深度大脑:AI大模型的设计与运行原理
AI大模型的设计与运行原理涉及多个复杂环节,以下是系统化的总结,结合核心要点与补充细节:

一、AI大模型的设计
1. 深度神经网络架构
Transformer:取代RNN/CNN,解决长程依赖问题。核心组件:
自注意力机制:通过查询(Query)、键(Key)、值(Value)向量计算注意力权重,公式为:
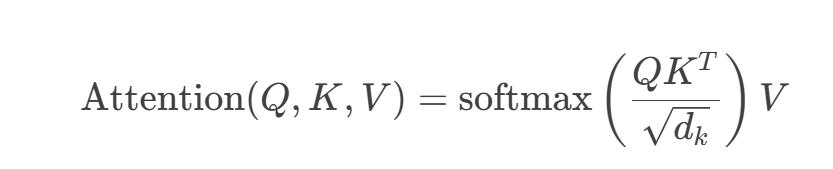
其中,dkdk为向量维度,缩放避免梯度消失。
多头注意力:并行多个注意力头,增强模型捕捉不同上下文特征的能力。
位置编码:注入序列位置信息,常用正弦函数或可学习参数。
前馈网络(FFN):对注意力输出进行非线性变换。
2. 预训练与微调范式
预训练任务:
BERT(Encoder):掩码语言建模(MLM)和下一句预测(NSP),双向上下文建模。
GPT(Decoder):自回归语言建模,逐词预测,适合生成任务。
微调:全参数更新或参数高效方法(如LoRA、Adapter),适配下游任务。
3. 模型规模化
参数增长:如GPT-3达1750亿参数,涌现few/zero-shot能力。
稀疏模型:混合专家(MoE)架构(如Switch Transformer),动态激活子网络。
二、运行原理
- 前向传播
- 输入通过嵌入层→位置编码→多Transformer层(自注意力→FFN)→输出层。
- 生成式推理:自回归生成(如GPT),采样策略包括贪心、beam search、top-k/p。
- 训练过程
- 损失函数:交叉熵损失,优化器(AdamW)结合学习率调度(如warmup)。
- 分布式训练:
- 数据并行:多卡拆分数据。
- 模型并行:Tensor并行(横向切分层)、Pipeline并行(纵向切分模型)。
- 内存优化:ZeRO(微软)、梯度检查点(重计算中间激活)。
- 硬件加速:GPU/TPU集群,混合精度训练(FP16/BF16)加速计算。
- 推理优化
- 技术:模型量化(INT8)、知识蒸馏(小模型模仿大模型)、KV缓存(减少重复计算)。
- 推测解码:并行候选生成,加速自回归过程。
三、应用与挑战
- 应用场景
- 多模态:CLIP(图文对齐)、DALL-E(文生图)、GPT-4V(多模态交互)。
- 跨领域:蛋白质结构预测(AlphaFold)、代码生成(Codex)。
- 核心挑战
- 算力与数据:千亿级参数需数月训练、千卡集群,数据清洗与版权争议。
- 安全与伦理:生成内容的偏见/虚假信息,隐私泄露风险(如训练数据记忆)。
- 可解释性:黑箱模型决策机制不明,研究聚焦注意力可视化、探针工具。
- 环境影响:高能耗碳足迹,需绿色AI技术(模型压缩、高效架构)。
四、前沿方向
- 架构创新:Retro Transformer(检索增强)、FlashAttention(高效注意力计算)。
- 训练优化:稀疏训练、动态网络结构。
- 伦理治理:内容审核、公平性评估、开源与闭源模型监管。
通过上述设计原理与技术创新,AI大模型持续突破性能边界,但其发展需平衡能力提升与伦理、资源消耗的制约。