树莓派5+Vosk+python实现语音识别
简介
Vosk是语音识别开源框架,支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语, 印地语, 捷克语, 波兰语, 乌兹别克语, 韩国语, 塔吉克语。
模型下载链接:https://alphacephei.com/vosk/models/vosk-model-cn-0.15.zip
实验环境:
- 树莓派第5代
- usb麦克风
安装
pip install vosk -i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packages
pip install sounddevice -i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packages将下载好的模型文件 vosk-model-cn-0.15.zip 上传到树莓派系统自定义的目录并解压,如图所示:
编写示例代码测试:
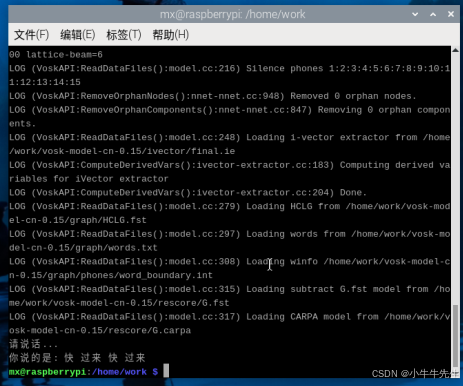
import sounddevice as sd
import vosk
import queue
import jsonq = queue.Queue()def callback(indata, frames, time, status):q.put(bytes(indata))def recognize_speech():model = vosk.Model(r"/home/work/vosk-model-cn-0.15") #模型文件路径with sd.RawInputStream(samplerate=16000, blocksize=8000, dtype='int16', channels=1, callback=callback):recognizer = vosk.KaldiRecognizer(model, 16000)print("请说话...")while True:data = q.get()if recognizer.AcceptWaveform(data):result = recognizer.Result()text = json.loads(result)["text"]print("你说的是: " + text)breakif __name__ == "__main__":recognize_speech()运行结果示例: