自编码网络深度解析:原理、数学推导与实现细节
引言:自编码网络的本质
自编码网络(Autoencoder)本质上是一种数据压缩算法,但它与传统的JPEG或ZIP压缩有着根本区别。自编码器学习的是数据的有意义的表示而不仅仅是存储效率。这种表示学习能力使其成为深度学习中的重要工具。
一、自编码器的数学原理深度剖析
1.1 基本架构的数学表达
自编码器可以形式化为两个函数的组合:
φ: 𝓧 → 𝓩 (编码器)
ψ: 𝓩 → 𝓧 (解码器)
其中𝓧是输入空间,𝓩是潜在空间(通常dim(𝓩) ≪ dim(𝓧))。我们的目标是找到:
φ, ψ = argmin 𝔼[Δ(x, ψ(φ(x)))]
Δ是重构误差度量,通常使用L2范数。
1.2 最优解的几何解释
理想情况下,自编码器学习的是数据流形的切平面。对于位于数据流形上的点x,存在:
ψ(φ(x)) = x
而对于流形外的点,重构误差会显著增大,这正是自编码器可用于异常检测的原理。
1.3 梯度推导
考虑简单的线性自编码器(无激活函数):
z = W₁x + b₁ (编码)
x̂ = W₂z + b₂ (解码)
损失函数:
L = ½‖x - x̂‖²
梯度计算(使用链式法则):
∂L/∂W₂ = (x̂ - x)zᵀ
∂L/∂b₂ = (x̂ - x)
∂L/∂W₁ = W₂ᵀ(x̂ - x)xᵀ
∂L/∂b₁ = W₂ᵀ(x̂ - x)
这个推导揭示了权重更新的内在机制。
二、自编码器的信息论视角
2.1 信息瓶颈理论
自编码器可以看作是在执行信息瓶颈(Information Bottleneck)原则:
min I(X;Z) - βI(Z;X̂)
其中I表示互信息,β是权衡系数。这迫使网络保留对重构最重要的信息。
2.2 率失真理论
从率失真角度看,自编码器在最小化:
min D(X,X̂) s.t. R(Z) ≤ R₀
D是失真度量,R是码率,R₀是目标码率。
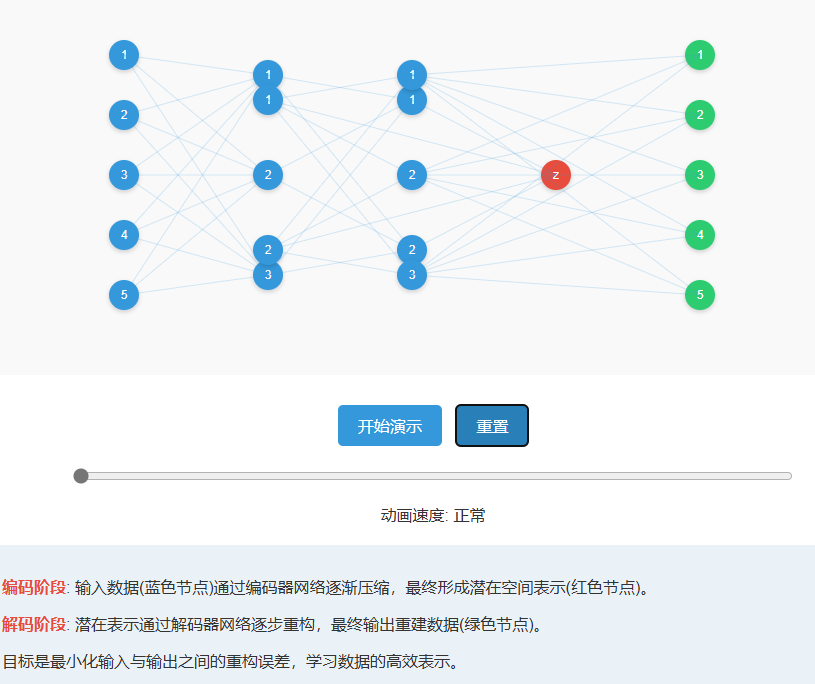
三、网络架构的工程细节
3.1 编码器设计黄金法则
-
逐层收缩原则:
每层的神经元数量建议按以下方式收缩:
nₖ ≈ nₖ₋₁/α,α∈[1.2,2]示例架构:
输入层:784 (28x28图像) 隐藏层1:392 隐藏层2:196 潜在层:32 -
激活函数选择:
-
中间层:LeakyReLU(α=0.1)避免死亡神经元
-
输出层:
-
图像:Sigmoid(值域[0,1])
-
其他:Tanh(值域[-1,1])
-
-
3.2 解码器的对称性设计
实践中发现,解码器与编码器对称(镜像结构)往往效果最佳。但需要注意:
-
最后一层维度必须匹配输入
-
每层权重应独立初始化
# 对称初始化示例
def init_weights(m):if type(m) == nn.Linear:nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='leaky_relu')m.bias.data.fill_(0.01)encoder.apply(init_weights)
decoder.apply(init_weights) # 独立初始化四、训练过程的优化细节
4.1 损失函数的进阶选择
-
感知损失(Perceptual Loss):
使用预训练网络(如VGG)的特征差异:L = ‖Φ(x) - Φ(x̂)‖ + λ‖x - x̂‖其中Φ是特征提取器。
-
对抗损失:
引入判别器D:L_AE = ‖x - x̂‖ + λlog(1 - D(x̂))
4.2 批量归一化的特殊处理
在自编码器中,BN层的位置非常关键:
# 最佳实践结构
self.encoder = nn.Sequential(nn.Linear(in_dim, h_dim1),nn.BatchNorm1d(h_dim1), # BN在激活前nn.LeakyReLU(0.1),nn.Linear(h_dim1, h_dim2),nn.BatchNorm1d(h_dim2),nn.LeakyReLU(0.1)4.3 学习率调度策略
由于重构任务的特殊性,推荐使用循环学习率:
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer,base_lr=1e-4,max_lr=1e-3,step_size_up=2000,cycle_momentum=False)自编码网络运行演示视频
五、潜在空间的数学性质
5.1 流形学习视角
理想的自编码器潜在空间应满足:
-
局部欧几里得性:小邻域内近似线性
-
全局紧致性:所有数据点映射到有限区域
-
平滑性:z的微小变化导致x̂的微小变化
5.2 潜在空间的可视化技术
-
t-SNE投影:
from sklearn.manifold import TSNE
latent_vectors = encoder(train_data)
tsne = TSNE(n_components=2)
vis_data = tsne.fit_transform(latent_vectors)-
主成分分析:
# 检查潜在空间的PCA能量分布
from sklearn.decomposition import PCA
pca = PCA().fit(latent_vectors)
plt.plot(np.cumsum(pca.explained_variance_ratio_))六、特殊变体的实现细节
6.1 变分自编码器(VAE)的数学基础
VAE的核心是变分推断,我们最大化证据下界(ELBO):
log p(x) ≥ 𝔼[log p(x|z)] - D_KL(q(z|x)‖p(z))
实现时需要特别注意"重参数化技巧":
def reparameterize(mu, logvar):std = torch.exp(0.5*logvar)eps = torch.randn_like(std)return mu + eps*std6.2 对抗自编码器(AAE)的实现
AAE使用GAN思想约束潜在空间:
# 判别器网络
discriminator = nn.Sequential(nn.Linear(latent_dim, 512),nn.LeakyReLU(0.2),nn.Linear(512, 256),nn.LeakyReLU(0.2),nn.Linear(256, 1),nn.Sigmoid())# 对抗损失
real_labels = torch.ones(batch_size, 1)
fake_labels = torch.zeros(batch_size, 1)
g_loss = bce(discriminator(fake_z), real_labels)七、实际应用中的陷阱与解决方案
7.1 常见问题排查表
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 重构结果模糊 | 潜在空间过大 | 减小潜在维度,添加稀疏约束 |
| 训练损失不下降 | 梯度消失 | 使用残差连接,检查初始化 |
| 过拟合明显 | 网络容量过大 | 添加Dropout,增强正则化 |
| 潜在空间不连续 | 非线性不足 | 增加网络深度,使用更好的激活函数 |
7.2 调试检查清单
-
输入数据是否归一化到合适范围
-
所有层是否都有适当的梯度流动
-
潜在空间维度是否与数据复杂度匹配
-
重构误差是否在合理范围内下降
-
验证集损失是否同步下降
八、前沿进展与未来方向
8.1 最新研究趋势
-
层次化潜在空间:
# 多尺度潜在表示 z1 = encoder1(x) # 高层语义 z2 = encoder2(x) # 低层细节 -
离散潜在表示:
使用矢量量化(VQ-VAE):# 最近邻查找 distances = torch.sum(z**2, dim=1) + torch.sum(self.embedding**2, dim=1) - 2*torch.matmul(z, self.embedding.t()) encoding_indices = torch.argmin(distances, dim=1) -
物理约束自编码器:
在损失函数中加入物理规律约束项。