上取得最佳成绩,领先于其他方法,特别是在未见环境中表现优异。
- ESceme在验证未见和测试未见环境中分别提升了20.7%、5.7%和7.3%。
消融研究

不同的ESceme构建
- 池化函数:评估了不同的池化函数对SPL的影响,发现最大池化在未见环境中效果更好。
不同的导航架构和推断策略
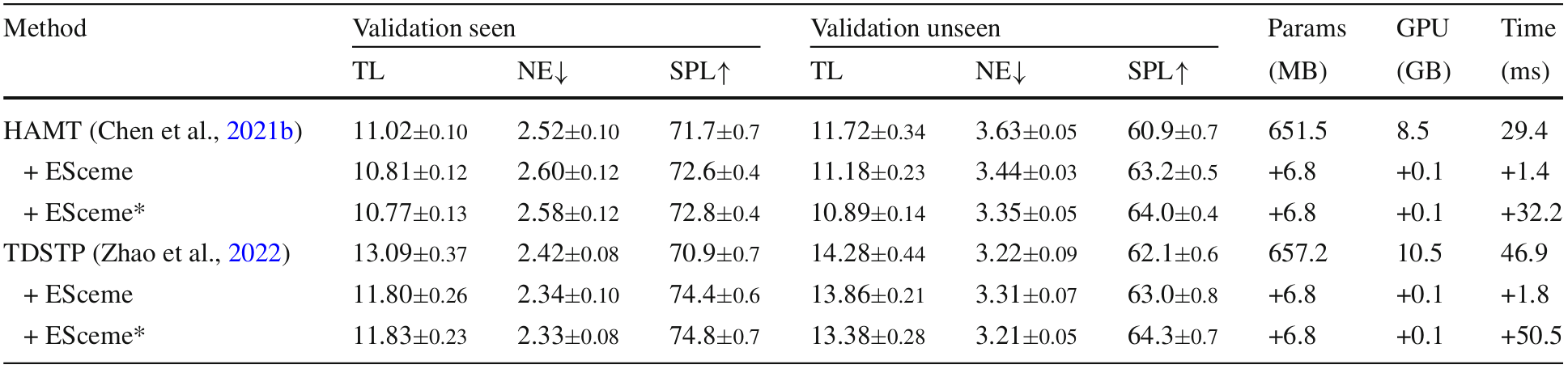
- 架构兼容性:ESceme设计为模型无关,可以在任何具有观察输入的导航网络中使用。实验表明,ESceme在TDSTP架构上也能提升导航性能。
计算效率
ESceme在单个运行设置中引入了适度的额外参数和内存占用,但计算时间增加较少。
执行指令的顺序
- 由于ESceme在导航过程中动态更新记忆,指令的执行顺序对整体性能影响较小。
- 实验结果表明,即使在打乱指令顺序的情况下,ESceme仍然保持了稳定的性能。
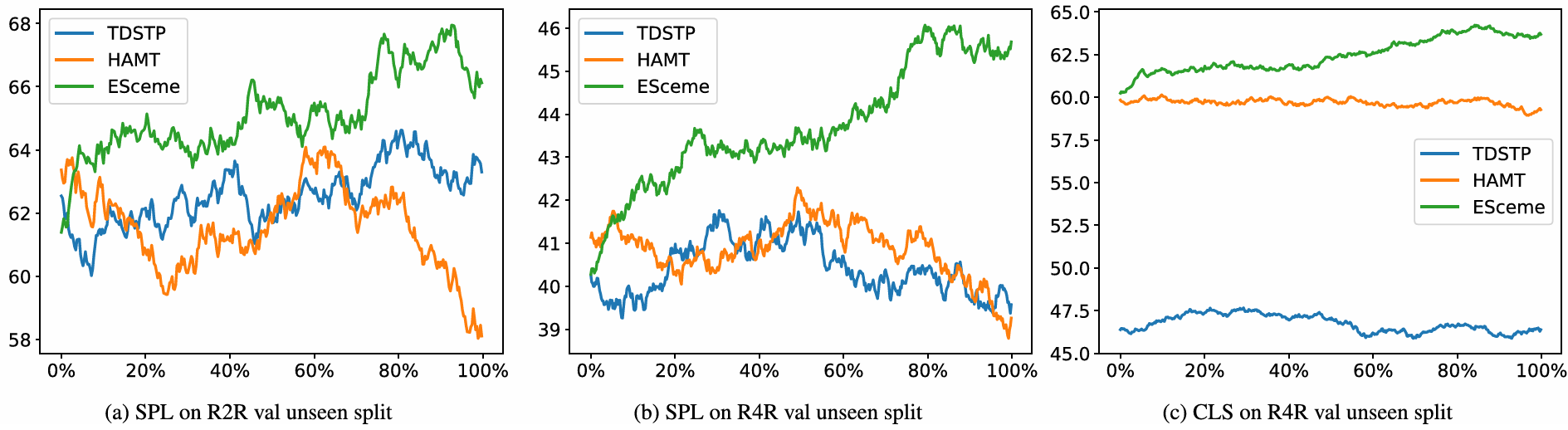
推理过程中的成功率变化
- 通过比较不同方法的成功率(SPL)和覆盖率加权得分(CLS)曲线,展示了ESceme在推理过程中的导航质量变化。
- 结果表明,ESceme在短视距和长视距导航任务中均表现出较高的成功率,并且在长视距任务中保持稳定。
定性分析

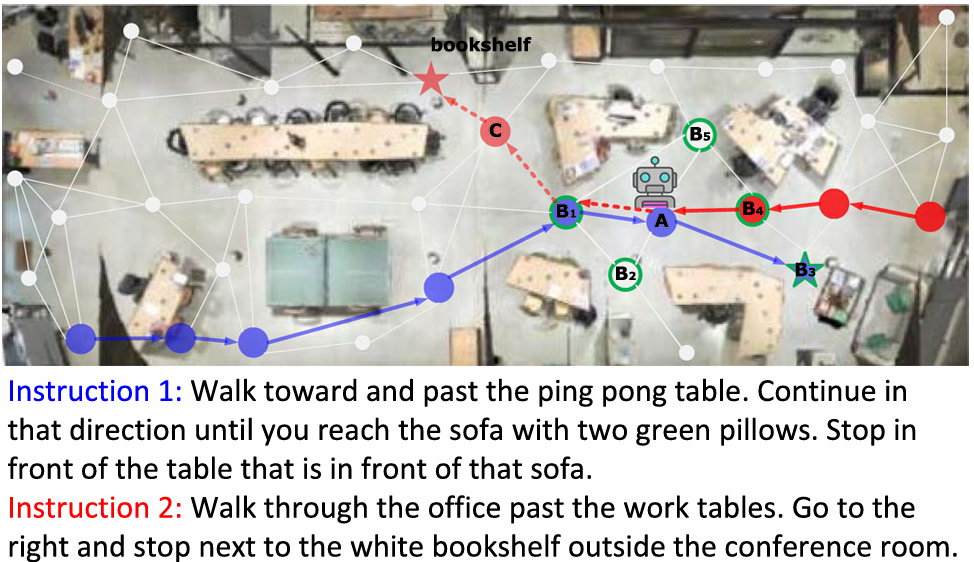
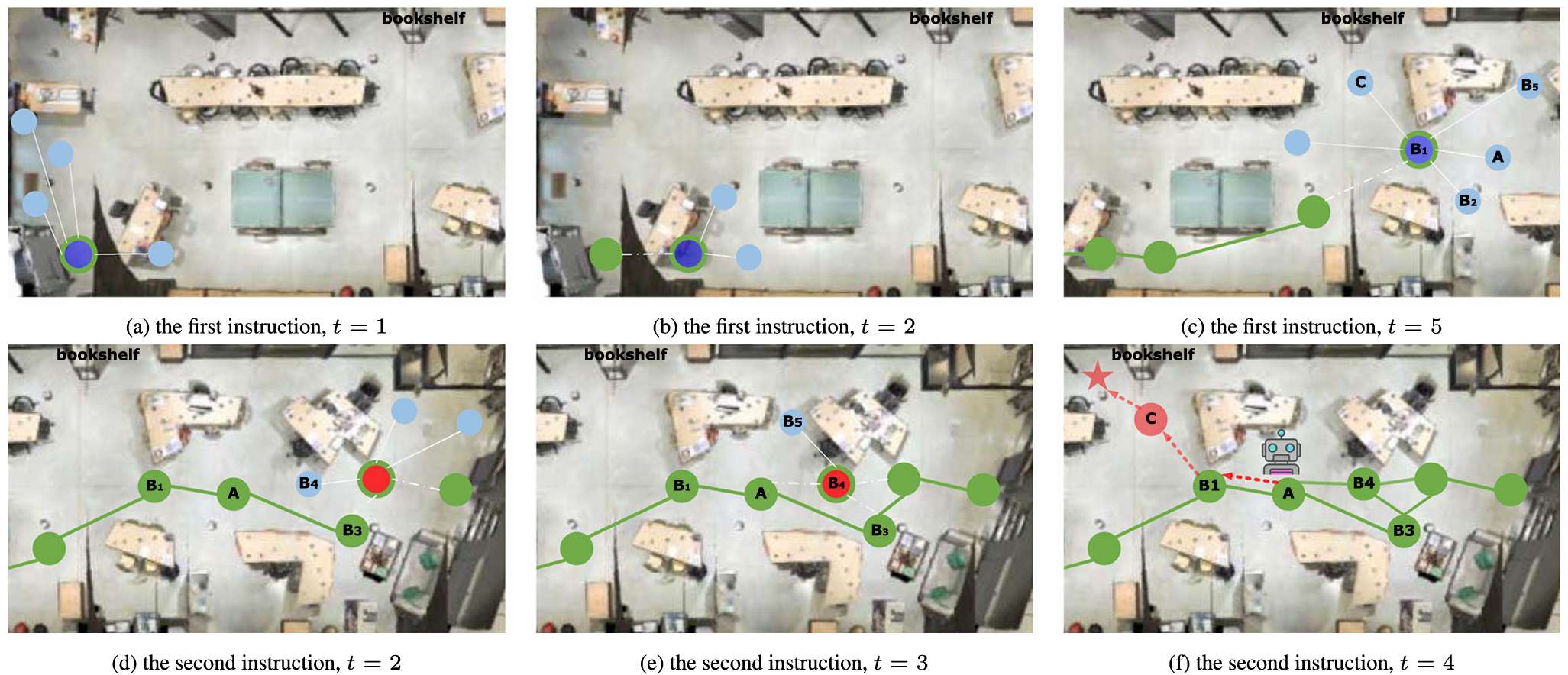
- 可视化示例:论文提供了定性分析,通过可视化导航过程展示了ESceme的优势。示例包括在R2R和R4R数据集上的导航情况,展示了ESceme如何更好地理解和遵循指令。

- 失败案例:论文还分析了ESceme的失败案例,指出在某些情况下,ESceme可能难以理解更细粒度的指令或区分细微的视觉观察。这为未来的研究提供了方向。
总结
- 本文提出了第一个具有情景记忆的VLN机制(ESceme),并通过候选增强实现了一个简单而有效的版本。
- 实验结果表明,ESceme在短视距、长视距和视觉对话导航任务中均表现出色,超越了现有的最先进方法,并在CVDN排行榜上获得了第一名。
- 该方法在保证效率的同时显著提高了导航的准确性,为未来的VLN和相关领域的情景记忆建模提供了新的思路。
