vLLM V1:性能优化与集群扩展的深度解析
近期,vLLM(Very Large Language Model)团队发布了重大版本更新——vLLM V1。这一版本不仅在性能上取得了显著提升,还通过集群扩展为大规模部署提供了新的解决方案。本文将从 vLLM V1 的性能优化、用户实际体验以及集群扩展三个方面进行详细解析,帮助读者全面了解这一版本的亮点与挑战。
一、vLLM V1 性能优化
(一)架构重构与 CPU Overhead 优化
vLLM V1 的核心架构进行了全面重构,主要目标是减少 CPU 开销并提升整体吞吐量。在 vLLM V0 中,API 服务器和推理引擎分离到不同进程,通过 ZMQ socket 进行通信。而在 vLLM V1 中,这一架构进一步优化,引入了 EngineCore 执行循环,专注于调度程序和模型执行器,使得 CPU 密集型任务(如 tokenization、多模态输入处理、de-tokenization 和请求流式传输)与核心执行循环有更大的重叠,从而最大化模型吞吐量。
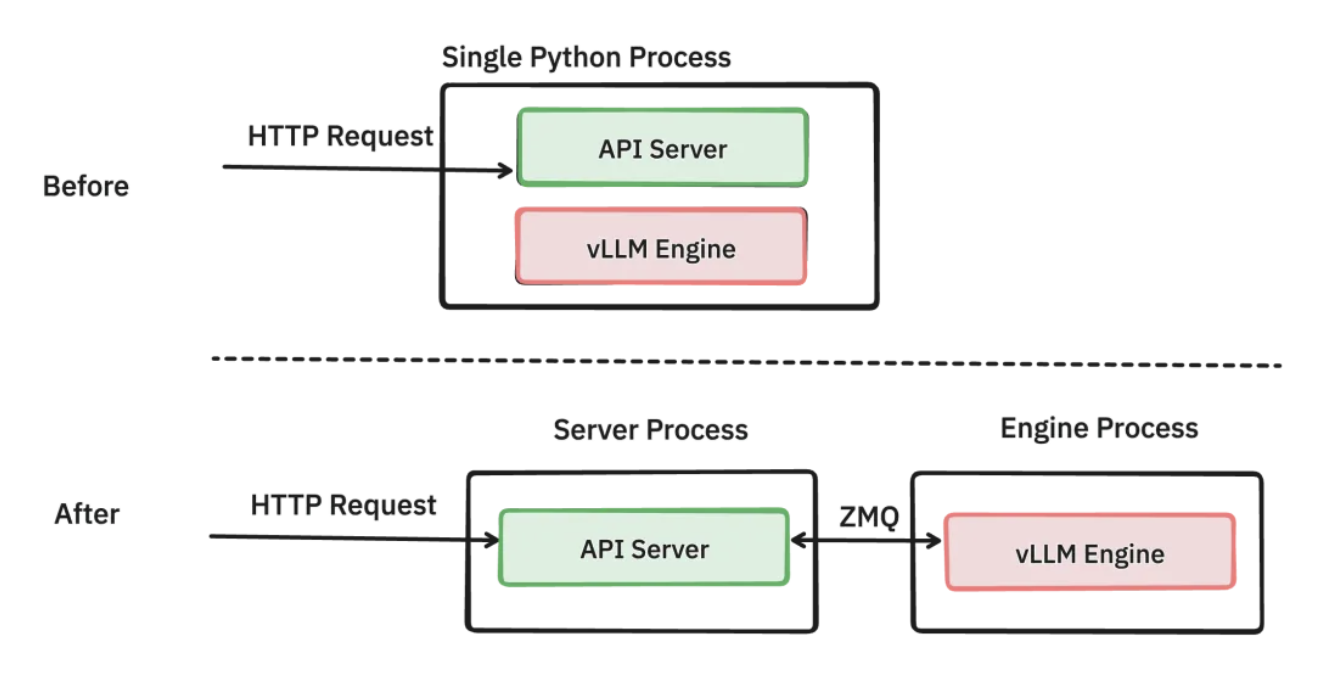
进程通信机制
vLLM V1 在进程通信方面采用了独特的策略,结合了 ZMQ 和共享内存的优势。其内存布局如下:
-
Buffer Memory Layout:
+-------------------------------+----------------------------------------+ | chunk0 | chunk1 | ... | chunk | metadata0 | metadata1 | ... | metadata | +-------------------------------+----------------------------------------+ | max_chunks x max_chunk_bytes | max_chunks x (1 + n_reader) bytes | -
Metadata Memory Layout:每个字节是一个标志,第一个字节是写入标志,其余是读取器标志。标志状态如下:
-
0???...???:块未写入,不可读,可写。 -
1000...000:块刚写入,可读,不可写。 -
1???...???:块已写入且被部分读取器读取,可读(未读),不可写。 -
1111...111:块已写入且被所有读取器读取,不可读,可写。
-
这种机制通过数据大小判断选择通信方式(小数据使用共享内存,大数据使用 ZMQ),并通过元数据区域跟踪每个块的读写状态,确保读写同步。
(二)调度器重构
vLLM V1 引入了一个简单而灵活的调度器,消除了 prefill 和 decode 阶段之间的传统区别。调度决策通过一个简单的字典表示,例如 {request_id: num_tokens},指定每个步骤中每个请求要处理的标记数。这种表示方式足够通用,可以支持以下功能:
-
Chunked Prefills:对长文本进行分块处理,避免阻塞其他请求。
-
Prefix Caching:重用相同前缀的 KV cache,提高吞吐量。
-
Speculative Decoding:预测可能的输出 token,减少推理次数。
-
Resource Preemption:在资源不足时抢占低优先级请求。
-
Encoder Cache:缓存多模态输入的编码结果,避免重复计算。
调度器的代码量从 v0 的 2k+ 行减少到 700+ 行,整体流程更加简洁高效。
(三)其他性能优化
除了上述重大更新,vLLM V1 还引入了以下优化:
-
分段 CUDA Graphs:缓解了 CUDA Graphs 的限制,提升了 GPU 利用率。
-
Tensor-Parallel Inference:优化了多 GPU 推理架构,减少了进程间通信开销。
-
Persistent Batch:通过缓存输入张量并仅应用差异更新,减少了 CPU 开销。
-
FlashAttention 3:集成了高性能的注意力机制,支持动态推理场景。
根据官方测试,vLLM V1 相比 V0 吞吐量提高了 1.7 倍,尤其在 H100 等高性能 GPU 上表现显著。
二、用户实际体验
尽管 vLLM V1 在理论上取得了显著的性能提升,但从用户实际体验来看,效果似乎并不一致。
(一)环境变量配置
在 vLLM 0.7.0 到 0.8.0 版本中,用户需要手动设置环境变量来启用 V1 架构:
Python
os.environ["VLLM_USE_V1"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
os.environ["TRITON_PTXAS_PATH"] = "/usr/local/cuda/bin/ptxas"而在 vLLM 8.0 及以上版本中,V1 架构默认启用,用户可以通过设置 VLLM_USE_V1=0 来禁用。
(二)性能反馈
根据用户反馈,在 NVIDIA L4 等中低端 GPU 上,vLLM V1 的性能提升并不明显,甚至在某些情况下出现了性能下降。例如,在 4 块 NVIDIA L4 GPU 上运行 14B 参数的量化模型时,vLLM V1 的表现如下:
| Framework | Time Taken (s) |
|---|---|
| vLLM V0 (0.7.3) | 456 |
| vLLM V1 (0.7.3) | 438 |
| SGLang | 390 |
可以看到,尽管 vLLM V1 有所提升,但仍未超过 SGLang。此外,用户还反馈 vLLM V1 在初始化时长和显存占用方面存在问题,例如:
-
v0.7.3 初始化时间:169.77 秒
-
v0.8.1 初始化时间:200.46 秒
-
v0.8.2 初始化时间:239.56 秒
(三)兼容性问题
在 vLLM V1 中,与 FlashInfer 的兼容性出现了问题。用户反馈在启用 FlashInfer 时,vLLM V1 会报错:
NotImplementedError: VLLM_USE_V1=1 is not supported with VLLM_ATTENTION_BACKEND=FLASHINFER.
解决方案是降级 FlashInfer 的版本:
bash
pip install vllm bitsandbytes flashinfer-python==0.2.2.post1三、vLLM 集群扩展:vLLM Production Stack
vLLM Production Stack 是 vLLM 团队推出的一个全推理栈,旨在将 vLLM 从单机部署扩展到集群部署,提供高性能、易部署的解决方案。
(一)架构设计
vLLM Production Stack 在 vLLM 的基础上,增加了以下关键功能:
-
KV Cache Sharing & Storage:通过 LMCache 项目实现 KV 缓存共享和存储,加速上下文重用场景的推理。
-
Prefix-Aware Routing:根据请求的上下文,将查询路由到已缓存相关 KV 缓存的 vLLM 实例。
-
Observability:通过 Grafana 提供实时监控,包括实例健康状态、请求延迟分布、首次令牌时间(TTFT)、吞吐量等指标。
-
Autoscaling:根据工作负载动态调整集群规模,确保高吞吐量和低延迟。
架构图如下:
https://blog.lmcache.ai/assets/img/stack-overview-2.png
(二)部署与性能优势
vLLM Production Stack 支持通过 Helm Chart 在 Kubernetes 集群上一键部署:
bash
sudo helm repo add llmstack-repo https://lmcache.github.io/helm/ && \sudo helm install llmstack llmstack-repo/vllm-stack在性能方面,vLLM Production Stack 相比其他部署方案(如 vLLM + KServe 和商业端点服务)表现出色,特别是在多轮问答工作负载中,其首次令牌时间和令牌间延迟显著优于其他方案。
(三)用户反馈
用户反馈 vLLM Production Stack 的部署过程简单,监控功能强大,且性能提升明显。然而,也有用户指出,其在某些环境下的初始化时间和显存占用仍有待优化。
四、总结与展望
vLLM V1 通过架构重构和多项优化,在理论上取得了显著的性能提升,尤其在高性能 GPU 上表现突出。然而,从用户实际体验来看,vLLM V1 在中低端 GPU 上的性能提升有限,甚至存在兼容性和初始化时间等问题。此外,vLLM Production Stack 为集群部署提供了新的解决方案,但在实际部署中仍需进一步优化。