动手学深度学习:手语视频在NiN模型中的测试
前言
NiN模型是在LeNet的基础上修改,提出了1x1卷积层和全局平均池化层的概念,减少了全连接所带来的参数量很多的问题。本篇在之前代码的基础上添加了模型保存,loss和acc记录以及记录模型时间等功能,所以模型后面的代码会重新记录一下。
模型
NiN模型主要的特色有1x1卷积和全局平均池化,以下是我个人的一些看法。
1x1卷积
由于再模型结尾将不再使用全连接层,如果还是原有的3x3等卷积的话就会丢失通道之间的信息,而1x1卷积在不改变图片大小的前提下,对通道进行卷积,可以解决这一问题。
全局平均池化
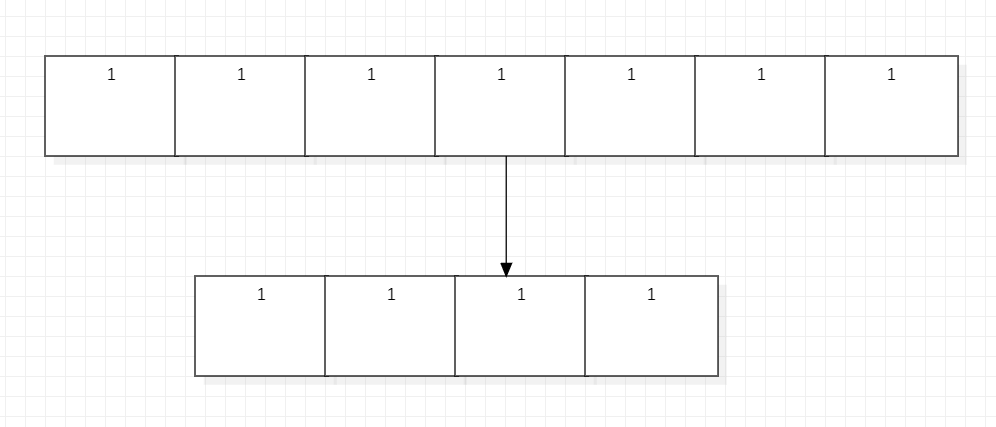
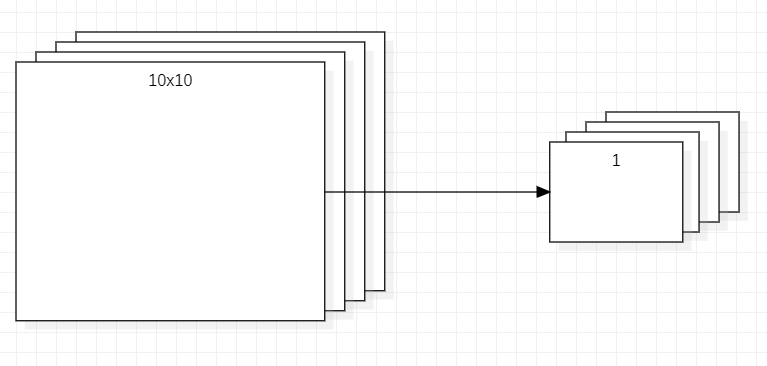
这个层主要是对每一个通道的图像进行池化变成1x1大小,也是取代全连接缩小像素得到要输出的类别大小的功能,如果说全连接是横向排布,不断减少到需要的数量的话(第一张图),那么全局平均池化就是竖向连接,一次性缩小到需要的形状(第二张图)。
代码
import torch.nn as nn
import os
import time
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
def nin_block(in_channels,out_channels,kernel_size,strides,padding):return nn.Sequential(nn.Conv2d(in_channels,out_channels,kernel_size,strides,padding),nn.ReLU(),nn.Conv2d(out_channels,out_channels,1),nn.ReLU(),nn.Conv2d(out_channels,out_channels,1),nn.ReLU())
net=nn.Sequential(
nin_block(frames_len,96,11,4,0),
nn.MaxPool2d(3,2),
nin_block(96,256,5,1,2),
nn.MaxPool2d(3,2),
nin_block(256,384,3,1,1),
nn.MaxPool2d(3,2),
nn.Dropout(0.5),
nin_block(384,len(labels),3,1,1),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten()).to(device)
def init_weight(m):if type(m)==nn.Linear or type(m)==nn.Conv2d:nn.init.xavier_uniform_(m.weight)
net.apply(init_weight)

学习率单独设置了一个变量
loss_fn=nn.CrossEntropyLoss()
lr=0.001
optimer=torch.optim.SGD(net.parameters(),lr=lr)#0.01会导致loss为nan
定义保存路径和模型名次,将主要需要调节的参数作为整个保存的文件夹名更易于区分。
# 初始化最小测试损失
best_test_loss = float('inf')
model_name="NiN"
epochs_num=300
save_path="./save/"+model_name+"_input_channels"+str(frames_len)+"_output_channels"+str(len(labels))+"_lr"+str(lr)+"_epochs"+str(epochs_num)+"/"
if not os.path.exists(save_path):os.makedirs(save_path)print(f"文件夹 '{save_path}' 已创建。")
else:print(f"文件夹 '{save_path}' 已存在。")
best_model_path = save_path+'model.pt'
best_onnx_path=save_path+"model.onnx"
添加计时功能,便于查看模型训练时间
train_len=len(train_iter.dataset)
all_acc=[]
all_loss=[]
test_all_acc=[]
test_all_loss=[]
start_time = time.time()
shape=None
for epoch in range(epochs_num):acc=0loss=0for x,y in train_iter:x=x.to(device)y=y.to(device)hat_y=net(x)l=loss_fn(hat_y,y)loss+=loptimer.zero_grad()l.backward()optimer.step()acc+=(hat_y.argmax(1)==y).sum()all_acc.append((acc/train_len).cpu().numpy())all_loss.append(loss.detach().cpu().numpy())
# print(all_loss)test_acc=0test_loss=0test_len=len(test_iter.dataset)with torch.no_grad():for x,y in test_iter:x=x.to(device)y=y.to(device)shape=x.shapehat_y=net(x)test_loss+=loss_fn(hat_y,y)test_acc+=(hat_y.argmax(1)==y).sum()test_all_acc.append((test_acc/test_len).cpu().numpy())test_all_loss.append(test_loss.detach().cpu().numpy())print(f'{epoch}的test的acc{test_acc/test_len}')# 保存测试损失最小的模型if test_loss < best_test_loss:best_test_loss = test_losstorch.save(net, best_model_path)
# dummy_input = torch.randn(shape).to(device)
# torch.onnx.export(net, dummy_input, best_onnx_path, opset_version=11)print(f'Saved better model with Test Loss: {best_test_loss:.4f}')
end_time = time.time()
elapsed_time = end_time - start_time # 计算耗时
print(f"程序运行了 {elapsed_time:.4f} 秒") # 保留4位小数

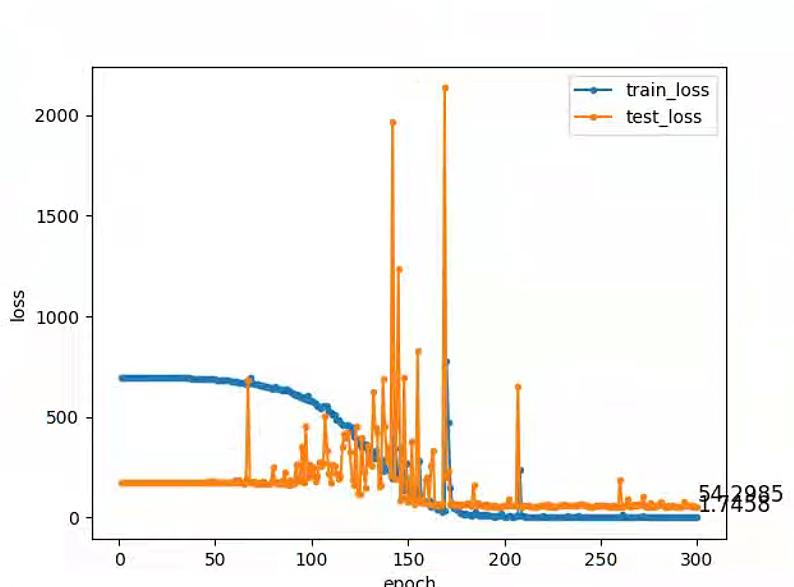
针对loss添加了test的记录并且将图片保存起来便于以后查看
import matplotlib.pyplot as plt
plt.plot(range(1,epochs_num+1),all_loss,'.-',label='train_loss')
plt.text(epochs_num, all_loss[-1], f'{all_loss[-1]:.4f}', fontsize=12, verticalalignment='bottom')
plt.plot(range(1,epochs_num+1),test_all_loss,'.-',label='test_loss')
plt.text(epochs_num, test_all_loss[-1], f'{test_all_loss[-1]:.4f}', fontsize=12, verticalalignment='bottom')
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.savefig(save_path+"train_loss.png")
acc同理处理
plt.plot(range(1,epochs_num+1),all_acc,'-',label='train_acc')
plt.text(epochs_num, all_acc[-1], f'{all_acc[-1]:.4f}', fontsize=12, verticalalignment='bottom')
plt.plot(range(1,epochs_num+1),test_all_acc,'-.',label='test_acc')
plt.text(epochs_num, test_all_acc[-1], f'{test_all_acc[-1]:.4f}', fontsize=12, verticalalignment='bottom')
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.savefig(save_path+"acc.png")
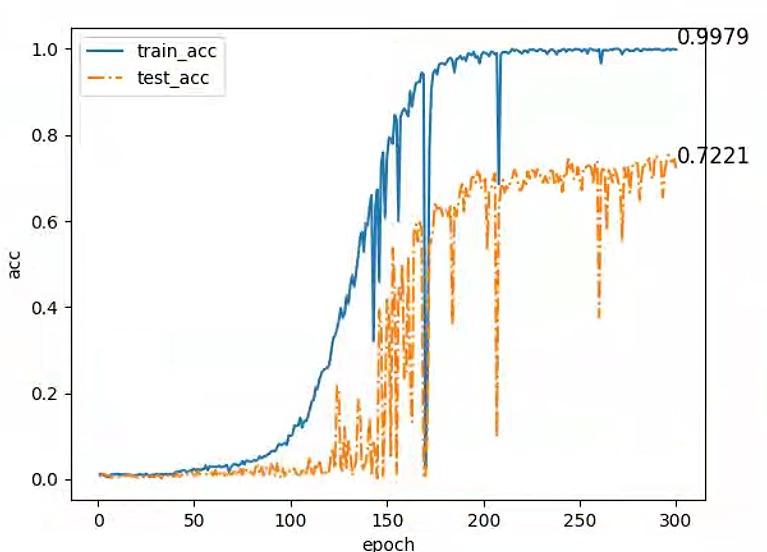
结论
NiN整体效果上比VGG还是要差一点的,收敛速度也很慢。但是运行时间比VGG快了快一倍,VGG花费了下图时间。