Motion Tracks:少样本模仿学习中人-机器人之间迁移的统一表征
25年1月来自Cornell和Stanford的论文“MOTION TRACKS: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning”。
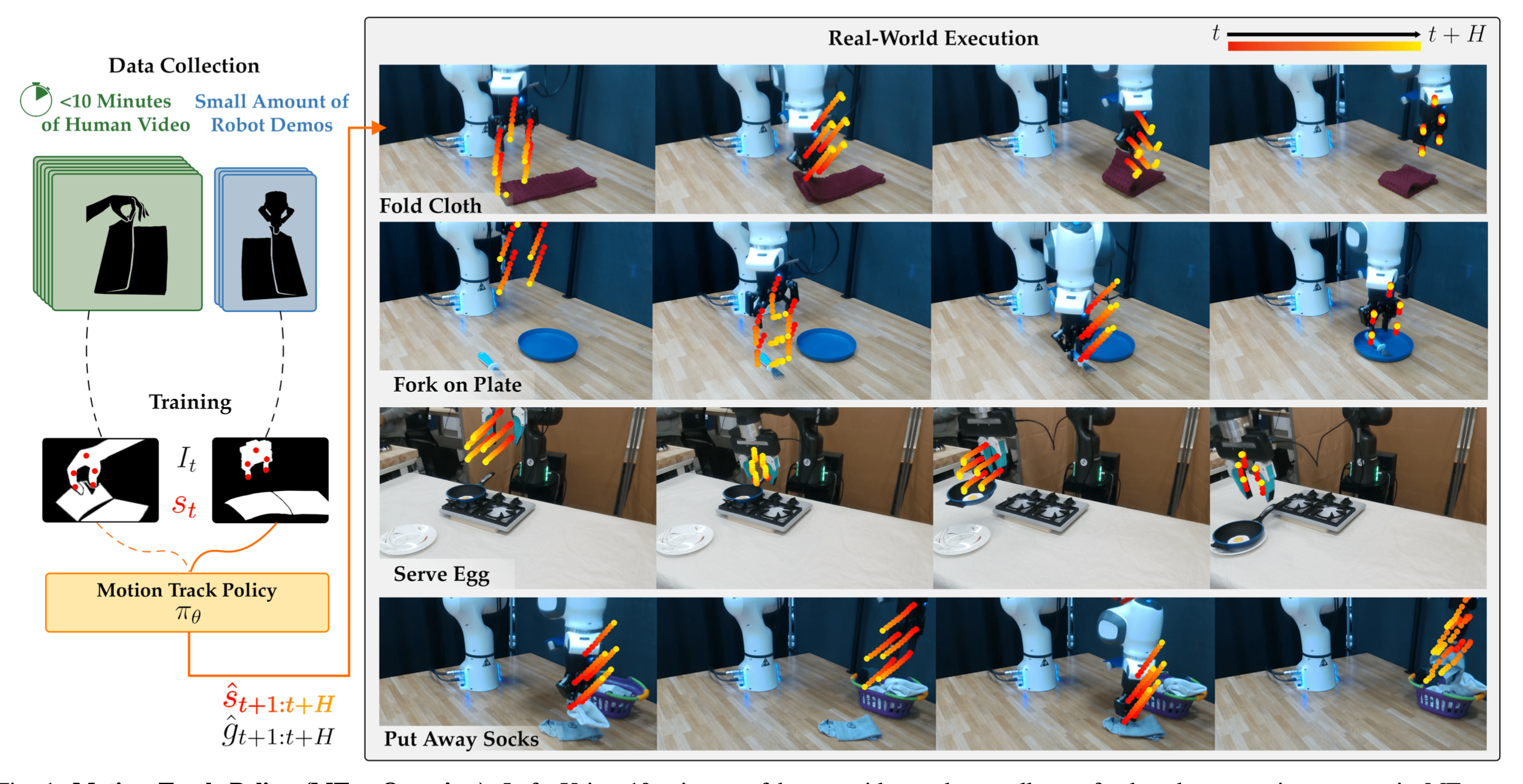
教会机器人自主完成日常任务仍然是一项挑战。模仿学习 (IL) 是一种强大的方法,它通过演示向机器人灌输技能,但受限于收集遥控机器人数据需要耗费大量的人力。人类视频提供一种可扩展的替代方案,但由于缺乏机器人动作标签,直接利用这些视频训练 IL 策略仍然困难重重。为了解决这个问题,将动作表示为图像上的短视域二维轨迹。这些动作,或Motion Tracks,捕捉人手或机器人末端执行器的预测运动方向。实例化一种名为运动轨迹策略 (MT-π) 的 IL 策略,它接收图像观测并将运动轨迹输出为动作。通过利用这个统一的跨具身动作空间,MT-π 仅需几分钟的人类视频和有限的额外机器人演示就能成功完成任务。在测试时,从两个摄像头视角预测运动轨迹,并通过多视角合成恢复六自由度轨迹。 MT-π 在 4 项真实世界任务中实现 86.5% 的平均成功率,比不利用人类数据或行动空间的最先进 IL 基线高出 40%,并且可泛化到仅在人类视频中看到的场景。
模仿学习 (IL) 是一种广泛采用的方法,用于通过人类演示训练机器人策略 [1, 2]。然而,即使是最先进的 IL 策略,在某些情况下也可能需要数百 [3, 4] 甚至数万 [5–7] 次众包遥操作演示才能达到良好的性能。这些演示通常由遥操作机器人通过虚拟现实设备 [8] 或木偶操控界面 [4, 9, 10] 收集。然而,某些设备不仅专用于机器人且并非普遍可用,而且长时间使用这些设备进行远程操作非常耗时耗力,并且通常需要大量练习才能开始收集数据集。
另一种方法是让机器人从被动观察中学习,例如从人类演示所需任务的视频中学习。人类视频数据更容易大规模收集,现有数据集提供数千小时的演示 [11, 12]。然而,这些真人视频缺乏训练模仿学习策略所必需的机器人动作标签,这对将真人视频中的知识迁移到机器人策略提出了挑战。
近期研究,通过对真人数据进行视觉表征预训练,解决了这一问题 [11, 13, 14]。然而,由于预训练数据的多样性 [15, 16],这些表征通常难以直接应用或针对特定任务进行微调。其他方法则侧重于收集特定任务的真人视频和遥控机器人演示,这些演示可以捕捉更广泛的动作。然后,这些方法通过逆强化学习 [21] 学习共享状态空间表征 [17–19]、共享潜嵌入 [20] 或奖励函数。虽然这些方法可以有效地对齐输入表征,但它们对输出动作对机器人数据集的依赖,限制它们的表达能力。例如,无论条件质量如何,仅接受向右关抽屉演示训练的机器人,可能无法泛化到向左关抽屉的动作。
其主要见解是,尽管人手和机器人末端执行器之间存在具身差距,但可以通过将它们的运动投影到图像平面作为 2D 轨迹来统一它们的动作空间。训练一个 IL 策略,它将图像观测作为输入,并将动作预测为运动轨迹或图像空间中的短视界 2D 轨迹,指示人手或机器人末端执行器上点的预测运动方向。这种重构使动作预测与人手和机器人末端执行器兼容。该方法需真值地面真实运动轨迹,并使用已知相机外参的正向运动学为机器人演示获得真值运动轨迹。在测试时,从两个摄像机视图预测运动轨迹并使用多视图几何在 3D 中重建可执行的 6DoF 末端执行器轨迹。
目标是学习一种视觉运动策略,该策略主要基于人类视频和少量机器人演示进行训练。为此,从像素级关键点的共享表征中提取动作,并训练一种直接在图像空间中输出动作的策略,从而使该流程与任一具身兼容。
给定图像 I_t(i) 和相应的 k 个末端执行器关键点 s_t^(i),我们的目标是学习一个关键点条件运动轨迹网络。
本文提出 MT-π(Motion Track 策略),这是一个旨在通过预测图像空间中的视觉运动控制动作来统一人类和机器人演示的框架。具体来说,将人类和机器人的演示映射到图像中机械臂上二维关键点的通用表示,并训练一个策略来预测这些关键点未来的像素位置。通过将人类和机器人的演示投射到这个统一的动作空间,在人类和机器人数据集上进行协同训练,可以促进人类和机器人运动之间的迁移。在推理时,只需将图像空间中的这些预测映射到三维空间,即可恢复机器人的动作。
MT-π 概述如图所示:
数据预处理
机器人演示。为了收集机器人演示,我们假设工作空间内有 ≥ 1个已标定的摄像头(摄像头到机器人的外参已知)以及机器人本体感受状态。对于每次演示,从每个可用视角捕捉图像轨迹 I_t(i)。利用机器人末端执行器的位置和已校准的外参,将末端执行器的三维位置投影到二维图像平面,得到 k 个关键点 s_t(i) = {(u_j(i),v_j(i))} 。实际应用中,取 k = 5,使夹持器上每个手指有两个点,中心有一个点(如图所示)。选择这种点定位方式,是因为它更适合夹持器在抓取动作中的定位。夹持器的打开/关闭状态表示为二元抓取变量 g_t^(i) ∈ {0, 1}。
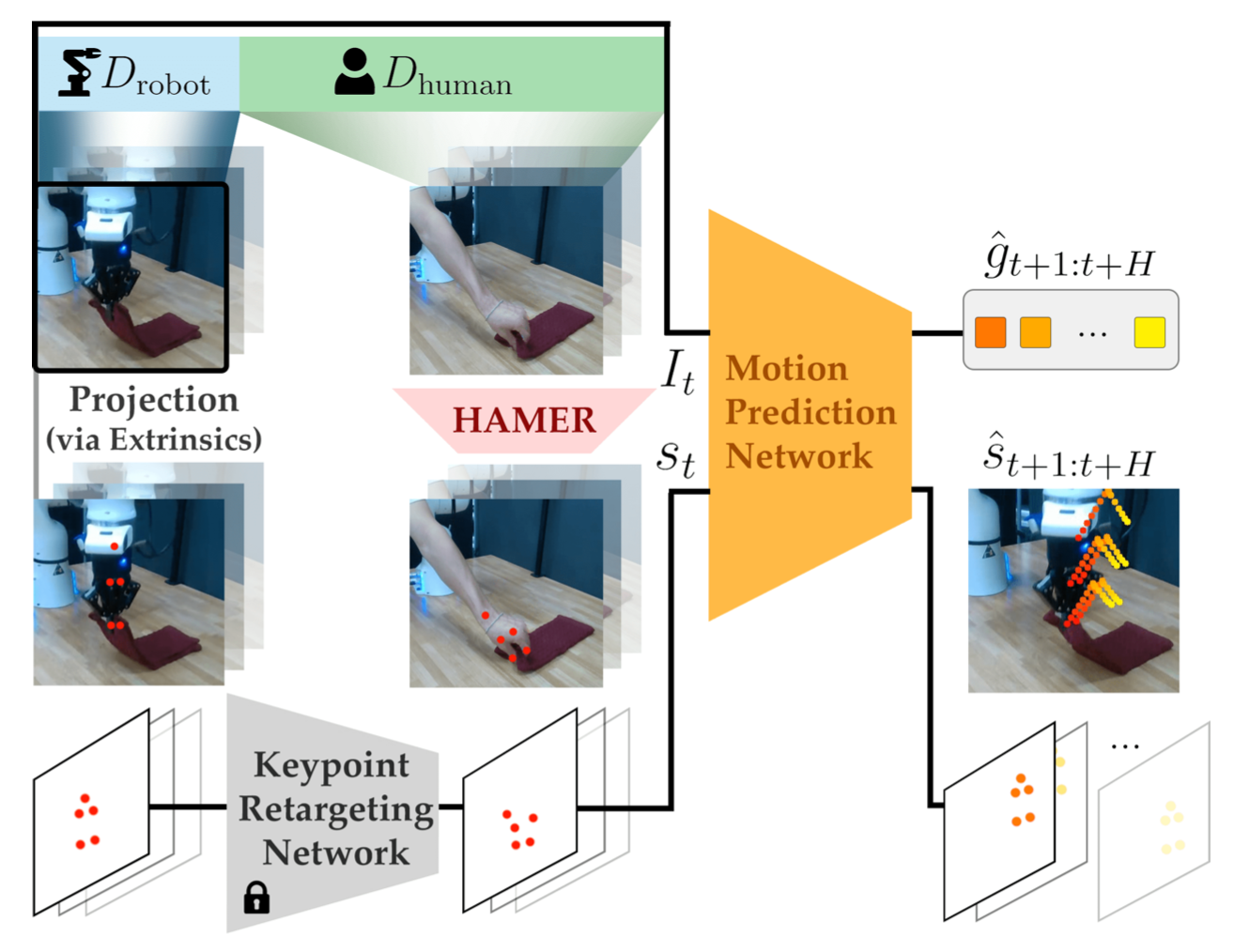
人类演示。人类演示使用 RGB 摄像头采集,无需访问已标定的外参,从而可以利用大规模人体视频数据集。使用 HaMeR [22](一款现成的手势检测器)提取一组 21 个关键点 s_t(i) = {(u_j(i) , v_j(i) )}。为了粗略匹配机器人手爪的结构,选择 k = 5 个关键点的子集:手腕上一个,拇指和食指上各两个。为了从人体视频中推断每个时间步的抓取动作,使用一种基于手部关键点与被操作物体接近度的启发式算法。对于每个任务,首先使用 Grounding-DINO [62] 和 SAM-v2 [63] 获取物体的像素级掩码。然后,如果目标掩码与拇指加上任何其他指尖上的关键点之间的像素数低于某个阈值,则设置 g_t^(i) = 1。通过松散地匹配人手和机器人夹持器之间关键点的位置和顺序,在图像平面上创建人类和机器人动作表征之间的明确对应关系。
训练流程
关键点重定向网络。尽管人手和机器人夹持器上点之间存在明确的对应关系,但具身差距(例如,手和夹持器之间的尺寸差异)仍然会导致关键点间距明显不同。直接以这些点为条件可能会导致策略过度依赖这些差异,为每个具身生成不同的轨迹预测,从而无法生成在人类演示中捕捉到的动作。为了解决这个问题,引入一个关键点重定向网络(如上图所示),它将机器人关键点映射到与人手关键点更一致的位置。
对于每个人类演示,为除锚点(例如,手腕)之外的所有关键点添加均匀的噪声。训练一个小型多层感知器 (MLP),将这些带噪声的关键点映射回其原始位置。训练完成后,该网络将被冻结并在训练和测试中使用。由于该网络仅训练为将带噪声的关键点映射回其原始间距,因此它可以兼容人类或机器人关键点作为输入。也就是说,任何机器人的关键点都将被视为“噪声点”,并被映射到更接近人手位置的位置。对于人体关键点,该网络充当身份映射。
Motion Track 网络。使用扩散策略目标 [3] 来训练预测 Motion Track 的策略头。网络的输入是来自预训练 ResNet 编码器 [64] 的图像嵌入和像素空间中当前关键点位置 s_t(i) 的串联。然后,网络预测每个二维关键点的偏移量以及短视界 H 内每个未来时间步的夹持器状态 g_t^(i)。重要的是,该模型每次只拍摄一张视点图像,但与视点姿态无关,这使得它能够适应通常来自单个 RGB 视点、互联网规模的真人视频。
图像表示对齐。为了防止策略过度关注人机输入图像之间的视觉差异,使用两个辅助损失函数来促进视觉嵌入的对齐:
• l_KL:[20] 中的 KL 散度损失函数,用于最小化人机特征分布之间的散度
• l_DA:[65] 中的域自适应损失函数,用于通过欺骗判别器来鼓励策略生成难以区分的人机嵌入。
总训练损失函数是原始扩散策略目标函数与辅助损失函数加权和的组合,其中 l_KL 和 l_DA 是缩放因子。在实践中,使用 l_KL = 1.0,并根据人机演示的比例调整 l_DA ∈ [0, 1]。
动作推理
在推理过程中,假设可以访问 2 个已知外参的摄像头。首先利用相机到机器人的外部参数,获取每个视角的机器人夹爪的一组关键点 s_t^(i)。然后,将这些关键点传入冻结关键点重定向网络,以获得 sˆ_t^(i),其位置与训练期间看到的更相似。接下来,将 sˆ_t^(i) 与它的图像嵌入连接起来,并作为输入传入运动轨迹网络 π_θ,以获得每个视角的预测轨迹,以及每个步骤的夹爪状态 gˆ_t +1:t +H(如上图所示)。使用已知外参的立体三角测量,恢复每个时间步轨迹的 3D 位置(如下图所示)。给定当前和预测的未来 3D 关键点,计算一个由旋转矩阵 R 和平移向量 t 组成的刚性变换,以使连续时间步之间的 3D 关键点达到最佳对齐。这些相对变换随后可作为可直接执行的六自由度末端执行器增量动作 a_t:t+H。准确的动作恢复,取决于两个摄像机视图之间的运动轨迹是否一致。通过实证研究发现,以相对一致、单峰的方式收集人类和机器人的演示有助于维持视图之间的一致性,从而实现更可靠的动作恢复。
利用一系列桌面任务对 MT-π 进行评估,并与两种常用的基于图像的 IL 算法进行比较:扩散策略 (DP) [3] 和 ACT [4]。所有算法均基于 25 个遥控机器人演示进行训练。对于扩散策略和 ACT,使用与原始实现相同的输出空间,即 6DoF 末端执行器增量命令。此外,为所有基线配备来自额外腕部摄像头的观测数据(这可以提高性能)。MT-π 仅接收两个第三人称视角,但每个任务会提供大约 10 分钟的额外真人视频演示。