Python网络爬虫设计(一)
目录
一、网络爬虫
1、基本的爬虫
2、获取URL
3、查找网页源码关键字
4、代码实现
二、requests库
1、requests的优势和劣势
2、获取网页的其他库
(1)selenium库
(2)pyppeteer库
三、pyppeteer库
1、pyppeteer库的来历
2、pyppeteer库的工作原理
3、pyppeteer相关环境安装
四、协程
1、概念
2、注意事项
五、用pyppeteer获取网页
一、网络爬虫
网络爬虫,简称爬虫,它可以用来在网络上搜集一些数据(比如在搜索引擎上),也可以模拟浏览器的快速操作(比如我们可以用爬虫来实现抢课)
1、基本的爬虫
一个基本的爬虫写法如下:
(1)首先手动找出我们想要获取的网址(URL)
(2)在浏览器中搜索这个网址,查看网页的源代码,在源代码中找出我们想要的内容的字符串的模式(比如我们想要查找一些图片,在网页源码中,图片都有一些固定的关键字,我们通过抓取这些关键字,就可以获取图片)
(3)在程序中我们用URL得到对应的网页
(4)再根据程序中的正则表达式或者BeautifulSoup库来查找关键字,得到对应的内容并保存
2、获取URL
我们先在浏览器上搜索一个关键字:
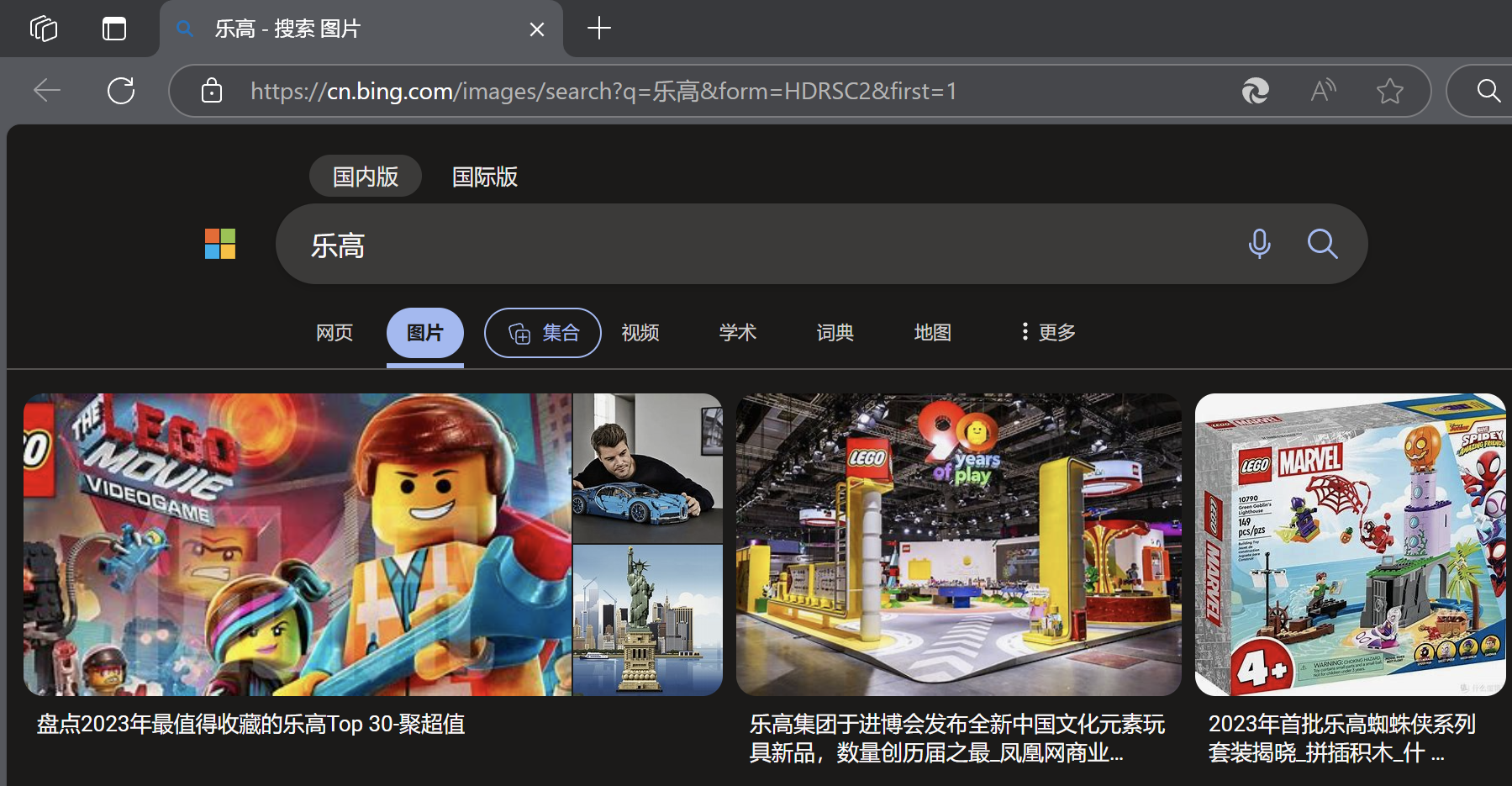
我们观察这个网页对应的URL:
可以发现,在这个URL中,有一部分是“q = 乐高”,我们就可以猜想,是不是只要把q后面的文字改成我们想要搜索的关键字,就可以到达对应的页面?
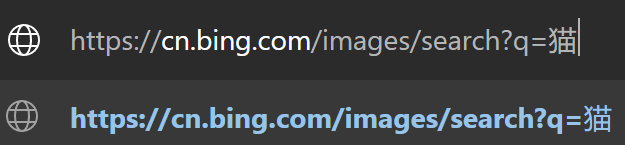
我们直接在URL上把q后面的关键词改成“猫”,然后按下回车:
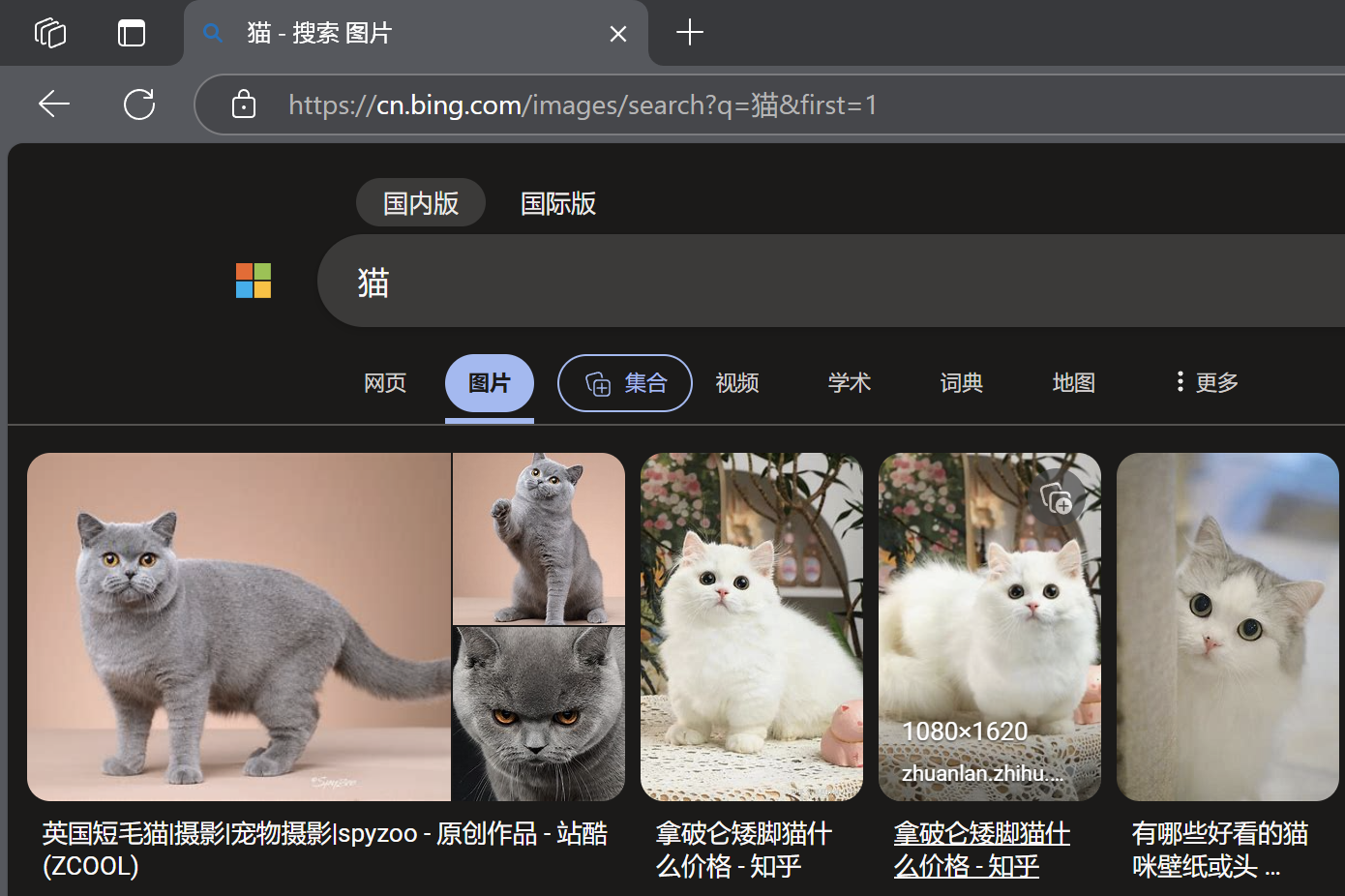
发现果然跳转到了猫的搜索页面!
这就意味着我们可以在代码中,通过修改q后面的数据,来到达对应的目标页面
3、查找网页源码关键字
当我们到达了目标页面,我们想要抓取几个图片,就需要通过页面源码的关键字:
我们在这个“猫”的搜索页面随便找一个图片,右键,选择“复制图像连接”
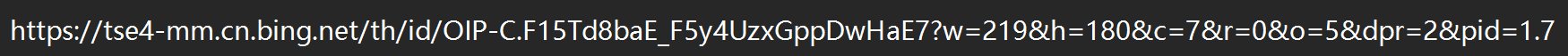
我们会发现th(略缩图),id等具有标志性的东西,这些都指明了这可能是一个图片
当然,如果看不出来我们可以多复制几个图片的链接,来寻找共同点:

不难发现,很多图片都有/th/id/OIP-这一部分,这可能就是图片链接的共同特点:
右击网页空白处,点击“查看网页源码”,按ctrl + F ,
我们把这串字符复制进去:
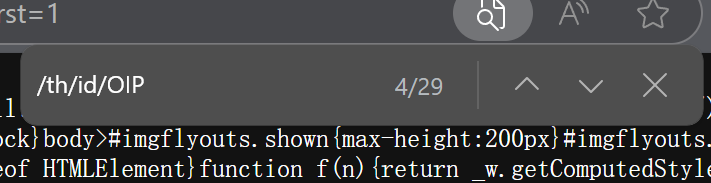
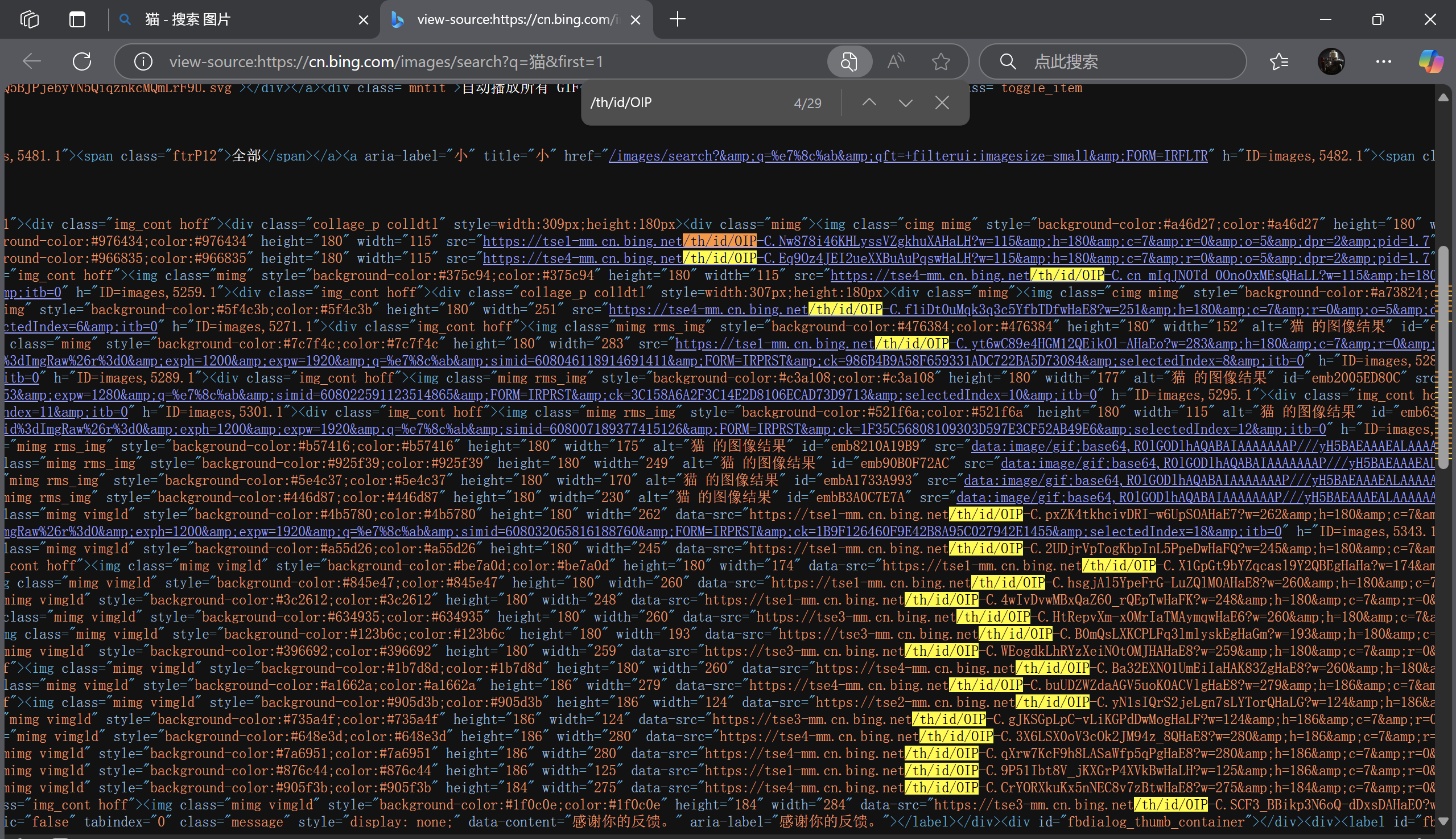
按下回车,就能看见在源码的地方,很多处都被标记了这个关键字符串,我们就可以根据这个来爬取想要的图片;
4、代码实现
我们来找一个专门练习爬虫的页面来爬取几个图片(很多网页有反爬技术,最最基础的爬虫代码难以成功)
import re #用来使用正则表达式
import requests #用于HTTP请求
import os #操作文件目录等def getHTML(url): #用于获取目标页面的HTMLfakeHeader = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.77'}#定义了一个字典,用来模拟浏览器的请求头,欺骗浏览器try:r = requests.get(url, headers=fakeHeader)#发送一个GET请求到指定的url,并使用我们的假头部r.encoding = r.apparent_encoding#设置编码格式return r.text #返回网页的HTML内容except Exception as e:print(e)return ""#------------------------以上内容可以固定的直接使用------------------------def getPicturePro(n):base_url = "https://spiderbuf.cn" #基础的路径url = "https://spiderbuf.cn/web-scraping-practice/scraping-images-from-web" #目标网页的URL(就是包含图片的)html = getHTML(url) #调用函数,获取目标页面的HTML内容pt = r'<img[^>]+src="([^"]+)"' #正则表达式,用于找到HTML里面的img标签的src属性的值i = 0 #图片个数(方便命名)for x in re.findall(pt, html): #使用正则表达式pt找到html中所有符合的图片路径if x.startswith("/"):x = base_url + x # 检查是否是相对路径,并转换为完整路径if not (x.lower().endswith(".jpg") or x.lower().endswith(".png")): #拼接好后,如果不是jpg或png的图片,跳过不要continuetry:print(x) #输出经过层层筛选的图片路径r = requests.get(x, stream=True) #发送GET请求,获取图片,并以流式下载,防止一次性到内存pos = x.rfind(".") #找到文件扩展名的起始位置if not os.path.exists(r"D:\学习\Python\temp"):os.makedirs(r"D:\学习\Python\temp") #若不存在该目录就创建该目录f = open(r"D:\学习\Python\temp\{0}{1}{2}".format("image", i, x[pos:]), "wb")#打开该目录,并且以image和i来命名f.write(r.content) #把图片写入文件f.close()except Exception as e:print(f"Error downloading {x}: {e}") #若报错就返回错误信息i += 1getPicturePro(1) #传入参数,表示开始执行输出:
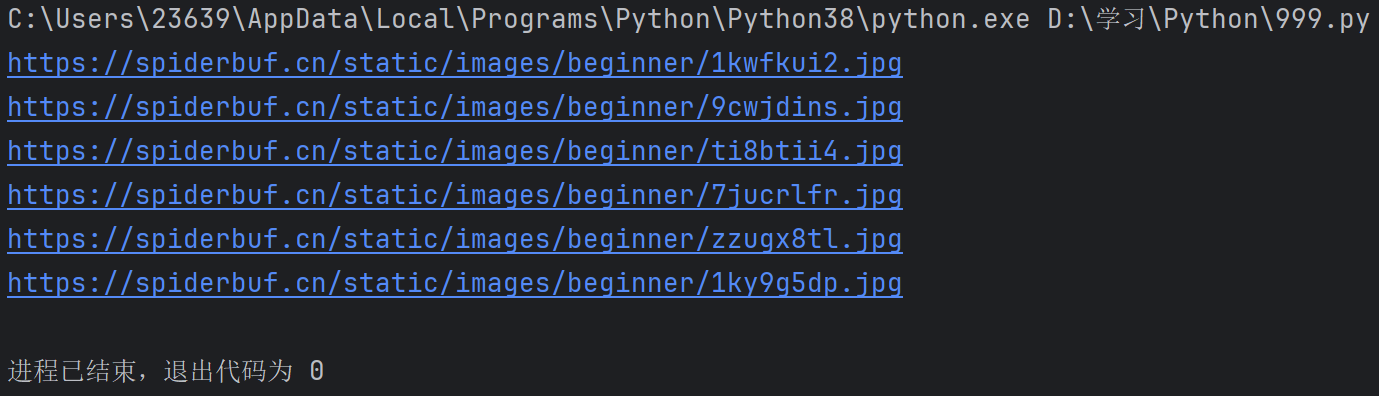
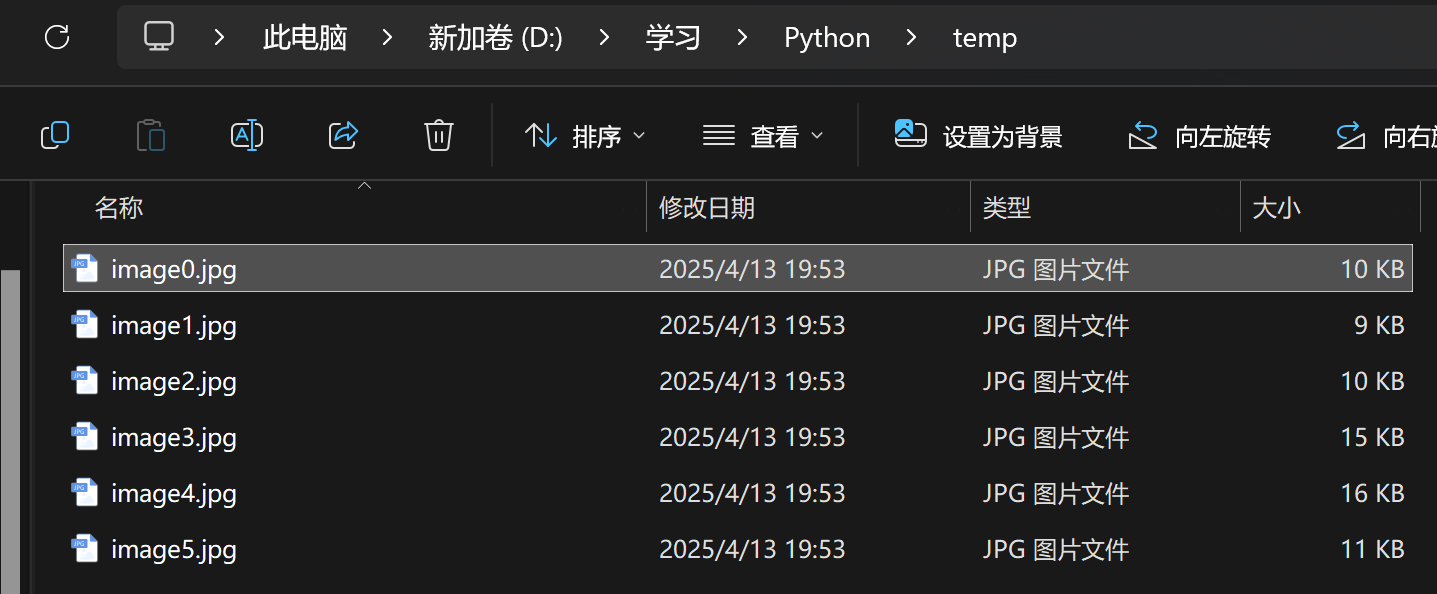
我们再看看文件夹:
二、requests库
在上面的代码中,我们可以看见,requests库的作用是用来发送HTTP请求的,可以完成大量的网络层面的任务
1、requests的优势和劣势
①优势:速度快,且安装简单,我们只需要使用pip命令就能安装requests库,很容易把自己的代码分享给别人使用,即共享性强
②劣势:requests库很容易被反爬虫手段屏蔽,可能一个有一点反爬虫手段的网页就能把这个代码屏蔽掉(比如我们用上面的代码去爬百度的搜索图片,是不能成功的,会被反爬),而且不能获取JavaScript的生成的动态网页。
2、获取网页的其他库
面对刚刚上面requests的缺陷,我们在Python中,也提供了很多库来弥补它的不足
(1)selenium库
selenium库虽然比requests库更强一些,但是它的速度很慢,而且已经被许多网站反爬,可能还是无法成功
(2)pyppeteer库
速度很快,而且目前还没有被很多网站反爬,是一个比较好的选择
三、pyppeteer库
1、pyppeteer库的来历
pyppeteer是puppeteer的Python版本,而puppeteer是谷歌公司推出的可以控制Chrome浏览器的一套编程工具
2、pyppeteer库的工作原理
①启动一个浏览器Chromium,用浏览器装入网页,并且浏览器可以用无头模式(隐藏模式)或者显式模式启动(就是在执行爬取操作的时候用户能否看见浏览器操作页面的具体过程)
②从浏览器中可以获得网页的源代码,若网页就JavaScript程序,获得到的就是JavaScript被浏览器执行后的网页源码
③pyppeteer可以向浏览器发送命令,模拟用户在浏览器上的键盘,鼠标等操作
④selenium和pyppeteer的工作原理相同
3、pyppeteer相关环境安装
我们先在cmd窗口用pip命令下载pyppeteer
pip install pyppeteer(要求Python版本在3.6及3.6以上)
当然,我们上面提到,我们需要启动一个特殊的浏览器Chromium,所以我们需要下载它:
在安装之前,我们需要确定我们安装了Node.js
安装官网:Node.js — 在任何地方运行 JavaScript
进入之后,我们点击下载LTS版本的(更加稳定)
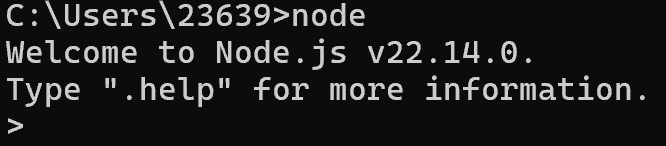
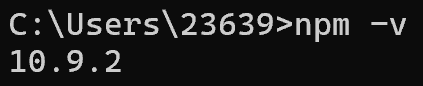
在安装完成后,我们可以在cmd窗口检查一下是否安装完成:
node -v
npm -v若安装成功,应该会类似如下:
安装完成之后,我们输入以下命令来安装:
npx @puppeteer/browsers install chrome@stable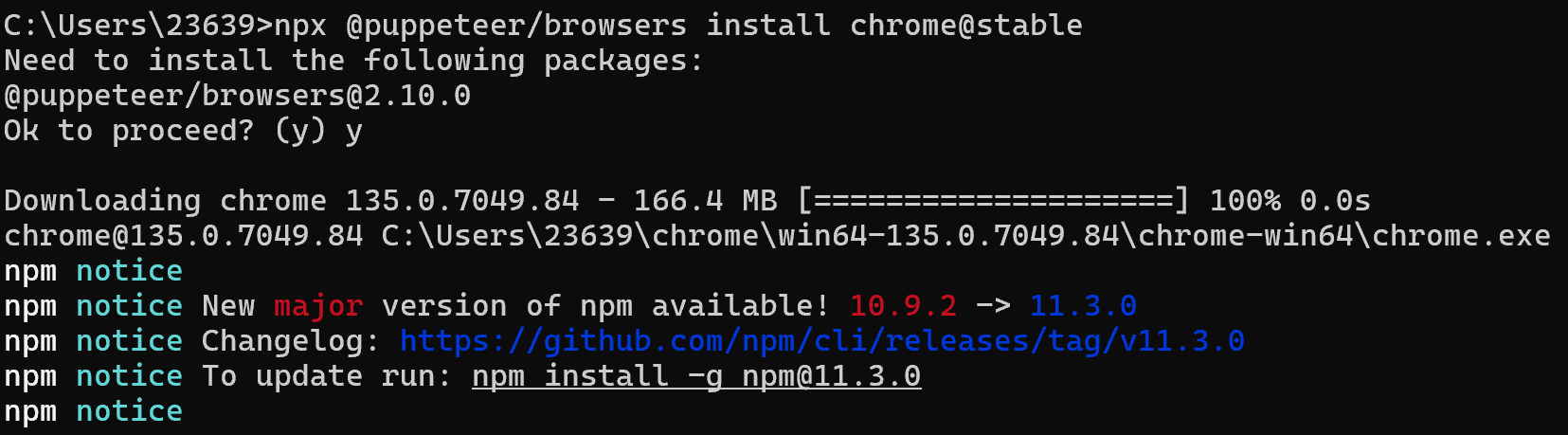
在上图中的第六行,显示了安装的位置,我们定位到具体的目录,找到exe文件,可以创建一个快捷方式到桌面:

四、协程
1、概念
协程就是在代码中,前面加了async的函数:
async def scy() :return 0在调用协程时,必须在前面添加await
await scy()2、注意事项
(1)协程只能在协程里面调用,也就是说await关键字只能出现在协程里面,出现在外面就会报错!
(2)协程是一种特殊的函数,多个协程可以并行
(3)pyppeteer中的所有函数都是协程
五、用pyppeteer获取网页
代码如下:
import asyncio #是Python的异步 I/O 框架,用于编写单线程并发代码
import pyppeteer as pyp#通过输入的url,获取指定的HTML内容
async def getHTML(url) : #构造一个异步函数browser = await pyp.launch(headless = False , executablePath=r'C:\Users\23639\AppData\Local\Google\Chrome\Application\chrome.exe') #启动一个浏览器,headless就是无头模式,设置成False就会显示浏览器,反之就不会#executablePath指明了Chrom浏览器的可执行路径page = await browser.newPage() #等打开了浏览器,再在浏览器中获取我们想要的页面await page.setUserAgent('Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 safari/537.36')#模拟浏览器的请求头await page.evaluateOnNewDocument(' () => Object. defineProperties (navigator, { webdriver: {get:()=> false } })}')#页面在加载的时候会被执行里面JavaScript代码,目的是防止浏览器检测自动化工具await page.goto(url) #导航到指定的URLtext = await page.content() #获取页面的HTML代码await browser.close() #关闭浏览器return text #返回text内容def getHTMLpro(url) :return asyncio.run(getHTML(url)) #返回页面的HTML内容HTML_result = getHTMLpro("https://cn.bing.com") #调用函数
print(HTML_result)执行结果:
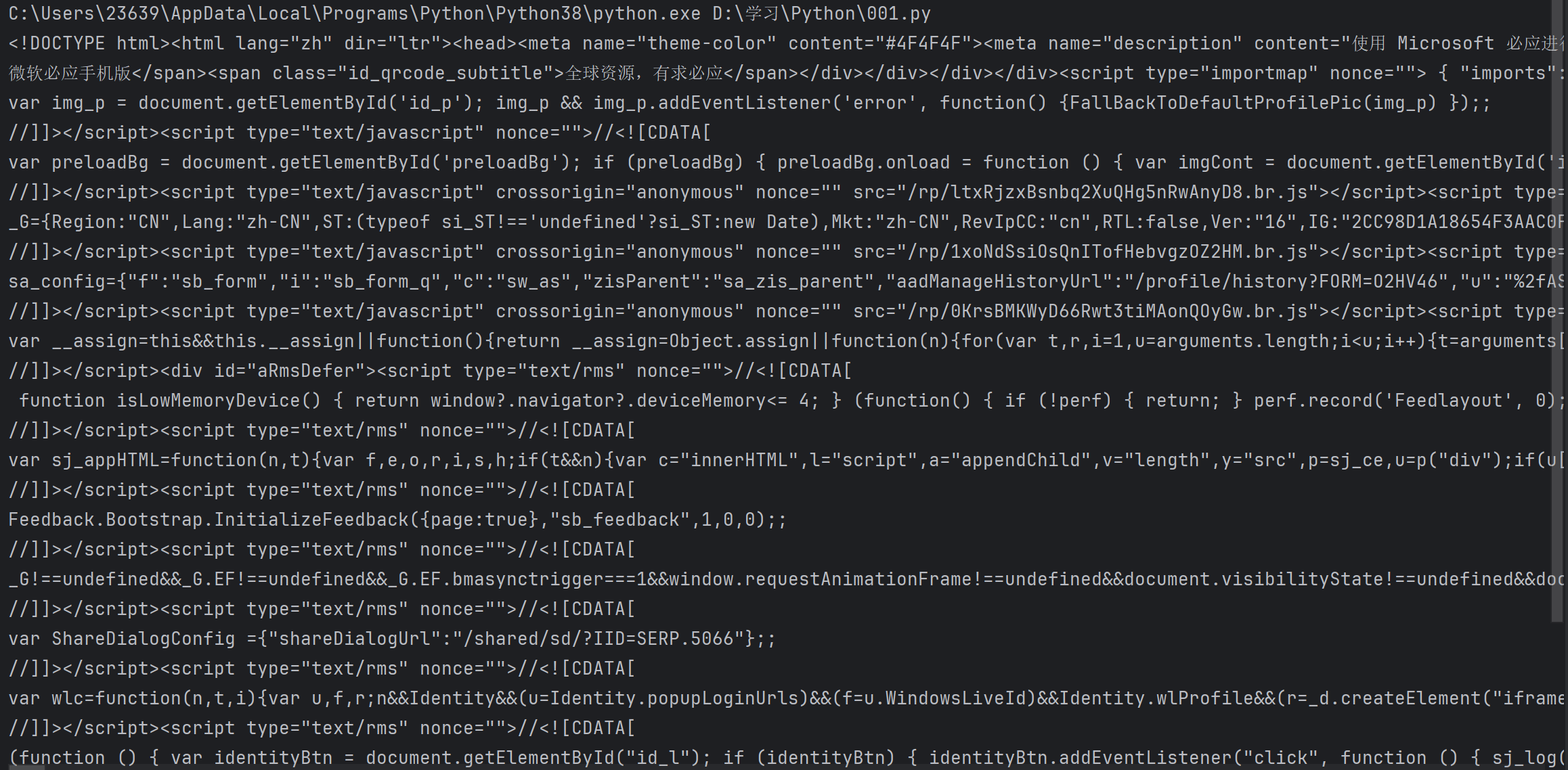
这就是把我们输入的那个URL的网页给爬取了下来,如果把这个复制到一个文本文档中,把后缀改成.html,就是我们想要的那个页面
以上就是Python网络爬虫设计(一)的全部内容:)