zset.
zset 有序集合
zset 保留了 set 不能有重复元素的特点
zset 中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,使得 zset 内部的元素是可以维护有序性的。但是这个有序不是用下标作为排序依据的,而是根据分数(score)
| 数据结构 | 是否允许重复元素 | 是否有序 | 有序依据 |
| list | 是 | 是 | 索引下标 |
| set | 否 | 否 | |
| zset | 否 | 是 | 分数 |
常见命令
zadd
添加 \ 更新指定的元素以及关联的分数到 zset 中(分数符合 double 类型,+inf -inf 合法)
zadd key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]
返回本次添加成功的元素个数 O(log(N))
XX 仅用于更新已经存在的元素,不会添加新的元素
NX 仅用于添加新的元素,不会更新已经存在的元素
LT 新的分数小于原分数就更新,反之不更新
GT 新的分数大于原分数就更新,反之不更新
CH zadd 默认返回本次添加的元素个数,指定选项后,将包含本次更新的元素个数
INCR 类似 zincrby,将元素的分数加上指定的分数。只能指定一个元素和分数
分数相同时,按照元素自身的字典序排列
分数不同时,按照分数排列
zset 内部是按照升序排列

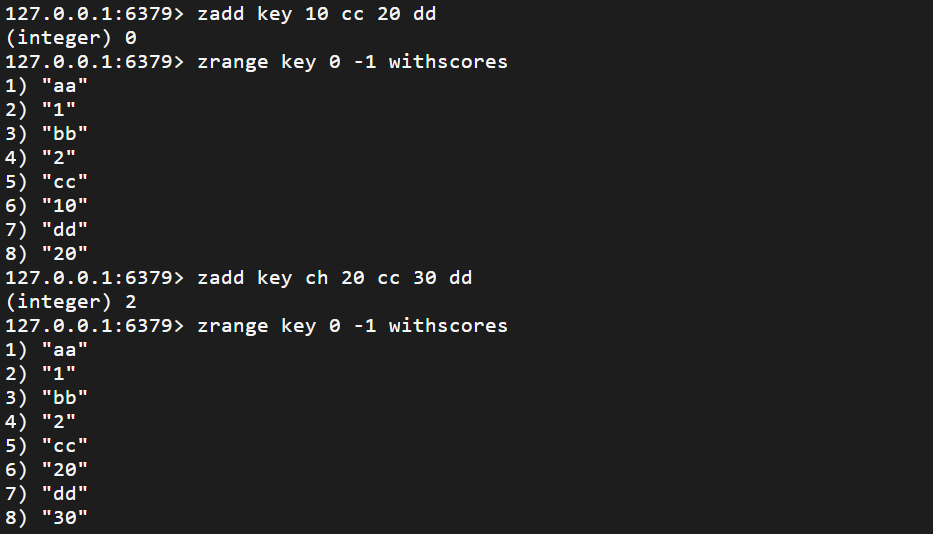

zrange
返回指定区间内的元素,按照分数升序
zrange key start stop [withscores]
返回区间内的元素列表 O(log(N) + M) N 集合中元素的个数 M start 到 stop 的元素个数
加上 withscores 将分数也一起返回
redis 内部存储数据时,是按照二进制的方式来存储的
redis 服务器不负责“字符编码”,把二进制转换成汉字,需要客户端支持 --raw
zcard
获取一个 zset 的基数(cardinality),即 zset 中的元素个数
zcard key
返回 zset 中的元素个数 O(1)
zcount
返回分数在 [min, max] 的元素个数(min max 默认包含,可通过 ( 排除)
zcount key min max
返回满足条件的元素列表个数 O(log(N))

zset 内部会记录每个元素当前的“排行” \ “次序”(下标)
查询到元素,就直接知道了元素所在的“次序”,直接把 min 和 max 对应的元素的次序减法
min 和 max 可以写成浮点数的形式(分数本身就是浮点数)
inf 无穷大 -inf 无穷小
zrevrange
返回指定区间里的元素,按照分数降序排列
zrevrange key start stop [withscores]
返回区间内的元素个数 O(log(N) + M)
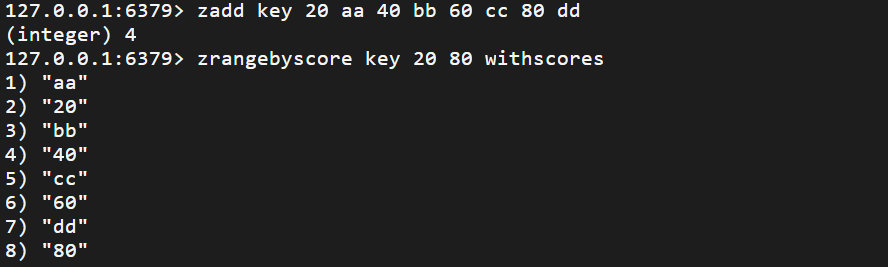
zrangebyscore
返回分数在 [min, max] 的元素
zrangebyscore key min max [withscores]
返回区间内的元素列表 O(log(N) + M)
zpopmax zpopmin
删除并返回分数最高的 count 个元素
zpopmax key [count ...]
zpopmin key [count ...]
返回 分数 和 元素列表 O(log(N) * count)
虽然 Redis 的有序集合记录了开头的元素,但是删除的时候使用的使用的是通用的删除函数,导致出现了重新查找的过程 O(1) ——> O(log(N))

如果存在多个元素,分数相同,同为最大值,zpopmax 删除时只删除其中一个元素
按照元素的字典序进行排列
bzpopmax bzpopmin
阻塞版本的 zpopmax zpopmin
bzpopmax key [key ...] timeout
bzpopmin key [key ...] timeout
返回元素列表 O(log(N))
timeout 超时时间,支持小写形式
zrank zrevrank
返回指定元素的排名(下标从 0 开始)
zrank key member 升序
zrevrank key member 降序
返回排名 O(log(N))

zcount 在计算时,先根据分数找到元素,再根据元素获取排名,把排名一减,得到元素个数
rev >= reverse
zscore
返回指定元素的分数
zscore key member
返回分数 O(1)

zrem
删除指定的元素
zrem key member [member ...]
返回本次删除的元素个数 O(log(N) * count)
zremrangebyrank
按照排序,删除指定范围内的元素(左闭右闭)升序
zremrangebyrank key start stop
返回本次删除的元素个数 O(log(N) + M)
zremrangebyscore
按照分数,删除指定范围内的元素(左闭右闭)升序
zremrangebyscore key min max ( 排除边界值
返回本次删除的元素个数 O(log(N) + M)
zincrby
为指定的元素的关联分数添加指定的分数值
zincrby key increment member
返回增加后的元素的分数 O(log(N))

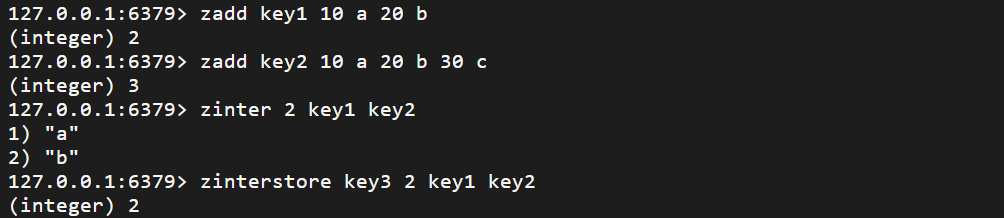
zinter zinterstore
求出给定有序集合中元素的交集,并保存进目标集合中
合并过程中以元素为单位,元素对应的分数按照不同的聚合方式和权重得到新的分数
zinter numkeys key [key ...] [weights weight [weight ...]] [aggreg <sum | min | max >]
zinterstore destination numkeys key [key ...] [weights weight [weight ...]]
[aggreg <sum | min | max >]
返回目标集合的元素列表
返回目标集合中的元素个数 O(N*K) + O(M*log(M))
N 最小集合的元素个数 K 集合的个数 M 目标集合的元素个数
zunion zunionstore
求出给定有序集合中元素的并集,并保存进目标集合中
zuoion numkeys key [key ...] [weights weight [weight ...]] [aggreg <sum | min | max >]
zunionstore destination numkeys key [key ...] [weights weight [weight ...]]
[aggreg <sum | min | max >]
O(N) + O(log(M) * M)
N 集合的个数 M 目标集合的元素个数
内部编码
1)ziplist(压缩列表)元素个数较少或者元素的体积较小
2)skiplist(跳表)
跳表是一个“复杂链表”,查询元素 O(N),相比于树状结构,更适合按照范围获取元素 (B+树)
应用场景
排行榜系统
例如网站上的热搜信息,榜单的维度是多方面的,“分数”是实时变化的
只要把相关信息和对应的分数放到 zset 中就会自动排序
随时可以按照下表进行查询,随着分数变化,使用 zincrby 也更方便,还可以自动排序
对于不同维度,可以将不同维度的数值都放到一个有序集合中,通过 zinterstore 或者 zunionstore 把上述集合按照权重进行集合间运算,得到结果集合