数据库之MySQL
程序猿的初心:通过代码来解决实际问题,提高效率~
1.初识
数据库是啥?数据库是一个广义的概念
1️⃣.表示一门学科 (这门学科,研究的是如何设计实现一个数据库【数据库软件背后的思想方法,设计哲学,比较抽象,学校要学的】)
2️⃣.表示一类软件,管理数据的软件,增删查改(CRUD)
- Oracle 数据库圈子中的大哥大 在使用的时候,必须搭配IBM的小型机,才能发挥出十成功力,超级贵
计算机导论:
巨型机(超算)
大型机
中型机
小型机 (以上三个统称为小型机)
微机(日常使用的)
- MySQL 开源&免费
- SQLServer 微软 很少有公司使用,最初的时候只支持Windows系统,而需要使用数据库的场景,一般是服务器开发,用到的系统,大多是Linux,不仅仅是系统,一系列和服务器开发的组件都是以linux为主的
- SQLite 轻 1)运行速度快 2)占用体积小(1M大小的左右的exe程序) 会经常在嵌入式设备中使用sqlite(嵌入式开发 冰箱 洗衣机 空调 路由器 这些东西里也要包含计算机,往往硬件非常简陋)
前面的这四种都是“关系型数据库” ,redis(MongoDB,HBase)则是“非关系型数据库”
关系型数据库VS非关系型数据库
▲关系型数据库,是使用“表这样的结构”来组织数据
excel 有很多行,很多列,每一条数据,都作为一行(一个记录),一行里有很多列(一个字段),每一行的列数,列的含义都得匹配
▲非关系型数据库,则更加灵活,会使用“文档” (一条数据,就是一个文档,文档和文档之间,可以差异很大)/“键值对”(没有太多要求,值是啥样的格式非常灵活)这样的结构来组织数据
关系型数据库之间,差异非常小,接下来要学习的mysql,未来公司里用的是oracle或者sqlserver,也是很容易上手的
3️⃣.表示某一个具体的数据库软件 (接下来将要学习的)
4️⃣.表示部署了某个数据库软件的主机(电脑)
2.MySQL
整个没啥特别难的地方,但是需要一定的练习量!
1️⃣SQL语句(一种编程语言)【重点】
2️⃣mysql的原理/面试题
3️⃣使用java代码来操作mysql
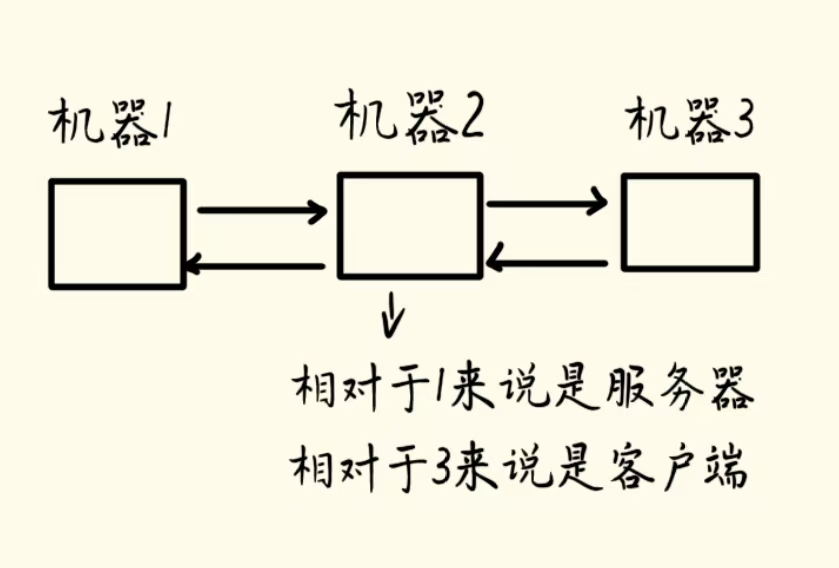
- mysql是一个“客户端-服务器”结构的软件 多个程序之间相互作用,相互配合
客户端:主动发起请求的一方
服务器:被动接收请求的一方(两个特点:一个是被动的一方,要等;一个是一个服务器往往也要给很多客户端提供服务)
两者需要通过网络进行通信的
客户端给服务器发起的数据,称为请求(Request)
服务器给客户端返回的数据,称为相应(Response)
是否存在服务器,只给一个客户端提供服务的?有
大多数服务器是给很多个客户端提供服务的,但是也有服务器是给少数一两个客户端提供服务的:分布式系统中,一台机器,能够处理的数据是有限的,往往就需要引入多台机器,相互配合,完成更复杂的工作(分布式系统中,机器之间也是需要进行网络通信的)
为啥只是使用命令行的客户端,不使用图形化界面的客户端workbench,navicat,datagrip =>因为图形化客户端以后再工作中,不一定能用的了,命令行客户端是100%能用的
- MSQL的本体是服务器,在服务器这边来负责存储(硬盘)和管理数据
一台电脑里面包含的核心的硬件设备:(现代的电脑)
CPU(电脑最核心的部分,中央处理器)
主板
内存
硬盘
散热器
电源
机箱(鞋盒)
显卡(可选)
显示器 键盘 鼠标 外设
最早的电脑:计算机的祖师爷:冯诺依曼
CPU
存储器(内存+硬盘)
输入设备
输出设备 没有显示器 键盘鼠标等 是纸带!
内存VS硬盘
内存 手机256G内存实际上是硬盘,手机真正的内存是“运存”
外存 硬盘/U盘/软盘/光盘(碟)
(整个硬盘不光要存储数据,还要存储一些属性(元数据))
两者的差别:
▲内存速度快,硬盘速度慢 差几千倍 数万倍
▲内存空间小,硬盘空间大 16GB 512GB
▲内存贵,硬盘便宜
▲内存中存储的数据是容易丢失的(程序重启/掉电,就没了),硬盘中存储的数据是持久的
数据库存储的数据,希望存储的数据量比较大,持久化存储(也有少数数据库是使用内存的,追求速度的最大化 redis)
总结:
1.
a.mysql是一个客户端-服务器结构的程序
b.mysql的服务器是真正的本体,负责保存和管理数据,数据都是存储在硬盘上的
2.
内存:速度快,空间小,成本高,数据易失
硬盘:速度慢,空间大,成本低,数据持久保存(一个硬盘在断电的情况下,里面的数据也就是保持几年到几十年)
相对~
3.数据库的操作
1️⃣成功连接客户端:
1.命令行客户端(我们使用的)
2.图形化客户端
一定要学会看报错,以在命令行客户端打开之后,输入密码,程序就会闪退为例:
- 出现Access denied for user...,十有八九就是密码错了
出现Can't connect to MySQL server on ...这种就需要检查mysql服务器是否正常工作了
操作数据库的命令,也称为“SQL语句”,也可以理解成是一种编程语言
2️⃣接下来进行数据库操作
此处的“数据库”指的是一个逻辑上的数据集合,一个mysql服务器程序,可以在硬盘上组织保存很多数据-》mysql服务器通过表来组织的,一个mysql服务器上有很多很多的表,就可以把有关联有关系的一些表放到一起,就构成了一个数据集合,此时就称为“数据库”,而且一个mysql服务器上可以有多个这样的数据库的
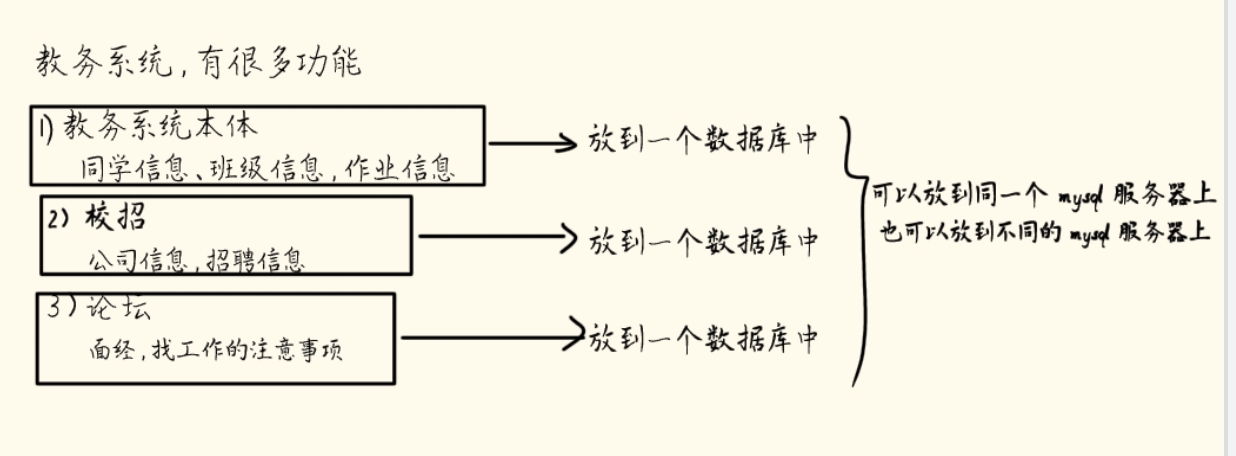
a.创建数据库

->sql中有特定含义的单词,关键字(数据库名,表名,列名都不能和关键字重复)
->sql的关键字是大小写不敏感的,建议写小写 CREATE DATABASE
->不能重复建立已经存在的数据库

数据库创建的时候,要求不能重复,此时就可以在创建的时候,加上一个修饰,来应对上述问题

此时就不会因为数据库同名而报错了。这个修饰的用途是避免sql报错,实际工作中很多时候,是把一系列sql写到一个文件中批量执行的,而很少会这样一条一条执行。在批量执行的情况下,如果一条sql报错了,后面的sql就无法继续执行了,此时这个修饰就可以避免这个问题。
->单词和单词之间,要至少有一个空格
思考题:面试题:
在你生活中使用的软件里,是否遇到过某些bug,这个bug你是怎么发现的?
你是否知道西安的洒水车,播放的音乐是啥?兰花草 世上只有妈妈好 小小世界
程序猿必须要非常细心!
->创建数据库的时候,可以手动指定一下字符集(每种字符集,都是一个很大的码表)的
在计算机中,一个汉字占几个字节?回答2是错误的
2这个数字是学习C的时候留下的印象,当时使用的VS,在windows上写的代码~
windows简体中文版 默认字符集是gbk
VS默认的字符集是和系统一致(gbk),在这个情况下,一个汉字是占2个字节
gbk现在已经用的越来越少了,主要是使用utf8(变长编码 不仅仅可以表示中文 也可以表示世界上的任何一种语言文字)作为编码方式
如果使用utf8编码,一个汉字通常是3个字节~
unicode编码是给一个字符进行编码的,但是无法给“字符串”进行编码(比如,把多个unicode编码的字符放到一起,构成一个字符串,就可能会乱套了,无法区分字符和字符之间的边界)
基于unicode就演化出了一些可以给“字符串”编码的版本:
在Java中,谈到char类型,内部编码unicode
谈到String,内部的编码一般是utf8(Java内部自动完成了编码转换)
注意:不同的字符集,不同的编码方式下,一个汉字占几个字节,是不同的!
character set字符集名字/charset 字符集名字
因为:咱们需要在数据库中保存中文,mysql默认的字符集是拉丁文,不支持中文
必须要在创建数据库的时候,手动指定编码方式为支持中文的编码(GBK UTF8)

mysql的utf8是一个残本,不是完全体的utf8,少了一些emoji表情(苹果手机 短信功能中 带有的表情) ,后来mysql又搞了个utf8mb4,则是完全体的utf8了
->sql 都需要以;结束 mysql客户端允许你输入sql的时候换行
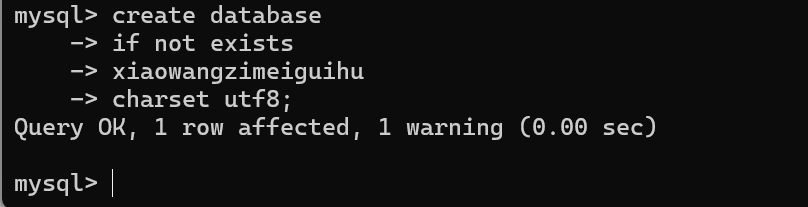
b.查看数据库
列出当前的mysql服务器上一共都有哪些数据库
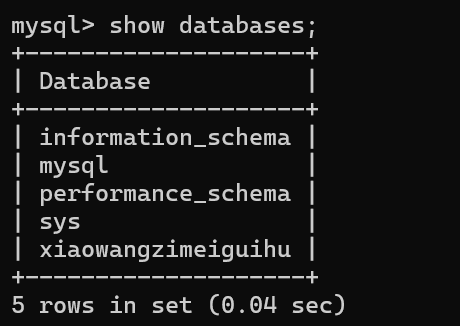
修改一些配置啥的都可以通过mysql数据库来操作 这里要慎重操作
c.选中数据库
数据库中最关键的操作,就是针对表进行增删查改,表是从属于数据库的,要针对表操作,就需要先把哪个数据库的表这个事情,指定清楚~
就像游戏一样,操作多个单位的游戏的基本模式都是:先选中单位,在操作单位
面试考察的问题不一定就是技术问题
面试真题:LOL属于那个类型的游戏:
A.MOBA B.FPS C.RPG D.RTS
d.删除数据库

删除操作,删掉的不仅是database,而且也删除了database中所有的表和表里所有的数据,删除数据库,是一个非常危险的操作
当前阶段,你删除自己的数据库,没事,如果在公司,公司里的数据库都是一些重要的商业数据,价值是难以估量的
公司为了避免出现上述删库的误操作,也会引入一些措施:
1.控制好权限
2.把数据及时做好备份(要养成良好的备份习惯)
3.确实要进行一些危险的,重要的操作的时候 ,还可以拉一个人和我们一起操作
公司中:
线上数据库/生产环境数据库 是被用户访问的数据库,真实用户的信息
线下数据库 开发/测试节点 自己构造的一些“假的”数据
4.数据表的操作:
针对数据表的操作,前提是先选中数据库
1️⃣创建表
2️⃣查看该数据库中的所有表
3️⃣查看指定表的结构
4️⃣删除表
先从mysql支持的数据类型说起~
一个表 包含很多行 每一行也称为一条记录
一个行里可以有很多列,每一列也称为是一个字段
每个列都是有一个具体的类型的
a.数据类型
-
数值类型
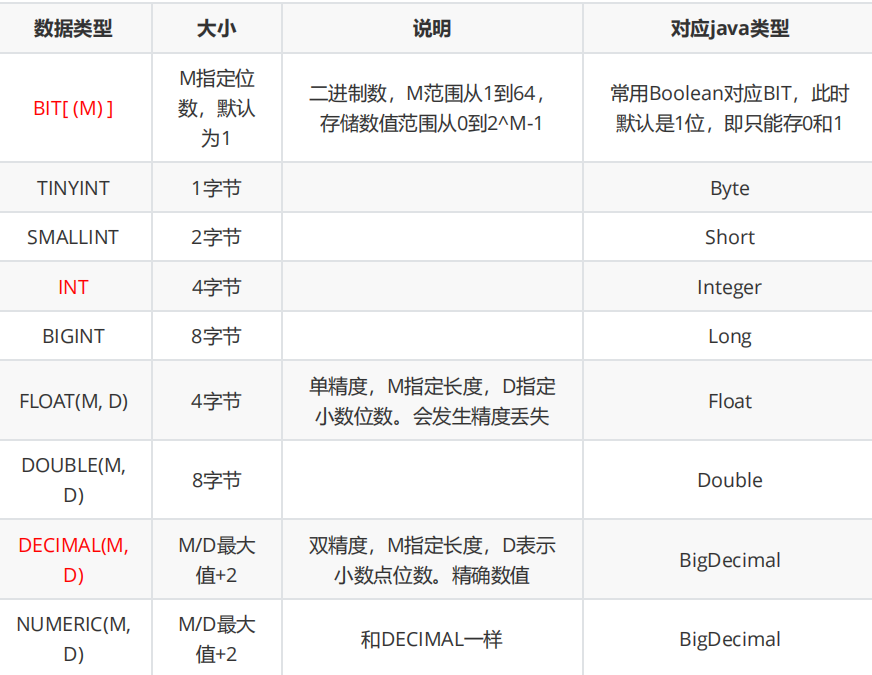
->float(M,D) ()用来描述精度 M表示小数的长度 D表示小数点后的位数
double(3,1) 长度是3 小数点后是1 99.5 10.0 20.3(跟有效数字差不多,但是还有点差别)
此处的float和double都是和Java/C类似 都是IEEE 754标准的浮点数[存在一定的缺陷,精度会丢失,存在一定的误差
e.g. 0.1+0.2 != 0.3 ==比较两个浮点数,非常危险的
->decimal(M,D) 精度更高的浮点数~~(使用其他的方式 来存储小数)
使用decimal表示小数,精度是更高了 但是运算速度会变慢,占用的空间也更多
decimal(3,1) 总长度是3,小数点后1位
->BigDecimal Java中对于decimal的一个实现
-
字符串类型
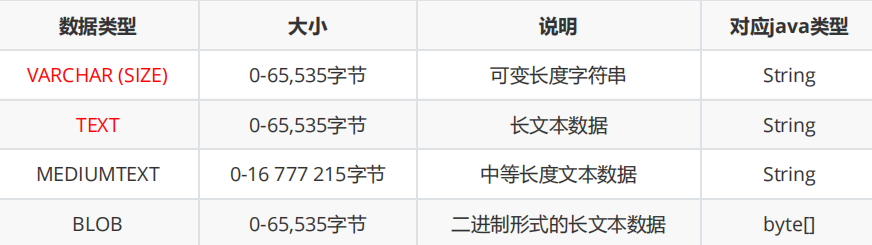
->VARCHAR(SIZE)【最常用】 size表示该类型里最多存储几个字符(不是字节),当你写了size为10,不是说,当前就立即分配10个字符的存储空间。。。是会先分配一个比较小的空间,如果不够,自动扩展,最大的空间不会超过10
【一个汉字,算是一个字符,但是可能是对应多个字节】
->TEXT 大小差不多64k
->BLOB 存储二进制的数据
->一般很少会在数据库的某一列中,存储特别大的数据(几十M,几百M),这样做会大大影响到数据库的增删查改的效率,实际开发中如果需要保存图片,一般都是把图片单独发到专门的目录中,然后让数据库保存图片的路径
文本数据VS二进制数据
文本数据存储的都是字符 这些字符都是可以在对应的码表上查到的
在码表上查不到的 就是二进制数据,音乐 图片 视频都属于二进制的
-
日期类型

计算机使用时间戳来表示时间,以1970年1月1日0时0分0秒作为基准,计算当前时刻和基准时刻的秒数/毫秒数/微秒数之差
四个字节的范围 如果是有符号 -21亿-》+21亿 如果是无符号 0-》42亿9千万
1690430855 快要超过4个字节的范围了
Java、python JS中就没有无符号类型 mysql虽然提供了无符号版本的数据类型(unsigned)但是官方文档上明确写了不建议使用,会在未来版本废除
因为两个无符号类型想减 可能会产生溢出的情况 10u-20u =>很大的数字
->TIMESTAMP 使用4个字节,表示秒级时间戳,已经要捉襟见肘了,2038(15)年之后,4个字节就无法继续表示秒级时间戳了
2038年的时候,一定会有很多程序/系统 因为时间戳的问题产生严重的bug !!!
推荐使用datetime
->java.util.Date 这个类型 只能表示年月日 不能表示时分秒
->java.sql.Timestamp 8个字节的ms级时间戳,不用担心2038年的问题
总结:
上述类型,只需要掌握几个重要的即可
整数 int long
小数 double decimal
字符串 varchar
时间日期 datetime
b.创建表
进行表操作的前提 是必须要先能够选中数据库


->如果想要让表名/列名 和关键字一样 可以使用反引号`来把表名列名引起来(英文标点)
->此处列名在前面,类型在后面
->sec =>second(秒) 0.06s =》60ms 站在计算机的角度,是一个挺慢的时间了,mysql这样的数据库,性能其实是短板
create table 表名(列名 类型,列名 类型。。。)
c.查看所有表
(查看当前数据库中的所有表)
数据库中的内容都是持久化存储的 后续重启电脑,数据都是仍然存在的
d.查看指定表的结构
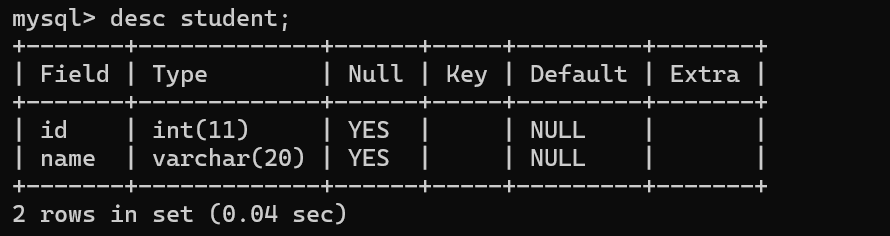
describe 描述
->field 字段 列
->int(11) 此处的(11)是显示的宽度,表示这个int类型,最多是占据11个字符的宽度(和存储时候的容量是无关的)
->Null空值 表示表格中的这个格子没填 此处写作YES允许这一列为NULL/null/Null
->default 默认值
e.删除表

删除表,也一定要慎重,也是非常危险的,甚至比删除数据库更严重,因为程序不会第一时间报错(有把之前备份的数据恢复回去的处理机会),程序就以错误的状态在生产环境又运行了很长时间,反而损失更严重。
5.练习题


钱都是带小数的,都是精确到分,为了精确表示,使用int来表示钱,以分为单位即可 0.5元=50分
6.MySQL表的增删查改(CRUD)
CRUD是数据库非常基础的部分,也是后端开发日常工作中,最主要要做的一项工作
a.新增
insert into 表名 values(值,值。。。); 此处的值要和列相匹配(列的个数和类型)

使用‘’或者“”来表示字符串,SQL没有“字符”这个类型

可以用中文的前提是创建数据库的时候指定字符集是utf8
指定列插入
insert into 表名(列名,列名。。。)values(值,值。。。);

比如此处只插入name, id这一列就会被填充为默认值(此处默认值就是null)
还可以一次插入多行记录
insert into 表名 values(值,值。。。) ,(值,值。。。)。。。
 这里的提示,就是反馈效果,客户端给服务器发起插入请求,服务器要返回这次插入是否成功了
这里的提示,就是反馈效果,客户端给服务器发起插入请求,服务器要返回这次插入是否成功了
一次插入多行记录,相比于一次插入一行,分多次插入(涉及到多次网络交互),要快不少(虽然请求比之前体积更大了)
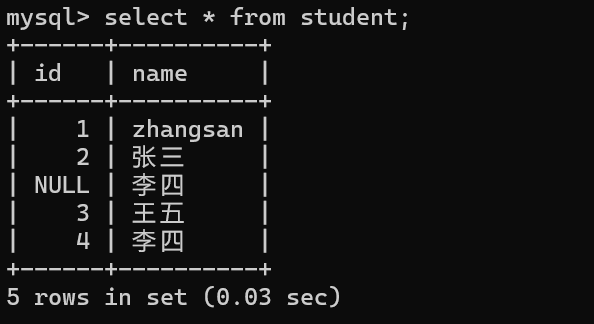
通过select就可以查询到表中的数据
datetime 类型如何插入呢?
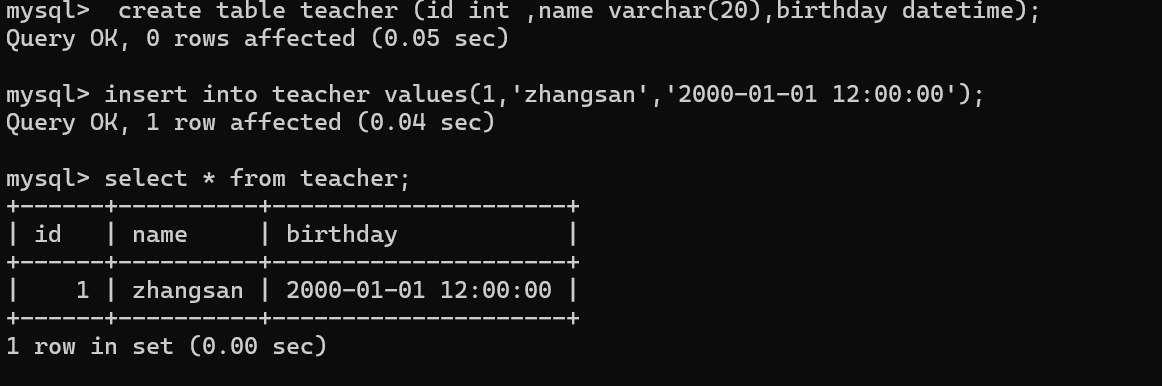
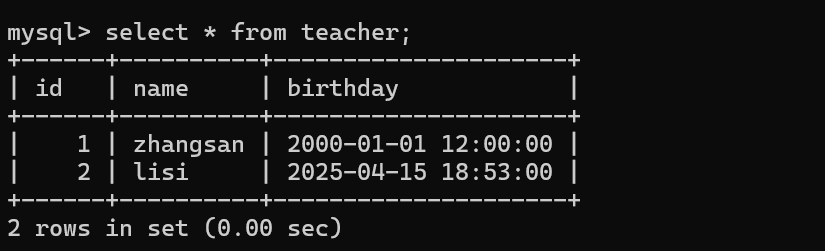
可以使用一个固定格式的字符串,来表示时间日期
如果想填写的时间日期,就是当前时刻,sql 提供了一个现成的函数now()
b.查询
sql中的增删改都非常简单,但是这个查询能玩出各种花样了,先构造一个表~
-
全列查询
select* from 表名;把表中的所有行和所有列都查询出来
*表示“通配符”可以代指所有的列
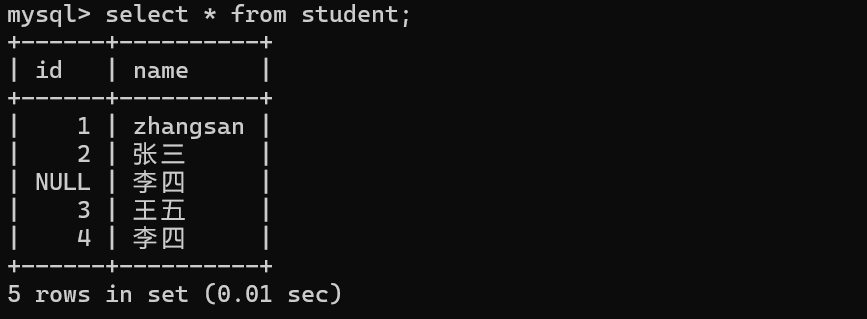
这里查询出来之后,服务器通过网络把这些数据返回给客户端,并且在客户端以表格的形式,打印出来
select* 操作,其实也是一个危险操作
mysql 是一个“客户端-服务器”结构的程序!
客户端这里进行的操作,就都会通过请求发送给服务器,服务器查询的结果也就会通过响应返回给客户端,都依靠网络
但是注意:如果数据库当前这个表中的数据特别多,就可能会产生问题
1.读取硬盘 把硬盘的IO给跑满了,此时程序的其他部分想访问硬盘,就会非常慢
2.操作网络 也可能把网卡的带宽也跑满,此时其他客户端想通过网络访问服务器,也会非常慢
==相当于堵车了,这样的拥堵,就可能导致客户端无法顺利访问到数据库,进一步的也就对整个系统造成影响(相当于数据库服务器挂了)
工作中涉及到的几套环境:
线下环境(公司内部的)
1.办公环境
入职公司,公司给你配个电脑(台式机/笔记本)
8C16G512G
2.开发环境
有的开发环境是办公环境(公司发的这个电脑)
也有的开发环境,是需要专门的服务器
28C128GNT(好几个人共用一个服务器)
3.测试环境
测试工程师,针对程序测试的时候,搭建的环境
28C128GNT(好几个人共用一个服务器) 需要尽可能的和生产环境保持一致
生产环境(线上环境)
一组服务器,这个服务器外面的用户能够直接访问到的服务器
如果生产环境的服务器上出现问题,外面的用户都能感知到,直接影响到用户体验
cpu 内存 硬盘 网卡 都会尽可能的用最好的
-
指定列查询
select 列名,列名。。。from表名;
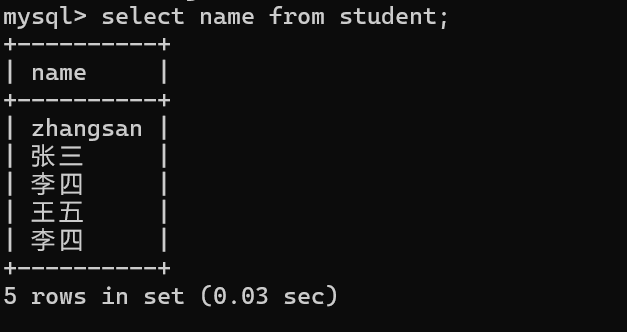
一个表的列数,可能是非常多的,某个场景下的操作,只需要关注其中的几个列
-
查询字段为表达式
SQL在查询的时候,可以进行一些简单的统计操作的
一边查询,一边进行计算,在查询的时候,写作由列名构成的表达式,把这一列中的所有行都带入到表达式中参与运算
select name,chinese-10 from exam;
这里的操作不会修改数据库服务器上的原始数据,只是在最终响应里的“临时结果”中做了计算
客户端-服务器结构的数据
进行查询的时候,是把服务器这里的数据读出来,返回给客户端,并且以临时表的形式进行展示
select name,chinese+english+math from exam;
表达式查询是列和列之间的运算,把每一行都带入到这样的运算中,不是行和行之间
如果这个表达式比较复杂,此时查询的临时结果,不容易理解是啥意思
-
别名
查询的时候给列或表达式指定别名(给表也能指定别名)
select 表达式 as 别名 from 表名;