注意力机制的改进
Transformer架构中的注意力机制优化是提升模型效率和扩展处理长序列能力的关键。以下从多个维度详细解析注意力机制的优化方法:
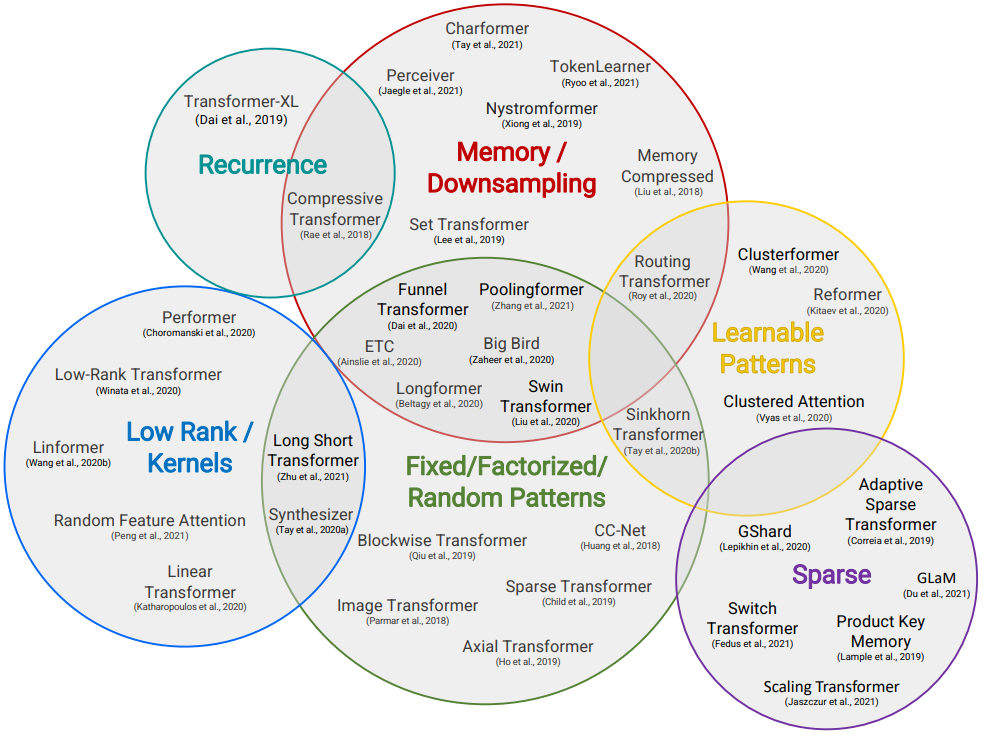
arXIv论文链接
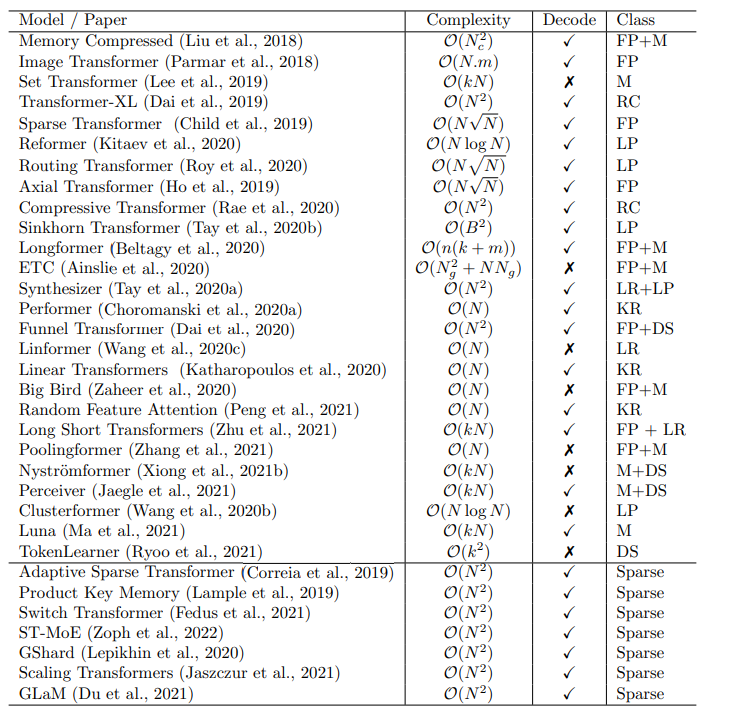
1. 稀疏注意力(Sparse Attention)
通过限制每个位置仅关注特定区域,减少计算量(从 O ( N 2 ) O(N^2) O(N2) 降至 O ( N ) O(N) O(N) 或 O ( N log N ) O(N \log N) O(NlogN))。
1.1 局部注意力(Local Attention)
-
原理:每个位置仅关注固定窗口内的邻近区域(如前后各50个token)。就是约束每个元素只与前后k个元素以及自身有关联,如下图所示:
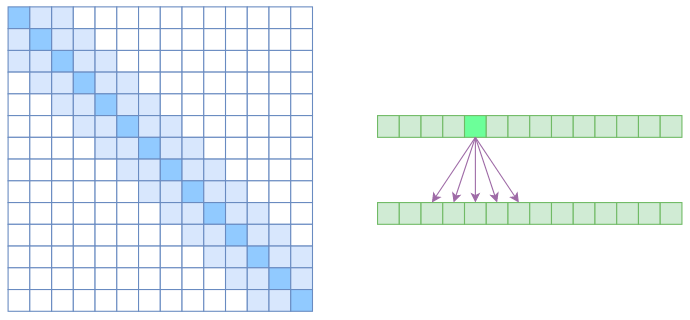
-
典型模型:
-
Local Transformer:适用于图像、语音等局部相关性强的任务。
-
Swin Transformer(CV领域):划分图像块,窗口内自注意力,跨窗口移位连接。实现
层次化窗口注意力.
(1) 窗口分区(Window Partition)- 局部窗口注意力:
- 将图像划分为不重叠的局部窗口(如 7 × 7 7 \times 7 7×7 窗口),每个窗口内独立计算自注意力。
- 计算复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( M × K 2 ) O(M \times K^2) O(M×K2),其中 M M M 是窗口数, K K K 是窗口大小(如 49 49 49)。
- 跨窗口交互(Shifted Window):
- 通过 窗口偏移(Shifted Window) 机制,使相邻窗口之间能交互信息。
- 例如,第 l l l 层用常规窗口,第 l + 1 l+1 l+1 层将窗口向右下角偏移一半大小,实现跨窗口连接。
(2) 层次化特征图(Hierarchical Feature Maps)
- 类似 CNN 的金字塔结构:
- 通过 Patch Merging 逐步降采样(类似池化),生成多尺度特征图(如 56 × 56 → 28 × 28 → 14 × 14 56 \times 56 \rightarrow 28 \times 28 \rightarrow 14 \times 14 56×56→28×28→14×14)。
- 适合密集预测任务(如目标检测、分割)。
- 局部窗口注意力:
-
| 特性 | 多头注意力 (MHA) | ViT 自注意力 | Swin Transformer 自注意力 |
|---|---|---|---|
| 计算范围 | 全局(所有位置交互) | 全局(所有 patch 交互) | 局部窗口 + 偏移窗口 |
| 复杂度 | O ( N 2 ) O(N^2) O(N2) | O ( N 2 ) O(N^2) O(N2)(N=patch 数) | O ( N ) O(N) O(N)(线性) |
| 位置编码 | 固定/可学习 | 可学习 | 相对位置偏置(Relative Bias) |
| 层次化结构 | 无 | 无 | 有(Patch Merging) |
| 适用任务 | NLP(如 BERT) | 图像分类 | 分类、检测、分割等 |
| 高分辨率支持 | 不适合 | 有限 | 优秀 |
1.2 全局+局部组合
- 原理:预设少量全局关注位置(如开头/结尾、标点符号),其余位置仅局部关注。
- 典型模型:
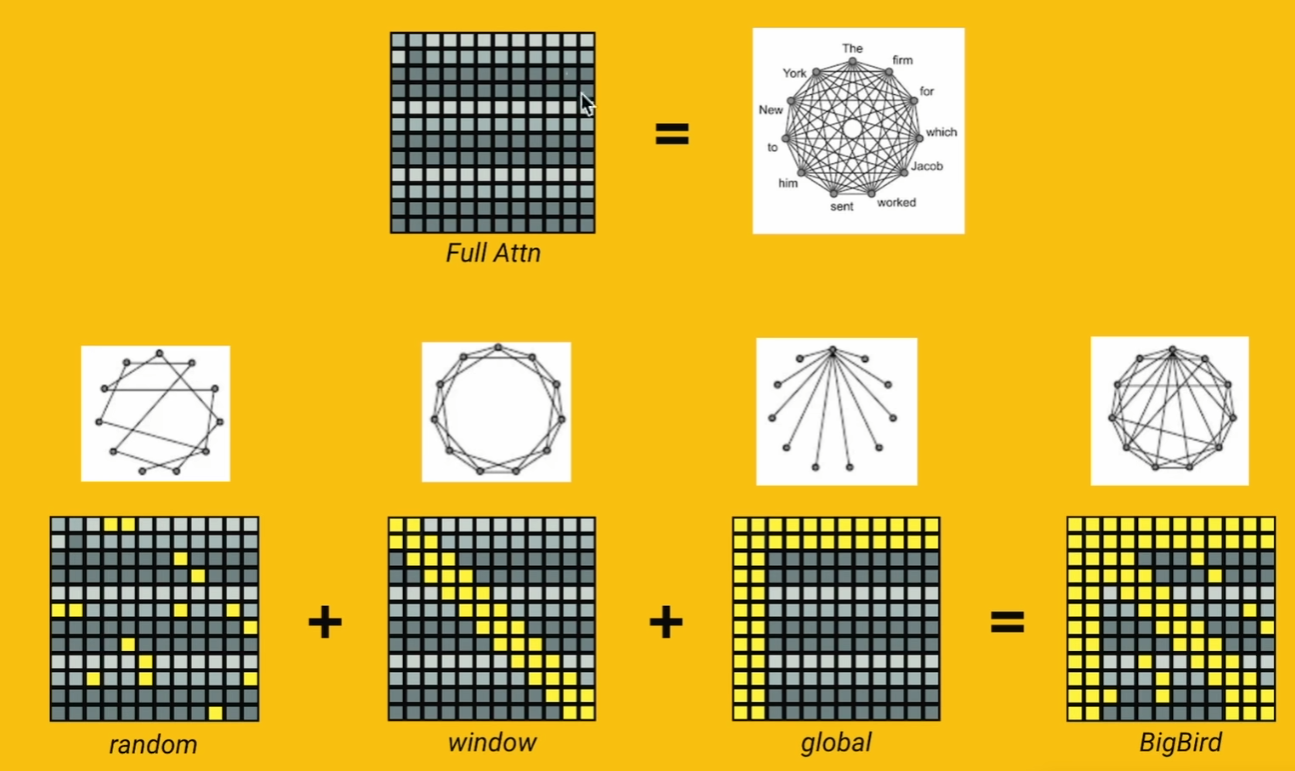
- Longformer:滑动窗口(局部) + 任务相关全局标记(如问答中的问题标记)。
- BigBird:局部窗口 + 随机注意力(稀疏连接) + 全局标记。
- 优势:平衡局部细节与全局信息,适合文档级任务(如文本摘要)。
1.3 基于内容的稀疏化
- 原理:动态选择与当前token语义相关的关键位置。
- 典型模型:
- Reformer:使用局部敏感哈希(LSH)将相似向量分到同一桶,仅桶内计算注意力。
- Routing Transformer:聚类相似token,簇内计算注意力。
- 优势:内容相关性更高,适合语义密集的任务(如机器翻译)。
1.4 随机稀疏注意力
- 原理:随机选择部分位置建立连接,模拟全连接的效果。
- 典型模型:
- Sparse Transformer:固定随机模式 + 局部注意力。
- BigBird的随机注意力模块。
- 优势:数学上近似全注意力,理论保证模型表达能力。
2. 高效注意力计算(降低显存与计算复杂度)
通过数学近似或计算策略减少显存和计算量。
2.1 线性化注意力(Linearized Attention)
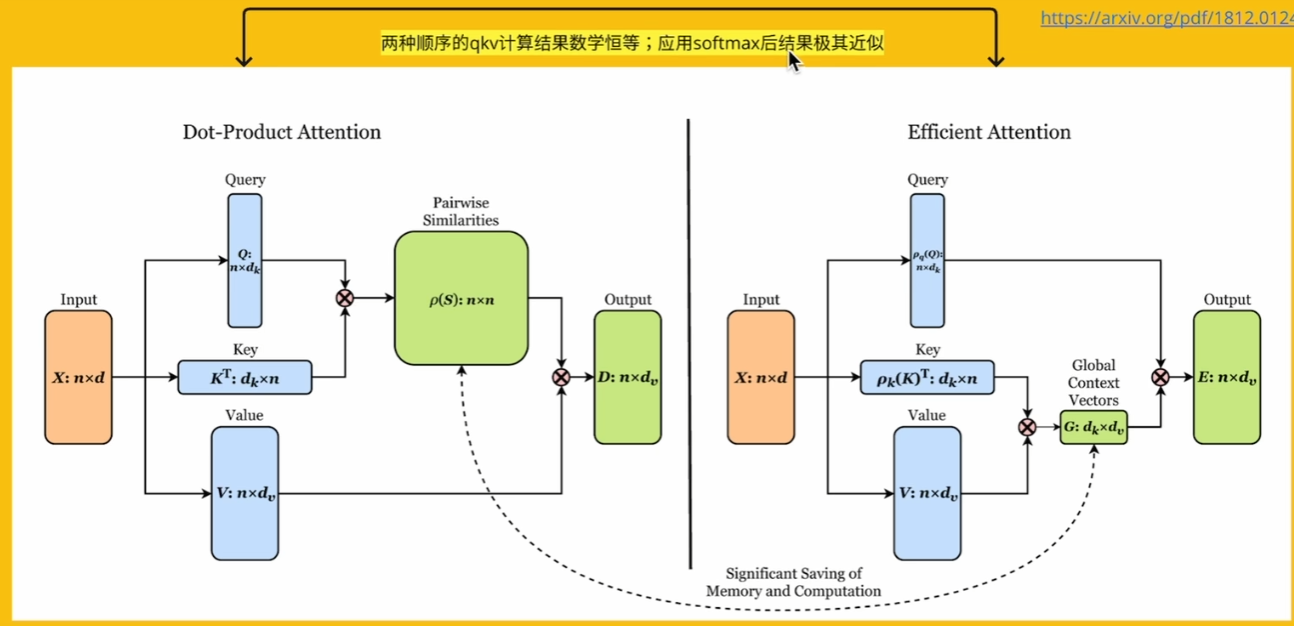
-
原理:将Softmax注意力分解为低秩形式,利用矩阵乘法的结合律。
- 公式: Attention ( Q , K , V ) = ϕ ( Q ) ( ϕ ( K ) ⊤ V ) \text{Attention}(Q,K,V) = \phi(Q) (\phi(K)^\top V) Attention(Q,K,V)=ϕ(Q)(ϕ(K)⊤V),其中 ϕ \phi ϕ 为核函数。
-
典型模型:Linformer(《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》(简称 Linear Transformer)):将键值投影到低维空间(如序列长度N→k),复杂度从 O ( N 2 ) O(N^2) O(N2) 降至 O ( N k ) O(Nk) O(Nk)。
-
优势:显存占用大幅降低,支持超长序列训练。
参考视频:b站
2.2 分块计算(Blockwise Processing)
- 原理:将序列分块,块内计算精细注意力,块间计算稀疏或粗粒度注意力。
- 典型模型:
- Blockwise Attention:分块后并行计算,减少显存峰值。
- Longformer的局部窗口本质是分块的特殊形式。
- 优势:适配硬件并行性,适合GPU显存优化。
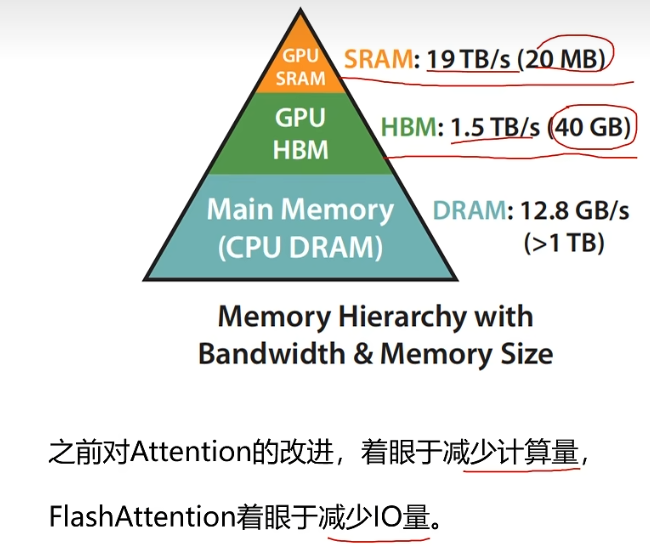
2.3 内存优化技术
- FlashAttention:通过分块计算(将输入QKV分割成小块,分别进行计算,将结果累加)和缓存储存策略,减少GPU显存读写次数(IO优化),提速2-3倍。
为什么要分块计算呢?—— 为了利用 GPU 中 IO 速度更快的那部分显存,也就是 SRAM。不分块的话,SRAM 放不下,只能从 HBM 中读取,IO 速度更慢。 - Memory-Efficient Attention:自动选择计算顺序(如先计算QK^T再乘V,或先KV再乘Q),减少中间矩阵存储。
b站讲解
2.4 原生稀疏注意力(NSA):动态分层策略的硬件级优化
通过动态分层剪枝实现计算复杂度从O(n²)到O(n log n)的突破。其核心架构包含三大分支:
- 粗粒度压缩层:使用K-means聚类对token分组,保留每组的中心代表
- 细粒度选择层:基于余弦相似度筛选关键token,过滤冗余信息
- 滑动窗口层:保留局部连续性信息,防止细节丢失
3. 动态稀疏注意力(Adaptive Sparsity)
根据输入内容动态调整注意力模式,平衡稀疏性与表达能力。
3.1 自适应注意力范围
- 原理:为每个token学习应关注的窗口大小。
- 典型模型:
- Adaptive Span Transformer:为每个注意力头学习不同的窗口范围。
- Dynamic Convolutional Attention:用卷积核动态调整感受野。
- 优势:灵活适应不同输入结构(如文本中长依赖与局部语法)。
3.2 可学习稀疏模式
- 原理:通过门控机制或强化学习选择重要位置。
- 典型模型:
- BP-Transformer:二元门控控制是否建立注意力连接。
- SparseBERT:训练时剪枝冗余注意力连接。
- 优势:任务导向的稀疏化,提升模型效率。
4. 硬件感知优化
结合硬件特性设计注意力计算方式。
4.1 FlashAttention-2
- 优化点:优化GPU线程分配和块大小,相比FlashAttention进一步减少非矩阵计算开销,提速1.5-2倍。
- 适用场景:大规模训练(如万卡集群训练GPT-4)。
4.2 混合精度注意力
- 原理:关键矩阵计算(如QK^T)使用FP16或BF16,中间结果用FP32累积。
- 优势:减少显存占用并利用Tensor Core加速。
5. 特征处理优化注意力
通道与空间注意力组合结合了 SE(通道注意力)和 CBAM(空间注意力)模块,通过合理放置于网络中间层,能够更有效地提取图像特征。SE 模块关注通道间的关系,CBAM 模块关注空间位置信息,两者结合就像是从不同角度观察一幅画,能够更全面地理解图像内容。通过这种组合方式,模型在特征提取效率和图像理解能力上都有显著提升。
5. 其他注意力变体
5.1 多头注意力优化
- Talking-Heads Attention:在多头输出的投影前增加跨头信息交互。
- Multi-Query Attention:所有头共享同一组键和值,减少显存占用(如谷歌的PaLM模型)。Multi-query attention 与 Transformer 中普通的 Multi-head attention 的唯一区别在于,不同的 heads 之间共享 K, V 矩阵;只有 Q 不同。
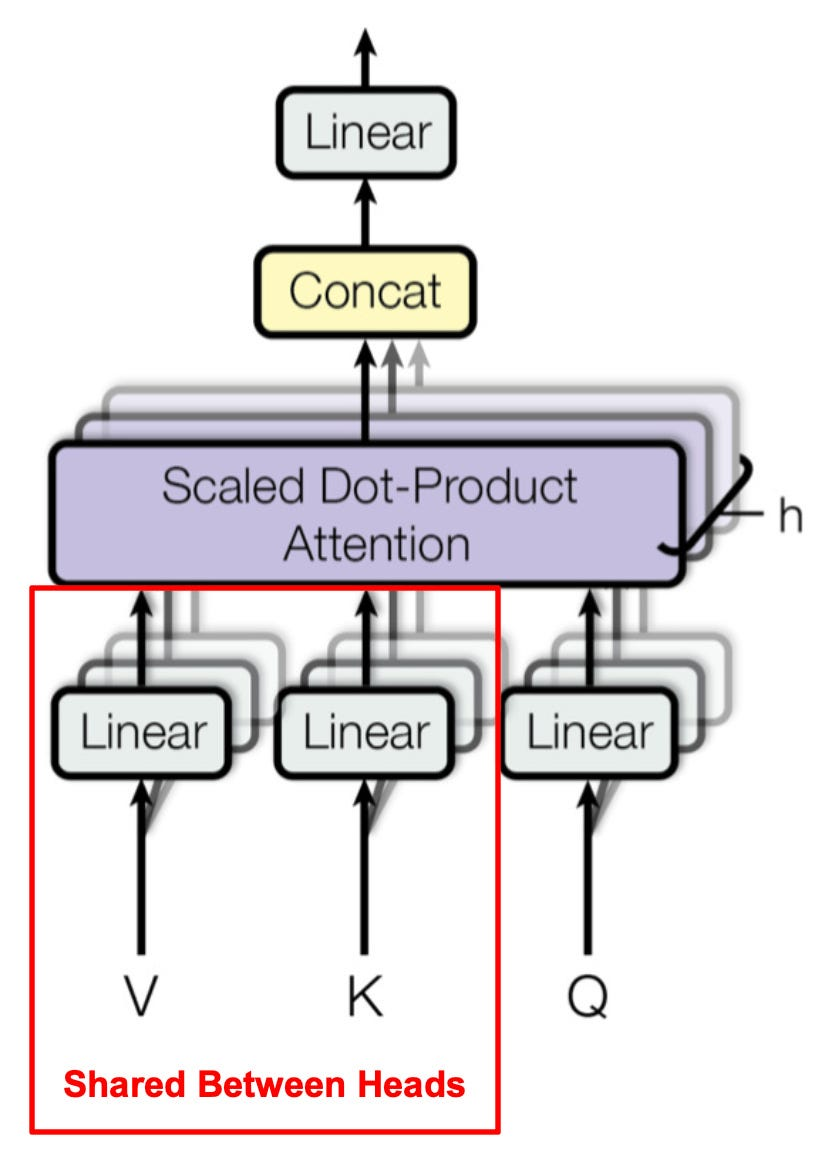
在 MQA 中:
- 生成 Q、K、V:
- 对输入数据,用线性层生成 Query (Q),每个头有自己独立的 Q。
- 但 Key (K) 和 Value (V) 是所有头共享的,只生成一份。
- K 和 V 的维度是 d m o d e l / h d_{model} / h dmodel/h,而不是 h × ( d m o d e l / h ) h \times (d_{model} / h) h×(dmodel/h)。
- 计算注意力分数:
- 用每个头的 Q 和共享的 K 计算注意力分数。
- 由于 K 是共享的,只需要计算一次,而不是 h h h 次。
- 加权求和:
- 用注意力分数对共享的 V 进行加权求和。
- 合并输出:
- 将所有头的输出拼接起来,通过一个线性层得到最终结果。
计算量对比
标准 MHA:
- Q、K、V 的维度: 3 × h × ( d m o d e l / h ) = 3 × d m o d e l 3 \times h \times (d_{model} / h) = 3 \times d_{model} 3×h×(dmodel/h)=3×dmodel。
- 计算注意力分数:需要对每个头单独计算,复杂度为 O ( N 2 × h × ( d m o d e l / h ) ) = O ( N 2 × d m o d e l ) O(N^2 \times h \times (d_{model} / h)) = O(N^2 \times d_{model}) O(N2×h×(dmodel/h))=O(N2×dmodel)。
MQA:
- Q 的维度: h × ( d m o d e l / h ) = d m o d e l h \times (d_{model} / h) = d_{model} h×(dmodel/h)=dmodel。
- K、V 的维度: 2 × ( d m o d e l / h ) 2 \times (d_{model} / h) 2×(dmodel/h)。
- 计算注意力分数:只需要计算一次,复杂度为 O ( N 2 × ( d m o d e l + 2 × ( d m o d e l / h ) ) ) O(N^2 \times (d_{model} + 2 \times (d_{model} / h))) O(N2×(dmodel+2×(dmodel/h)))。
优化效果:
- MQA 的计算量减少了约 h h h 倍( h h h 是注意力头的数量)。
Grouped-Query Attention (GQA),被LLama、ChatGLM2、ChatGLM3使用:介于 Multi-head 和 Multi-query 之间,Grouped-query 是指:多个 query 矩阵对应同样的 key, value 矩阵。如下图中间所示
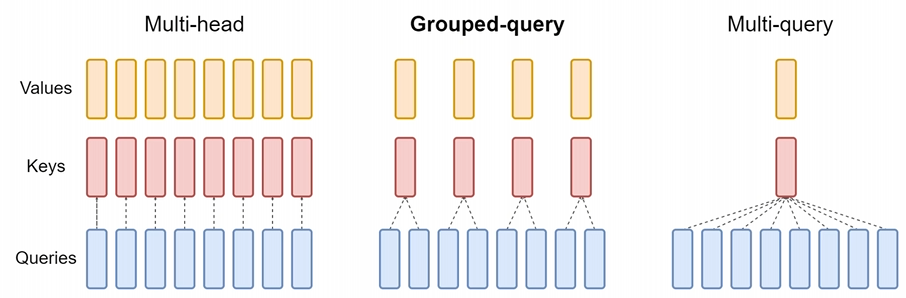
GQA 介于 MHA 和 MQA 之间,把 h个头分为 g 组,同一组的头共用同一个Wk 和同一个Wq, g=1就是 MQA,g=h 就是 MHA。
5.2 轴向注意力(Axial Attention)
- 原理:在高维数据(如图像、视频)中按不同轴(行、列)分别计算注意力。
- 典型模型: Axial-Transformer(用于图像生成)。
5.3 时态注意力(Temporal Attention)
- 原理:在视频或语音任务中,约束注意力仅关注时序上的邻近帧。
- 典型模型: TimeSformer(视频分类)。
总结与适用场景
| 优化方法 | 计算复杂度 | 典型应用场景 | 代表模型 |
|---|---|---|---|
| 稀疏注意力 | O ( N ) O(N) O(N) | 长文本、高分辨率图像 | Longformer, BigBird |
| 线性化注意力 | O ( N ) O(N) O(N) | 超长序列训练(>8k tokens) | Performer, Linformer |
| 分块计算 | O ( N N ) O(N \sqrt{N}) O(NN) | 显存受限的GPU训练 | Blockwise, FlashAttention |
| 动态稀疏注意力 | O ( N log N ) O(N \log N) O(NlogN) | 输入结构多变的任务(如对话) | Adaptive Span |
| 硬件感知优化 | - | 大规模分布式训练 | FlashAttention-2 |
未来方向:
- 动态稀疏与硬件协同优化:结合内容感知稀疏化和GPU内存管理(如NVIDIA的SparTA)。
- 注意力与卷积/RNN融合:如Hybrid Transformers,在底层用卷积捕捉局部特征,高层用注意力建模全局依赖。
- 量子化注意力:探索二值化或三元化注意力权重,进一步压缩计算。
MHA、MQA、GQA、
