【LLMs篇】09:白话PPO训练
想象一下,你在玩一个闯关游戏,目标是获得最高分。你不知道游戏规则是什么,只能通过不断尝试来学习。
1. 强化学习是什么?
简单来说,强化学习就是让一个“智能体”(agent,比如游戏里的你)通过与“环境”(environment,比如游戏世界)交互来学习最优的“策略”(policy,也就是在某个情况下应该做什么动作)。智能体做出一个动作,环境会给它一个“奖励”(reward),智能体根据奖励的好坏来调整自己的策略,争取以后获得更多奖励。
核心: 智能体学习一个策略 π(a|s),这个策略告诉它在状态 s 下,应该以多大的概率选择动作 a。
2. 策略优化:怎么找到好策略?
找到最优策略的方法有很多,其中一类叫做“策略梯度”(Policy Gradient)。它的基本思想是:既然策略是一个概率分布(在某个状态下选择各种动作的概率),我们可以把这个策略表示成一个神经网络,网络的参数决定了在不同状态下选择不同动作的概率。
策略梯度的想法很简单:如果在某个状态下,你选择了某个动作并获得了很高的奖励(或者说“优势”,后面会解释),那么下次再遇到这个状态时,你应该增加选择这个动作的概率。反之,如果奖励很低,就减少选择这个动作的概率。通过大量尝试和调整,策略网络就会慢慢学会在什么情况下做什么动作能获得高奖励。
策略梯度的问题:步子迈大了容易扯着蛋
策略梯度的更新有点像爬山找最高点。每走一步(更新一次策略网络),你都朝着让奖励增加最快的方向走。问题是,如果你每一步迈得太大,很可能一下就跨过了最高点,甚至跑到悬崖边上!也就是说,策略网络参数的一次大更新,可能导致策略发生巨大变化,让智能体的表现变得非常糟糕,甚至永远学不回来了。
控制更新步长很重要!TRPO(Trust Region Policy Optimization,信任区域策略优化)就是为了解决这个问题而诞生的。它通过一些复杂的方法,限制每次策略更新后,新策略与旧策略之间的差异不能太大,确保更新是“安全”的。但TRPO实现起来比较复杂。
3. PPO登场:在简单和安全之间找到平衡
PPO(Proximal Policy Optimization,近端策略优化)的目标:在更新策略时,限制新策略与旧策略的差距,保证更新的稳定性,同时让实现尽可能简单。PPO也因此成为了目前强化学习领域最流行、应用最广泛的算法之一。
PPO的核心思想:修剪(Clip)掉那些“太过激进”的策略更新
PPO不像TRPO那样用复杂的方法来限制策略差异,而是提出了一种巧妙的目标函数(训练时最大化的那个数学表达式)。这个目标函数在计算新策略的好坏时,会“检查”新策略相对于旧策略在某个动作上的概率变化。如果这个变化“太大”(超过了设定的一个阈值),它就会被“修剪”掉,不再对目标函数产生影响。
打个比方: 想象旧策略是你原来的做人原则,新策略是你想要调整后的原则。PPO说:你可以调整你的原则,但每次调整幅度不能太大。如果你某个新原则和旧原则差异太大(比如原来你觉得这件事有10%的概率去做,新原则变成90%),PPO就认为这个改变太激进了,会忽略掉这次“太过激进”的改变带来的潜在好处(或者坏处),强行把它限制在一个合理的范围内。
4. PPO是怎么计算和训练的?
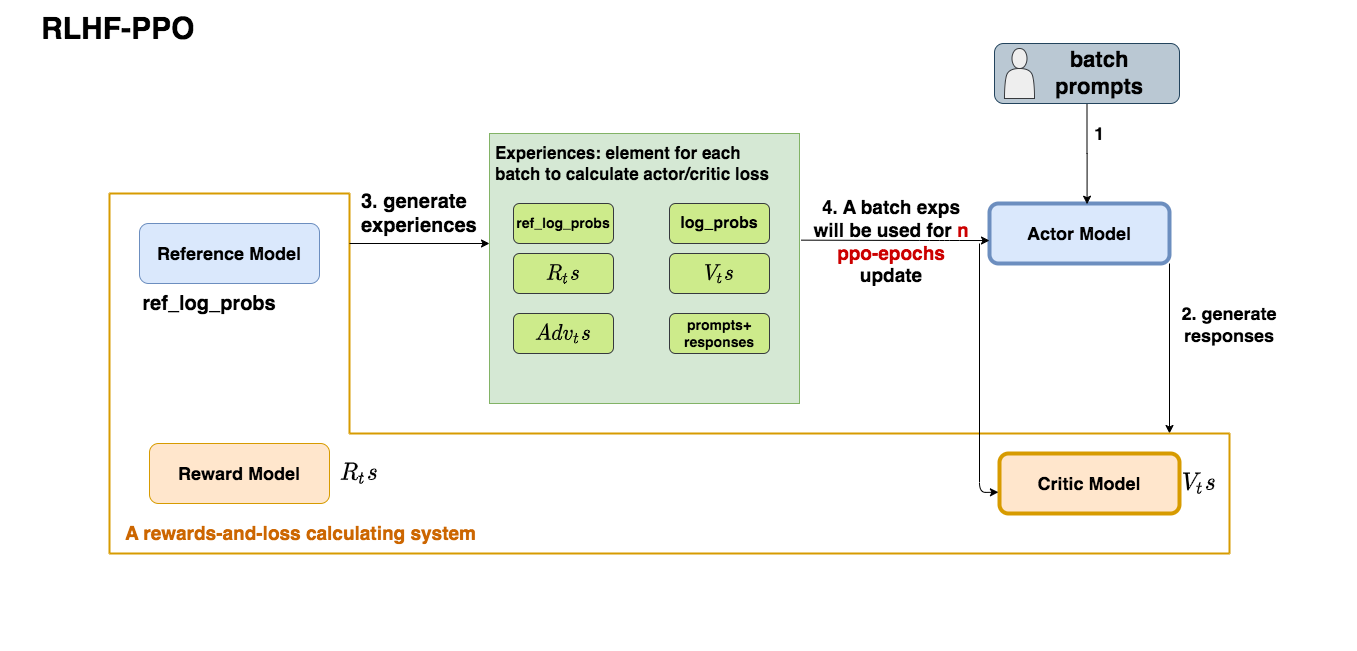
PPO通常采用“Actor-Critic”架构。
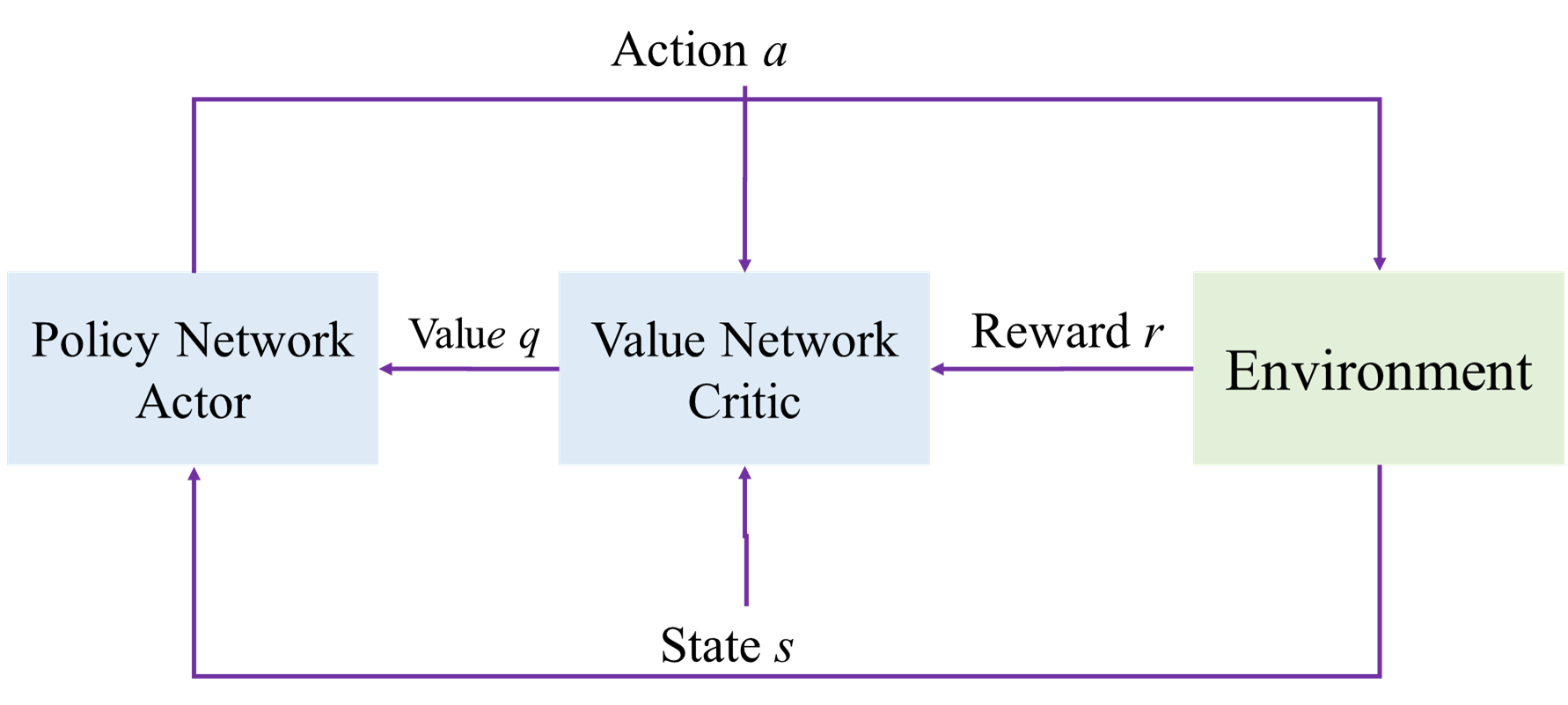
- Actor(演员): 这就是我们的策略网络 π。它根据当前的状态 s,输出在各种可能动作上的概率分布。它决定了智能体“演”什么动作。
- Critic(评论家): 这是另一个网络,通常是一个“价值网络”V。它用来评估在某个状态 s 下,预期的总奖励是多少(或者说,这个状态有多好)。Critic给Actor的表演打分。
在理解了PPO的核心思想是通过裁剪(Clipping)来限制策略更新的幅度,保证训练稳定性。现在,我们来看一下在实际训练中,这些思想是如何通过一个标准的流程来实现的。PPO通常采用Actor-Critic框架,因此训练过程涉及到这两个网络的协同更新。
5. PPO 训练流程
整个PPO训练可以看作是一个迭代优化的过程,每一次迭代(通常称为一个“训练循环”或“回合”)都包含以下几个主要步骤:
步骤 1:数据收集 (Collecting Experience)
- 目标: 使用当前的策略(由Actor网络 π_θ_old 表示,这里的
θ_old是本次迭代开始时的策略网络参数)与环境进行交互,生成一批用于训练的数据。 - 过程: 智能体在环境中执行一系列动作。从一个初始状态开始,智能体根据策略 π_θ_old 在当前状态
s_t下选择一个动作a_t。环境接收动作a_t后,转移到新的状态s_{t+1}并给出奖励r_t。这个过程持续进行,直到达到终止状态或达到预设的最大步数(例如,收集 T 步的数据)。 - 产出: 收集到一批“经验数据”,通常组织成轨迹(Trajectories)或一个大的批次(Batch)。这些数据包括状态序列
(s_0, s_1, ..., s_T)、动作序列(a_0, a_1, ..., a_T)、奖励序列(r_0, r_1, ..., r_T),以及每个状态下旧策略输出的动作概率π_θ_old(a_t|s_t)和旧价值网络预测的值V_φ_old(s_t)(这里的φ_old是本次迭代开始时的价值网络参数)。 - 专业术语: 这批数据被称为一个
on-policy batch,因为它是用当前正在优化的策略收集的。收集的数据量T是一个重要的超参数。
步骤 2:优势函数计算 (Advantage Estimation)
- 目标: 根据收集到的经验数据,计算每个时间步
t的优势函数A_t。优势函数衡量了在状态s_t执行动作a_t相对于该状态平均而言(即相对于价值函数V(s_t))有多好。 - 过程: 在收集完 T 步数据后,我们利用这些数据和当前的价值网络
V_φ_old来估算优势。一种非常常用的、标准的方法是 广义优势估计 (Generalized Advantage Estimation, GAE)。GAE 使用一个衰减因子γ(用于未来奖励)和一个平滑因子λ(用于平衡方差与偏差)来计算优势。- 首先计算时间差分(TD)误差
δ_t = r_t + γ * V_φ_old(s_{t+1}) - V_φ_old(s_t)。TD误差表示单步奖励加上对下一状态的预测价值与当前状态预测价值之间的差。 - 然后,GAE 将这些TD误差以
(γλ)为权重进行加权求和,得到优势估计A_t。
- 首先计算时间差分(TD)误差
- 产出: 为批次中的每个时间步
t计算得到一个对应的优势值A_t。
步骤 3:网络参数优化 (Network Optimization)
- 目标: 利用收集到的批次数据(状态、动作、优势、旧策略概率等),更新策略网络(Actor)的参数
θ和价值网络(Critic)的参数φ。 - 过程: PPO的一个关键特点是在收集到一批数据后,会在这批固定的数据上进行多次(K 次)迭代优化(称为
epochs per update)。这样做可以更有效地利用数据,并提高样本效率。- 划分 Minibatch: 在每次迭代优化时,通常会将整个批次数据进一步划分为更小的子批次(
minibatches),然后依次处理这些minibatches进行随机梯度优化。 - 计算总损失函数 (Total Loss): PPO通常优化一个总的损失函数,它结合了策略损失、价值损失,并常常包含一个熵损失项以鼓励探索:
L(θ, φ) = L_clip(θ) - c1 * L_VF(φ) + c2 * S(π_θ)L_clip(θ):这是策略的PPO裁剪目标函数,用于最大化。它依赖于新旧策略的概率比值r(θ) = π_θ(a|s) / π_θ_old(a|s)和计算好的优势A,并包含裁剪机制。L_VF(φ):这是价值网络的损失函数,通常是预测值V_φ(s)与一个目标值(如GAE优势A_t加上旧的预测值V_φ_old(s_t),或者更简单的如 TD(λ) 回报或蒙特卡洛回报)之间的均方误差(MSE),用于最小化。c1是一个系数,平衡策略和价值损失的重要性。S(π_θ):这是策略的熵,用于最小化(当前面是-号时)或最大化(当前面是+号时,通常是最大化以增加随机性)。它可以帮助智能体进行更充分的探索。c2是一个系数,控制熵项的权重。
- 梯度更新:
- 对参数
θ执行梯度上升(因为我们要最大化L_clip项,而L_VF和S对θ的梯度也需要考虑)。使用收集到的数据计算关于θ的梯度∇_θ L(θ, φ),然后更新θ:θ ← θ + α_θ * ∇_θ L(θ, φ),其中α_θ是策略网络的学习率。 - 对参数
φ执行梯度下降(因为我们要最小化L_VF项)。使用收集到的数据计算关于φ的梯度∇_φ L_VF(φ),然后更新φ:φ ← φ - α_φ * ∇_φ L_VF(φ),其中α_φ是价值网络的学习率。注意,在实现中,通常是计算∇_φ L(θ, φ),但L_clip和S对φ的梯度为零,所以实际上就是基于L_VF更新φ。
- 对参数
- 重要: 在这 K 个 epoch 的优化过程中,用于计算概率比值
r(θ)的旧策略π_θ_old是固定不变的,它就是步骤 1 中用来收集数据的策略。只有正在优化的新策略π_θ是变化的。
- 划分 Minibatch: 在每次迭代优化时,通常会将整个批次数据进一步划分为更小的子批次(
步骤 4:更新旧策略 (Update Old Policy)
- 目标: 为下一次数据收集循环准备新的“旧策略”。
- 过程: 在完成了步骤 3 中的 K 个 epoch 优化后,当前的策略网络参数
θ已经更新。我们将这个新的参数θ赋值给θ_old,即将当前的策略设置为下一次迭代的旧策略π_θ_old ← π_θ。同样,价值网络的参数φ也被更新。
步骤 5:重复 (Repeat)
- 回到步骤 1,使用新的策略
π_θ_old和价值函数V_φ_old再次与环境互动,收集新的批次数据,并重复步骤 2-4,直到达到训练的总步数或智能体学会了任务。
关键超参数 (Hyperparameters):
在PPO训练中,一些关键的超参数需要仔细调整,它们直接影响训练的稳定性和性能:
T(Steps per batch): 每次数据收集循环收集多少步经验。K(Epochs per update): 在收集到的一批数据上,进行多少次梯度更新。Minibatch size: 每次梯度计算使用多少个样本。ε(Clip ratio): PPO裁剪目标函数中的阈值,通常取 0.1 或 0.2。γ(Discount factor): 未来奖励的衰减因子,通常接近 1 (如 0.99)。λ(GAE factor): GAE 中的平滑因子,通常取 0.95。α_θ,α_φ(Learning rates): 策略网络和价值网络的学习率。c1,c2: 价值损失系数和熵损失系数。
6. PPO的优点:
- 实现简单: 相比TRPO,PPO的算法框架和目标函数更容易理解和实现。
- 性能好: PPO在很多任务上都能取得与最先进算法相媲美的性能。
- 稳定可靠: 裁剪机制有效地控制了策略更新的幅度,使得训练过程更加稳定,不容易崩溃。
7. PPO的应用:
PPO被广泛应用于各种需要智能体学习复杂策略的场景,比如:
- 机器人控制(行走、抓取等)
- 玩电子游戏(Atari、StarCraft等)
- 自动驾驶
- 推荐系统
- 金融交易
总结:
PPO就像一个经验丰富的老师,它不像新手老师那样,看到一点进步或退步就大幅调整教学计划。PPO会根据学生(智能体)的表现(优势),决定如何调整教学内容(策略)。但它会时刻注意,这次调整不能让学生的学习方向(新策略)和之前的方向(旧策略)偏离得太远。如果学生“领悟”得太快,进步太激进(概率比值太大),或者“钻牛角尖”退步太厉害(概率比值太小),老师就会“修剪”掉这些极端的反应,把调整幅度限制在一个“信任区域”内(通过裁剪 ε 参数控制),确保学生能稳步前进,最终学成。