【CRF系列】第5篇:CRF的学习:参数估计与优化算法
【CRF系列】第5篇:CRF的学习:参数估计与优化算法
1. 引言
在之前的文章中,我们了解了CRF的基本概念、理论基础、数学形式,以及特征函数的设计。现在,我们面临着一个关键问题:如何确定这些特征函数的权重?也就是说,如何训练一个CRF模型?
想象一下:我们已经设计好了成百上千个特征函数,它们能够捕捉输入序列中各种有用的模式。但如果不知道这些特征的重要性(权重),这些特征函数就像是一把没有调音的钢琴琴键——按下去没有和谐的旋律。
本篇文章将深入探讨CRF的参数估计(学习)过程。我们将讨论:
- 如何定义CRF的学习目标(最大化对数似然函数)
- 如何计算梯度(涉及特征函数的期望)
- 如何高效计算归一化因子和特征期望(前向-后向算法)
- 常用的优化算法(特别是L-BFGS)及其优势
虽然这部分内容涉及较多数学推导,但我们会尽量通过直观解释和类比,让这些概念变得清晰易懂。毕竟,理解CRF的训练过程,对于真正掌握这一强大模型至关重要。
2. 学习目标:最大化对数似然函数
2.1 条件对数似然函数
CRF的学习目标很直观:给定训练数据,我们希望找到一组参数,使得模型预测的标签序列尽可能接近真实标签序列。
具体来说,假设我们有一个训练集 { ( X ( j ) , Y ( j ) ) } j = 1 N \{(X^{(j)}, Y^{(j)})\}_{j=1}^N {(X(j),Y(j))}j=1N,包含N个训练样本,每个样本由观测序列 X ( j ) X^{(j)} X(j) 和对应的标签序列 Y ( j ) Y^{(j)} Y(j) 组成。我们希望最大化这些样本的条件对数似然函数:
L ( θ ) = ∑ j = 1 N log P ( Y ( j ) ∣ X ( j ) ; θ ) L(\theta) = \sum_{j=1}^N \log P(Y^{(j)}|X^{(j)}; \theta) L(θ)=j=1∑NlogP(Y(j)∣X(j);θ)
其中 θ \theta θ 是模型参数(特征函数的权重), P ( Y ( j ) ∣ X ( j ) ; θ ) P(Y^{(j)}|X^{(j)}; \theta) P(Y(j)∣X(j);θ) 是给定参数 θ \theta θ 下,观测序列 X ( j ) X^{(j)} X(j) 产生标签序列 Y ( j ) Y^{(j)} Y(j) 的条件概率。
将CRF的条件概率公式代入,我们得到:
L ( θ ) = ∑ j = 1 N [ ∑ i = 1 n j ∑ k = 1 K θ k f k ( y i − 1 ( j ) , y i ( j ) , X ( j ) , i ) − log Z ( X ( j ) ; θ ) ] L(\theta) = \sum_{j=1}^N \left[ \sum_{i=1}^{n_j} \sum_{k=1}^K \theta_k f_k(y_{i-1}^{(j)}, y_i^{(j)}, X^{(j)}, i) - \log Z(X^{(j)}; \theta) \right] L(θ)=j=1∑N[i=1∑njk=1∑Kθkfk(yi−1(j),yi(j),X(j),i)−logZ(X(j);θ)]
其中:
- n j n_j nj 是第j个样本的序列长度
- K K K 是特征函数的总数
- f k f_k fk 是第k个特征函数
- Z ( X ( j ) ; θ ) Z(X^{(j)}; \theta) Z(X(j);θ) 是归一化因子
这个学习目标有一个直观解释:我们希望增大真实标签序列的概率(公式第一部分),同时减小所有可能标签序列的概率之和(通过减小归一化因子,公式第二部分)。
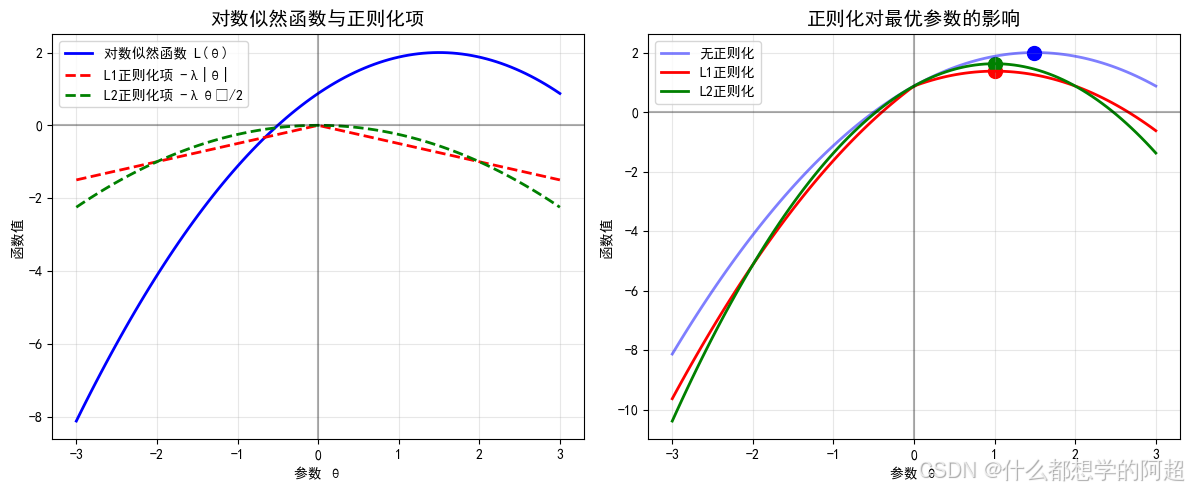
2.2 添加正则化项
为了防止过拟合,通常会在对数似然函数中添加一个正则化项:
L reg ( θ ) = L ( θ ) − λ 2 ∥ θ ∥ 2 L_{\text{reg}}(\theta) = L(\theta) - \frac{\lambda}{2} \|\theta\|^2 Lreg(θ)=L(θ)−2λ∥θ∥2
其中 λ \lambda λ 是正则化强度, ∥ θ ∥ 2 = ∑ k = 1 K θ k 2 \|\theta\|^2 = \sum_{k=1}^K \theta_k^2 ∥θ∥2=∑k=1Kθk2 是参数的L2范数平方。这相当于对参数加入了先验知识,假设参数服从均值为0的高斯分布。
L2正则化(或称为权重衰减)鼓励参数值保持较小,从而防止模型对训练数据过度拟合。
另一种选择是L1正则化:
L reg ( θ ) = L ( θ ) − λ ∥ θ ∥ 1 L_{\text{reg}}(\theta) = L(\theta) - \lambda \|\theta\|_1 Lreg(θ)=L(θ)−λ∥θ∥1
其中 ∥ θ ∥ 1 = ∑ k = 1 K ∣ θ k ∣ \|\theta\|_1 = \sum_{k=1}^K |\theta_k| ∥θ∥1=∑k=1K∣θk∣ 是参数的L1范数。L1正则化倾向于产生稀疏解,即许多参数会变为0,相当于进行了特征选择。
3. 梯度计算:挑战与方法
要最大化对数似然函数,我们需要计算它相对于每个参数 θ k \theta_k θk 的偏导数(梯度),然后使用梯度上升(或者对负的对数似然函数使用梯度下降)来更新参数。
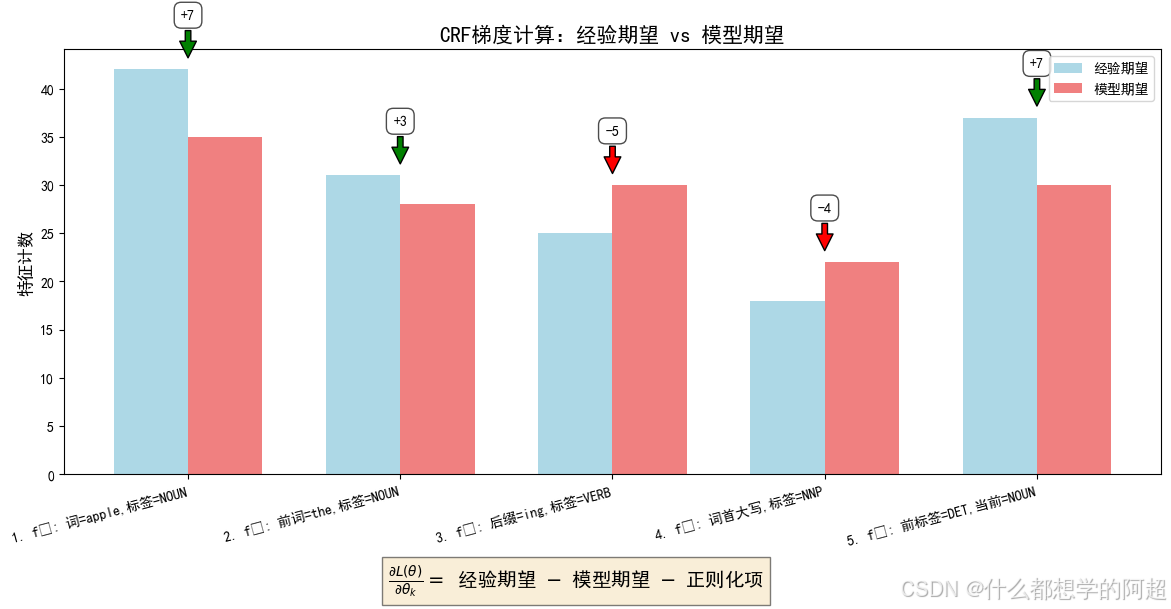
3.1 对数似然函数的梯度
对带L2正则化的对数似然函数求导,我们得到:
∂ L reg ( θ ) ∂ θ k = ∑ j = 1 N ∑ i = 1 n j f k ( y i − 1 ( j ) , y i ( j ) , X ( j ) , i ) − ∑ j = 1 N ∑ Y ′ P ( Y ′ ∣ X ( j ) ; θ ) ∑ i = 1 n j f k ( y i − 1 ′ , y i ′ , X ( j ) , i ) − λ θ k \frac{\partial L_{\text{reg}}(\theta)}{\partial \theta_k} = \sum_{j=1}^N \sum_{i=1}^{n_j} f_k(y_{i-1}^{(j)}, y_i^{(j)}, X^{(j)}, i) - \sum_{j=1}^N \sum_{Y'} P(Y'|X^{(j)}; \theta) \sum_{i=1}^{n_j} f_k(y'_{i-1}, y'_i, X^{(j)}, i) - \lambda\theta_k ∂θk∂Lreg(θ)=j=1∑Ni=1∑njfk(yi−1(j),yi(j),X(j),i)−j=1∑NY′∑P(Y′∣X(j);θ)i=1∑njfk(yi−1′,yi′,X(j),i)−λθk
这个梯度有三部分:
- 经验期望(第一项):特征 f k f_k fk 在训练数据上的实际出现次数。
- 模型期望(第二项):特征 f k f_k fk 在模型当前参数下的期望出现次数。
- 正则化项(第三项):参数本身乘以正则化系数。
直观上,这个梯度表示:如果某个特征在训练数据中的实际出现次数大于模型预期的出现次数,那么我们应该增大这个特征的权重;反之则减小。
3.2 计算难点:模型期望
梯度计算中最大的挑战是第二项——模型期望。这一项需要对所有可能的标签序列 Y ′ Y' Y′ 求和,数量随序列长度呈指数增长,直接计算不可行。
举例来说,对于一个长度为10的序列,如果每个位置有5种可能的标签,那么可能的标签序列总数为 5 10 = 9 , 765 , 625 5^{10} = 9,765,625 510=9,765,625。而实际应用中,序列长度通常更长,标签数量也可能更多,使得穷举所有可能的标签序列变得不可能。
幸运的是,我们可以使用动态规划算法——前向-后向算法(Forward-Backward Algorithm)来高效计算这个期望值。
4. 归一化因子 Z ( X ) Z(X) Z(X) 与特征期望的计算:前向-后向算法
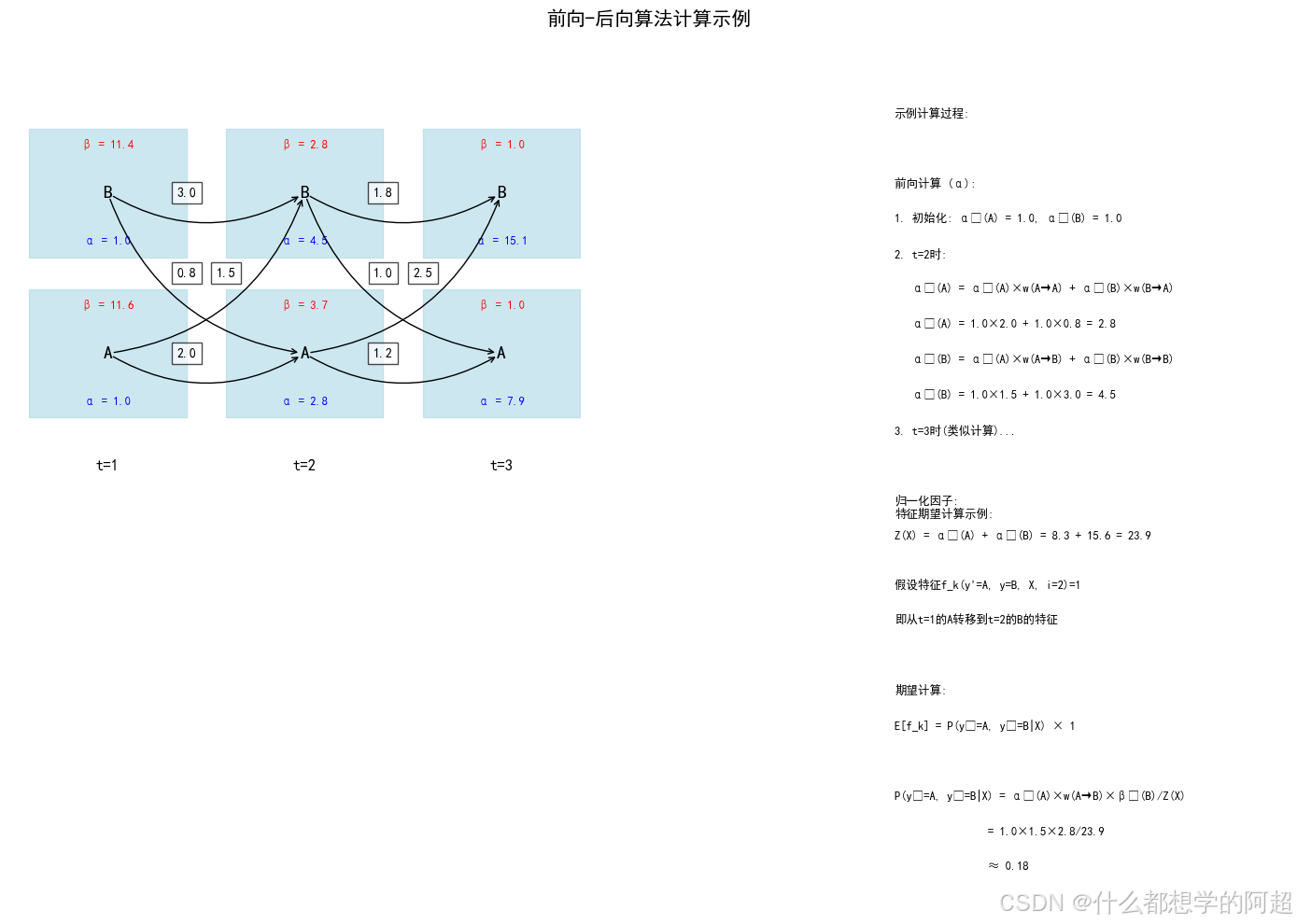
4.1 前向算法(Forward Algorithm)
前向算法用于计算归一化因子 Z ( X ) Z(X) Z(X)。
定义前向变量 α i ( y ) \alpha_i(y) αi(y) 为:从序列开始到位置 i i i、位置 i i i 的标签为 y y y 的所有路径的(未归一化)得分之和。
递推公式:
α 1 ( y ) = exp ( ∑ k θ k f k ( START , y , X , 1 ) ) \alpha_1(y) = \exp\left(\sum_k \theta_k f_k(\text{START}, y, X, 1)\right) α1(y)=exp(k∑θkfk(START,y,X,1))
α i ( y ) = ∑ y ′ α i − 1 ( y ′ ) exp ( ∑ k θ k f k ( y ′ , y , X , i ) ) \alpha_i(y) = \sum_{y'} \alpha_{i-1}(y') \exp\left(\sum_k \theta_k f_k(y', y, X, i)\right) αi(y)=y′∑αi−1(y′)exp(k∑θkfk(y′,y,X,i))
其中, START \text{START} START 是一个特殊的开始标签。
最终,归一化因子 Z ( X ) Z(X) Z(X) 可以通过所有可能的结束标签 y y y 的前向变量求和得到:
Z ( X ) = ∑ y α n ( y ) Z(X) = \sum_y \alpha_n(y) Z(X)=y∑αn(y)
其中 n n n 是序列长度。
4.2 后向算法(Backward Algorithm)
类似地,我们定义后向变量 β i ( y ) \beta_i(y) βi(y) 为:从位置 i i i(标签为 y y y)到序列结束的所有路径的(未归一化)得分之和。
递推公式:
β n ( y ) = exp ( ∑ k θ k f k ( y , STOP , X , n + 1 ) ) \beta_n(y) = \exp\left(\sum_k \theta_k f_k(y, \text{STOP}, X, n+1)\right) βn(y)=exp(k∑θkfk(y,STOP,X,n+1))
β i ( y ) = ∑ y ′ β i + 1 ( y ′ ) exp ( ∑ k θ k f k ( y , y ′ , X , i + 1 ) ) \beta_i(y) = \sum_{y'} \beta_{i+1}(y') \exp\left(\sum_k \theta_k f_k(y, y', X, i+1)\right) βi(y)=y′∑βi+1(y′)exp(k∑θkfk(y,y′,X,i+1))
其中, STOP \text{STOP} STOP 是一个特殊的结束标签。
同样,可以通过所有可能的开始标签的后向变量计算归一化因子:
Z ( X ) = ∑ y β 1 ( y ) Z(X) = \sum_y \beta_1(y) Z(X)=y∑β1(y)
4.3 计算特征期望
有了前向和后向变量,我们可以高效计算特征期望。对于特征函数 f k f_k fk,其在模型下的期望值为:
E [ f k ] = ∑ i = 1 n ∑ y ′ , y P ( y i − 1 = y ′ , y i = y ∣ X ) f k ( y ′ , y , X , i ) E[f_k] = \sum_{i=1}^n \sum_{y', y} P(y_{i-1}=y', y_i=y | X) f_k(y', y, X, i) E[fk]=i=1∑ny′,y∑P(yi−1=y′,yi=y∣X)fk(y′,y,X,i)
其中,条件概率 P ( y i − 1 = y ′ , y i = y ∣ X ) P(y_{i-1}=y', y_i=y | X) P(yi−1=y′,yi=y∣X) 可以通过前向和后向变量计算:
P ( y i − 1 = y ′ , y i = y ∣ X ) = α i − 1 ( y ′ ) exp ( ∑ k θ k f k ( y ′ , y , X , i ) ) β i ( y ) Z ( X ) P(y_{i-1}=y', y_i=y | X) = \frac{\alpha_{i-1}(y') \exp\left(\sum_k \theta_k f_k(y', y, X, i)\right) \beta_i(y)}{Z(X)} P(yi−1=y′,yi=y∣X)=Z(X)αi−1(y′)exp(∑kθkfk(y′,y,X,i))βi(y)
这样,我们就避免了对所有可能的标签序列进行枚举,将计算复杂度从指数级降到了多项式级。
4.4 一个简单的例子
为了具体理解前向-后向算法,我们来看一个极简例子:假设有一个长度为3的序列,每个位置可以标注为A或B,只考虑两个特征:当前词是"the"时标签为A的特征,以及标签从A转移到B的特征。
-
初始化前向变量:
- α 1 ( A ) = exp ( θ 1 ) \alpha_1(A) = \exp(\theta_1) α1(A)=exp(θ1)(假设第一个词是"the")
- α 1 ( B ) = 1 \alpha_1(B) = 1 α1(B)=1(假设特征不匹配)
-
递推计算:
- α 2 ( A ) = α 1 ( A ) × 1 + α 1 ( B ) × 1 \alpha_2(A) = \alpha_1(A) \times 1 + \alpha_1(B) \times 1 α2(A)=α1(A)×1+α1(B)×1(假设没有匹配的特征)
- α 2 ( B ) = α 1 ( A ) × exp ( θ 2 ) + α 1 ( B ) × 1 \alpha_2(B) = \alpha_1(A) \times \exp(\theta_2) + \alpha_1(B) \times 1 α2(B)=α1(A)×exp(θ2)+α1(B)×1(A到B的转移特征匹配)
- …以此类推计算 α 3 ( A ) \alpha_3(A) α3(A) 和 α 3 ( B ) \alpha_3(B) α3(B)
-
计算归一化因子:
- Z ( X ) = α 3 ( A ) + α 3 ( B ) Z(X) = \alpha_3(A) + \alpha_3(B) Z(X)=α3(A)+α3(B)
通过类似步骤可以计算后向变量,最终得到每个特征的期望值。
5. 优化算法
有了梯度计算方法,我们可以使用各种优化算法来最大化对数似然函数。
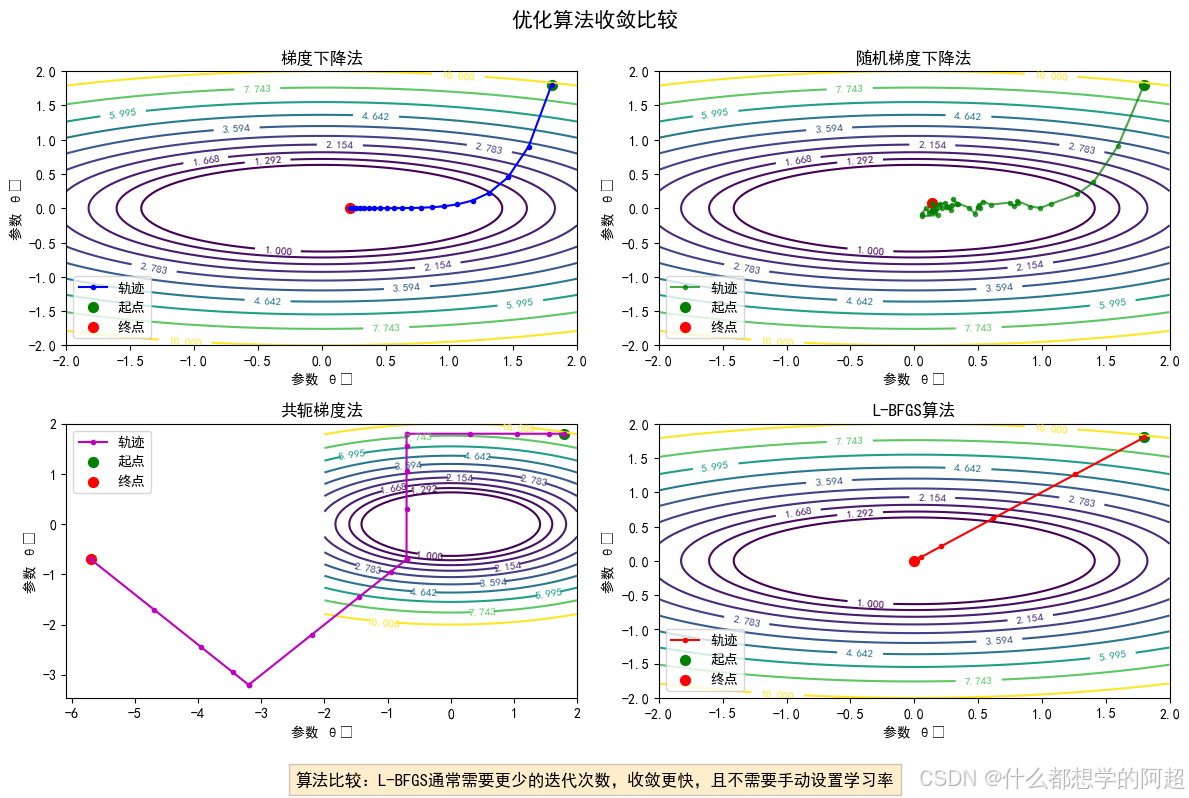
5.1 梯度下降法(Gradient Descent)
最简单的方法是梯度下降(确切地说是梯度上升,因为我们是最大化目标函数):
θ ( t + 1 ) = θ ( t ) + η ∇ L reg ( θ ( t ) ) \theta^{(t+1)} = \theta^{(t)} + \eta \nabla L_{\text{reg}}(\theta^{(t)}) θ(t+1)=θ(t)+η∇Lreg(θ(t))
其中, η \eta η 是学习率, ∇ L reg ( θ ( t ) ) \nabla L_{\text{reg}}(\theta^{(t)}) ∇Lreg(θ(t)) 是梯度向量。
梯度下降简单直观,但收敛慢,且对学习率敏感。对于CRF这种有大量参数的模型,不太适合直接使用梯度下降。
5.2 随机梯度下降(Stochastic Gradient Descent)
一个改进是随机梯度下降(SGD),每次只使用一个或一小批样本估计梯度:
θ ( t + 1 ) = θ ( t ) + η ∇ L reg,batch ( θ ( t ) ) \theta^{(t+1)} = \theta^{(t)} + \eta \nabla L_{\text{reg,batch}}(\theta^{(t)}) θ(t+1)=θ(t)+η∇Lreg,batch(θ(t))
SGD计算更快,但收敛轨迹更加嘈杂,仍需要仔细调整学习率。
5.3 共轭梯度法(Conjugate Gradient)
共轭梯度法是一种更高级的优化算法,它考虑了梯度的先前方向,通常比梯度下降收敛更快。
它的核心思想是:新的搜索方向不仅考虑当前梯度,还要与先前的搜索方向"共轭"(正交)。这样可以避免在优化过程中的震荡,提高收敛速度。
5.4 L-BFGS算法
有限内存BFGS(L-BFGS) 是训练CRF最常用的算法,包括CRF++在内的大多数CRF工具也默认使用L-BFGS。
BFGS(Broyden–Fletcher–Goldfarb–Shanno)算法是一种拟牛顿法,通过近似计算Hessian矩阵(目标函数的二阶导数矩阵)的逆来加速优化。
L-BFGS是BFGS的改进版,不需要存储完整的Hessian矩阵逆,而是保存最近的m次迭代中的梯度差向量,用它们来近似Hessian矩阵逆的乘法操作。这大大减少了内存需求,使算法适用于大规模优化问题。
L-BFGS的优势:
- 收敛速度快:通常比梯度下降和共轭梯度法需要更少的迭代次数。
- 无需手动设置学习率:自动调整步长,减少了超参数调优的负担。
- 内存需求适中:对于大型模型也能高效运行。
- 对初始点不太敏感:比一些其他优化方法更稳定。
为什么L-BFGS适合CRF:
CRF的目标函数通常是"平滑"且"凸"的(至少对于线性特征函数),L-BFGS在这类问题上表现极佳。同时,CRF的参数通常很多(可能达到数百万),L-BFGS的低内存需求使它成为理想选择。
6. 总结与展望
本篇文章中,我们深入探讨了CRF的参数学习过程:
- 学习目标:最大化带正则化的条件对数似然函数。
- 梯度计算:涉及特征函数在训练数据上的经验期望和在模型下的期望。
- 前向-后向算法:高效计算归一化因子和特征期望,避免指数级的计算复杂度。
- 优化算法:从简单的梯度下降到高效的L-BFGS,帮助我们找到最优参数。
CRF的训练涉及复杂的数学运算和算法,但通过本文的解析,希望它们变得更加清晰易懂。理解这些过程不仅有助于深入掌握CRF原理,也能帮助我们更好地使用和调优CRF模型。
在下一篇文章**【CRF系列】第6篇:CRF的预测:维特比(Viterbi)解码详解**中,我们将讨论模型训练好后,如何使用它进行预测——即给定一个新的观测序列,如何找到最可能的标签序列。
7. 思考题
-
前向算法与HMM中的前向算法有何相似之处和区别?(提示:考虑它们的目的、递推公式和计算对象)
-
为什么说计算模型期望(第二项梯度)比计算经验期望(第一项梯度)要困难得多?是否有方法可以进一步提高模型期望的计算效率?