力扣热题——使数组元素互不相同所需的最少操作次数

目录
题目链接:3396. 使数组元素互不相同所需的最少操作次数 - 力扣(LeetCode)
题目描述
编辑
解法一:找到最后一个重复元素的位置
1. 问题的核心
2. 算法设计
(1) 找到最后一个重复元素的位置
(2) 计算最少操作次数
Java写法:
C++写法:
运行时间
时间复杂度和空间复杂度
时间复杂度
空间复杂度
编辑
解法二:哈希表+暴力
1. 核心逻辑
2. 哈希表的作用
3. 移除操作
Java写法:
C++写法:
运行时间
时间复杂度和空间复杂度
总结

题目链接:3396. 使数组元素互不相同所需的最少操作次数 - 力扣(LeetCode)
注:下述题目描述和示例均来自力扣
题目描述
给你一个整数数组 nums,你需要确保数组中的元素 互不相同 。为此,你可以执行以下操作任意次:
- 从数组的开头移除 3 个元素。如果数组中元素少于 3 个,则移除所有剩余元素。
注意:空数组也视作为数组元素互不相同。返回使数组元素互不相同所需的 最少操作次数 。
示例 1:
输入: nums = [1,2,3,4,2,3,3,5,7]
输出: 2
解释:
- 第一次操作:移除前 3 个元素,数组变为
[4, 2, 3, 3, 5, 7]。 - 第二次操作:再次移除前 3 个元素,数组变为
[3, 5, 7],此时数组中的元素互不相同。
因此,答案是 2。
示例 2:
输入: nums = [4,5,6,4,4]
输出: 2
解释:
- 第一次操作:移除前 3 个元素,数组变为
[4, 4]。 - 第二次操作:移除所有剩余元素,数组变为空。
因此,答案是 2。
示例 3:
输入: nums = [6,7,8,9]
输出: 0
解释:
数组中的元素已经互不相同,因此不需要进行任何操作,答案是 0。
提示:
1 <= nums.length <= 1001 <= nums[i] <= 100

解法一:找到最后一个重复元素的位置
1. 问题的核心
题目要求我们通过移除数组前 3 个元素的操作,使得数组中的元素互不相同。我们需要计算最少的操作次数。
核心思想是:
- 如果数组中已经没有重复元素,则不需要任何操作。
- 如果有重复元素,我们需要找到最后一个重复元素的位置,并基于此位置计算需要移除的次数。
2. 算法设计
(1) 找到最后一个重复元素的位置
为了判断数组中是否存在重复元素,以及确定最后一次出现重复的位置,代码使用了以下方法:
- 从数组的末尾向前遍历(
for (int i = nums.length - 1; i >= 0; i--))。 - 使用一个
HashSet来存储已经访问过的元素。- 如果当前元素已经在
HashSet中(即出现了重复),记录下它的索引index并退出循环。 - 否则,将当前元素加入
HashSet。
- 如果当前元素已经在
为什么从后往前遍历?
- 因为我们关心的是“最后一个”重复元素的位置,这样可以确保找到的索引是最接近数组开头的。
(2) 计算最少操作次数
根据找到的 index,我们可以计算出需要移除的次数:
- 每次操作最多移除 3 个元素。
- 需要移除的元素总数是从数组开头到
index的所有元素(即index + 1个元素)。 - 因此,操作次数为
(index + 1) / 3(整除),如果不能整除,则需要额外一次操作。
(index + 1) % 3 == 0 ? (index + 1) / 3 : (index + 1) / 3 + 1
Java写法:
class Solution {public int minimumOperations(int[] nums) {HashSet<Integer> set = new HashSet<>();// 这里的-1不只是说是标记为未操作数// 还是为了后面的index计算做了铺垫int index = -1;for(int i = nums.length - 1;i >= 0;i--){if(set.contains(nums[i])){index = i;break; }set.add(nums[i]);}// 这里得到了index// 那么结果就是// (index + 1)%3 == 0?(index + 1)/3:(index + 1)/3 + 1return (index + 1)%3 == 0?(index + 1)/3:(index + 1)/3 + 1;}
}C++写法:
#include <vector>
#include <unordered_set>
using namespace std;class Solution {
public:int minimumOperations(vector<int>& nums) {unordered_set<int> set;// 初始化 index 为 -1,表示没有重复元素int index = -1;// 从数组末尾向前遍历,找到最后一个重复元素的位置for (int i = nums.size() - 1; i >= 0; --i) {if (set.find(nums[i]) != set.end()) {index = i;break;}set.insert(nums[i]);}// 如果没有重复元素,返回 0if (index == -1) {return 0;}// 计算最少操作次数return (index + 1) % 3 == 0 ? (index + 1) / 3 : (index + 1) / 3 + 1;}
};运行时间
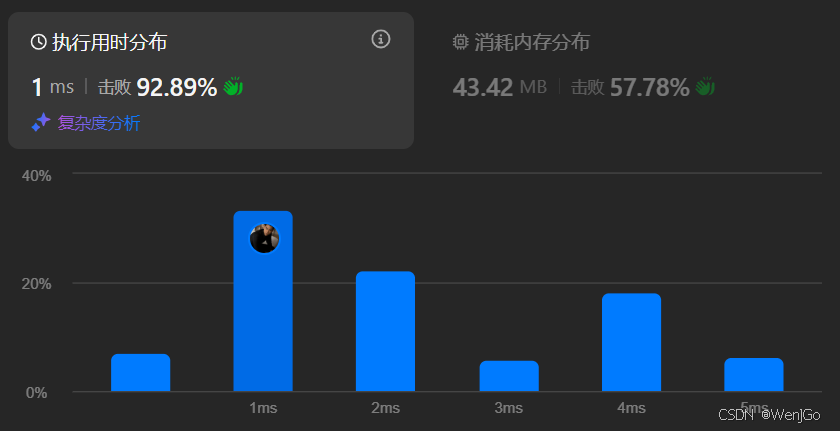
时间复杂度和空间复杂度
时间复杂度
- 遍历数组的时间复杂度为
O(n),其中n是数组的长度。 HashSet的插入和查找操作平均时间复杂度为O(1)。- 总体时间复杂度为
O(n)。
空间复杂度
- 使用了一个
HashSet存储数组中的元素,最坏情况下需要存储所有元素,空间复杂度为O(n)。

解法二:哈希表+暴力
1. 核心逻辑
- 使用一个循环从数组的开头开始,每次尝试检查当前剩余数组是否有重复元素。
- 如果有重复元素,则执行一次操作(移除前 3 个元素),并增加操作计数。
- 如果没有重复元素,直接返回当前的操作次数。
2. 哈希表的作用
- 在每次检查时,使用哈希表(
HashSet或unordered_set)来判断当前剩余数组中是否有重复元素。 - 如果某个元素已经存在于哈希表中,则说明存在重复。
3. 移除操作
- 每次操作最多移除 3 个元素。如果数组中剩余元素不足 3 个,则移除所有剩余元素。
- 通过
i += 3来模拟移除操作。
Java写法:
class Solution {public int minimumOperations(int[] nums) {int operations = 0;int n = nums.length;// 模拟移除操作for (int i = 0; i < n; ) {// 使用 HashSet 判断当前剩余数组是否有重复元素HashSet<Integer> set = new HashSet<>();boolean hasDuplicate = false;for (int j = i; j < n; j++) {if (!set.add(nums[j])) { // 如果无法添加到集合中,说明有重复hasDuplicate = true;break;}}// 如果没有重复元素,直接返回操作次数if (!hasDuplicate) {return operations;}// 否则,移除前 3 个元素(或剩余所有元素)i += 3;operations++;}return operations;}
}C++写法:
#include <vector>
#include <unordered_set>
using namespace std;class Solution {
public:int minimumOperations(vector<int>& nums) {int operations = 0;int n = nums.size();// 模拟移除操作for (int i = 0; i < n; ) {// 使用 unordered_set 判断当前剩余数组是否有重复元素unordered_set<int> set;bool hasDuplicate = false;for (int j = i; j < n; j++) {if (!set.insert(nums[j]).second) { // 如果插入失败,说明有重复hasDuplicate = true;break;}}// 如果没有重复元素,直接返回操作次数if (!hasDuplicate) {return operations;}// 否则,移除前 3 个元素(或剩余所有元素)i += 3;operations++;}return operations;}
};运行时间
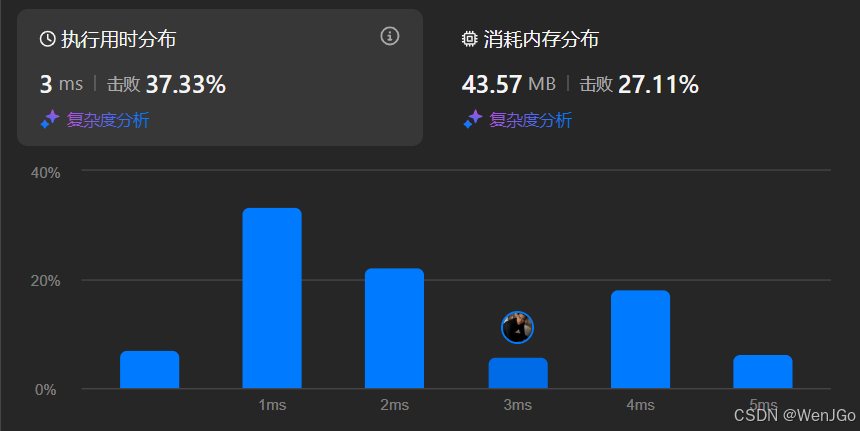
时间复杂度和空间复杂度
时间复杂度
- 最坏情况下,每次只移除 3 个元素,总共需要遍历整个数组。
- 时间复杂度为
O(n),其中n是数组的长度。
空间复杂度
- 每次检查时使用一个哈希表存储当前剩余数组中的元素。
- 空间复杂度为
O(n),其中n是数组的长度。
总结
还是用第一个方法吧!~~~