微服务即时通信系统---(四)框架学习
目录
ElasticSearch
介绍
安装
安装kibana
ES客户端安装
头文件包含和编译时链接库
ES核心概念
索引(Index)
类型(Type)
字段(Field)
映射(mapping)
文档(document)
ES对比MySQL
Kibana访问ES测试
创建索引库
新增数据
查看并搜索数据
删除索引
ES客户端接口介绍
ES二次封装(elasticSearch.hpp)
Json序列化
Json反序列化
创建索引(库)
插入数据
删除数据
数据搜索(查询)
二次封装测试
ES客户端操作句柄获取封装
cpp-httplib
介绍
安装
头文件和链接库
类于接口介绍
HTTP请求类
HTTP应答类
HTTP服务器类
HTTP客户端类
使用样例
websocketpp
Websocket协议介绍
Websocketpp介绍
WebSocketpp安装
类与接口
日志等级
状态码
数据帧类型
消息缓冲区
HTTP请求解析
connect连接后的相关操作(对请求进行响应)
服务器
endpoint(服务端/客户端的管理)
redis
介绍
安装
头文件包含和编译时链接库
接口介绍
Redis++客户端操作句柄获取封装
本章主要是学习和使用本项目中所需使用到的一些框架。
ElasticSearch
介绍
ElasticSearch,简称ES,是一个开源分布式搜索引擎。
它的特点有:分布式、零配置、自动发现、索引自动分片、索引副本机制、restful风格接口、多数据源、自动搜索负载等。
ES是面向文档的,意味着它可以存储整个对象或文档。
它不仅仅是存储,还会索引每个文档的内容,使之可以被搜索。
在ES中,可以对文档进行索引、搜索、排序、过滤。
安装
# 添加仓库秘钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -# 添加镜像源仓库
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list # 更新软件包列表
sudo apt update # 安装es
sudo apt-get install elasticsearch=7.17.21 # 启动es
sudo systemctl start elasticsearch # 安装ik分词器插件
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install
https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21启动ES报错:
![]()
解决办法:
调整ES虚拟内存,虚拟内存默认最大映射数为65530,无法满足ES系统要求, 需要调整为262144以上。
sudo sysctl -w vm.max_map_count=262144在 /etc/elasticsearch/jvm.options中新增:
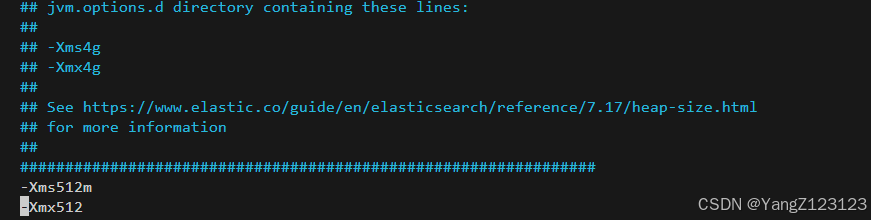
再次启动ES:成功。
但是我自己重新弄的时候,一直启动失败,后续查看日志发现:
sudo vim /var/log/elasticsearch/elasticsearch.log
前面下载的分词器,和当前版本不兼容(我的ES升级了,所以不兼容),于是寻找解决方案:删除旧版本分词器,下载与当前elasticsearch匹配的分词器:
sudo rm -rf /usr/share/elasticsearch/plugins/analysis-iksudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.25/elasticsearch-analysis-ik-7.17.25.zipsudo systemctl restart elasticsearch.service此时才完美解决。
验证ES是否安装启动成功:
curl -X GET "http://localhost:9200/"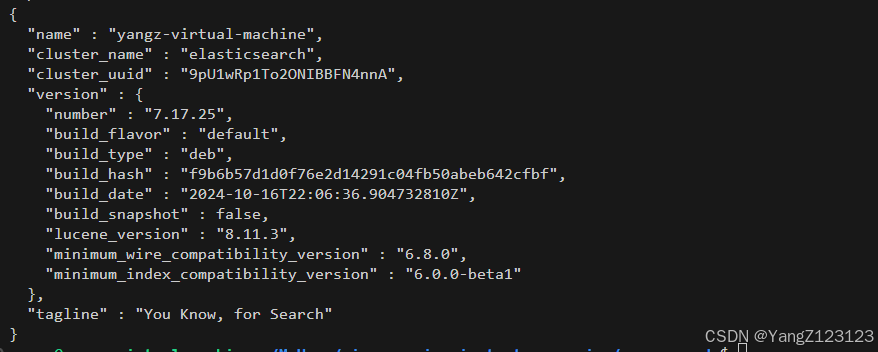
设置外网访问,如果新配置完成的话,默认只能在本机进行访问:
sudo vim /etc/elasticsearch/elasticsearch.yml![]()
![]()
此时用浏览器访问 "localhost:9200":
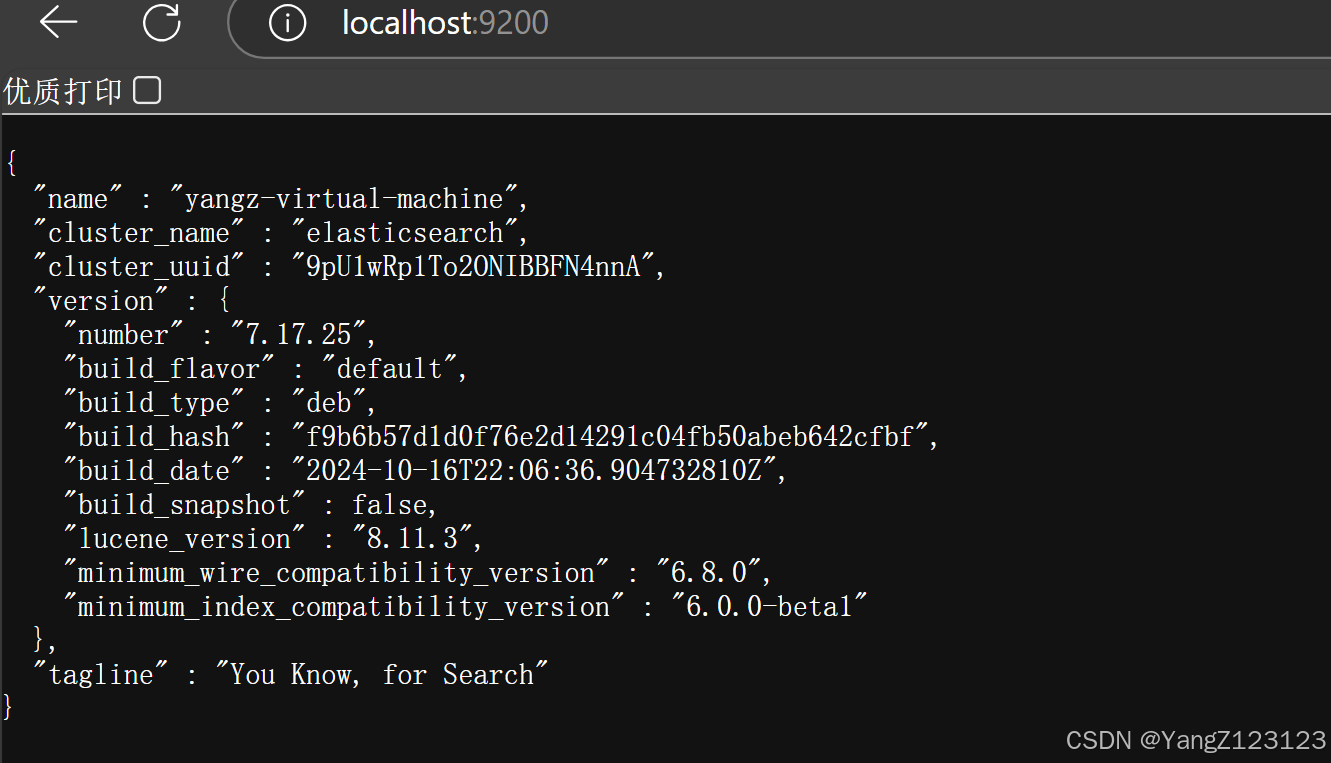
安装kibana
Kibana 是一个开源的数据可视化工具,专门为 Elasticsearch 设计。它提供了一个用户友好的界面,用于搜索、查看和分析存储在 Elasticsearch 中的数据。Kibana 通常与 Elasticsearch 一起使用,是 Elastic Stack(以前称为 ELK Stack,包括 Elasticsearch、Logstash 和 Kibana)的核心组件之一。
在浏览器上访问:"localhost:5601"。
命令安装:
sudo apt install kibana配置 Kibana(可选):
根据需要配置 Kibana。配置文件通常位于 /etc/kibana/kibana.yml。可能需要
设置如服务器地址、端口、Elasticsearch URL 等。
sudo vim /etc/kibana/kibana.yml
例如,你可能需要设置 Elasticsearch 服务的 URL: 大概32行左右
elasticsearch.host: "http://localhost:9200"ES客户端安装
sudo apt-get install libmicrohttpd-dev # 克隆代码
git clone https://github.com/seznam/elasticlient # 切换目录
cd elasticlient # 更新子模块
git submodule update --init --recursive # 编译代码
mkdir build
cd build
cmake ..
make # 安装
make install # make的时候编译出错,这是子模块googletest没有编译安装
# 解决: 手动安装子模块
cd ../external/googletest/
mkdir cmake && cd cmake/
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
make && sudo make install # 安装好了 再次 cmake即可头文件包含和编译时链接库
头文件
#include <cpr/response.h>
#include <elasticlient/client.h>库:
-lcpr -lelasticlientES核心概念
索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。
比如说,你可以有一个客户数据 的索引,一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标 识(必须全部是小写字母的),并且当我们要对应于这个索引中的文档进行索引、搜索、 更新和删除的时候,都要使用到这个名字。
类型(Type)
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分 类/分区,其语义完全由你来定。
通常,会为具有一组共同字段的文档定义一个类型。
比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这 个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,为评论数 据定义另一个类型......
字段(Field)
| 分类 | 类型 | 备注 |
| 字符串 | text、keyword | text会被分词生成索引。 keyword不会被分词生成索引,只能精确搜索。 |
| 整形 | integer、long、short、byte | |
| 浮点 | double、float | |
| 逻辑 | boolean | true 或者 false |
| 日期 | date、date_nanos | “2018-01-13” 或 “2018-01-13 12:10:30” 或者时间戳,即1970到现在的秒数/毫秒数 |
| 二进制 | binary | 二进制通常只存储,不索引。 |
| 范围 | range |
映射(mapping)
映射是在处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、 分析器、是否被索引等等。
其它就是处理es里面数据 的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
| 名称 | 数值 | 备注 |
| enabled | true(默认)、false | 是否仅作存储,不做搜索和分析。 |
| index | true(默认)、false | 是否构建倒排锁芯(决定了是否分词,是否被索引)。 |
| index_option | ||
| dynamic | true(默认)、false | 控制mapping的自动更新。 |
| doc_value | true(默认)、false | 是否开启doc_value,用户聚合和排序分析,分词字段不能使用。 |
| fielddata | "fielddata" : {"format" : "disabled"} | 是否为text类型启动fielddata,实现排序和 聚合分析。 针对分词字段,参与排序或聚合时能提高性 能。 不分词字段统一建议使用doc_value。 |
| store | true、false(默认) | 是否单独设置此字段的是否存储,储而从 _source 字段中分离。 只能搜索,不能获取值。 |
| coerce | true(默认)、false | 是否开启自动数据类型转换功能。 比如:字符串转数字,浮点转整型 |
| analyzer | "analyzer" : "ik" | 指定分词器,默认分词器是standard analyzer |
| boost | "boost" : 1.23 | 字段级别的分数加权,默认值是1.0 |
| fields | "fields" : { "raw" : { "type": "text", "index": "not_analyzed", } } | 对一个字段提供多种索引模式。 同一个字段的值,一个分词,一个不分词。 |
| data_detection | true(默认)、false | 是否自动识别日期类型 |
文档(document)
一个文档是一个可被索引的基础信息单元。
比如,你可以拥有某一个客户的文档,某 一个产品的一个文档或者某个订单的一个文档。
文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个 index/type 里面,你可以存储任意多的文档。
一个文档必须被索引或者赋予一个索引 的type。
ES对比MySQL
| MySQL | ES | 说明 |
| Database | Index | 最顶层的逻辑容器。 |
| Table | Type (ES 7.x之后) | 存储结构化数据的单元。 |
| Row | Document | 一条记录。 |
| Column | Field | 数据字段。 |
| Schema | Mapping | 定义数据结构。 |
| Index(索引) | Inverted Index | 加速查询的数据结构。 |
| SQL | Query DSL | 查询语言。 |
| Primary Key | _id | 唯一标识符。 |
| 分库分表 | Shard | 数据分片。 |
| 主从复制 | Replica Shard | 数据复制和高可用性。 |
| 事务 | 版本控制 | 数据一致性机制。 |
| 全文搜索 | 核心功能 | ES 专为全文搜索设计,功能更强大。 |
Kibana访问ES测试
创建索引库
POST /user/_doc
{ "settings" : { "analysis" : { "analyzer" : { "ik" : { "tokenizer" : "ik_max_word" } } } }, "mappings" : { "dynamic" : true, "properties" : { "nickname" : { "type" : "text","analyzer" : "ik_max_word" }, "user_id" : { "type" : "keyword", "analyzer" : "standard" }, "phone" : { "type" : "keyword", "analyzer" : "standard" }, "description" : { "type" : "text", "enabled" : false }, "avatar_id" : { "type" : "keyword" ,"enabled" : false } } }
}新增数据
POST /user/_doc/_bulk
{"index":{"_id":"1"}}
{"user_id" : "USER4b862aaa-2df8654a-7eb4bb65e3507f66","nickname" : "昵称1","phone" : "手机号1","description" : "签名1","avatar_id" : "头像1"}
{"index":{"_id":"2"}}
{"user_id" : "USER14eeeaa5-442771b9-0262e455e4663d1d","nickname" : "昵称2","phone" : "手机号2","description" : "签名2","avatar_id" : "头像2"}
{"index":{"_id":"3"}}
{"user_id" : "USER484a6734-03a124f0-996c169dd05c1869","nickname" : "昵称3","phone" : "手机号3","description" : "签名3","avatar_id" : "头像3"}
{"index":{"_id":"4"}}
{"user_id" : "USER186ade83-4460d4a6-8c08068f83127b5d","nickname" : "昵称4","phone" : "手机号4","des