探索 HumanoidBench:类人机器人学习的新平台
在科技飞速发展的当下,类人机器人逐渐走进我们的视野,它们有着和人类相似的外形,看起来能像人类一样在各种环境里完成复杂任务,潜力巨大。但实际上,让类人机器人真正发挥出实力,还面临着重重挑战。
这篇文章,将给大家带来一个Benchmark的工作:HumanoidBench。
它是一个新的模拟基准平台。工作链接:https://arxiv.org/pdf/2403.10506
如下图所示:
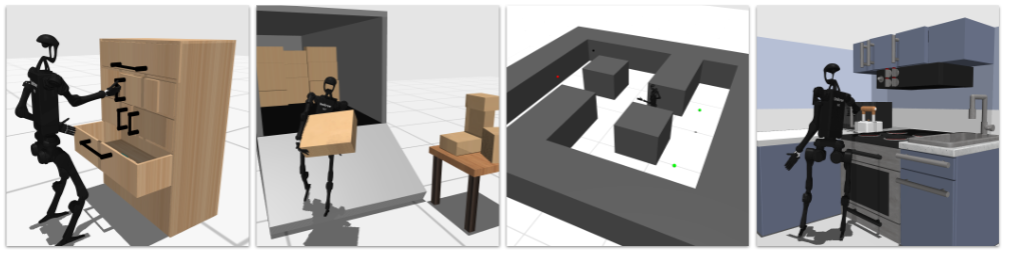
1、研究背景:类人机器人发展的困境
一直以来,类人机器人都被寄予厚望,大家期待它们能在日常生活中无缝协助人类。像波士顿动力的 Atlas、特斯拉的 Optimus、宇树的 H1 等,这些类人机器人在硬件方面取得了很大进展。可它们的控制器大多是针对特定任务专门设计的,每次遇到新任务或新环境,都得花费大量精力重新设计,而且整体的全身控制能力也很有限。
近年来,机器人学习在操作和移动方面都有了一定进展。但要把这些学习算法应用到类人机器人上,却困难重重。主要原因是在现实世界中对类人机器人进行实验,成本太高,还存在安全风险。比如,类人机器人的硬件设备价格昂贵,一旦在实验中损坏,维修成本很高;而且如果机器人在实验过程中失控,还可能对周围环境和人员造成伤害。
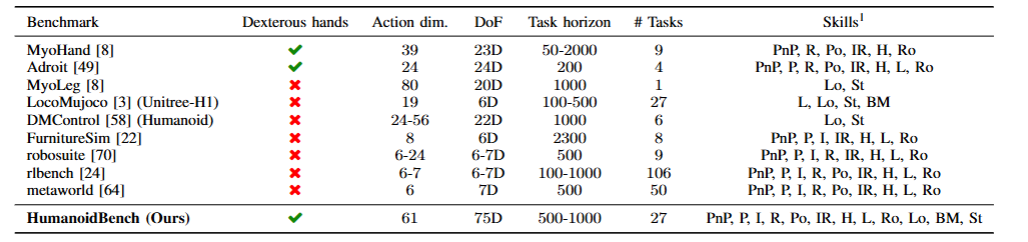
为了推动类人机器人研究的快速发展,就需要一个合适的测试平台。以往的模拟环境和基准测试,要么只关注简单的操作任务,像抓取和放置;要么只侧重于移动,忽略了全身控制和复杂任务的挑战。就算有些引入了复杂任务,但在任务多样性、模型准确性等方面还是有所欠缺。所以,开发一个全面的、能涵盖各种复杂任务的类人机器人基准测试平台就显得尤为重要,这就是 HumanoidBench 诞生的背景。
2、方法——打造类人机器人的试炼场
2.1 模拟环境搭建
HumanoidBench 的模拟环境基于 MuJoCo 物理引擎构建,这个引擎以运行速度快、物理模拟准确著称,为类人机器人的模拟提供了可靠的基础。在这个环境中,主要使用宇树 H1 类人机器人,它相对成本较低,并且有精确的模拟模型。H1 机器人配备了两只灵巧的 Shadow Hands,这让机器人具备了很强的操作能力。同时,环境中还提供了其他机器人模型,像宇树 G1、敏捷机器人 Digit,以及不同的末端执行器,比如 Robotiq 2F - 85 平行夹爪和宇树的 13 自由度手,满足不同研究的需求。
如下图:
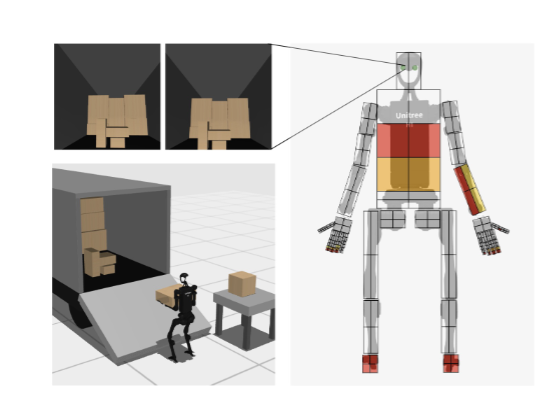
从机器人的身体和手部设置来看,研究人员对不同机器人模型进行了细致的调整。比如,为了让模拟机器人更接近人类形态,去掉了 Shadow Hands 原本笨重的前臂,使机器人的手部更符合未来类人机器人的发展趋势。在观察和动作空间方面,也有明确的设定。观察空间包含机器人的本体感受状态(关节角度和速度)、任务相关的环境观察(物体的姿态和速度),还有从机器人头部两个摄像头获取的视觉观察以及全身的触觉感知。动作空间则通过位置控制来实现,控制频率为 50Hz,这样的设置能让机器人在模拟环境中做出各种动作。
2.2 任务设计
HumanoidBench 包含了丰富多样的任务,总共 27 个,分为 12 个移动任务和 15 个全身操作任务。这些任务从简单到复杂,涵盖了各种不同的场景和技能要求。
如下图:

移动任务像是走路、站立、跑步等,看似简单,但对于类人机器人来说却并不轻松。以走路任务为例,机器人要保持向前的速度接近 1m/s,同时还不能摔倒,这就需要它精确控制身体的平衡和各个关节的运动。跑步任务则要求机器人以 5m/s 的速度前进,对其运动能力和协调性提出了更高的要求。还有像跨越障碍、在迷宫中导航这样的任务,不仅考验机器人的移动能力,还需要它具备一定的感知和决策能力。
全身操作任务就更复杂了,涉及到与物体的各种交互。比如,从卡车卸货这个任务,机器人要先走到卡车旁,然后拿起货物,再搬运到指定位置,这一过程需要它协调手部的抓取动作和身体的移动,还要根据货物的重量和形状调整力度。再比如打开不同类型的橱柜门,像铰链门、滑动门和抽屉,每种门的打开方式都不同,机器人需要学习不同的操作技巧。还有像打篮球这样的任务,机器人要先接住从不同方向飞来的球,然后再投篮,这对它的反应速度、空间感知能力和手部操作能力都是极大的挑战。
2.3 分层强化学习策略
针对类人机器人学习的复杂性,研究人员引入了分层强化学习(HRL)策略。在传统的端到端强化学习中,算法很难处理高维度的动作空间和复杂的长期规划任务,而 HRL 则将学习问题分层,把低层次的技能策略和高层次的规划策略分开。
具体来说,在执行操作任务时,会先预训练一个低层次的到达策略。比如在推箱子任务中,低层次策略就是让机器人的手能够准确地到达指定的 3D 点。这个策略就像是搭建高楼的基石,需要非常稳健。为了训练出这样的策略,研究人员利用了 MuJoCo MJX 提供的硬件加速功能,在大量并行环境中进行训练。训练完成后,低层次策略就被固定下来,高层次策略则利用这个预训练的低层次策略,根据不同的任务需求,指挥低层次策略执行相应的动作,从而实现整个任务的完成。
3、实验——检验 HumanoidBench 的有效性
3.1 实验设置

在实验中,研究人员选择了四种强化学习算法作为基线进行测试,分别是 DreamerV3、TD - MPC2、SAC 和 PPO。这些算法在机器人学习领域都有一定的代表性,但在面对类人机器人的复杂任务时,表现却各有不同。
为了确保实验的准确性和可靠性,研究人员对每个算法都进行了约 48 小时的训练,不同算法的训练步数有所差异,比如 TD - MPC2 训练 200 万步,DreamerV3 训练 1000 万步。在训练过程中,每个环境都设置了密集奖励和稀疏子任务完成奖励,通过这些奖励机制来引导机器人学习正确的行为。同时,还对每个任务设置了成功的定性指标,方便评估算法的性能。
3.2 实验结果
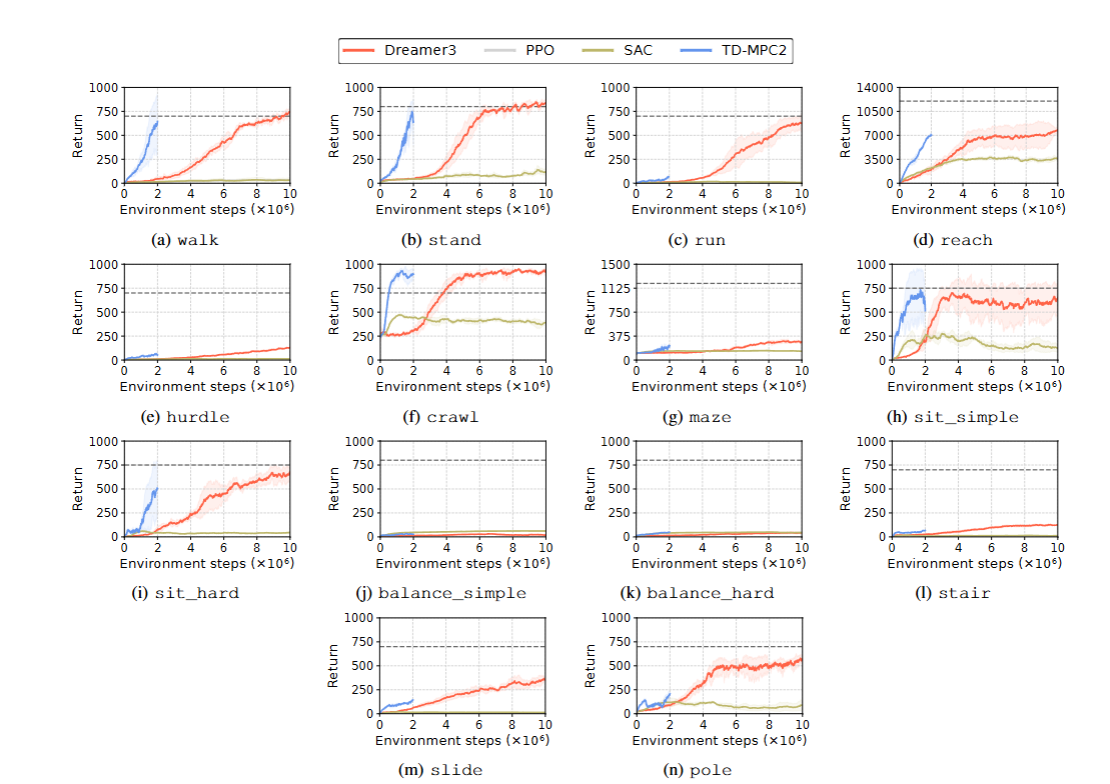
从实验结果来看,这些基线算法在大多数任务上的表现都不太理想。在移动任务中,即使是像走路这样看似简单的任务,算法也需要大量的训练步数才能学会,而且成功率也不高。这主要是因为类人机器人的状态和动作空间维度很高,即使在移动任务中手部动作使用较少,但算法还是难以忽略手部的信息,导致策略学习变得困难。
点击探索 HumanoidBench:类人机器人学习的新平台查看全文