gbdt总结
GBDT
GBDT被写作梯度提升机器(Gradient Boosting Machine,GBM),它融合了Bagging与Boosting的思想
GBDT中自然也包含Boosting三要素:
损失函数 𝐿(𝑥,𝑦)
:用以衡量模型预测结果与真实结果的差异
弱评估器 𝑓(𝑥)
:(一般为)决策树,不同的boosting算法使用不同的建树过程
综合集成结果 𝐻(𝑥)
:即集成算法具体如何输出集成结果
GBDT与ADABOOST 的不同:
1.弱评估器:GBDT的弱评估器输出类型不再与整体集成算法输出类型一致。无论GBDT整体在执行回归/分类/排序任务,弱评估器一定是回归器。GBDT通过sigmoid或softmax函数输出具体的分类结果,但实际弱评估器一定是回归器。
2.损失函数 𝐿(𝑥,𝑦):任意可微的函数
3.拟合残差:不像AdaBoost一样通过调整数据分布来间接影响后续弱评估器。相对的,GBDT通过修改后续弱评估器的拟合目标来直接影响后续弱评估器的结构。
4.抽样思想:在每次建树之前,允许对样本和特征进行抽样来增大弱评估器之间的独立性
(这种思想来源于bagging)
参数图

1.迭代过程
init:初始预测结果,先选择输入任意评估器,不行选NONE(此时对于每一个样本都有不同的H0),再不行选字符串"zero"(通常选zero)
用弱回归器完成分类任务:二分类用sigmoid,多分类用softmax,几分类就要输入几个值,因此多分类问题在随机森林上的计算可能会表现得更快。
8种损失函数loss:
分类器中的loss:字符串型,可输入"deviance", "exponential",默认值="deviance"
对于梯度提升回归树来说,loss的备选项有如下几种:回归器中的loss:字符串型,可输入{"squared_error", "absolute_error", "huber", "quantile"},默认值="squared_error"
如何选择:
当高度关注离群值、并且希望努力将离群值预测正确时,选择平方误差
努力排除离群值的影响、更关注非离群值的时候,选择绝对误差
试图平衡离群值与非离群值、没有偏好时,选择Huber或者Quantileloss
2.弱评估器结构
特别注意criterion:采用弗里德曼均方误差,公式为左右叶子节点上样本量的调和平均 * (左叶子节点上均方误差 - 右叶子节点上的均方误差)^2
前者鼓励左右样本量相似,后者则鼓励不纯度差异巨大
用这个效果最好,有时基于平方误差也效果类似
3.提起停止(全新,重要)
目的:节省计算资源,防止进入无效迭代
三个条件:
当GBDT已经达到了足够好的效果(非常接近收敛状态),持续迭代下去不会有助于提升算法表现(机器学习更常见)
GBDT还没有达到足够好的效果(没有接近收敛),但迭代过程中呈现出越迭代算法表现越糟糕的情况(深度学习更常见)
虽然GBDT还没有达到足够好的效果,但是训练时间太长/速度太慢,我们需要重新调整训练
在实际数据训练时,我们往往不能动用真正的测试集进行提前停止的验证,因此我们需要从训练集中划分出一小部分数据,专用于验证是否应该提前停止。
当连续n_iter_no_change次迭代中,验证集上损失函数的减小值都低于阈值tol,或者验证集的分数提升值都低于阈值tol的时候,我们就令迭代停止。
相关参数如下:
validation_fraction:从训练集中提取出、用于提前停止的验证数据占比,值域为[0,1]。
n_iter_no_change:当验证集上的损失函数值连续n_iter_no_change次没有下降或下降量不达阈值时,则触发提前停止。平时则设置为None,表示不进行提前停止。
tol:损失函数下降的阈值,默认值为1e-4,也可调整为其他浮点数来观察提前停止的情况。
什么时候使用提前停止呢?一般有以下几种场景:
当数据量非常大,肉眼可见训练速度会非常缓慢的时候,开启提前停止以节约运算时间
n_estimators参数范围极广、可能涉及到需要500~1000棵树时,开启提前停止来寻找可能的更小的n_estimators取值
当数据量非常小,模型很可能快速陷入过拟合状况时,开启提前停止来防止过拟合
4.弱评估器的训练数据:袋外数据
当进行有放回抽样时,就变成了随机提升树
对样本抽样参数:subsample
对特征的有放回抽样比例:max_features
随机模式则由参数random_state确定
过程:每建立一棵树,GBDT就会使用当前树的袋外数据对建立新树后的模型进行验证,以此来对比新建弱评估器后模型整体的水平是否提高,并保留提升或下降的结果。这个过程相当于在GBDT迭代时,不断检验损失函数的值并捕捉其变化的趋势。在GBDT当中,这些袋外分数的变化值被储存在属性oob_improvement_中,同时,GBDT还会在每棵树的训练数据上保留袋内分数(in-bag)的变化,且储存在属性train_score_当中。也就是说,即便在不做交叉验证的情况下,我们也可以简单地通过属性oob_improvement与属性train_score_来观察GBDT迭代的结果。
没有的参数:sklearn中的GBDT分类器并没有提供调节样本不均衡问题的参数class_weights,也不存在并行参数n_jobs。
要注意,如果样本存在严重不均衡的状况,那我们可能会考虑不使用梯度提升树,或者先对数据进行样本均衡的预处理后,再使用梯度提升树。
为什么没有n_jobs:GBDT中的树必须一棵棵建立、且后面建立的树还必须依赖于之前建树的结果,因此GBDT很难在某种程度上实现并行,因此sklearn并没有提供n_jobs参数给Boosting算法使用。
5.GBDT参数重要性
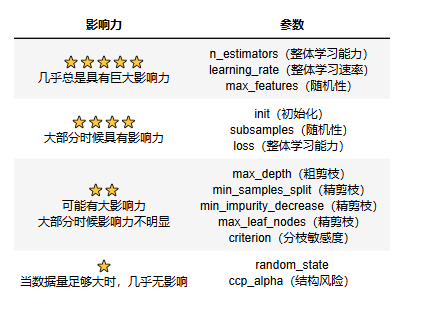
值得注意的是,在随机森林中非常关键的max_depth在GBDT中没有什么地位,取而代之的是Boosting中特有的迭代参数学习率learning_rate。在随机森林中,关注复杂度(max_depth)与模型整体学习能力(n_estimators)的平衡,单一弱评估器的复杂度越大,单一弱评估器对模型的整体贡献就越大,因此需要的树数量就越少。而在Boosting算法中我们寻找的是learning_rate与n_estimators的平衡。
同理,其它剪枝类参数在boosting里也没多大用
max_depth在gbdt里用来加深模型复杂度,在随机森林里用来剪枝
如果无法对弱评估器进行剪枝,最好的控制过拟合的方法就是增加随机性/多样性,因此max_features和subsample就很重要
可见,虽然树的集成算法们大多共享相同的超参数,都由于不同算法构建时的原理假设不同,相同参数在不同算法中的默认值可能被设置得不同,因此相同参数在不同算法中的重要性和调参思路也不同。