从图像“看出动作”

📘 第一部分:运动估计(Motion Estimation)
🧠 什么是运动估计?
简单说:
👉 给你一段视频,计算机要“看懂”里面什么东西动了、往哪动了、有多快。
比如:
-
一个人从左往右走
-
一辆车开向远方
→ 这些动作,在图像中就是像素位置和亮度的变化。
🧩 1. 基本方法:帧差法(Frame Differencing)
最简单粗暴的办法:
❓做法:
把相邻两帧图像像减法一样相减:
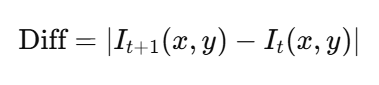
-
如果像素差大 → 表示这个地方“变了” → 说明物体移动了。
-
如果差很小 → 说明这个区域没动。
✅ 优点:
-
简单、快速
-
不需要复杂模型
❌ 缺点:
-
相机抖动也会造成“运动误判”
-
无法判断方向
-
不适合运动缓慢或光照变化大的情况
🧩 2. 更高级方法:光流(Optical Flow)
💡 思想核心:
如果物体在移动,它的外观(颜色、亮度)不会变,只是位置改变了。
于是我们提出一个“亮度恒定”假设(Brightness Constancy Assumption):
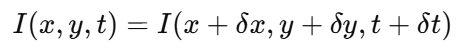
-
意思是:第 t 帧某个位置的像素亮度,等于下一帧这个点“移动后”新位置的亮度。
📐 公式推导(只理解逻辑,不用推导):
对这个式子求导后可以得到:
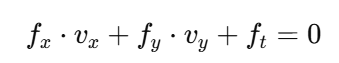
这是经典的光流约束方程(Optical Flow Constraint Equation)
| 符号 | 意义 |
|---|---|
| fx,fy | 空间梯度:图像在 x、y 方向变化多快 |
| ft | 时间梯度:这个像素亮度变化了多少 |
| vx,vy | 这个像素在 x、y 方向移动速度(光流) |
❗问题来了:这个方程只有一个式子,但有两个未知数(vx 和 vy)!
这就叫做:方程不够,解不出精确速度 → 所以我们要加“额外假设”来补救。
🧩 3. 光流估计的两种主流方法
✅ 方法一:Lucas-Kanade 光流(局部解法)
假设某个小窗口(比如 3×3 区域)内的像素都是“差不多的速度”在移动。
于是我们就可以用 9 个像素点的方程联立,做最小二乘求解:
-
解一组 (vx, vy)
-
每个窗口输出一个运动向量
✅ 优点:
-
稳定、对噪声不敏感
-
适合小区域物体移动缓慢的情况
❌ 缺点:
-
不适合大范围运动或运动剧烈的情况
✅ 方法二:Horn-Schunck 光流(全局解法)
假设整个图像的光流是连续、平滑变化的
核心思想:
-
既要满足光流约束方程(f_x v_x + f_y v_y = -f_t)
-
又要让 vx 和 vy 在空间上尽量平滑(不能跳跃太大)
数学目标变成一个能量最小化问题:
E=数据误差+λ⋅平滑惩罚
其中 λ 控制“平滑重要性”:
-
λ 大:更平滑,但细节少
-
λ 小:细节保留好,但噪声多
✅ 优点:
-
能全局考虑整幅图,保留连续性
❌ 缺点:
-
数学复杂
-
计算慢
🧠 实际应用举例:
| 应用场景 | 使用哪种方法 |
|---|---|
| 小目标、摄像头稳定 | Lucas-Kanade |
| 大范围流动、水面波动 | Horn-Schunck |
| 车流分析、动作捕捉 | Optical Flow (变体) |
🚶 第二部分:单目标跟踪 Object Tracking
🧠 什么是目标跟踪(Object Tracking)?
在一段视频中,持续地追踪一个目标的位置和状态。
比如:
-
你要一直追踪视频中的某一个人
-
他从左走到右,视频有 30 帧
-
你要知道每一帧他在哪里(用框框框住他)
📌 跟踪 vs 检测的区别?
| 任务 | 检测(Detection) | 跟踪(Tracking) |
|---|---|---|
| 每帧处理 | 是,重新识别 | 否,用上一帧预测当前位置 |
| 输入 | 每帧独立图像 | 连续图像序列 |
| 输出 | 当前帧中所有目标的位置 | 特定目标在整个序列中的轨迹 |
| 开销 | 大(重复识别) | 小(预测+更新) |
🎯 Tracking-by-Detection 框架
一种流行策略是:
先检测(每一帧用目标检测器找目标),再用跟踪器“追踪”这个目标。
📐 步骤如下:
-
检测器在第 1 帧中找到目标(如一个人)
-
跟踪器记录这个人的位置(比如:中心点、速度)
-
到下一帧:根据之前的位置“预测”现在应该在哪
-
实际测量当前位置 → 校正
🧰 实现目标跟踪的常用方法(两个核心滤波器):
1️⃣ Kalman Filter(卡尔曼滤波)——适合线性+高斯噪声场景
🧠 卡尔曼滤波适合什么任务?
你跟踪的物体是“平稳移动”的,比如:人走路、小车移动
🎯 它做两件事:
| 步骤 | 说明 |
|---|---|
| 预测 | 根据“运动模型”预测目标下一个位置 |
| 更新 | 根据“实际测量”修正位置(结合当前帧检测框) |
📐 数学逻辑:

✅ 优点:
-
速度快
-
数学清晰,有闭式解
-
适合实际系统(摄像头、雷达)
❌ 缺点:
-
假设线性 + 高斯
-
无法处理跳跃、不规则动作(如:人突然跑)
2️⃣ Particle Filter(粒子滤波)——适合复杂运动、不规则情况
🧠 核心思想:
用很多“粒子”来表示目标的可能位置。每个粒子是一个猜测,谁更像目标,就给它更高的权重。
📷 类比理解:
-
你在丛林里追踪一个逃跑的人
-
你不知道他在哪,但你有 100 个探员(粒子)去“猜”他可能的位置
-
每帧你会根据图像反馈来更新这些探员的“猜测可信度”
-
下一帧你重新采样+移动探员 → 持续追踪
✅ 粒子滤波过程:
-
初始化:生成一堆粒子,代表各种可能位置
-
预测:每个粒子根据运动模型前进
-
赋权重:根据当前图像(比如目标外观)评估粒子
-
重采样:根据权重选择新的粒子集合
-
估计位置:权重最大的粒子 → 当前目标位置
✅ 优点:
-
可以处理非线性、非高斯问题
-
支持遮挡、多假设、目标跳跃
❌ 缺点:
-
计算量大(每帧计算多次)
-
粒子数太少 → 会偏移
-
粒子数太多 → 算得慢
📋 总结表:Kalman vs Particle
| 特性 | Kalman 滤波 | 粒子滤波 |
|---|---|---|
| 运动建模 | 线性 | 可非线性 |
| 噪声分布 | 高斯 | 任意分布 |
| 表达方式 | 高斯均值+协方差 | 一堆粒子(样本) |
| 是否支持多峰估计 | ❌ | ✅(可多个猜测) |
| 速度 | 快 | 较慢 |
📍 实际应用建议:
-
人体跟踪(线性运动) → Kalman
-
跳跃/遮挡/视频抖动大 → Particle Filter
-
跟踪多个目标(MOT) → 结合检测框匹配 + 滤波器预测(如 SORT)
🎯 什么是 Multi-Object Tracking?
目标不止一个的时候,我们要“同时追踪多个目标”,而且要“知道谁是谁”。
🌟 比如你有这样的视频:
-
有 5 个人走来走去
-
有人进出画面
-
有人遮挡别人
你要做的就是:
| 帧数 | 人的位置 |
|---|---|
| 帧1 | Person1: (x1,y1), Person2: (x2,y2)... |
| 帧2 | Person1: (x1’,y1’), Person2: (x2’,y2’) |
| ... | ... |
你要持续追踪每一个人,不能搞混他们的 ID!
🧩 MOT 中面临的三大核心挑战
1️⃣ ID管理(Identity Switch)
ID Switch 是 MOT 中的最大问题之一。
模型错误地把 A 当作 B,把 B 当作 A(ID 互换)
📍 举例:
-
帧1:Person A 是 ID=1,Person B 是 ID=2
-
帧2:模型把 A 当成了 2,B 当成了 1 → ❌ ID Switch
2️⃣ 遮挡问题(Occlusion)
一个人被挡住了几帧怎么办?
-
不能直接删掉他
-
要预测他还“在场”,等出现时再继续跟踪他
3️⃣ 出入场问题(Entry / Exit)
-
新人进来时,应该分配一个新 ID(不能误认为是别人)
-
某人出画时,不能误判为“消失”,更不能转给别人
🏗️ MOT 系统结构 = Detection + Association + Tracking
一般框架:
-
Detection(检测)
用 Faster R-CNN、YOLO、SSD 等方法获取当前帧中所有人的位置(bounding box) -
Association(关联)
把当前帧的检测框和上一帧的目标一一匹配-
匹配好了:更新目标轨迹
-
匹配不上:可能是新目标 or 消失了
-
-
Tracking(预测+更新)
每个目标用 Kalman Filter 预测下一帧的移动
再结合检测框做更新
🔧 一种经典算法:SORT
Simple Online and Realtime Tracking
🔁 工作流程:
-
用 YOLO 之类检测器获取当前帧中的目标框
-
用 Kalman Filter 为每个目标预测位置
-
用匈牙利算法(Hungarian Algorithm)进行匹配
-
利用 IOU(交并比)作为匹配代价
-
-
分配 ID,更新轨迹状态
✅ 优点:
-
实时运行(可以做到 30 FPS+)
-
效果不错,适合多目标行人跟踪
-
代码结构简单(所以叫 “Simple”)
❌ 缺点:
-
完全基于位置信息,没考虑“外观信息”
-
如果两个人交叉靠得很近,容易 ID Switch
-
遮挡多时很容易断开重连错人
🧬 改进版本:Deep SORT
SORT + 加上一个深度学习的“外观特征提取器”
💡 外观 Re-ID 模块:
-
给每个检测框抽取一个外观向量(如 128 维)
-
如果两个人的外观特征差别大 → 不匹配
-
如果特征很接近 → 可以认为是同一个人
⚙️ Deep SORT 多了哪些内容?
-
检测框 → 抽特征(用 CNN 网络)
-
把外观特征和位置信息结合起来
-
匹配时同时考虑 IOU 和 appearance similarity
✅ 优点:
-
减少 ID Switch
-
适合复杂遮挡、密集人群场景
-
更智能的目标识别与保持 ID 稳定性
🔢 MOT 评价指标(Multiple Object Tracking Metrics)
📊 常用指标:
| 指标 | 含义说明 |
|---|---|
| MOTA | Multi-object tracking accuracy,考虑了 ID switch、FP、FN 等综合评分,越高越好 |
| IDF1 | ID consistency,ID 保持一致的程度,越高越好 |
| FP | False Positives(检测了不存在的目标) |
| FN | False Negatives(漏检) |
| ID switches | ID 被换错的次数,越少越好 |
✅ 一句话记忆:
MOTA 越高越好,ID Switch 越低越好,IDF1 越接近 100 越好。
🛠️ 实际部署中,还要考虑的因素:
| 场景 | 实际困难 |
|---|---|
| 安防监控 | 摄像头抖动、视角偏差、多目标靠近 |
| 自动驾驶 | 光照变化、目标进出频繁、反射干扰 |
| 医学场景 | 多细胞遮挡、目标形状相似 |
| 体育分析 | 球员动态剧烈、视角切换快、相似球衣 |
✅ 三大算法对比总结表:
| 算法 | 用途 | 是否用外观 | 速度 | 稳定性 |
|---|---|---|---|---|
| SORT | 实时场景 | ❌ | ⚡ 非常快 | ❌ 容易ID错 |
| Deep SORT | 精确场景 | ✅(Re-ID) | 🟢 中速 | ✅ 更稳定 |
| ByteTrack | 无需外观、用全部框 | ❌(更鲁棒) | 🟢 快 | ✅ 精度高 |
✅ 本节小结:
| 技术 | 关键词 |
|---|---|
| MOT 核心流程 | 检测 + 匹配 + 跟踪更新 |
| SORT | Kalman + IOU + 匈牙利算法 |
| Deep SORT | SORT + 外观特征提取 |
| 难点 | 遮挡、ID切换、出入场判断 |
| 评估指标 | MOTA, IDF1, ID Switch |
例题

✅ 正确答案:B ❌
🔍 每个选项逐项解释:
✅ A 是正确的:
图像差分法(Image Subtraction)是基于帧之间像素变化检测运动物体。
这在背景稳定(如静止摄像头)时最有效,因为背景不动,变化就代表“前景目标动了”。
❌ B 是错误的:
Template Matching(模板匹配)常用相似度度量如:
SAD(Sum of Absolute Differences)绝对差和 ✅
SSD(Sum of Squared Differences)平方差和 ✅
Cross-correlation 互相关 ✅
而 Mutual Information(互信息)是图像配准(medical imaging 等)常用,不是模板匹配中主流选择,而且是要最大化不是最小化。
✅ C 是正确的:
Optical Flow(光流)假设图像中每个小区域在时间上保持“局部一致性”——亮度不变、形状小变化,这样才便于追踪。
✅ D 是正确的:
光流约束方程(Optical Flow Constraint Equation):
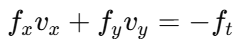
只有一个方程(每像素),但未知量有两个(vx, vy) → 方程不够 → 需要额外约束(如:邻域平滑、Lucas-Kanade)
🧠 总结记忆点:
点 解释 图像差分 适合背景恒定 模板匹配 用的是 SSD / SAD / CC,不是 MI 光流 假设邻域不变(小区域亮度恒定) 光流方程不够 一个像素两个未知,需加约束求解

✅ 正确答案:A ❌
🔍 每个选项逐项解释:
❌ A 是错误的:
Particle Filter(粒子滤波)不要求模型必须有显式参数形式。
它的优势在于可以处理 非线性、非高斯 的模型,通过采样(粒子)进行近似。
它只需要能“采样”模型的动态和观测,不需要显式参数表达。
✅ B 是正确的:
HMM(隐马尔可夫模型)假设:
状态只依赖前一个状态
当前观测值 只依赖于当前状态
符合“马尔可夫性质”
✅ C 是正确的:
贝叶斯跟踪中的预测步骤通常基于 当前状态只依赖上一个状态。
即:
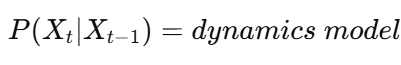
✅ D 是正确的:
卡尔曼滤波要求:
模型是线性的
噪声是加性高斯分布(Additive Gaussian)
🧠 小技巧记忆:
方法 是否需要参数模型? Kalman ✅ 线性、高斯 Particle Filter ❌ 不要求参数表达