HTTP:九.WEB机器人
概念
- Web机器人是能够在无需人类干预的情况下自动进行一系列Web事务处理的软件程序。人们根据这些机器人探查web站点的方式,形象的给它们取了一个饱含特色的名字,比如“爬虫”、“蜘蛛”、“蠕虫”以及“机器人”等!
爬虫概述
- 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理。
-
网络爬虫始于一张被称作种子的统一资源地址(URL)列表。当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张“待访列表”,即所谓爬行疆域。此疆域上的URL将会被按照一套策略循环来访问。如果爬虫在执行的过程中复制归档和保存网站上的信息,这些档案通常储存,使他们可以较容易的被查看。阅读和浏览他们存储的网站上并即时更新的信息,这些被存储的网页又被称为“快照”。越大容量的网页意味着网络爬虫只能在给予的时间内下载越少部分的网页,所以要优先考虑其下载。高变化率意味着网页可能已经被更新或者被取代。一些服务器端软件生成的URL(统一资源定位符)也使得网络爬虫很难避免检索到重复内容。
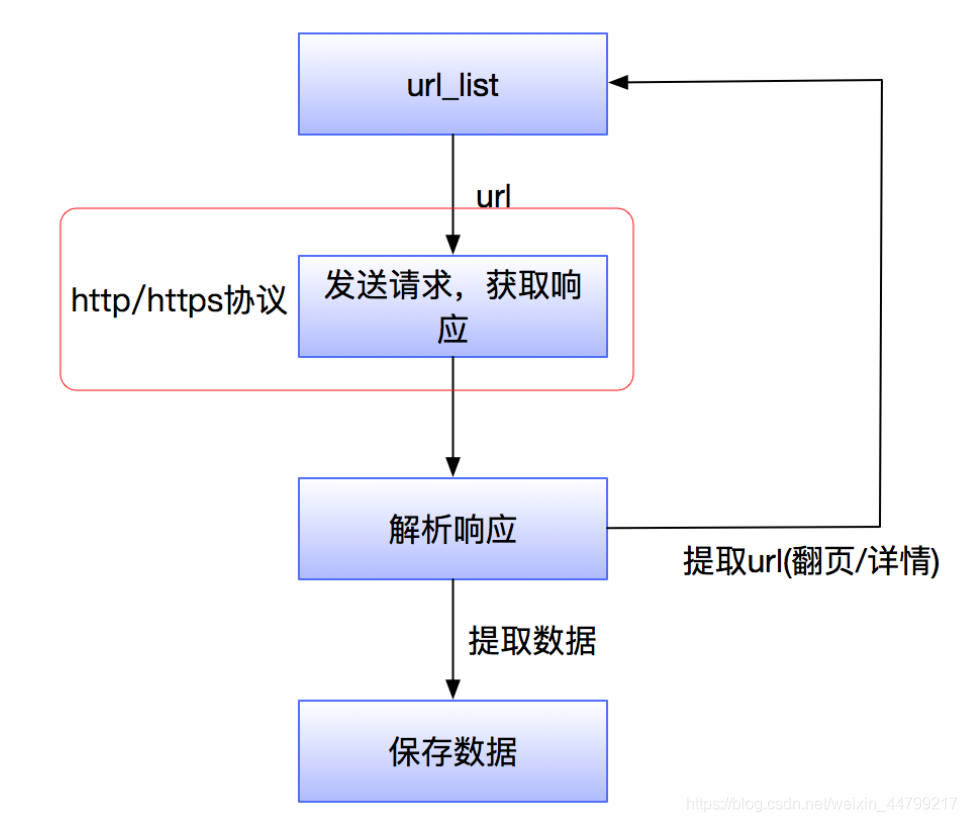
爬虫流程
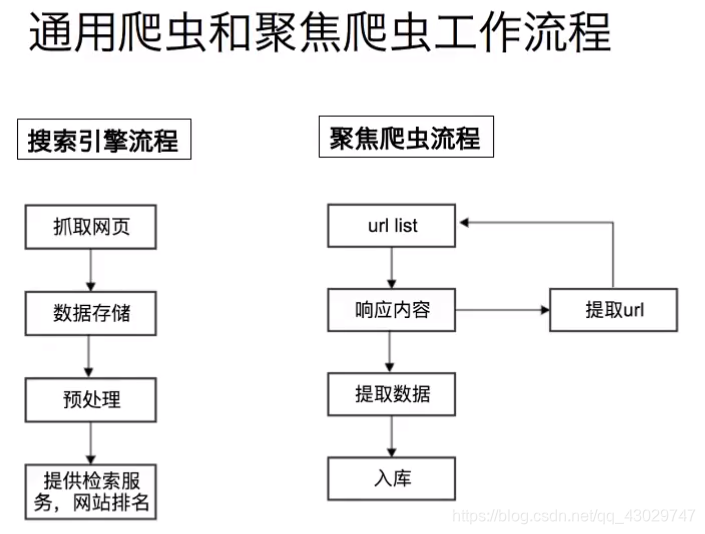
- 发送 HTTP 请求到目标网站:爬虫模拟浏览器发送请求获取网页数据。
- 获取服务器返回的 HTML 页面:服务器响应请求并返回网页内容。
- 解析 HTML 内容,提取所需数据:爬虫使用解析库提取网页中的有用信息。 要避免环路的出现,因为这些环路会暂停或减缓机器人的爬行过程
- 保存数据以供后续使用:提取的数据被保存到文件或数据库中。
环路对爬虫有害的三个原因:
爬虫会陷入循环之中,从而兜圈子,浪费带宽,无法获取新页面!
爬虫无限的请求服务器,从而阻塞了真正的用户去